mysql查询各科成绩前三名的记录_mysql巧用连表查询各科成绩前三名-程序员宅基地
技术标签: mysql查询各科成绩前三名的记录
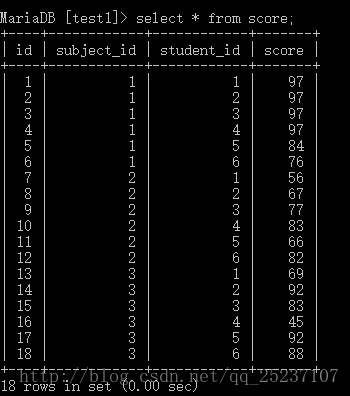
下列是各表的详情,不想自己建表的同学可以直接copy code,数据随意。
创建表成绩详情表:
CREATE TABLE score (
id int(10) NOT NULL AUTO_INCREMENT,
subject_id int(10) DEFAULT NULL,
student_id int(10) DEFAULT NULL,
score float DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=19 DEFAULT CHARSET=utf8;
创建学生表:
CREATE TABLE student (
id int(10) NOT NULL AUTO_INCREMENT,
name varchar(10) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;

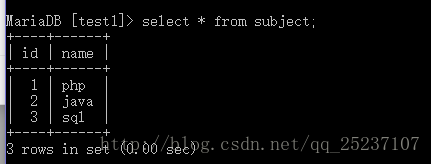
创建科目表:
CREATE TABLE subject (
id int(10) NOT NULL AUTO_INCREMENT,
name varchar(10) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
查询语句:
select a.id,a.subject_id,a.student_id,a.score from score as a left join score as b on a.subject_id=b.subject_id and a.score>=b.score
group by a.subject_id,a.student_id,a.score
having count(a.subject_id)>=4
order by a.subject_id,a.score desc;
分析:先将查询语句分别拆开来一步一步分析
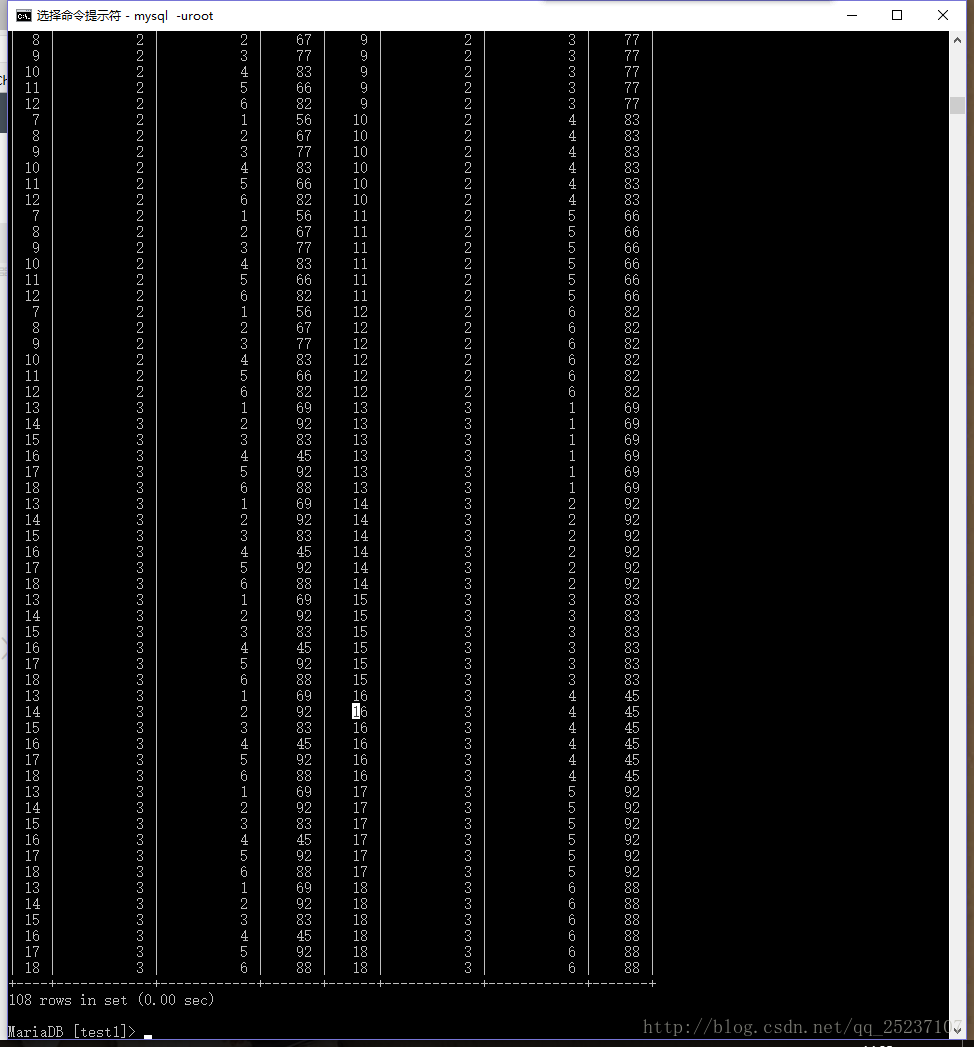
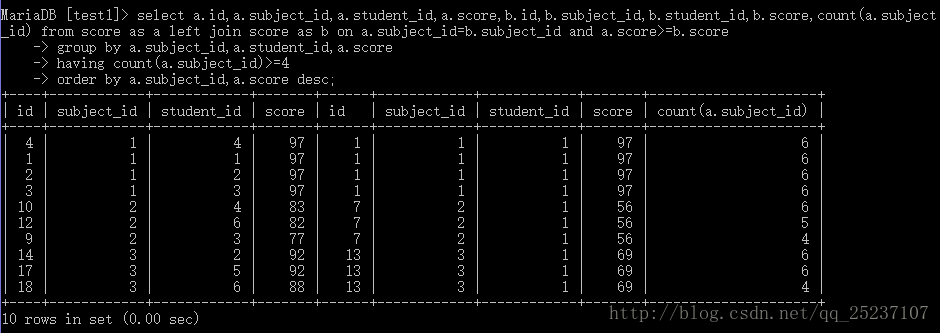
select a.id,a.subject_id,a.student_id,a.score,b.id,b.subject_id,b.student_id,b.score
from score as a left join score as b on a.subject_id=b.subject_id;
#这里把所有的列都列出来了便于对比
这里把表score的每一条同subject_id的数据都连接起来,形成笛卡尔积,如图所示:共18*6=108条数据
现在我们可以再进一步处理上面的数据了。这里我们再加上 a.score>=b.score 这个条件筛选再进行一次筛选。
select a.id,a.subject_id,a.student_id,a.score,b.id,b.subject_id,b.student_id,b.score
from score as a left join score as b on a.subject_id=b.subject_id and a.score>=b.score;
a.score>=b.score 这里是在同一门课程中,将每一个分数与其他分数(包括自己)进行一一对比,只留下大于自己,或者等于自己的分数。
如果选择对比的行中的a.score是最高分,那么在后面利用group by a.subject_id,a.student_id,a.score分组的时候,此时计算得出的count(a.subject_id)就是最多的(count为总人数),因为其它的分数最多也只是和它一样多,其它的都比它低;同理,如果a.score是最低分,那么count(a.subject_id)是最少的(count最少为1,只有它自己,其余分数都比它高;最多为总人数,这种情况是其它人的分数都和最低分一样多...),其它的分数最差也和它一样多,其它的都比它要高。例如:
100分是最高的,所以几乎其他所有分数都符合100>=其他分数 这个条件,所以100分出现次数最多(count为总人数)
0分,是最低分,几乎其他所有分数都不符合0>=其他分数这个条件,所以0分出现的次数应该是最少的(count最少为1;最多为总人数,此时其他的分数也都是最低分,即大家分数一样低)
有同学可能会问为什么不用a.score > b.score来筛选。如果用a.score > b.score来进行筛选的话,如果数据中某个科目出现大量的并列第一名的话那么第一名就会被过滤掉,以至于得不到结果。如图:

接下来就是分组:group by a.subject_id,a.student_id,a.score #按subject_id,student_id,score来进行分组
(这里使用group by a.subject_id,a.student_id,a.score和使用group by a.subject_id,a.student_id一样的,因为两表左连接之后,不可能出现相同的a.subject_id,a.student_id有多条不同的a.score的记录;因为同一个同学a.student_id,同一个科目a.subject_id,只能有一个分数a.score,一个同学不可能一个科目有多个不同的分数);
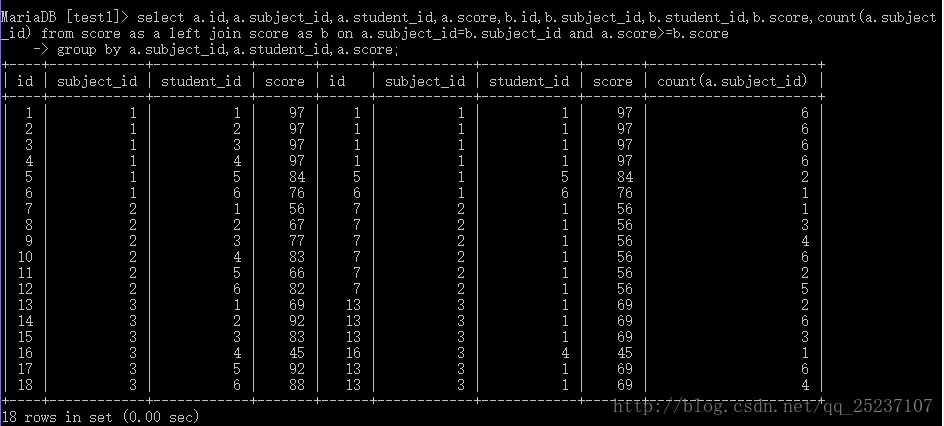
select a.id,a.subject_id,a.student_id,a.score,b.id,b.subject_id,b.student_id
b.score,count(a.subject_id) from score as a left join score as b
on a.subject_id=b.subject_id and a.score>=b.score group by a.subject_id,a.student_id,a.score;
添加count(a.subject_id)来进行对比易于理解
分组后再进行条件查询:having count(a.subject_id)>=4;
下面来讨论下>=4是什么含义:正常来说,如果每门课程的各个同学的分数都不一样,那么同一门课程中从最高分到最低分的count(a.subject_id) 分别为:6,5,4,3,2,1;取count>=4就是取6,5,4即取count最多的三个,所以取出的数据就是排名前三(count从高到低,取前三,那么就是前三甲的记录):
接下来就是排序:order by a.subject_id,a.score desc。
智能推荐
记录Linux安装Oracle19c_debian 安装 oracle19c-程序员宅基地
文章浏览阅读712次。最近单位要求本渣学习服务器脚本编写完成定点市级机构下发的数据库表导入项目服务器数据库,按工作顺序就先打算在自己笔记本电脑上通过虚拟机来模拟生产环境,部署虚拟环境后安装Linux版本Oracle19c数据库。经过数天研究终完成安装,记录如下。安装准备:1、虚拟软件 Oracle VM VirtualBox2、镜像 CentOS-7-x86_64-Minimal-2009.iso3、Xshell 7.04、Xftp 7.05、Xmanager Enterprise 56、LINUX._debian 安装 oracle19c
Halcon分类器之高斯混合模型分类器_训练高斯混合模型分类器-程序员宅基地
文章浏览阅读2k次,点赞2次,收藏20次。Halcon分类器示例自我理解看了很多网上的例子,总有一种纸上得来终觉浅,绝知此事要躬行的感觉。说干就干,将Halcon自带分类器例子classify_metal_parts.hdev按照自己的理解重新写一遍,示例中的分类器是MLP(多层感知机),我将它改变为GMM(高斯混合模型)。希望可以帮助刚入门的同学学习理解,大神请绕路吧,当然也喜欢各位看官帮我找出不足之处,共同进步。谢谢!分类效果如图..._训练高斯混合模型分类器
Office转PDF工具类_"officetopdf.wordtopdf(\"d:\\\\1234.doc\", \"d:\\\-程序员宅基地
文章浏览阅读819次。使用Jacob转换office文件,Jacob.dll文件需要放到jdk\bin目录下Jacob.dll文件下载地址https://download.csdn.net/download/zss0101/10546500package com.zss.util;import java.io.File;import com.jacob.activeX.ActiveXComponent;..._"officetopdf.wordtopdf(\"d:\\\\1234.doc\", \"d:\\\\1234.pdf\");"
redis实现队列_redistemplate convertandsend方法实现队列-程序员宅基地
文章浏览阅读1k次,点赞30次,收藏30次。上面的例子我们已经了一个简易的消息队列。我们继续思考一个现实的场景,假定这些是一些游戏商品,它需要添加"延迟销售"特性,在未来某个时候才可以开始处理这些游戏商品数据。那么要实现这个延迟的特性,我们需要修改现有队列的实现。在消息数据的信息中包含延迟处理消息的执行时间,如果工作进程发现消息的执行时间还没到,那么它将会在短暂的等待之后重新把消息数据推入队列中。(延迟发送消息)_redistemplate convertandsend方法实现队列
java基础-程序员宅基地
文章浏览阅读287次,点赞5次,收藏5次。java基础篇
使用gparted对linux根目录扩容(windows+linux双系统)_双系统linux扩容-程序员宅基地
文章浏览阅读298次。linux扩容根目录与/home_双系统linux扩容
随便推点
Python使用pika调用RabbitMQ_python pika 通过主机名称来访问mq-程序员宅基地
文章浏览阅读388次。定义RabbitMQ类import jsonimport osimport sysimport pikafrom Data import Datafrom MongoDB import MongoDBfrom constants import *class RabbitMQ: def __init__(self, queue_name): """ 初始化队列对象 :param queue_name: 队列名称 "_python pika 通过主机名称来访问mq
Python利用openpyxl处理excel文件_在 python 中可以通過 openpyxl 套件來很好的操作 excel 讀寫-程序员宅基地
文章浏览阅读568次。**openpyxl简介**openpyxl是一个开源项目,openpyxl模块是一个读写Excel 2010文档的Python库,如果要处理更早格式的Excel文档,需要用到其它库(如:xlrd、xlwt等),这是openpyxl比较其他模块的不足之处。openpyxl是一款比较综合的工具,不仅能够同时读取和修改Excel文档,而且可以对Excel文件内单元格进行详细设置,包括单元格样式等内容,甚至还支持图表插入、打印设置等内容,使用openpyxl可以读写xltm, xltx, xlsm, xls_在 python 中可以通過 openpyxl 套件來很好的操作 excel 讀寫
Unity判断某个物体是否在某个规定的区域_unity判断物体在范围内-程序员宅基地
文章浏览阅读1.4w次,点赞7次,收藏56次。Unity自带的两种写法:①物体的位置是否在某个区域内Vector3 pos = someRenderer.transform.position;Bounds bounds = myBoxCollider.bounds;bool rendererIsInsideTheBox = bounds.Contains(pos);②物体的矩形与区域的矩形是否交叉Bounds rendererBo..._unity判断物体在范围内
[深度学习] 使用深度学习开发的循线小车-程序员宅基地
文章浏览阅读295次,点赞6次,收藏4次。报错:Unable to find image 'openexplorer/ai_toolchain_centos_7_xj3:v2.3.3' locally。报错: ./best_line_follower_model_xy.pth cannot be opened。可以看到生成的文件 best_line_follower_model_xy.pth。报错:Module onnx is not installed!安装onox,onnxruntime。这是由于没有文件夹的写权限。
MDB-RS232测试NAYAX的VPOS刷卡器注意事项-程序员宅基地
文章浏览阅读393次,点赞10次,收藏8次。MDB-RS232测试NAYAX的VPOS非现金MDB协议刷卡器注意事项
Pytorch和Tensorflow,谁会笑到最后?-程序员宅基地
文章浏览阅读2.5k次。作者 |土豆变成泥来源 |知秋路(ID:gh_4a538bd95663)【导读】作为谷歌tensorflow某项目的Contributor,已经迅速弃坑转向Pytorch。目前Ten..._pytorch与tensorflow