centos上配置flashcache_centos7安装flashcache-程序员宅基地
技术标签: kernel编译 linux flashcache centos
在写这篇博客之前,我想淡淡的发表下自己的观点:在写技术博客的时候用点心,积点德,自己搞清楚了在往上写,比如下面这一位,可把我坑惨了https://www.cnblogs.com/wuchanming/p/4043480.html我都跟着一步步的往下做了,后面 他突然来了一句,他也没搭出来环境,我....呵呵just a joke~
开始正题,最近在测bcache,dm-cache以及flashcache 的性能并比较 时间短任务重 我之前没有接触过这些cache,只是知道一些cache的基本原理,所以各种搜资料 发现国内的博客 论坛 百度 Bing之类上的 千篇一律 一知半解 于是上google上找找,这里不得不提一句,老外写技术博客的时候 还是比较认真负责的(不排除国外也有像我这样的菜鸡 哈哈)
flash-cache概念:
是 facebook 开源的 ssd 存储产品,它基于内核的 devicemapper 机制,允许将 ssd 设备映射为机械存储设备的缓存,堆叠成为一个虚拟设备供用户读写,从而在一定程度上兼顾 ssd 的高速与机械存储设备的高容量,更加经济高效地支撑线上业务。

flashcache安装使用:
1.源码获取
https://github.com/facebookarchive/flashcache 获取后放到自己指定目录下 比如我的在/hoem/下 解压 (网上乱七八糟说的进入解压后的目录 然后make && makefile是错的,此时肯定过不了)
2.确定自己内核版本并编译内核
uname -a 查看自己内核版本
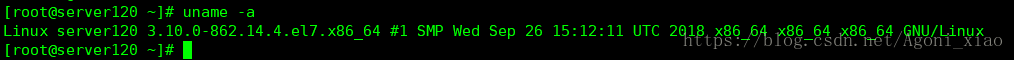
此时,要确定自己编译的flashcache版本是基于哪个版本,比如 我是用3.10.0编译flashcache的
所以你在变异的时候,一定先将内核默认启动版本切换到3.10
grub2-set-default 'CentOS Linux (3.10**) 7 (Core)'
编译命令:
cd /root/linux-3.10.0/
make KERNEL_TREE=/usr/src/kernels/linux-3.10.0/
编译如果出错的话,进入到报错的文件,并注释对应的函数 变量 我这里有两个错,具体错误我就不贴了,该屏蔽屏蔽 不影响flashcache性能
flashcache_conf.c flashcache_ioctl.c然后这个函数一直有问题wait_on_bit_lock
3.加载模块
make成功后 执行make moduels_install
然后执行 modprobe flashcache
使用这个命令查看是否正常加载ll /lib/modules/4.9.103/或者find ./ -name flash
至此flashcache安装成功一定要注意:用哪个内核版本编译,就必须用哪个内核版本加载启动
flashcache测试配置:
1.创建
flashcache_create
flashcache_create相关参数说明:
-p:缓存模式 writeback(数据先写到SSD,随后写到普通硬盘),
writethrough(数据同时写到SSD和普通硬盘),
writearound(数据绕过SSD,直接写到普通硬盘)三种,三种模式的所有读都会被缓存到flashcache可以通过dev.flashcache.<cachedev>.cache_all参数调整
-s:缓存大小,可选项,如果未指定则整个SSD设备被用于缓存,默认的计数单位是扇区(sectors),但是可以接受k/m/g单位。
-b:指定块大小,可选项,默认为4KB,必须为2的指数。默认单位为扇区。也可以用K作为单位,一般选4KB。
-f:强制创建,不进行检查
-m:设备元数据块大小,只有writeback需要存储metadata块,默认4K
flashcache_create -p thru -s 20g cachedev /dev/sdb1 /dev/sda1
2.挂载
mount /dev/mapper/cachedev /data
lsblk查看是否高速分区/dev/sdb1 和低速分区/dev/sda1下分别有cachedev

3.销毁
flashcache_destroy -f /dev/sdb1
umount /dev/sdb1
这里是我找的老外的资料,比国内的强太多 提供给大家参考 有什么不对的地方还请大家留言 指正
FlashCache System Administration Guide
--------------------------------------
Introduction :
============
Flashcache is a block cache for Linux, built as a kernel module,
using the Device Mapper. Flashcache supports writeback, writethrough
and writearound caching modes. This document is a quick administration
guide to flashcache.
Requirements :
============
Flashcache has been tested on variety of kernels between 2.6.18 and 2.6.38.
If you'd like to build and use it on a newer kernel, please send me an email
and I can help. I will not support older than 2.6.18 kernels.
Choice of Caching Modes :
=========================
Writethrough - safest, all writes are cached to ssd but also written to disk
immediately. If your ssd has slower write performance than your disk (likely
for early generation SSDs purchased in 2008-2010), this may limit your system
write performance. All disk reads are cached (tunable).
Writearound - again, very safe, writes are not written to ssd but directly to
disk. Disk blocks will only be cached after they are read. All disk reads
are cached (tunable).
Writeback - fastest but less safe. Writes only go to the ssd initially, and
based on various policies are written to disk later. All disk reads are
cached (tunable).
Writeonly - variant of writeback caching. In this mode, only incoming writes
are cached. No reads are ever cached.
Cache Persistence :
=================
Writethrough and Writearound caches are not persistent across a device removal
or a reboot. Only Writeback caches are persistent across device removals
and reboots. This reinforces 'writeback is fastest', 'writethrough is safest'.
Known Bugs :
============
See https://github.com/facebook/flashcache/issues and report new issues there please.
Data corruption has been reported when using a loopback device for the cache device.
See also the 'Futures and Features' section of the design document, flashcache-doc.txt.
Cache creation and loading using the flashcache utilities :
=========================================================
Included are 3 utilities - flashcache_create, flashcache_load and
flashcache_destroy. These utilities use dmsetup internally, presenting
a simpler interface to create, load and destroy flashcache volumes.
It is expected that the majority of users can use these utilities
instead of using dmsetup.
flashcache_create : Create a new flashcache volume.
flashcache_create [-v] -p back|around|thru [-s cache size] [-w] [-b block size] cachedevname ssd_devname disk_devname
-v : verbose.
-p : cache mode (writeback/writethrough/writearound).
-s : cache size. Optional. If this is not specified, the entire ssd device
is used as cache. The default units is sectors. But you can specify
k/m/g as units as well.
-b : block size. Optional. Defaults to 4KB. Must be a power of 2.
The default units is sectors. But you can specify k as units as well.
(A 4KB blocksize is the correct choice for the vast majority of
applications. But see the section "Cache Blocksize selection" below).
-f : force create. by pass checks (eg for ssd sectorsize).
-w : write cache mode. Only writes are cached, not reads
-d : disk associativity, within each cache set, we store several contigous
disk extents. Defaults to off.
Examples :
flashcache_create -p back -s 1g -b 4k cachedev /dev/sdc /dev/sdb
Creates a 1GB writeback cache volume with a 4KB block size on ssd
device /dev/sdc to cache the disk volume /dev/sdb. The name of the device
created is "cachedev".
flashcache_create -p thru -s 2097152 -b 8 cachedev /dev/sdc /dev/sdb
Same as above but creates a write through cache with units specified in
sectors instead. The name of the device created is "cachedev".
flashcache_load : Load an existing writeback cache volume.
flashcache_load ssd_devname [cachedev_name]
Example :
flashcache_load /dev/sd
Load the existing writeback cache on /dev/sdc, using the virtual
cachedev_name from when the device was created. If you're upgrading from
an older flashcache device format that didn't store the cachedev name
internally, or you want to change the cachedev name use, you can specify
it as an optional second argument to flashcache_load.
For writethrough and writearound caches flashcache_load is not needed; flashcache_create
should be used each time.
flashcache_destroy : Destroy an existing writeback flashcache. All data will be lost !!!
flashcache_destroy ssd_devname
Example :
flashcache_destroy /dev/sdc
Destroy the existing cache on /dev/sdc. All data is lost !!!
For writethrough and writearound caches this is not necessary.
Removing a flashcache volume :
============================
Use dmsetup remove to remove a flashcache volume. For writeback
cache mode, the default behavior on a remove is to clean all dirty
cache blocks to disk. The remove will not return until all blocks
are cleaned. Progress on disk cleaning is reported on the console
(also see the "fast_remove" flashcache sysctl).
A reboot of the node will also result in all dirty cache blocks being
cleaned synchronously (again see the note about "fast_remove" in the
sysctls section).
For writethrough and writearound caches, the device removal or reboot
results in the cache being destroyed. However, there is no harm is
doing a 'dmsetup remove' to tidy up before boot, and indeed
this will be needed if you ever need to unload the flashcache kernel
module (for example to load an new version into a running system).
Example:
dmsetup remove cachedev
This removes the flashcache volume name cachedev. Cleaning
all blocks prior to removal.
Cache Stats :
===========
Use 'dmsetup status' for cache statistics.
'dmsetup table' also dumps a number of cache related statistics.
Examples :
dmsetup status cachedev
dmsetup table cachedev
Flashcache errors are reported in
/proc/flashcache/<cache name>/flashcache_errors
Flashcache stats are also reported in
/proc/flashcache/<cache name>/flashcache_stats
for easier parseability.
Using Flashcache sysVinit script (Redhat based systems):
=======================================================
Kindly note that, this sections only applies to the Redhat based systems. Use
'utils/flashcache' from the repository as the sysvinit script.
This script is to load, unload and get statistics of an existing flashcache
writeback cache volume. It helps in loading the already created cachedev during
system boot and removes the flashcache volume before system halt happens.
This script is necessary, because, when a flashcache volume is not removed
before the system halt, kernel panic occurs.
Configuring the script using chkconfig:
1. Copy 'utils/flashcache' from the repo to '/etc/init.d/flashcache'
2. Make sure this file has execute permissions,
'sudo chmod +x /etc/init.d/flashcache'.
3. Edit this file and specify the values for the following variables
SSD_DISK, BACKEND_DISK, CACHEDEV_NAME, MOUNTPOINT, FLASHCACHE_NAME
4. Modify the headers in the file if necessary.
By default, it starts in runlevel 3, with start-stop priority 90-10
5. Register this file using chkconfig
'chkconfig --add /etc/init.d/flashcache'
Cache Blocksize selection :
=========================
Cache blocksize selection is critical for good cache utilization and
performance.
A 4KB cache blocksize for the vast majority of workloads (and filesystems).
Cache Metadata Blocksize selection :
==================================
This section only applies to the writeback cache mode. Writethrough and
writearound modes store no cache metadata at all.
In Flashcache version 1, the metadata blocksize was fixed at 1 (512b) sector.
Flashcache version 2 removes this limitation. In version 2, we can configure
a larger flashcache metadata blocksize. Version 2 maintains backwards compatibility
for caches created with Version 1. For these cases, a metadata blocksize of 512
will continue to be used.
flashcache_create -m can be used to optionally configure the metadata blocksize.
Defaults to 4KB.
Ideal choices for the metadata blocksize are 4KB (default) or 8KB. There is
little benefit to choosing a metadata blocksize greater than 8KB. The choice
of metadata blocksize is subject to the following rules :
1) Metadata blocksize must be a power of 2.
2) Metadata blocksize cannot be smaller than sector size configured on the
ssd device.
3) A single metadata block cannot contain metadata for 2 cache sets. In other
words, with the default associativity of 512 (with each cache metadata slot
sizing at 16 bytes), the entire metadata for a given set fits in 8KB (512*16b).
For an associativity of 512, we cannot configure a metadata blocksize greater
than 8KB.
Advantages of choosing a larger (than 512b) metadata blocksize :
- Allows the ssd to be configured to larger sectors. For example, some ssds
allow choosing a 4KB sector, often a more performant choice.
- Allows flashache to do better batching of metadata updates, potentially
reducing metadata updates, small ssd writes, reducing write amplification
and higher ssd lifetimes.
Thanks due to Earle Philhower of Virident for this feature !
FlashCache Sysctls :
==================
Flashcache sysctls operate on a per-cache device basis. A couple of examples
first.
Sysctls for a writearound or writethrough mode cache :
cache device /dev/ram3, disk device /dev/ram4
dev.flashcache.ram3+ram4.cache_all = 1
dev.flashcache.ram3+ram4.zero_stats = 0
dev.flashcache.ram3+ram4.reclaim_policy = 0
dev.flashcache.ram3+ram4.pid_expiry_secs = 60
dev.flashcache.ram3+ram4.max_pids = 100
dev.flashcache.ram3+ram4.do_pid_expiry = 0
dev.flashcache.ram3+ram4.io_latency_hist = 0
dev.flashcache.ram3+ram4.skip_seq_thresh_kb = 0
Sysctls for a writeback mode cache :
cache device /dev/sdb, disk device /dev/cciss/c0d2
dev.flashcache.sdb+c0d2.fallow_delay = 900
dev.flashcache.sdb+c0d2.fallow_clean_speed = 2
dev.flashcache.sdb+c0d2.cache_all = 1
dev.flashcache.sdb+c0d2.fast_remove = 0
dev.flashcache.sdb+c0d2.zero_stats = 0
dev.flashcache.sdb+c0d2.reclaim_policy = 0
dev.flashcache.sdb+c0d2.pid_expiry_secs = 60
dev.flashcache.sdb+c0d2.max_pids = 100
dev.flashcache.sdb+c0d2.do_pid_expiry = 0
dev.flashcache.sdb+c0d2.max_clean_ios_set = 2
dev.flashcache.sdb+c0d2.max_clean_ios_total = 4
dev.flashcache.sdb+c0d2.dirty_thresh_pct = 20
dev.flashcache.sdb+c0d2.stop_sync = 0
dev.flashcache.sdb+c0d2.do_sync = 0
dev.flashcache.sdb+c0d2.io_latency_hist = 0
dev.flashcache.sdb+c0d2.skip_seq_thresh_kb = 0
Sysctls common to all cache modes :
dev.flashcache.<cachedev>.cache_all:
Global caching mode to cache everything or cache nothing.
See section on Caching Controls. Defaults to "cache everything".
dev.flashcache.<cachedev>.zero_stats:
Zero stats (once).
dev.flashcache.<cachedev>.reclaim_policy:
FIFO (0) vs LRU (1). Defaults to FIFO. Can be switched at
runtime.
dev.flashcache.<cachedev>.io_latency_hist:
Compute IO latencies and plot these out on a histogram.
The scale is 250 usecs. This is disabled by default since
internally flashcache uses gettimeofday() to compute latency
and this can get expensive depending on the clocksource used.
Setting this to 1 enables computation of IO latencies.
The IO latency histogram is appended to 'dmsetup status'.
(There is little reason to tune these)
dev.flashcache.<cachedev>.max_pids:
Maximum number of pids in the white/black lists.
dev.flashcache.<cachedev>.do_pid_expiry:
Enable expiry on the list of pids in the white/black lists.
dev.flashcache.<cachedev>.pid_expiry_secs:
Set the expiry on the pid white/black lists.
dev.flashcache.<cachedev>.skip_seq_thresh_kb:
Skip (don't cache) sequential IO larger than this number (in kb).
0 (default) means cache all IO, both sequential and random.
Sequential IO can only be determined 'after the fact', so
this much of each sequential I/O will be cached before we skip
the rest. Does not affect searching for IO in an existing cache.
Sysctls for writeback mode only :
dev.flashcache.<cachedev>.fallow_delay = 900
In seconds. Clean dirty blocks that have been "idle" (not
read or written) for fallow_delay seconds. Default is 15
minutes.
Setting this to 0 disables idle cleaning completely.
dev.flashcache.<cachedev>.fallow_clean_speed = 2
The maximum number of "fallow clean" disk writes per set
per second. Defaults to 2.
dev.flashcache.<cachedev>.fast_remove = 0
Don't sync dirty blocks when removing cache. On a reload
both DIRTY and CLEAN blocks persist in the cache. This
option can be used to do a quick cache remove.
CAUTION: The cache still has uncommitted (to disk) dirty
blocks after a fast_remove.
dev.flashcache.<cachedev>.dirty_thresh_pct = 20
Flashcache will attempt to keep the dirty blocks in each set
under this %. A lower dirty threshold increases disk writes,
and reduces block overwrites, but increases the blocks
available for read caching.
dev.flashcache.<cachedev>.stop_sync = 0
Stop the sync in progress.
dev.flashcache.<cachedev>.do_sync = 0
Schedule cleaning of all dirty blocks in the cache.
(There is little reason to tune these)
dev.flashcache.<cachedev>.max_clean_ios_set = 2
Maximum writes that can be issues per set when cleaning
blocks.
dev.flashcache.<cachedev>.max_clean_ios_total = 4
Maximum writes that can be issued when syncing all blocks.
Using dmsetup to create and load flashcache volumes :
===================================================
Few users will need to use dmsetup natively to create and load
flashcache volumes. This section covers that.
dmsetup create device_name table_file
where
device_name: name of the flashcache device being created or loaded.
table_file : other cache args (format below). If this is omitted, dmsetup
attempts to read this from stdin.
table_file format :
0 <disk dev sz in sectors> flashcache <disk dev> <ssd dev> <dm virtual name> <cache mode> <flashcache cmd> <blksize in sectors> [size of cache in sectors] [cache set size]
cache mode:
1: Write Back
2: Write Through
3: Write Around
flashcache cmd:
1: load existing cache
2: create cache
3: force create cache (overwriting existing cache). USE WITH CAUTION
blksize in sectors:
4KB (8 sectors, PAGE_SIZE) is the right choice for most applications.
See note on block size selection below.
Unused (can be omitted) for cache loads.
size of cache in sectors:
Optional. if size is not specified, the entire ssd device is used as
cache. Needs to be a power of 2.
Unused (can be omitted) for cache loads.
cache set size:
Optional. The default set size is 512, which works well for most
applications. Little reason to change this. Needs to be a
power of 2.
Unused (can be omitted) for cache loads.
Example :
echo 0 `blockdev --getsize /dev/cciss/c0d1p2` flashcache /dev/cciss/c0d1p2 /dev/fioa2 cachedev 1 2 8 522000000 | dmsetup create cachedev
This creates a writeback cache device called "cachedev" (/dev/mapper/cachedev)
with a 4KB blocksize to cache /dev/cciss/c0d1p2 on /dev/fioa2.
The size of the cache is 522000000 sectors.
(TODO : Change loading of the cache happen via "dmsetup load" instead
of "dmsetup create").
Caching Controls
================
Flashcache can be put in one of 2 modes - Cache Everything or
Cache Nothing (dev.flashcache.cache_all). The defaults is to "cache
everything".
These 2 modes have a blacklist and a whitelist.
The tgid (thread group id) for a group of pthreads can be used as a
shorthand to tag all threads in an application. The tgid for a pthread
is returned by getpid() and the pid of the individual thread is
returned by gettid().
The algorithm works as follows :
In "cache everything" mode,
1) If the pid of the process issuing the IO is in the blacklist, do
not cache the IO. ELSE,
2) If the tgid is in the blacklist, don't cache this IO. UNLESS
3) The particular pid is marked as an exception (and entered in the
whitelist, which makes the IO cacheable).
4) Finally, even if IO is cacheable up to this point, skip sequential IO
if configured by the sysctl.
Conversely, in "cache nothing" mode,
1) If the pid of the process issuing the IO is in the whitelist,
cache the IO. ELSE,
2) If the tgid is in the whitelist, cache this IO. UNLESS
3) The particular pid is marked as an exception (and entered in the
blacklist, which makes the IO non-cacheable).
4) Anything whitelisted is cached, regardless of sequential or random
IO.
Examples :
--------
1) You can make the global cache setting "cache nothing", and add the
tgid of your pthreaded application to the whitelist. Which makes only
IOs issued by your application cacheable by Flashcache.
2) You can make the global cache setting "cache everything" and add
tgids (or pids) of other applications that may issue IOs on this
volume to the blacklist, which will make those un-interesting IOs not
cacheable.
Note that this only works for O_DIRECT IOs. For buffered IOs, pdflush,
kswapd would also do the writes, with flashcache caching those.
The following cacheability ioctls are supported on /dev/mapper/<cachedev>
FLASHCACHEADDBLACKLIST: add the pid (or tgid) to the blacklist.
FLASHCACHEDELBLACKLIST: Remove the pid (or tgid) from the blacklist.
FLASHCACHEDELALLBLACKLIST: Clear the blacklist. This can be used to
cleanup if a process dies.
FLASHCACHEADDWHITELIST: add the pid (or tgid) to the whitelist.
FLASHCACHEDELWHITELIST: Remove the pid (or tgid) from the whitelist.
FLASHCACHEDELALLWHITELIST: Clear the whitelist. This can be used to
cleanup if a process dies.
/proc/flashcache_pidlists shows the list of pids on the whitelist
and the blacklist.
Security Note :
=============
With Flashcache, it is possible for a malicious user process to
corrupt data in files with only read access. In a future revision
of flashcache, this will be addressed (with an extra data copy).
Not documenting the mechanics of how a malicious process could
corrupt data here.
You can work around this by setting file permissions on files in
the flashcache volume appropriately.
Why is my cache only (<< 100%) utilized ?
=======================================
(Answer contributed by Will Smith)
- There is essentially a 1:many mapping between SSD blocks and HDD blocks.
- In more detail, a HDD block gets hashed to a set on SSD which contains by
default 512 blocks. It can only be stored in that set on SSD, nowhere else.
So with a simplified SSD containing only 3 sets:
SSD = 1 2 3 , and a HDD with 9 sets worth of data, the HDD sets would map to the SSD
sets like this:
HDD: 1 2 3 4 5 6 7 8 9
SSD: 1 2 3 1 2 3 1 2 3
So if your data only happens to live in HDD sets 1 and 4, they will compete for
SSD set 1 and your SSD will at most become 33% utilized.
If you use XFS you can tune the XFS agsize/agcount to try and mitigate this
(described next section).
Tuning XFS for better flashcache performance :
============================================
If you run XFS/Flashcache, it is worth tuning XFS' allocation group
parameters (agsize/agcount) to achieve better flashcache performance.
XFS allocates blocks for files in a given directory in a new
allocation group. By tuning agsize and agcount (mkfs.xfs parameters),
we can achieve much better distribution of blocks across
flashcache. Better distribution of blocks across flashcache will
decrease collisions on flashcache sets considerably, increase cache
hit rates significantly and result in lower IO latencies.
We can achieve this by computing agsize (and implicitly agcount) using
these equations,
C = Cache size,
V = Size of filesystem Volume.
agsize % C = (1/agcount)*C
agsize * agcount ~= V
where agsize <= 1000g (XFS limits on agsize).
A couple of examples that illustrate the formula,
For agcount = 4, let's divide up the cache into 4 equal parts (each
part is size C/agcount). Let's call the parts C1, C2, C3, C4. One
ideal way to map the allocation groups onto the cache is as follows.
Ag1 Ag2 Ag3 Ag4
-- -- -- --
C1 C2 C3 C4 (stripe 1)
C2 C3 C4 C1 (stripe 2)
C3 C4 C1 C2 (stripe 3)
C4 C1 C2 C3 (stripe 4)
C1 C2 C3 C4 (stripe 5)
In this simple example, note that each "stripe" has 2 properties
1) Each element of the stripe is a unique part of the cache.
2) The union of all the parts for a stripe gives us the entire cache.
Clearly, this is an ideal mapping, from a distribution across the
cache point of view.
Another example, this time with agcount = 5, the cache is divided into
5 equal parts C1, .. C5.
Ag1 Ag2 Ag3 Ag4 Ag5
-- -- -- -- --
C1 C2 C3 C4 C5 (stripe 1)
C2 C3 C4 C5 C1 (stripe 2)
C3 C4 C5 C1 C2 (stripe 3)
C4 C5 C1 C2 C3 (stripe 4)
C5 C1 C2 C3 C4 (stripe 5)
C1 C2 C3 C4 C5 (stripe 6)
A couple of examples that compute the optimal agsize for a given
Cachesize and Filesystem volume size.
a) C = 600g, V = 3,5TB
Consider agcount = 5
agsize % 600 = (1/5)*600
agsize % 600 = 120
So an agsize of 720g would work well, and 720*5 = 3.6TB (~ 3.5TB)
b) C = 150g, V = 3.5TB
Consider agcount=4
agsize % 150 = (1/4)*150
agsize % 150 = 37.5
So an agsize of 937g would work well, and 937*4 = 3.7TB (~ 3.5TB)
As an alternative,
agsize % C = (1 - (1/agcount))*C
agsize * agcount ~= V
Works just as well as the formula above.
This computation has been implemented in the utils/get_agsize utility.
Tuning Sequential IO Skipping for better flashcache performance
===============================================================
Skipping sequential IO makes sense in two cases:
1) your sequential write speed of your SSD is slower than
the sequential write speed or read speed of your disk. In
particular, for implementations with RAID disks (especially
modes 0, 10 or 5) sequential reads may be very fast. If
'cache_all' mode is used, every disk read miss must also be
written to SSD. If you notice slower sequential reads and writes
after enabling flashcache, this is likely your problem.
2) Your 'resident set' of disk blocks that you want cached, i.e.
those that you would hope to keep in cache, is smaller
than the size of your SSD. You can check this by monitoring
how quick your cache fills up ('dmsetup table'). If this
is the case, it makes sense to prioritize caching of random IO,
since SSD performance vastly exceeds disk performance for
random IO, but is typically not much better for sequential IO.
In the above cases, start with a high value (say 1024k) for
sysctl dev.flashcache.<device>.skip_seq_thresh_kb, so only the
largest sequential IOs are skipped, and gradually reduce
if benchmarks show it's helping. Don't leave it set to a very
high value, return it to 0 (the default), since there is some
overhead in categorizing IO as random or sequential.
If neither of the above hold, continue to cache all IO,
(the default) you will likely benefit from it.
Further Information
===================
Git repository : https://github.com/facebook/flashcache/
Developer mailing list : http://groups.google.com/group/flashcache-dev/
智能推荐
攻防世界_难度8_happy_puzzle_攻防世界困难模式攻略图文-程序员宅基地
文章浏览阅读645次。这个肯定是末尾的IDAT了,因为IDAT必须要满了才会开始一下个IDAT,这个明显就是末尾的IDAT了。,对应下面的create_head()代码。,对应下面的create_tail()代码。不要考虑爆破,我已经试了一下,太多情况了。题目来源:UNCTF。_攻防世界困难模式攻略图文
达梦数据库的导出(备份)、导入_达梦数据库导入导出-程序员宅基地
文章浏览阅读2.9k次,点赞3次,收藏10次。偶尔会用到,记录、分享。1. 数据库导出1.1 切换到dmdba用户su - dmdba1.2 进入达梦数据库安装路径的bin目录,执行导库操作 导出语句:./dexp cwy_init/[email protected]:5236 file=cwy_init.dmp log=cwy_init_exp.log 注释: cwy_init/init_123..._达梦数据库导入导出
js引入kindeditor富文本编辑器的使用_kindeditor.js-程序员宅基地
文章浏览阅读1.9k次。1. 在官网上下载KindEditor文件,可以删掉不需要要到的jsp,asp,asp.net和php文件夹。接着把文件夹放到项目文件目录下。2. 修改html文件,在页面引入js文件:<script type="text/javascript" src="./kindeditor/kindeditor-all.js"></script><script type="text/javascript" src="./kindeditor/lang/zh-CN.js"_kindeditor.js
STM32学习过程记录11——基于STM32G431CBU6硬件SPI+DMA的高效WS2812B控制方法-程序员宅基地
文章浏览阅读2.3k次,点赞6次,收藏14次。SPI的详情简介不必赘述。假设我们通过SPI发送0xAA,我们的数据线就会变为10101010,通过修改不同的内容,即可修改SPI中0和1的持续时间。比如0xF0即为前半周期为高电平,后半周期为低电平的状态。在SPI的通信模式中,CPHA配置会影响该实验,下图展示了不同采样位置的SPI时序图[1]。CPOL = 0,CPHA = 1:CLK空闲状态 = 低电平,数据在下降沿采样,并在上升沿移出CPOL = 0,CPHA = 0:CLK空闲状态 = 低电平,数据在上升沿采样,并在下降沿移出。_stm32g431cbu6
计算机网络-数据链路层_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏8次。数据链路层习题自测问题1.数据链路(即逻辑链路)与链路(即物理链路)有何区别?“电路接通了”与”数据链路接通了”的区别何在?2.数据链路层中的链路控制包括哪些功能?试讨论数据链路层做成可靠的链路层有哪些优点和缺点。3.网络适配器的作用是什么?网络适配器工作在哪一层?4.数据链路层的三个基本问题(帧定界、透明传输和差错检测)为什么都必须加以解决?5.如果在数据链路层不进行帧定界,会发生什么问题?6.PPP协议的主要特点是什么?为什么PPP不使用帧的编号?PPP适用于什么情况?为什么PPP协议不_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输
软件测试工程师移民加拿大_无证移民,未受过软件工程师的教育(第1部分)-程序员宅基地
文章浏览阅读587次。软件测试工程师移民加拿大 无证移民,未受过软件工程师的教育(第1部分) (Undocumented Immigrant With No Education to Software Engineer(Part 1))Before I start, I want you to please bear with me on the way I write, I have very little gen...
随便推点
Thinkpad X250 secure boot failed 启动失败问题解决_安装完系统提示secureboot failure-程序员宅基地
文章浏览阅读304次。Thinkpad X250笔记本电脑,装的是FreeBSD,进入BIOS修改虚拟化配置(其后可能是误设置了安全开机),保存退出后系统无法启动,显示:secure boot failed ,把自己惊出一身冷汗,因为这台笔记本刚好还没开始做备份.....根据错误提示,到bios里面去找相关配置,在Security里面找到了Secure Boot选项,发现果然被设置为Enabled,将其修改为Disabled ,再开机,终于正常启动了。_安装完系统提示secureboot failure
C++如何做字符串分割(5种方法)_c++ 字符串分割-程序员宅基地
文章浏览阅读10w+次,点赞93次,收藏352次。1、用strtok函数进行字符串分割原型: char *strtok(char *str, const char *delim);功能:分解字符串为一组字符串。参数说明:str为要分解的字符串,delim为分隔符字符串。返回值:从str开头开始的一个个被分割的串。当没有被分割的串时则返回NULL。其它:strtok函数线程不安全,可以使用strtok_r替代。示例://借助strtok实现split#include <string.h>#include <stdio.h&_c++ 字符串分割
2013第四届蓝桥杯 C/C++本科A组 真题答案解析_2013年第四届c a组蓝桥杯省赛真题解答-程序员宅基地
文章浏览阅读2.3k次。1 .高斯日记 大数学家高斯有个好习惯:无论如何都要记日记。他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210后来人们知道,那个整数就是日期,它表示那一天是高斯出生后的第几天。这或许也是个好习惯,它时时刻刻提醒着主人:日子又过去一天,还有多少时光可以用于浪费呢?高斯出生于:1777年4月30日。在高斯发现的一个重要定理的日记_2013年第四届c a组蓝桥杯省赛真题解答
基于供需算法优化的核极限学习机(KELM)分类算法-程序员宅基地
文章浏览阅读851次,点赞17次,收藏22次。摘要:本文利用供需算法对核极限学习机(KELM)进行优化,并用于分类。
metasploitable2渗透测试_metasploitable2怎么进入-程序员宅基地
文章浏览阅读1.1k次。一、系统弱密码登录1、在kali上执行命令行telnet 192.168.26.1292、Login和password都输入msfadmin3、登录成功,进入系统4、测试如下:二、MySQL弱密码登录:1、在kali上执行mysql –h 192.168.26.129 –u root2、登录成功,进入MySQL系统3、测试效果:三、PostgreSQL弱密码登录1、在Kali上执行psql -h 192.168.26.129 –U post..._metasploitable2怎么进入
Python学习之路:从入门到精通的指南_python人工智能开发从入门到精通pdf-程序员宅基地
文章浏览阅读257次。本文将为初学者提供Python学习的详细指南,从Python的历史、基础语法和数据类型到面向对象编程、模块和库的使用。通过本文,您将能够掌握Python编程的核心概念,为今后的编程学习和实践打下坚实基础。_python人工智能开发从入门到精通pdf