两个不同的进程 虚拟地址相同_Linux的进程地址空间[二] - VMA-程序员宅基地
技术标签: 两个不同的进程 虚拟地址相同
Linux的进程地址空间[一]
segments
一个进程通常由加载一个elf文件启动,而elf文件是由若干segments组成的,同样的,进程地址空间也由许多不同属性的segments组成,但这与硬件意义上的segmentation机制(参考这篇文章)不同,后者在某些体系结构(比如x86)中起重要作用,充当内存中物理地址连续的独立空间。Linux进程中的segment是虚拟地址空间中用于保存数据的区域,只在虚拟地址上连续。
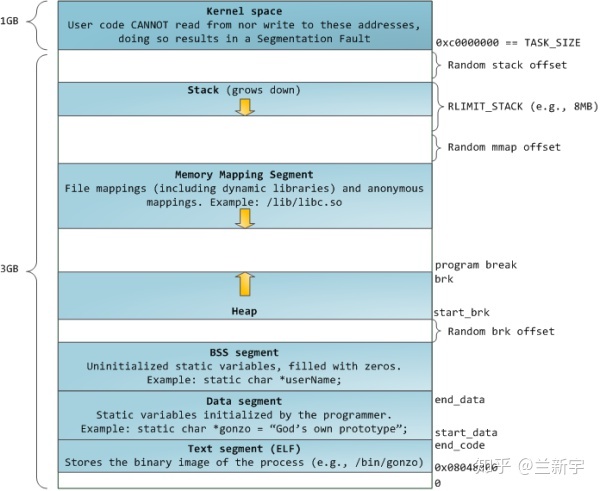
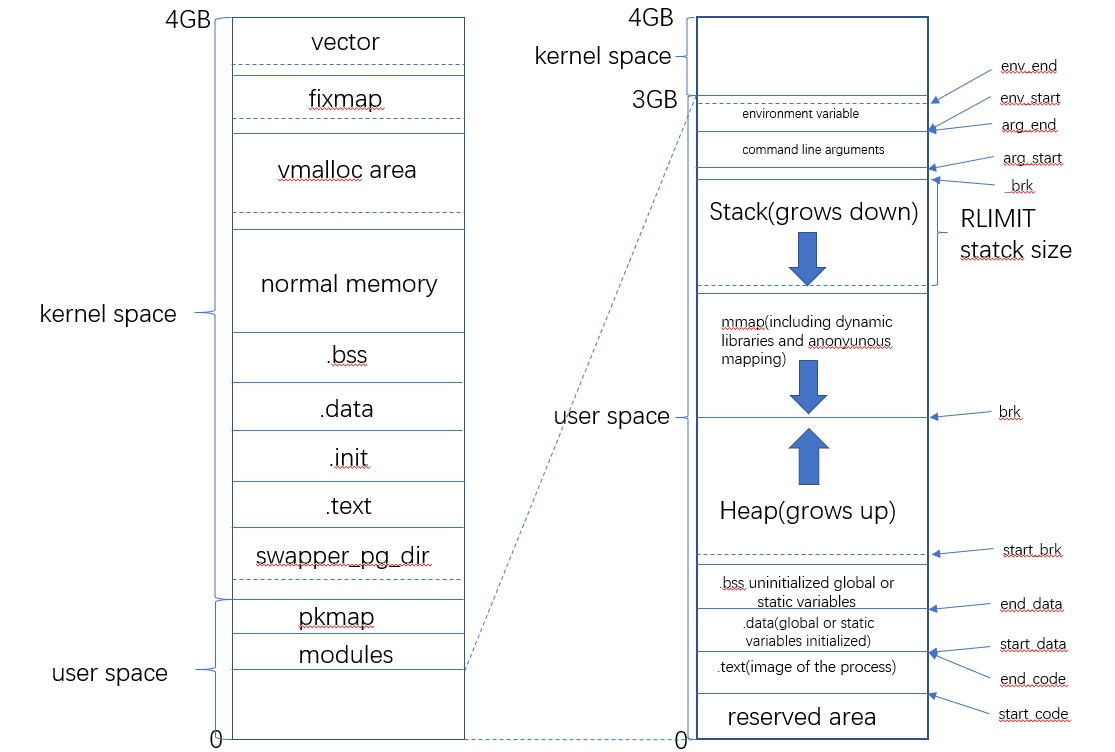
text段包含了当前运行进程的二进制代码,其起始地址在IA32体系中中通常为0x08048000,在IA64体系中通常为0x0000000000400000(都是虚拟地址哈)。data段存储已初始化的全局变量,bss段存储未初始化的全局变量。从上图可以看出,这3个segments是紧挨者的,因为它们的大小是确定的,不会动态变化。
与之相对应的就是heap段和stack段。heap段存储动态分配的内存中的数据,stack段用于保存局部变量和实现函数/过程调用的上下文,它们的大小都是会在进程运行过程中发生变化的,因此中间留有空隙,heap向上增长,stack向下增长,因为不知道heap和stack哪个会用的多一些,这样设置可以最大限度的利用中间的空隙空间。
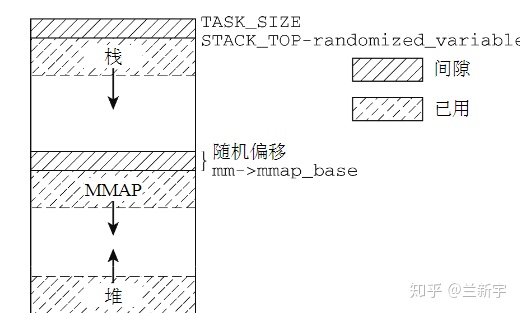
还有一个段比较特殊,是mmap()系统调用映射出来的。mmap映射的大小也是不确定的。3GB的虚拟地址空间已经很大了,但heap段, stack段,mmap段在动态增长的过程还是有重叠(碰撞)的可能。为了避免重叠发生,通常将mmap映射段的起始地址选在TASK_SIZE/3(也就是1GB)的位置。如果是64位系统,则虚拟地址空间更加巨大,几乎不可能发生重叠。
如果stack段和mmap段都采用固定的起始地址,这样实现起来简单,而且所有Linux系统都能保持统一,但是真实的世界不是那么简单纯洁的,正邪双方的较量一直存在。对于攻击者来说,如果他知道你的这些segments的起始地址,那么他构建恶意代码(比如通过缓冲区溢出获得栈内存区域的访问权,进而恶意操纵栈的内容)就变得容易了。
一个可以采用的反制措施就是不为这些segments的起点选择固定位置,而是在每次新进程启动时(通过设置PF_RANDOMIZE标志)随机改变这些值的设置。
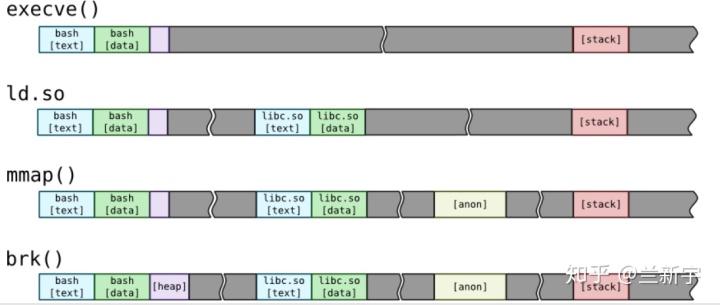
那这些segments的加载顺序是怎样的呢?以下图为例,首先通过execve()执行elf,则该可执行文件的text段,data段,stack段就建立了,在进程运行过程中,可能需要借助ld.so加载动态链接库,比如最常用的libc,则libc.so的text段,data段也建立了,而后可能通过mmap()的匿名映射来实现与其他进程的共享内存,还有可能通过brk()来扩大heap段的大小。
vm_area_struct
在Linux中,每个segment用一个vm_area_struct(以下简称vma)结构体表示。vma是通过一个双向链表(早期的内核实现是单向链表)串起来的,现存的vma按起始地址以递增次序被归入链表中,每个vma是这个链表里的一个节点。
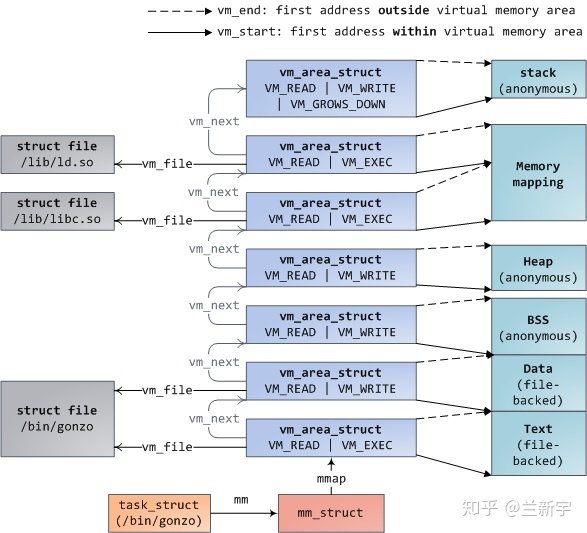
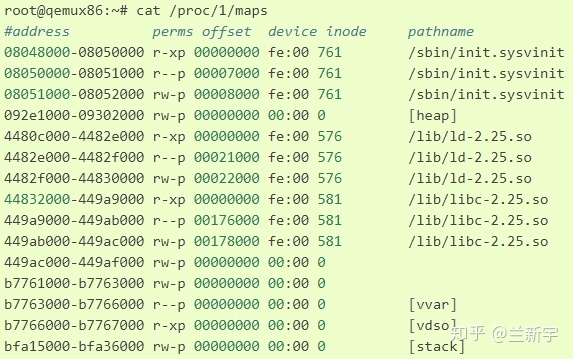
在用户空间可通过"/proc/PID/maps"接口来查看一个进程的所有vma在虚拟地址空间的分布情况,其内部实现靠的就是对这个链表的遍历。
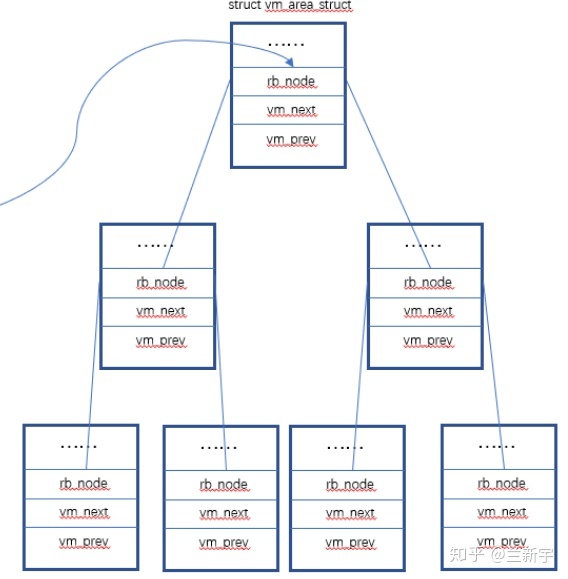
同时,vma又通过红黑树(red black tree)组织起来,每个vma又是这个红黑树里的一个节点。为什么要同时使用两种数据结构呢?使用链表管理固然简单方便,但是通过查找链表找到与特定地址关联的vma,其时间复杂度是O(N),而现实应用中,在进程地址空间中查找vma又是非常频繁的操作(比如发生page fault的时候)。
使用红黑树的话时间复杂度是O(
现在我们来看一下vm_area_struct结构体在Linux中是如何定义的(这里为了讲解的需要对结构体内元素的分布有所调整,事实上,结构体元素的分布是有讲究的,将相关的元素相邻放置并按cache line对齐,有利于它们在cache中处于同一条cache line上,提高效率):
struct vm_area_struct
{
unsigned long vm_start;
unsigned long vm_end;
struct vm_area_struct *vm_next, *vm_prev;
rb_node_t vm_rb;
unsigned long vm_flags;
struct file * vm_file;
unsigned long vm_pgoff;
struct mm_struct * vm_mm;
...
}其中,vm_start和vm_end分别是这个vma所指向区域的起始地址和结束地址,虽然vma是虚拟地址空间,但最终毕竟是要映射到物理内存上去的,所以也要求是4KB对齐的。
vm_next是指向链表的下一个vma,vm_rb是作为红黑树的一个节点。
vm_flags描述的是vma的属性,flag可以是VM_READ、VM_WRITE、VM_EXEC、VM_SHARED,分别指定vma的内容是否可以读、写、执行,或者由几个进程共享。前面介绍的页表PTE中也有类似的Read/Write权限限制位,那它和vma中的这些标志位是什么关系呢?
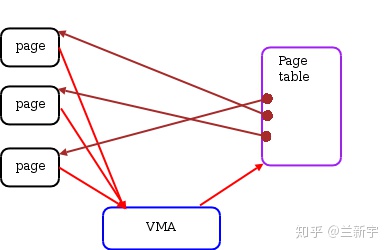
vma由许多的虚拟pages组成,每个虚拟page需要经过page table的转换才能找到对应的物理页面。PTE中的Read/Write位是由软件设置的,设置依据就是这个page所属的vma,因此一个vma设置的VM_READ/VM_WRITE属性会复制到这个vma所含pages的PTE中。
之后,硬件MMU就可以在地址翻译的过程中根据PTE的标志位来检测访问是否合法,这也是为什么PTE是一个软件实现的东西,但又必须按照处理器定义的格式去填充,这可以理解为软硬件之间的一种约定。那可以用软件去检测PTE么?当然可以,但肯定没有用专门的硬件单元来处理更快嘛。
可执行文件和动态链接库的text段和data段是基于elf文件的,mmap对文件的映射也是对应外部存储介质中这个被映射的文件的,这两种情况下,vm_file指向这个被映射的文件,进而可获得该文件的inode信息,而"vm_pgoff"是这个段在该文件内的偏移。
对于text段,一般偏移就是0。对于heap段,stack段以及mmap的匿名映射,没有与之相对应的文件实体,此时"vm_file"就为NULL,"vm_pgoff"的值没有意义。
那一个进程是怎么找到它的这些vma的呢?请看下文分解。
参考:
How The Kernel Manages Your Memory
原创文章,转载请注明出处。
智能推荐
!! 浅谈Java学习方法和后期面试技巧-程序员宅基地
文章浏览阅读61次。浅谈Java学习方法和后期面试技巧昨天查看3303回复33部落用户大酋长下面简单列举一下大家学习java的一个系统知识点的一些介绍一、java基础部分:java基础的时候,有些知识点是非常重要的,比如循环系列。For,while,do-while.这方面只要大家用心点基本没什么难点。二、面向对象:oop面向对象的时候,偏重理...
Silverlight完全自定义DataPager-程序员宅基地
文章浏览阅读39次。silverlight 提供的控件虽然都好用 但是通常都会有默认模板样式 有些模板样式在中国人看来肯定不是很好看所以又时候 有必要修改下再使用 今天我就遇到DataPager的模板样式问题 我觉得自带的不怎么好看在网上查了下 还没有什么好的例子 那我就分享下我自己的例子 大神们见谅哦!先上图感觉这个看着换可以吧 你们如果要用可以自己再修改下首先引入命名空间...
iOS中XML的相关知识-程序员宅基地
文章浏览阅读47次。 1.什么是XML “当 XML(扩展标记语言)于 1998 年 2 月被引入软件工业界时,它给整个行业带来了一场风暴。有史以来第一次,这个世界拥有了一种用来结构化文档和数据的通用且适应性强的格式,它不仅仅可以用于 WEB,而且可以被用于任何地方。”---《Designing With Web Standards Second Edition》, Jeffrey Zeldman...
MFC WinInetHttp抓取网页代码内容-程序员宅基地
文章浏览阅读84次。Windows Internet编程主要包括两方面: l 服务器端 l 客户端WinInet编程 Internet客户端主要实现的功能,主要是通过Internet协议(HTTP、FTP等)获取网络数据源(服务器)的信息。如,客户端可以访问服务器,获得天气预报、股票加个、新闻数据等信息。 MFC为Internet客户端程序提供了专门的W..._wininet函数获取网页的内容
Android Retrofit通过OkHttp设置Interceptor拦截器统一打印请求报文及返回报文_android retrofit chain.request()-程序员宅基地
文章浏览阅读4.6k次,点赞4次,收藏5次。我们先定义一个打印报文的拦截器,继承Interceptorpublic class LogInterceptor implements Interceptor { private static final String TAG = LogInterceptor.class.getSimpleName(); @Override public Response int..._android retrofit chain.request()
java.lang.NoClassDefFoundError类似这种错误catch expection是捕获不到的异常-程序员宅基地
文章浏览阅读436次。https://blog.csdn.net/weixin_40648117/article/details/80819972一 概念众所周知java提供了丰富的异常类,这些异常类之间有严格的集成关系,分类为父类ThrowableThrowable的两个子类Error和ExceptionException的两个子类CheckedException和RuntimeException二 ..._java.lang.noclassdeffounderror: 这类报错能否try catch解决
随便推点
FPGA基础学习(7) -- 内部结构之CLB-程序员宅基地
文章浏览阅读427次。目录 1. 总览 2. 可配置逻辑单元 2.1 6输入查找表(LUT6) 2.2 选择器(MUX) 2.3 进位链(Carry Chain) 2.4 触发器(Flip-Flop) 参考文献: 一直以来,..._使用最小数目的6输入查找表lut6实现16-to-1mux复用
神经网络和深度学习-学习总结-程序员宅基地
文章浏览阅读942次。1. 简介 神经网络和深度学习是由Michael Nielsen所写,其特色是:兼顾理论和实战,是一本供初学者深入理解Deep Learning的好书。2. 感知器与sigmoid神经元2.1 感知器(Perceptrons) 感知器工作原理:接收一系列二进制输入,经过特定的规则计算之后,输出一个简单的二进制。 计算规则:通过引入权重(weights)表示每个输入对..._简述共享权重的优点
cxf Webservice 使用httpClient 调用-程序员宅基地
文章浏览阅读52次。package com.wistron.wh.swpc.portal.uitl;import java.io.BufferedInputStream;import java.io.File;import java.io.FileInputStream;import java.io.IOException;import org.apache.http.HttpEntity;import org....
https证书pfx 生成 pem,crt,key-程序员宅基地
文章浏览阅读273次。(1)将.pfx格式的证书转换为.pem文件格式:openssl pkcs12 -in xxx.pfx -nodes -out server.pem(2)从.pem文件中导出私钥server.key:openssl rsa -in server.pem -out server.key(3)从.pem文件中导出证书server.crt opens..._有了crt和pfx怎么生产key和pem
【2017.11.29 周三 转载之李航博士的文章:李航图灵访谈】-程序员宅基地
文章浏览阅读135次。原文地址:http://www.ituring.com.cn/article/196610李航,华为技术有限公司诺亚方舟实验室主任,北京大学、南京大学兼职教授。他日本京都大学电气电子工程系毕业,日本东京大学获得计算机科学博士学位。曾就职于日本NEC公司中央研究所,任研究员,以及微软亚洲研究院,任高级研究员与主任研究员。李航博士的研究方向包括信息检索,自然语言处理,统计机器学..._智能仪器 李航博士的论文
.NET中使用APlayer组件自制播放器-程序员宅基地
文章浏览阅读92次。.NET中使用APlayer组件自制播放器 原文:.NET中使用APlayer组件自制播放器目录说明APlayer介绍APlayer具备功能APlayer使用自制播放器Demo未完成工作源码下载说明由于需求原因,需要在项目中(桌面程序)集成一个在线播放视频的功能。大概要具备“流式”边下载边播放的..._.net播放视频组件