MapReduce之GroupingComparator分组(辅助排序、二次排序)_mapreduce groupingcomparator-程序员宅基地
技术标签: java mapreduce Hadoop hadoop 大数据
指对Reduce阶段的数据根据某一个或几个字段进行分组。
案例
需求
有如下订单数据
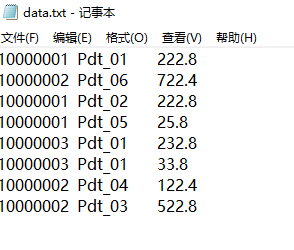
现在需要找出每一个订单中最贵的商品,如图

需求分析
-
利用“订单id和成交金额”作为
key,可以将Map阶段读取到的所有订单数据先按照订单id(升降序都可以),再按照acount(降序)排序,发送到Reduce。 -
在Reduce端利用
groupingComparator将订单id相同的kv聚合成组,然后取第一个成交金额即是最大值(若有多个成交金额并排第一,则都输出)。 -
Mapper阶段主要做三件事:
keyin-valuein
map()
keyout-valueout -
期待shuffle之后的数据:
10000001 Pdt_02 222.8
10000001 Pdt_01 222.8
10000001 Pdt_05 25.810000002 Pdt_06 722.4
10000002 Pdt_03 522.8
10000002 Pdt_04 122.410000003 Pdt_01 232.8
10000003 Pdt_01 33.8 -
Reducer阶段主要做三件事:
keyin-valuein
reduce()
keyout-valueout -
进入Reduce需要考虑的事
- 获取分组比较器,如果没设置默认使用MapTask排序时key的比较器
- 默认的比较器比较策略不符合要求,它会将orderId一样且acount一样的记录才认为是一组的
- 自定义分组比较器,只按照orderId进行对比,只要OrderId一样,认为key相等,这样可以将orderId相同的分到一个组!
在组内去第一个最大的即可
编写程序
利用“订单id和成交金额”作为key,所以把每一行记录封装为bean。由于需要比较ID,所以实现了WritableComparable接口
OrderBean.java
public class OrderBean implements WritableComparable<OrderBean>{
private String orderId;
private String pId;
private Double acount;
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getpId() {
return pId;
}
public void setpId(String pId) {
this.pId = pId;
}
public Double getAcount() {
return acount;
}
public void setAcount(Double acount) {
this.acount = acount;
}
public OrderBean() {
}
@Override
public String toString() {
return orderId + "\t" + pId + "\t" + acount ;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(orderId);
out.writeUTF(pId);
out.writeDouble(acount);
}
@Override
public void readFields(DataInput in) throws IOException {
orderId=in.readUTF();
pId=in.readUTF();
acount=in.readDouble();
}
// 二次排序,先按照orderid排序(升降序都可以),再按照acount(降序)排序
@Override
public int compareTo(OrderBean o) {
//先按照orderid排序升序排序
int result=this.orderId.compareTo(o.getOrderId());
if (result==0) {
//订单ID相同,就比较成交金额的大小
//再按照acount(降序)排序
result=-this.acount.compareTo(o.getAcount());
}
return result;
}
}
自定义比较器,可以通过两种方法:
- 继承
WritableCompartor - 实现
RawComparator
MyGroupingComparator.java
//实现RawComparator
public class MyGroupingComparator implements RawComparator<OrderBean>{
private OrderBean key1=new OrderBean();
private OrderBean key2=new OrderBean();
private DataInputBuffer buffer=new DataInputBuffer();
@Override
public int compare(OrderBean o1, OrderBean o2) {
return o1.getOrderId().compareTo(o2.getOrderId());
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer);
buffer.reset(null, 0, 0); // clean up reference
} catch (IOException e) {
throw new RuntimeException(e);
}
return compare(key1, key2);
}
}
MyGroupingComparator2.java
//继承WritableCompartor
public class MyGroupingComparator2 extends WritableComparator{
public MyGroupingComparator2() {
super(OrderBean.class,null,true);
}
public int compare(WritableComparable a, WritableComparable b) {
OrderBean o1=(OrderBean) a;
OrderBean o2=(OrderBean) b;
return o1.getOrderId().compareTo(o2.getOrderId());
}
}
OrderMapper.java
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable>{
private OrderBean out_key=new OrderBean();
private NullWritable out_value=NullWritable.get();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, OrderBean, NullWritable>.Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
out_key.setOrderId(words[0]);
out_key.setpId(words[1]);
out_key.setAcount(Double.parseDouble(words[2]));
context.write(out_key, out_value);
}
}
OrderReducer.java
public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable>{
/*
* OrderBean key-NullWritable nullWritable在reducer工作期间,
* 只会实例化一个key-value的对象!
* 每次调用迭代器迭代下个记录时,使用反序列化器从文件中或内存中读取下一个key-value数据的值,
* 封装到之前OrderBean key-NullWritable nullWritable在reducer的属性中
*/
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values,
Reducer<OrderBean, NullWritable, OrderBean, NullWritable>.Context context)
throws IOException, InterruptedException {
Double maxAcount = key.getAcount();
for (NullWritable nullWritable : values) {
if (!key.getAcount().equals(maxAcount)) {
break;
}
//复合条件的记录
context.write(key, nullWritable);
}
}
}
OrderBeanDriver.java
public class OrderBeanDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("E:\\mrinput\\groupcomparator");
Path outputPath=new Path("e:/mroutput/groupcomparator");
//作为整个Job的配置
Configuration conf = new Configuration();
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
// Job需要根据Mapper和Reducer输出的Key-value类型准备序列化器,通过序列化器对输出的key-value进行序列化和反序列化
// 如果Mapper和Reducer输出的Key-value类型一致,直接设置Job最终的输出类型
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 设置自定义的分组比较器
job.setGroupingComparatorClass(MyGroupingComparator2.class);
// ③运行Job
job.waitForCompletion(true);
}
}
输出结果
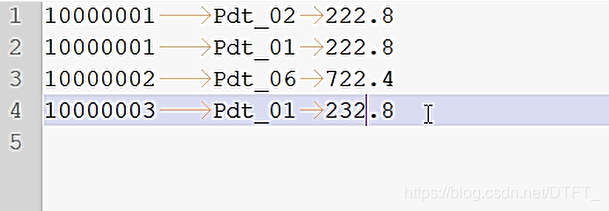
智能推荐
docker删除重装,以及极其重要的/etc/docker/key.json文件-程序员宅基地
文章浏览阅读8.9k次,点赞2次,收藏2次。先说以下我为何要删除docker的原因吧:因为我感觉Docker Hub有点慢,就配置了阿里云的镜像加速器,可是按阿里云的官方配置完后我怎么感觉它更慢了,对比昨天配置阿里的maven镜像仓库后快到起飞的速度,我认为是此次配置没有生效。多次确认新加入的/etc/docker/demon.json文件无误后又多次systemctl了未果,随即我怀疑阿里给出的以下方案中的“修改”的/etc/dock...
空间物理——概述_空间物理概论-程序员宅基地
文章浏览阅读1.9k次,点赞3次,收藏4次。文章目录空间物理的研究对象太阳风能量向地球传输的三种方式和所需要的时间太阳内部结构、太阳活动太阳内部结构太阳活动太阳风速度从太阳表面到地球轨道附近变化参考空间物理的研究对象大气层:10KM以上,分成平流层、中层、低热层、热层、逃逸层电离层:60-90KM以上,一直到1000KM左右,部分电离气体,中性成风碰撞的影响不可忽略地球磁层:完全电离的气体,1000KM以上,可忽略碰撞,有太阳风和..._空间物理概论
BQ4050学习笔记(二)-程序员宅基地
文章浏览阅读2.9k次,点赞5次,收藏25次。BQ4050学习笔记(二)永久失效:如果发⽣严重故障,该设备可以永久禁⽤电池组。永久故障检查(IFC 和 DFW 除外)可以通过设置Settings:Enabled PFA、 Settings:Enabled PF B、 Settings:Enabled PF C 和Settings:Enabled PF D 中的相应位单独启⽤或禁⽤。所有永久在设置ManufacturingStatus()[PF]之前,故障检查(IFC 和 DFW 除外)被禁⽤。当任何PFStatus()位置位时,器件进⼊ PER_bq4050
SpringCloudAlibaba-Nacos注册中心的使用_spring-cloud-alibaba 使用nacos 2.1版本-程序员宅基地
文章浏览阅读152次。第二步:填写配置文件参数,这里定义了一个名字为application-user-dev.yaml的配置,使用的是YAML格式。DataID : 非常重要,可以看做是配置的文件的名字,在程序中拉取配置文件的时候需要指定Data ID。如果不使用默认的public命名空间,那么需要指定namespace配置为要使用的命名空间的Id值。第一步:打开Nacos监控面板,进入配置列表,新增一个user服务的配置文件。进入配置列表 ,切换到新建立的命名空间,创建配置文件。修改Nacos,添加命名空间。_spring-cloud-alibaba 使用nacos 2.1版本
CVE-2023-21716 Microsoft Word远程代码执行漏洞Poc_cve-2023-21716复现-程序员宅基地
文章浏览阅读293次。受害者打开python代码生成的RTF文件,RTF解析器解析恶意代码,触发堆溢出,Microsoft Word会闪退,用户其它Word中未保存的内容会丢失。_cve-2023-21716复现
c语言程序设计让a变成A,c语言程序设计a期末模拟试题.docx-程序员宅基地
文章浏览阅读451次。文件排版存档编号:[UYTR-OUPT28-KBNTL98-UYNN208]文件排版存档编号:[UYTR-OUPT28-KBNTL98-UYNN208]C语言程序设计A期末模拟试题C语言程序设计A期末模拟试题一一、单项选择题(每小题2分,共20分)由C++目标文件连接而成的可执行文件的缺省扩展名为( )。A. cpp B. exe C. obj D. li..._c语言如何将a转换成a
随便推点
利用beef和msf实现session远程命令_msf如何切换一个session-程序员宅基地
文章浏览阅读534次。笔记beef启动 beef 的方法msfbeef工具目录 /usr/share/beef-xss配置文件 config.yaml启动 beef 的方法1.beef-xss2./usr/share/beef-xss/beef(使用前需要修改默认的用户名称和密码)Web 管理界面 http://127.0.0.1:3000/ui/panelShellcode http://127.0.0.1:3000/hook.js测试页面 http://127.0.0.1:3000/demos/butch_msf如何切换一个session
python判断丑数_丑数问题及变种小结-程序员宅基地
文章浏览阅读503次。丑数问题及变种小结声明1 判断丑数因子只包含2,3,5的数称为丑数(Ugly Number),习惯上把1当作第一个丑数面试lintcode 517 ugly numbersegmentfault剑指offer 面试题34 丑数数组解法:参考剑指offer,将待判断目标依次连续整除2,3,5,若是最后获得1,证实该数为丑数;优化/*** 依次整除2,3,5判断(2,3,5顺序判断时间最优)* htt..._编写python来证明一个数是丑数
python自动化测试实战 —— WebDriver API的使用_python webdriver api-程序员宅基地
文章浏览阅读1.9k次,点赞30次,收藏11次。Selenium 简介: WebDriver是Selenium Tool套件中最重要的组件。Selenium 2.0之后已经将Selenium和WebDriver进行合并,作为一个更简单、简洁、有利于维护的API提供给测试人员使用。 它提供了一套标准的接口,可以用多种编程语言调用,并且和浏览器进行交互。 WebDriver可以对浏览器进行控制,包括输入URL,点击按钮,填写表单,滚动页面,甚至是执行JavaScript代码。同时,它也能够获取网页中的信息,如文本,标签,属_python webdriver api
Nodejs crypto模块公钥加密私钥解密探索_crypto.publicencrypt-程序员宅基地
文章浏览阅读1w次。1.什么是公钥加密私钥解密 简单一点来说一般加密解密都用的是同一个秘钥或者根本不用,而这里采用的是加密用一个秘钥,解密用另一个秘钥且能解密成功.这就属于不对称加密解密算法的一种了.2.公钥秘钥的生成 由于这种加密方案,公钥秘钥是成对的,所以需要一些工具生成 利用 openssl 生成公钥私钥 生成公钥: openssl genrsa -out rsa_private_key...._crypto.publicencrypt
Maven简明教程(5)---依赖关系(实例篇)_依赖关系怎么写-程序员宅基地
文章浏览阅读1.7k次。[工欲善其事,必先利其器]上文中,我们简单介绍了依赖关系的基本理论与配置方式。但是由于这个知识点在我们日后的开发过程中会经常使用到,因此,我们在本篇中通过演示实例来说明依赖关系,请各位看官一定跟着步骤,亲自尝试一番。仔细观察通过这种方式对我们程序架构造成的影响。特别的,这里以一份已经调试完成的工程为例,因此,与前文说的工程命名不一致,敬请谅解。准备工作:a.操作系统:win7 x6_依赖关系怎么写
2017多校联合第五场1006/hdu6090Rikka with Graph(思维公式)-程序员宅基地
文章浏览阅读343次。Rikka with GraphTime Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Submission(s): 592 Accepted Submission(s): 353Problem DescriptionAs we know,