数据结构之图结构_数据结构图结构-程序员宅基地
10.图
图基本介绍
为什么要有图
- 前面我们学了线性表和树
- 线性表局限于一个直接前驱和一个直接后继的关系
- 树也只能有一个直接前驱也就是父节点
- 当我们需要表示多对多的关系时, 这里我们就用到了图。
图的举例说明
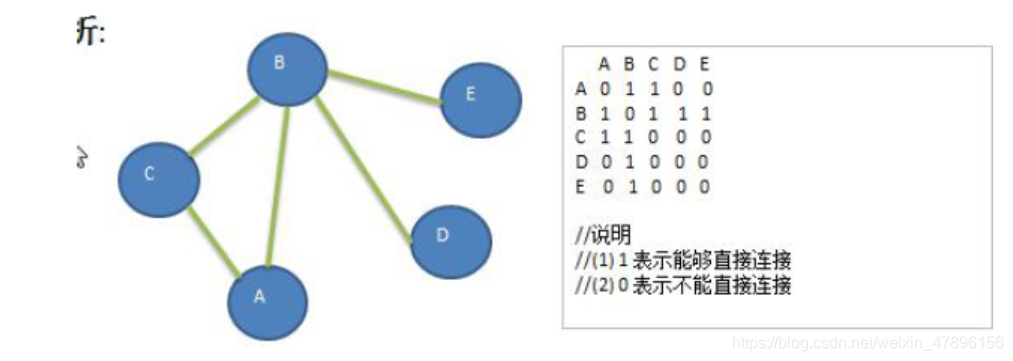
图是一种数据结构,其中结点可以具有零个或多个相邻元素。两个结点之间的连接称为边。结点也可以称为
顶点。如图:
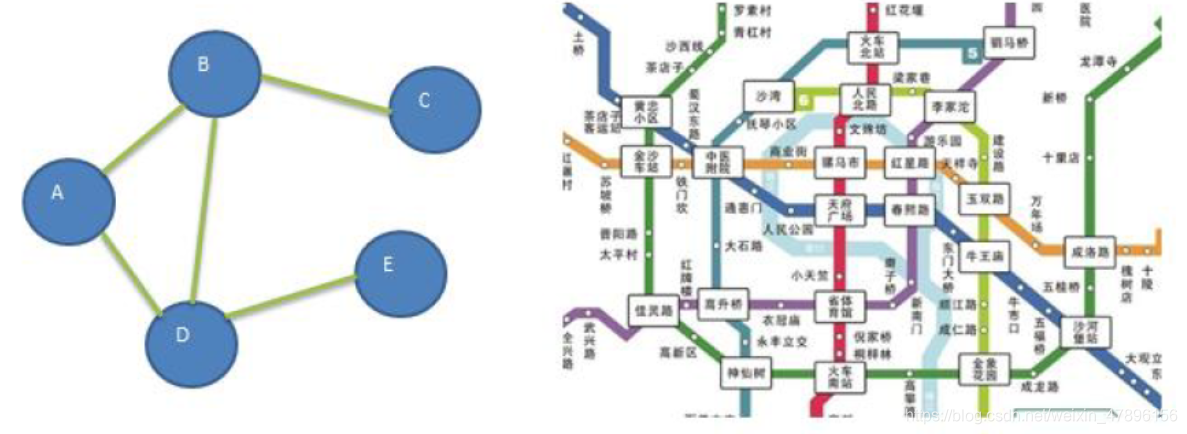
图的常用概念
1) 顶点(vertex)
2) 边(edge)
3) 路径
4) 无向图(右图
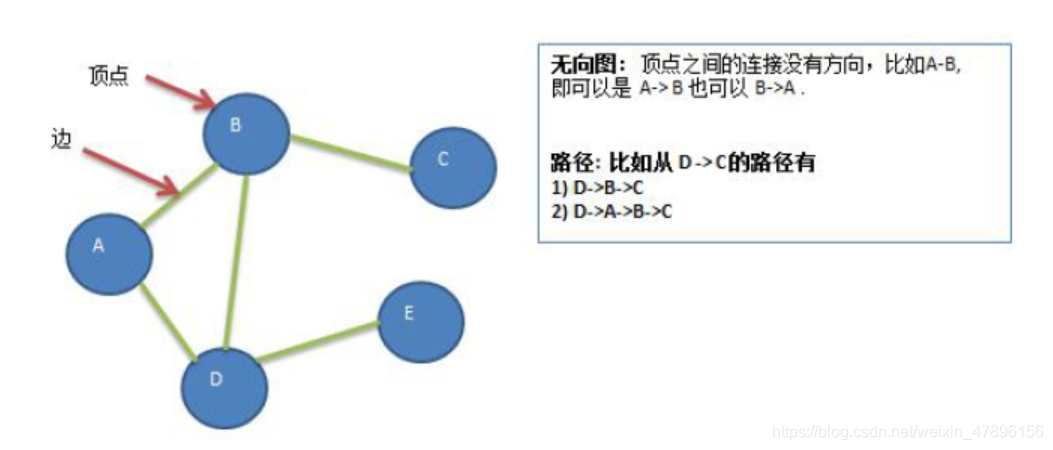
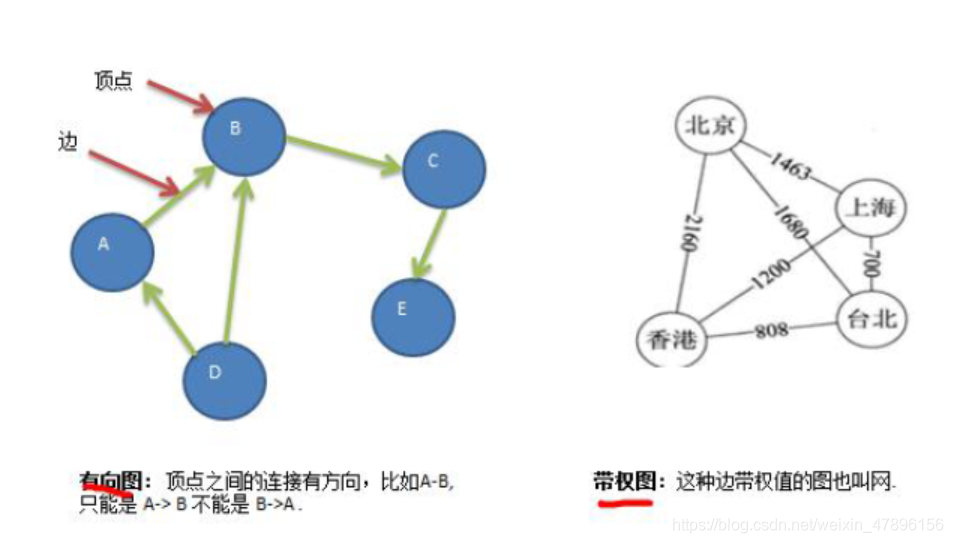
5) 有向图
6) 带权图
图的表示方式
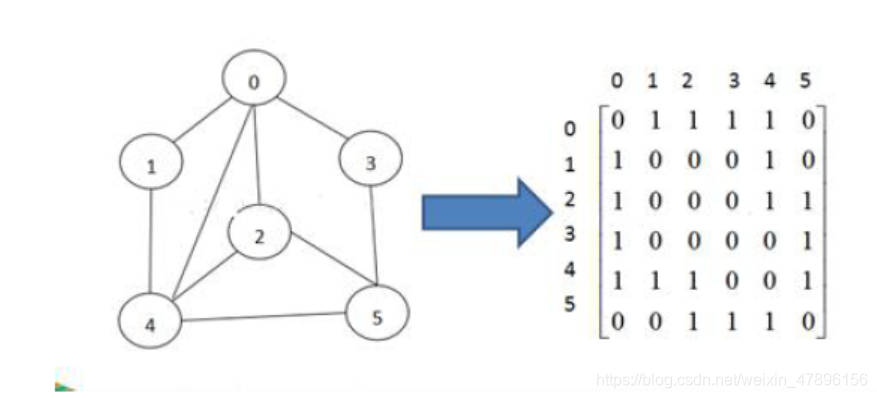
图的表示方式有两种:二维数组表示(邻接矩阵);链表表示(邻接表)。
邻接矩阵
V邻接矩阵是表示图形中顶点之间相邻关系的矩阵,对于n 个顶点的图而言,矩阵是的row 和col 表示的是1…n个点。
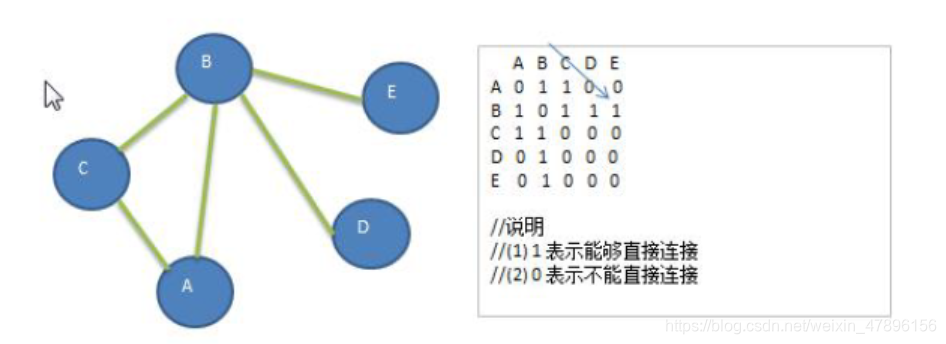
邻接表
- 邻接矩阵需要为每个顶点都分配n 个边的空间,其实有很多边都是不存在,会造成空间的一定损失.
- 邻接表的实现只关心存在的边,不关心不存在的边。因此没有空间浪费,邻接表由数组+链表组成
- 举例说明
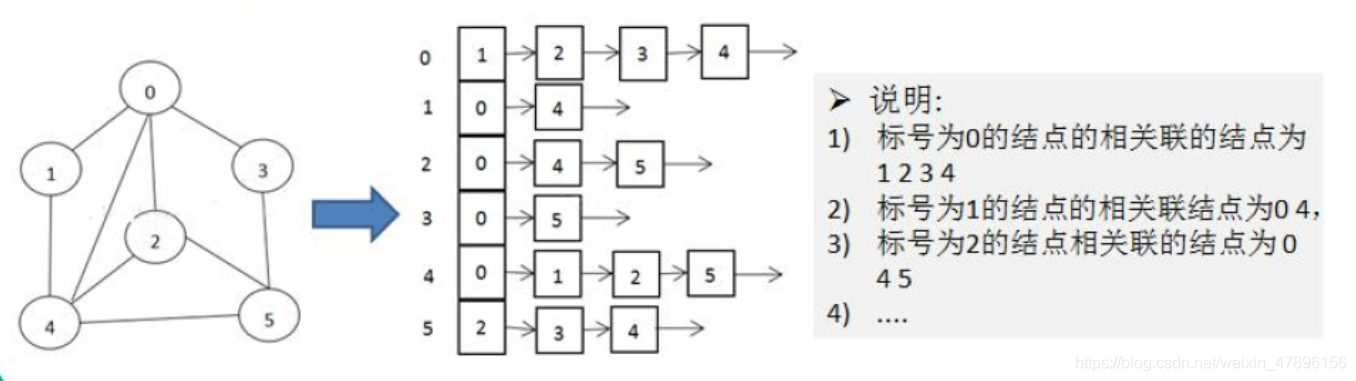
图的快速入门案例
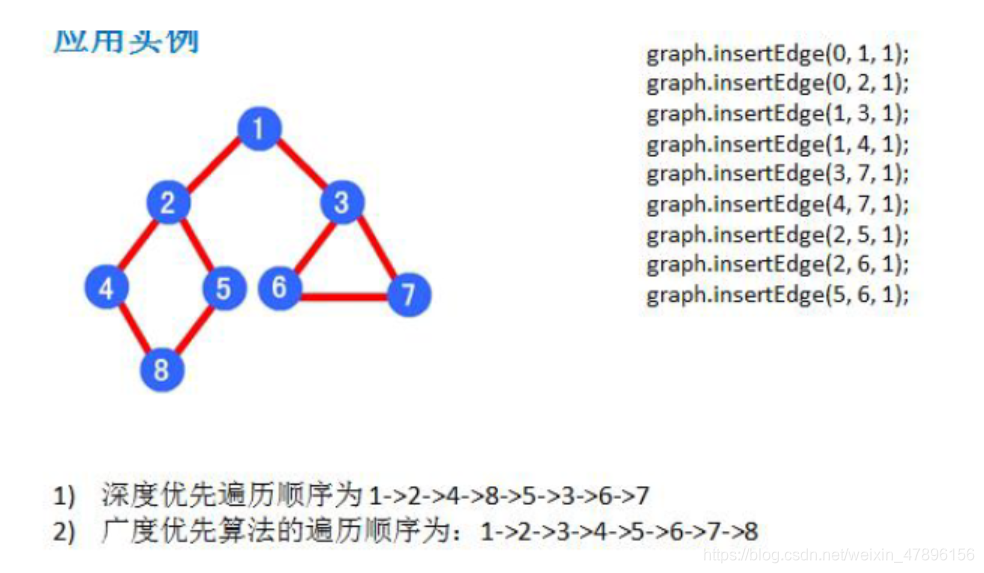
- 要求: 代码实现如下图结构.
- 思路分析(1) 存储顶点String 使用ArrayList (2) 保存矩阵int[][] edges
代码实现
//插入结点
public void insertVertex(String vertex){
vertexList.add(vertex);
}
//添加边
/**
*
* @param v1 表示点下标即是第几个顶点 "A" - "B" "A" -> 0 "B" -> 1
* @param v2 第二个顶点对应的下标
* @param weight 表示
*/
public void insertEdge(int v1,int v2,int weight){
edges[v1][v2] = weight;
edges[v2][v1] = weight;
numOfEdges++;
}
图的深度优先遍历介绍
图遍历介绍
所谓图的遍历,即是对结点的访问。一个图有那么多个结点,如何遍历这些结点,需要特定策略,一般有两种访问策略: (1)深度优先遍历(2)广度优先遍历
深度优先遍历基本思想
图的深度优先搜索(Depth First Search) 。
- 深度优先遍历,从初始访问结点出发,初始访问结点可能有多个邻接结点,深度优先遍历的策略就是首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接结点, 可以这样理解:每次都在访问完当前结点后首先访问当前结点的第一个邻接结点。
- 我们可以看到,这样的访问策略是优先往纵向挖掘深入,而不是对一个结点的所有邻接结点进行横向访问。
- 显然,深度优先搜索是一个递归的过程
深度优先遍历算法步骤
- 访问初始结点v,并标记结点v 为已访问。
- 查找结点v 的第一个邻接结点w。
- 若w 存在,则继续执行4,如果w 不存在,则回到第1 步,将从v 的下一个结点继续。
- 若w 未被访问,对w 进行深度优先遍历递归(即把w 当做另一个v,然后进行步骤123)。
- 查找结点v 的w 邻接结点的下一个邻接结点,转到步骤3。
- 分析图
深度优先算法的代码实现
//深度优先遍历算法 //i 第一次就是0 public void dfs(boolean[] isVisited,int i){ //首先我们访问该节点,输出 System.out.print(getValueByIndex(i) + "->"); //将节点设置为已经访问 isVisited[i] = true; //查找节点i的第一个邻接结点 int w = getFirstNeighbor(i); while (w != -1){ //说明有 if (!isVisited[w]){ dfs(isVisited, w); } //如果w结点已经被访问过 w = getNextNeighbor(i,w); } } //对dfs 进行一个重载,遍历我们所有的结点,并进行dfs public void dfs(){ isVisited = new boolean[vertexList.size()]; //遍历所有的结点,进行dfs[回溯] for (int i = 0; i < getNUmOfVertex(); i++) { if (!isVisited[i]){ dfs(isVisited,i); } } }图的广度优先遍历
广度优先遍历基本思想
- 图的广度优先搜索(Broad First Search) 。
- 类似于一个分层搜索的过程,广度优先遍历需要使用一个队列以保持访问过的结点的顺序,以便按这个顺序来
访问这些结点的邻接结点广度优先遍历算法步骤
访问初始结点v 并标记结点v 为已访问。
结点v 入队列
当队列非空时,继续执行,否则算法结束。
出队列,取得队头结点u。
查找结点u 的第一个邻接结点w。
若结点u 的邻接结点w 不存在,则转到步骤3;否则循环执行以下三个步骤:
6.1 若结点w 尚未被访问,则访问结点w 并标记为已访问。
6.2 结点w 入队列
6.3 查找结点u 的继w 邻接结点后的下一个邻接结点w,转到步骤6。广度优先算法的图示
广度优先算法的代码实现
//对一个结点进行广度优先遍历的方法 private void bfs(boolean[] isVisited,int i){ int u;//表示队列的头结点对应下标 int w;//邻接结点w //队列,记录结点访问的顺序 LinkedList queue = new LinkedList(); //访问结点,输出节点信息 System.out.print(getValueByIndex(i)+"=>"); //标记为已访问 isVisited[i] = true; //将结点加入队列 queue.addLast(i);//队列从尾部加入 while (! queue.isEmpty()){ //取出队列的头结点下标 u = (Integer) queue.removeFirst(); //得到第一个邻接点的下标w w = getFirstNeighbor(u); while (w != -1){ //找到 //是否访问过 if(!isVisited[w]){ System.out.print(getValueByIndex(w) + "=>"); //标记已经访问 isVisited[w] = true; //入队 queue.addLast(w); } //以u为前驱点,找w后面的下一个邻接结点 w = getNextNeighbor(u,w);//体现出我们的广度优先 } } } //遍历所有的结点,都进行广度优先搜索 public void bfs(){ isVisited = new boolean[vertexList.size()]; for (int i = 0; i < getNUmOfVertex(); i++) { if (!isVisited[i]){ bfs(isVisited,i); } } }
图的代码汇总
/**
* @author xiaososa
* @date 2021/1/7
**/
public class Graph {
private ArrayList<String> vertexList;//存储顶点集合
private int[][] edges;//存储图对应的邻接矩阵
private int numOfEdges;//表示边的数目
//定义一个数组boolean[],记录某个节点是否被访问
private boolean[] isVisited;
public static void main(String[] args) {
//测试一把图是否创建ok
int n = 8;//结点的个数
//String Vertexs[] ={"A","B","C","D","E"};
String Vertexs[] ={
"1","2","3","4","5","6","7","8"};
//创建图对象
Graph graph = new Graph(n);
//循环的添加顶点
for (String vertex : Vertexs) {
graph.insertVertex(vertex);
}
//添加边
//A-B A-C B-C B-D B-E
// graph.insertEdge(0,1,1);//A-B
// graph.insertEdge(0,2,1);//
// graph.insertEdge(1,2,1);//
// graph.insertEdge(1,3,1);//
// graph.insertEdge(1,4,1);//
//更新边的关系
graph.insertEdge(0,1,1);
graph.insertEdge(0,2,1);
graph.insertEdge(1,3,1);
graph.insertEdge(1,4,1);
graph.insertEdge(3,7,1);
graph.insertEdge(4,7,1);
graph.insertEdge(2,5,1);
graph.insertEdge(2,6,1);
graph.insertEdge(5,6,1);
//显示一把邻接矩阵
graph.showGraph();
//测试一把我们的dfs遍历是否ok
System.out.println("深度遍历!");
graph.dfs();//1->2->4->8->5->3->6->7->
System.out.println();
System.out.println("广度优先遍历");
graph.bfs();
}
//构造器
public Graph(int n){
//初始化矩阵和vertexList
edges = new int[n][n];
vertexList = new ArrayList<String>(n);
numOfEdges = 0;
isVisited = new boolean[5];
}
//得到第一个邻接结点的下标w
/**
*
* @param index
* @return 如果存在就返回对应的下标,否则返回-1
*/
public int getFirstNeighbor(int index){
for (int j = 0; j < vertexList.size(); j++) {
if (edges[index][j] > 0){
return j;
}
}
return -1;
}
//根据前一个邻接结点的下标来获取下一个邻接结点
public int getNextNeighbor(int v1,int v2){
for (int j = v2 + 1; j < vertexList.size(); j++) {
if (edges[v1][j] > 0){
return j;
}
}
return -1;
}
//深度优先遍历算法
//i 第一次就是0
public void dfs(boolean[] isVisited,int i){
//首先我们访问该节点,输出
System.out.print(getValueByIndex(i) + "->");
//将节点设置为已经访问
isVisited[i] = true;
//查找节点i的第一个邻接结点
int w = getFirstNeighbor(i);
while (w != -1){
//说明有
if (!isVisited[w]){
dfs(isVisited, w);
}
//如果w结点已经被访问过
w = getNextNeighbor(i,w);
}
}
//对dfs 进行一个重载,遍历我们所有的结点,并进行dfs
public void dfs(){
isVisited = new boolean[vertexList.size()];
//遍历所有的结点,进行dfs[回溯]
for (int i = 0; i < getNUmOfVertex(); i++) {
if (!isVisited[i]){
dfs(isVisited,i);
}
}
}
//对一个结点进行广度优先遍历的方法
private void bfs(boolean[] isVisited,int i){
int u;//表示队列的头结点对应下标
int w;//邻接结点w
//队列,记录结点访问的顺序
LinkedList queue = new LinkedList();
//访问结点,输出节点信息
System.out.print(getValueByIndex(i)+"=>");
//标记为已访问
isVisited[i] = true;
//将结点加入队列
queue.addLast(i);//队列从尾部加入
while (! queue.isEmpty()){
//取出队列的头结点下标
u = (Integer) queue.removeFirst();
//得到第一个邻接点的下标w
w = getFirstNeighbor(u);
while (w != -1){
//找到
//是否访问过
if(!isVisited[w]){
System.out.print(getValueByIndex(w) + "=>");
//标记已经访问
isVisited[w] = true;
//入队
queue.addLast(w);
}
//以u为前驱点,找w后面的下一个邻接结点
w = getNextNeighbor(u,w);//体现出我们的广度优先
}
}
}
//遍历所有的结点,都进行广度优先搜索
public void bfs(){
isVisited = new boolean[vertexList.size()];
for (int i = 0; i < getNUmOfVertex(); i++) {
if (!isVisited[i]){
bfs(isVisited,i);
}
}
}
//图中常用的方法
//返回结点的个数
public int getNUmOfVertex(){
return vertexList.size();
}
//显示图对应的矩阵
public void showGraph(){
for (int[] link : edges) {
System.out.println(Arrays.toString(link));
}
}
//得到边的数目
public int getNumofEdges(){
return numOfEdges;
}
//返回结点i(下标)对应的数据 0 -> "A" 1 -> "B" 2-> "C"
public String getValueByIndex(int i){
return vertexList.get(i);
}
//返回v1和v2的权值
public int getWeight(int v1,int v2){
return edges[v1][v2];
}
//插入结点
public void insertVertex(String vertex){
vertexList.add(vertex);
}
//添加边
/**
*
* @param v1 表示点下标即是第几个顶点 "A" - "B" "A" -> 0 "B" -> 1
* @param v2 第二个顶点对应的下标
* @param weight 表示
*/
public void insertEdge(int v1,int v2,int weight){
edges[v1][v2] = weight;
edges[v2][v1] = weight;
numOfEdges++;
}
}
图的深度优先VS 广度优先
智能推荐
C# XmlDocument处理XML元素节点_c# xml历遍所有节点-程序员宅基地
文章浏览阅读1.2k次。XmlDocument处理XML元素节点_c# xml历遍所有节点
【GRU回归预测】基于matlab凌日算法优化多头注意力机制卷积神经网络结合双向门控循环单元CGO-MultiAttention-CNN-BiGRU数据预测(多输入单输出)【含Matlab源码 401_自回归gru-程序员宅基地
文章浏览阅读904次,点赞21次,收藏22次。凌日算法优化多头注意力机制卷积神经网络结合双向门控循环单元CGO-MultiAttention-CNN-BiGRU数据预测(多输入单输出)完整的代码,方可运行;可提供运行操作视频!适合小白!_自回归gru
Matlab中Ksdensity()函数的用途_matlab ksdeshity什么意思-程序员宅基地
文章浏览阅读3k次。我们在统计数据处理时,经常计算一个样本的概率密度估计,也就是说给出一组统计数据,要求你绘制出它的概率分布曲线,matla..._matlab ksdeshity什么意思
USDT TRX ETH 自动归集_php 实现usdt自动归集功能-程序员宅基地
文章浏览阅读605次,点赞13次,收藏9次。在数字货币领域,多地址多资金自动归集系统用于集中管理和归集来自多个地址的资金,以提高操作效率和降低交易成本。在实际开发中,需要考虑更多的细节,例如事务处理、错误处理、日志管理等。此外,确保系统的安全性是至关重要的,采用最佳实践来保护用户的资金和数据。_php 实现usdt自动归集功能
C# 输入一个三位数的字符串,输出为三位数的整数,并输出百位、十位、和个位_输入三个数字字符,然后组成一个三位数输出-程序员宅基地
文章浏览阅读3.5k次。C# 输入一个三位数的字符串,输出为三位数的整数,并输出百位、十位、和个位以C# 语言编写,控制台应用程序运行代码运行_输入三个数字字符,然后组成一个三位数输出
十三、W5100S/W5500+RP2040之MicroPython开发<MQTT&新版OneNET示例>-程序员宅基地
文章浏览阅读1.7k次,点赞44次,收藏44次。在这个智能硬件和物联网时代,MicroPython和树莓派PICO正以其独特的优势引领着嵌入式开发的新潮流。MicroPython作为一种精简优化的Python 3语言,为微控制器和嵌入式设备提供了高效开发和简易调试的当我们结合WIZnet W5100S/W5500网络模块,MicroPython和树莓派PICO的开发潜力被进一步放大。这两款模块都内置了TCP/IP协议栈,使得在嵌入式设备上实现网络连接变得更加容易。无论是进行数据传输、远程控制,还是构建物联网应用,它们都提供了强大的支持。
随便推点
M1 mac 如何安装 centos 7_centos7苹果m系列-程序员宅基地
文章浏览阅读301次。需要使用特殊镜像哈,官网或国内的arch 镜像源不可安装。获取镜像源,抑或向群里的同道一起讨论,分享解决方案。用这个镜像源,如果上面的镜像过期,欢迎加V群。_centos7苹果m系列
ubuntu 为firefox 安装flash_player-程序员宅基地
文章浏览阅读44次。1、下载安装包install_flash_player_11_linux.i386.tar.gz;2、解压文件:$ tar -xvf install_flash_player_11_linux.i386.tar.gz;3、得到一个文件与一个目录:libflashplayer.so与usr;4、将以上两个对象移动到mozilla下的plugins(也许是)目录下:(其中tt1为..._ubuntu firefox显示flash player
解决‘GNN’中‘over—smoothing’问题(通俗易懂)_over-smoothing-程序员宅基地
文章浏览阅读4.6k次,点赞16次,收藏49次。轻松解决GNN中’over-smoothing‘问题,让读者不再为此问题困扰!!!!!_over-smoothing
支持NEON指令集的android编译设置_anddroid 配置libyuv neon指令集-程序员宅基地
文章浏览阅读7.7k次。支持NEON指令集的选择从ARMv7开始ARM提供高级单指令多数据 (SIMD) 扩展亦称 NEON 技术,它是一种由 ARM 开发的 64/128 位混合 SIMD 体系结构,可以提升多媒体和信号处理应用程序的性能。 NEON 作为处理器的一部分来实现,但是它拥有自己的执行管道,以及有别于 ARM_anddroid 配置libyuv neon指令集
民宿小程序源码搭建 酒店预订小程序源码 完整前后端+安装搭建教程_民宿酒店预订管理系统小程序-程序员宅基地
文章浏览阅读670次。分享一个民宿小程序源码搭建酒店预订小程序源码,含完整代码程序包和详细的安装搭建教程。系统为多用户,可以多商家入驻收入驻费用运营,可自用搭建民宿酒店小程序,在线订房管理。_民宿酒店预订管理系统小程序
JAVA新实战1:使用vscode+gradle+openJDK21搭建java springboot3项目开发环境_openjdk 21-程序员宅基地
文章浏览阅读4.2k次,点赞8次,收藏21次。作为一个干了多年的全栈技术工程师,厌倦了使用盗版IDE,近些年开发Java一直使用IntelliJ IDEA进行Springboot后端项目开发,对于IntelliJ IDEA 授权问题,一直花钱买学生类的授权,但经常被屏蔽,无法使用,又不舍得花大钱买企业版,索性不再使用了。决定改用 VsCode+Gradle+OpenJDK21进行JAVA Spring Boot开发,后续逐渐前后端都统一一套IDE工具。_openjdk 21