PyTorch强化学习实战(1)——强化学习环境配置与PyTorch基础-程序员宅基地
技术标签: PyTorch强化学习实战 深度学习 pytorch 强化学习
PyTorch强化学习实战(1)——强化学习环境配置与PyTorch基础
0. 前言
工欲善其事,必先利其器。为了更专注于学习强化学习的思想,而不必关注其底层的计算细节,我们首先搭建相关深度学习环境,主要包括 Python 以及 PyTorch。Python,更具体说使用 Python3.7+ 作为我们实现强化学习算法进行实战的编程语言。PyTorch 是我们将要使用的主要深度学习框架,PyTorch 由 Facebook AI Research 基于 Torch 开发,是主流的机器学习库之一。在 PyTorch 中,使用张量 (Tensors) 代替了 NumPy 中的 ndarray 数据类型,从而提供了更强大的灵活性和与 GPU 的兼容性。由于其强大的计算图特性和简单的上手难度,使得 PyTorch 受到了广泛的欢迎,并且它已被越来越多的科技巨头所采用。
1. 搭建 PyTorch 环境
关于 Python 的安装和配置,在此不再赘述。可选的,由于,深度学习中模型的训练需要大量时间,因此通常使用 GPU加速计算,在安装 PyTorch 之前需要根据选用的 PyTorch 版本和显卡安装 CUDA 和 cudnn,关于 CUDA 和 cudnn 的安装和配置可以参考官方文档,建议在安装之前根据自己的操作系统认真查看官方的安装文档,可以避免踩不必要的坑。
然后,在 PyTorch 官方网页,根据自己实际的环境,进行相应的选择,在 Run this Command 栏中将给出安装 PyTorch 的命令:

在此,我们以 Linux、pip、Python 和 CUDA10.2 为例,复制并在终端执行安装命令:
pip3 install torch torchvision torchaudio
为了确认 PyTorch 已正确安装,可以在 Python shell 中运行以下代码:
>>> import torch
>>> test = torch.empty(2,2)
>>> print(test)
tensor([[2.9685e-26, 4.5722e-41],
[2.9685e-26, 4.5722e-41]])
如果能够正确调用 PyTorch 相关函数,表明 PyTorch 已正确安装。需要注意的是,以上代码中,使用 torch.emty() 中创建了一个尺寸为 2 x 2 的张量,它是一个空矩阵,这里的“空”并不意味着所有元素的值都为 Null,而是使用一些被认为是占位符的无意义浮点数,需要在之后进行赋值,这与 NumPy 中的空数组类似。
2. OpenAI Gym简介与安装
深度学习环境配置后,我们继续安装 OpenAI Gym,OpenAI Gym 提供多种环境,可以在其中开发和比较强化学习算法,通过提供标准 API 用于学习算法和环境之间的通信。Gym 事实上已经成为用于强化学习中的基准,涵盖了许多功能全面且易于使用的环境。这类似于我们经常在监督学习中用作基准的数据集,例如 MNIST,Imagenet,和 Reuters 新闻数据集。
OpenAI 是一家致力于建立安全的人工智能并确保其对人类有益的非营利性研究公司。OpenAI Gym 是一个功能强大的开源工具包,可用于各种强化学习模拟和任务,包括从赛车到 Atari 游戏等多种类型,Gym 提供的完整环境列表可以参见官方网页。我们可以使用任何机器学习库,包括 PyTorch,TensorFlow 或 Keras 等,训练智能体与 OpenAI Gym 环境进行交互。
Gym 的安装与其它标准第三方库一样,可以通过 pip 命令方便的安装:
pip install gym
安装完成后,可以在命令行中使用以下代码来查看可用的 gym 环境:
>>> import gym
>>> print(gym.envs.registry.all())
dict_values([EnvSpec(Copy-v0), EnvSpec(RepeatCopy-v0), EnvSpec(ReversedAddition-v0), EnvSpec(ReversedAddition3-v0), EnvSpec(DuplicatedInput-v0), EnvSpec(Reverse-v0), EnvSpec(CartPole-v0), EnvSpec(CartPole-v1), EnvSpec(MountainCar-v0), EnvSpec(MountainCarContinuous-v0), EnvSpec(Pendulum-v0),...
可以看到,如果正确安装了 Gym,使用 gym.envs.registry.all() 可以返回 Gym 中所有可用的环境。
3. 模拟 Atari 环境
Atari 环境中包含各种 Atari 电子游戏,例如 Alien,AirRaid,Pong 和 Space Race 等。接下来,我们按照以下步骤安装模拟 Atari 环境,要运行 Atari 环境,需要在终端中运行以下命令安装 Atari 依赖项:
pip install gym[atari]
安装 Atari 依赖项后,我们可以使用 Python 导入 Gym 库来验证安装是否成功:
>>> import gym
使用 Gym,可以通过使用环境名称作为参数调用 make() 方法创建环境实例。以创建 SpaceInvaders 环境的实例为例:
>>> env = gym.make('SpaceInvaders-v0')
重置 SpaceInvaders 环境,可以看到 reset() 方法返回环境中的初始状态:
>>> env.reset()
array([[[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
...,
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0]],
...,
[[80, 89, 22],
[80, 89, 22],
[80, 89, 22],
...,
[80, 89, 22],
[80, 89, 22],
[80, 89, 22]]], dtype=uint8)
使用 render 方法渲染 SpaceInvaders 环境,可以看到弹出的游戏窗口:
>>> env.render()
True

在以上游戏窗口中可以看到,其中包含三个红色太空飞船,表示飞船包含三条命。使用 sample() 方法可以随机选择智能体执行的动作,step() 方法使智能体根据给定参数执行相应动作。通常,在强化学习中,我们将使用复杂的智能体选择要执行的动作。在这里,仅仅为了演示如何模拟环境,以及智能体如何采取行动而不管结果如何。通过随机选择动作并执行所选择的动作:
>>> action = env.action_space.sample()
>>> new_state, reward, is_done, info = env.step(action)
step() 方法可以返回执行动作后的情况,包括以下内容:
new_state:对游戏环境新的观测值 (observation),在单智能体环境中也可以理解为新状态reward:执行动作后在新状态下得到的相应奖励is_done:用于指示游戏是否结束的标志,例如,在SpaceInvaders环境中,如果飞船三条命耗尽或所有外星敌人都被消失,则为True,否则,为Falseinfo:与环境有关的其他信息,例如,在SpaceInvaders环境中,info中包含当前状态下飞船剩余生命的数量,info通常用于程序的调试
可以通过 action_sapce 查看智能体能够执行的动作数量,即动作空间大小:
>>> print(env.action_space)
Discrete(6)
在 SpaceInvaders 环境中,从 0 到 5 的动作分别代表不进行任何操作,开火,向上,向右,向左和向下,这是飞船在游戏中可以做的所有动作。
对环境的观察值 new_state 是一个形状为 210 x 160 x 3 的矩阵,即游戏屏幕的每一帧都是大小为 210 x 160 的 RGB 图像:
>>> print(new_state.shape)
(210, 160, 3)
接下来,我们打印 is_done 和 info 查看其具体内容:
>>> print(is_done)
False
>>> print(info)
{
'ale.lives': 3}
然后,继续渲染环境,render() 方法根据对环境的最新观察值来更新显示窗口,可以看到游戏窗口中的内容有所改变,但由于飞船只做了一个动作,因此改变并不明显:
>>> env.render()

为了使智能体执行更多动作,我们接下来使用 while 循环:
>>> while not is_done:
... action = env.action_space.sample()
... new_state, reward, is_done, info = env.step(action)
... env.render()
... print(info)
...
True
{
'ale.lives': 3}
True
{
'ale.lives': 3}
True
...
{
'ale.lives': 1}
True
{
'ale.lives': 0}
可以看到游戏的运行情况,飞船和外星人都会不断移动和射击。最后,在游戏结束时,窗口如下所示,在这场游戏中获取 30 分,并且最终的生命值为 0:

额外安装 Atari 依赖项的原因是由于其并不包含在 gym 环境中,此外 Box2d,Classic control,MuJoCo 和 Robotics 等环境也并不在 gym 环境中,这些环境的安装与 Atari 的安装类似,以 Box2d 环境为例,在首次运行环境之前安装 Box2d 依赖项:
pip install gym[box2d]
安装完成后,我们就可以使用 LunarLander 环境,如下所示:
>>> env = gym.make('LunarLander-v2')
>>> env.reset()
array([-1.2830734e-03, 1.4214842e+00, -1.2998608e-01, 4.6951649e-01,
1.4936496e-03, 2.9443752e-02, 0.0000000e+00, 0.0000000e+00],
dtype=float32)
>>> env.render()
True

如果并不确定要模拟环境在 make() 方法中应使用的名称,可以在官方环境列表中进行查找。该表除了给出用于调用环境的名称外,还列出了游戏窗口画面矩阵的尺寸和可以采取的动作数量。
4. 模拟 CartPole 环境
为了加深对 gym 环境的了解,本节我们将模拟另一个强化学习中的经典环境—— CartPole。
CartPole 是一项经典的强化学习任务,在 CartPole 环境中,一根直立的杆置于推车的顶部。智能体在一个时间步中会将推车向左或向右移动 1 个单位,其目的是平衡推车顶部的杆并防止其跌落。如果杆与垂直方向的夹角超过 12 度或者推车离原点的距离超过 2.4 个单位,则我们认为杆已跌落。遇到以下任何情况之一,我们可以认为一个回合/情节 (episode) 终止:
- 推车上的杆跌落
- 时间步数达到
200
接下来,我们在 gym 中模拟 CartPole 环境,为了对 CartPole 环境有所了解,我们首先导入 gym 库,实例化 CartPole-v0 环境,并打印其状态空间和动作空间:
>>> import gym
>>> env = gym.make('CartPole-v0')
>>> print(env.observation_space)
Box(4,)
>>> print(env.action_space)
Discrete(2)
可以看到 CartPole-v0 环境的状态空间以 4 维数组表示,并且有 2 个可能的动作。
接下来,重置环境,将返回 4 个浮点数数组表示的初始状态:
>>> env.reset()
array([ 0.0461389 , -0.0080376 , 0.03944101, 0.03537847])
渲染环境,可以看出弹出的游戏窗口:
>>> env.render()
True
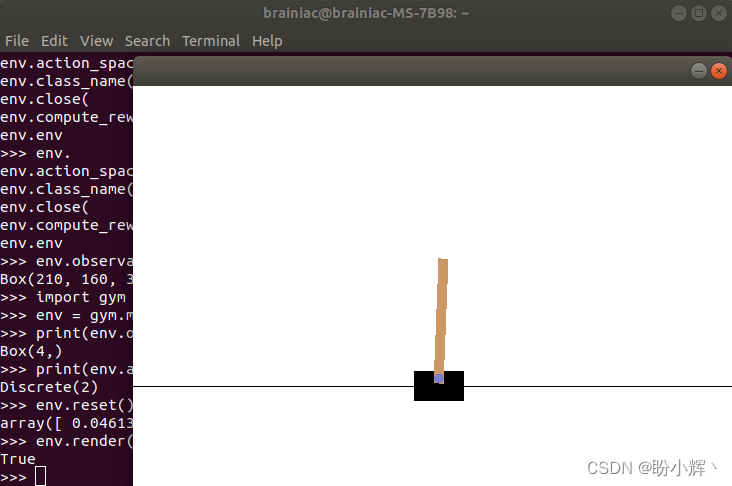
接下来,我们使用 while 循环,使智能体执行尽可能多的随机动作:
>>> is_done = False
>>> while not is_done:
... action = env.action_space.sample()
... new_state, reward, is_done, info = env.step(action)
... env.render()
... print(new_state)
...
True
[ 0.04970809 -0.0091745 0.03525649 0.06046739]
True
[ 0.0495246 -0.20478375 0.03646584 0.36406219]
......
True
[-0.0470163 -1.19033894 0.21028888 2.08433865]
我们在每个时间步中打印出当前状态,数组中的包含 4 个浮点数,可以在 Gym 的 GitHub Wiki 页面上找到关于这 4 个浮点数的更多信息,这 4 个浮点数分别表示:
- 推车位置:范围在区间
[-2.4, 2.4]之内,任何超出此范围的位置都会导致回合终止 - 推车速度
- 杆与垂直方向夹角:小于
-0.209(-12度)或大于0.209(12度)的值将导致回合终止 - 杆端点处的速度
动作的可能值为 0 和 1,分别对应于将推车向左和向右推动。在回合终止之前的每个时间步中,智能体都能从环境中得到奖励 +1,因此,总奖励等于一个回合中的时间步总数。
在代码执行过程中,可以看到推车和杆都会移动,并最终停止,停止时游戏窗口如下所示:

由于向左或向右的动作是随机选择的,因此一个回合仅持续几个时间步。我们也可以记录整个过程,以便进行回顾。为了录制视频记录游戏过程,我们首先需要安装 ffmpeg,对于 Linux,可以使用以下命令进行安装,对于其他操作系统,可以参考官方文档:
sudo apt-get install ffmpeg
为了进行记录,需要创建 CartPole 实例后,使用 Monitor 对象记录游戏窗口中显示的内容并将其存储在指定目录中,其余的步骤和以上过程完全一致:
# monitor_gym.py
import gym
env = gym.make('CartPole-v0')
env.reset()
video_dir = './cartpole_video'
env = gym.wrappers.Monitor(env, video_dir)
is_done = False
while not is_done:
action = env.action_space.sample()
new_state, reward, is_done, info = env.step(action)
env.render()
运行以上代码,回合终止后,我们可以看到在 video_dir 文件夹中包含了一个 .mp4 文件,其中记录了一个回合的游戏过程。

为了评估智能体的表现,我们可以模拟多个回合,计算每个回合的总奖励,然后计算平均值。平均总奖励可以用于评估采取随机动作的智能体性能,我们使用 10000 个回合,在每个回合中,我们通过累积每个时间步中的奖励来计算总奖励:
# multi_episodes.py
import gym
env = gym.make('CartPole-v0')
n_episode = 10000
total_rewards = []
for e in range(n_episode):
state = env.reset()
total_reward = 0
is_done = False
while not is_done:
action = env.action_space.sample()
state, reward, is_done, info = env.step(action)
total_reward += reward
total_rewards.append(total_reward)
# 最后,我们计算平均总奖励
print('Average total reward over {} episodes: {}'.format(n_episode, sum(total_rewards) / n_episode))
运行以上代码,可以看到以下输出:
Average total reward over 10000 episodes: 22.1942
可以看出,采取随机动作的平均总奖励为 22.25,采取随机动作过于简单,我们将在之后的学习中实现更加有效的算法策略。
5. PyTorch 基础
我们将使用 PyTorch 作为实现强化学习算法的数值计算库。PyTorch 是 Facebook 开发的科学计算和机器学习库,张量 (Tensor) 是 PyTorch 中的核心数据结构,类似于 NumPy 中的 ndarray。 但是,PyTorch 在数组操作和遍历等方面的速度比 NumPy 更快,这主要是由于在 PyTorch 中,数组元素的访问速度更快。接下来,我们介绍一些 PyTorch 中的基本知识,以便在之后的强化学习实战中使用。
默认张量 (Tensor) 的数据类型是 torch.float32,这是张量运算最常用的数据类型。从区间 [0,1] 的均匀分布中随机采样生成浮点数:
>>> import torch
>>> x = torch.rand(4,3)
>>> print(x)
tensor([[0.1968, 0.6183, 0.9863],
[0.6465, 0.5472, 0.7393],
[0.4933, 0.1890, 0.0459],
[0.4462, 0.8802, 0.4948]])
我们也可以创建指定数据类型的张量,例如,返回一个 double 类型的张量 (float64),如下所示:
>>> x = torch.rand(4,3,dtype=torch.double)
>>> print(x)
tensor([[0.3899, 0.2509, 0.5130],
[0.5605, 0.5399, 0.2442],
[0.5419, 0.8523, 0.3360],
[0.4898, 0.1152, 0.4379]], dtype=torch.float64)
创建指定尺寸的矩阵,并用 0 或 1 进行填充:
>>> x = torch.zeros(4,3)
>>> print(x)
tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
>>> x = torch.ones(4,3)
>>> print(x)
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
可以使用数据的 size 方法获得张量的尺寸,其返回 torch.Size 元组:
>>> print(x.size())
torch.Size([4, 3])
可以使用 view 方法变换张量形状:
>>> x_reshaped = x.view(2,6)
>>> print(x_reshaped)
tensor([[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.]])
可以直接使用数据创建张量,包括单个值,列表和嵌套列表:
>>> x_1 = torch.tensor(4)
>>> print(x_1)
tensor(4)
>>> x_2 = torch.tensor([11.11,22,33,0])
>>> print(x_2)
tensor([11.1100, 22.0000, 33.0000, 0.0000])
>>> x_3 = torch.tensor([[1,2,3,4],[5,6.6,7.7,8.0]])
>>> print(x_3)
tensor([[1.0000, 2.0000, 3.0000, 4.0000],
[5.0000, 6.6000, 7.7000, 8.0000]])
可以使用类似于 NumPy 的方式利用索引来访问张量中的元素,对于单元素张量,我们也可以使用 item() 方法来访张量中的元素:
>>> print(x_3[0])
tensor([1., 2., 3., 4.])
>>> print(x_3[0,0])
tensor(1.)
>>> print(x_3[:,2])
tensor([3.0000, 7.7000])
>>> print(x_3[:,2:])
tensor([[3.0000, 4.0000],
[7.7000, 8.0000]])
>>> print(x_1.item())
4
Tensor 和 NumPy 数组可以相互转换,使用 numpy() 方法可以将张量转换为 NumPy 数组,而想要将 NumPy 数组转换为张量想要使用 from_numpy() 方法:
>>> print(x_3.numpy())
[[1. 2. 3. 4. ]
[5. 6.6 7.7 8. ]]
>>> import numpy as np
>>> x_np = np.ones(4)
>>> x_torch = torch.from_numpy(x_np)
>>> print(x_torch)
tensor([1., 1., 1., 1.], dtype=torch.float64)
需要注意的是,如果输入的 NumPy 数组是 float 数据类型,输出张量默认情况下为 double 类型,因此可能需要类型转换。在以下代码中,我们可以将 double 类型的张量转换为 float 类型:
>>> print(x_torch.float())
tensor([1., 1., 1., 1.])
PyTorch 中的运算操作也类似于 NumPy。接下来,我们以加法为例,可以直接使用 + 运算符,或者使用 add() 方法:
>>> x_4 = torch.tensor([[1,1,1,0],[1,2,3,4.]])
>>> print(x_3+x_4)
tensor([[ 2.0000, 3.0000, 4.0000, 4.0000],
[ 6.0000, 8.6000, 10.7000, 12.0000]])
>>> print(torch.add(x_3, x_4))
tensor([[ 2.0000, 3.0000, 4.0000, 4.0000],
[ 6.0000, 8.6000, 10.7000, 12.0000]])
同时,PyTorch 也支持就地 (in-place) 操作,这类操作可以直接改变张量对象:
>>> x_3.add_(x_4)
tensor([[ 2.0000, 3.0000, 4.0000, 4.0000],
[ 6.0000, 8.6000, 10.7000, 12.0000]])
>>> print(x_3)
tensor([[ 2.0000, 3.0000, 4.0000, 4.0000],
[ 6.0000, 8.6000, 10.7000, 12.0000]])
在以上输出中,可以看到使用 add_() 方法,会直接修改 x_3 的值,将其改变为原始 x_3 与 x_4 之和。在 PyTorch 中,带有 _ 的方法都表明其为就地操作,它将使用结果值来更新张量。
默认情况下,PyTorch 张量存储在 CPU 上。PyTorch 张量可以使用 GPU 加速计算,这是张量与 NumPy 数组相比的主要优势。为了利用此优势,我们需要将张量移动到 CUDA 设备上。使用 cuda.is_available() 方法可以检测cuda的可用性,可以使用 to() 方法将张量移动到任何可用设备上:
>>> torch.cuda.is_available()
True
>>> torch.cuda.device_count() # 统计可用的GPU数量
1
>>> torch.cuda.current_device() # 当前GPU索引
0
>>> torch.cuda.get_device_name(0) # GPU型号
'NVIDIA GeForce RTX 2070 SUPER'
>>> x_3.device # 当前设备
device(type='cpu')
>>> device = 'cuda' if torch.cuda.is_available() else 'cpu'
>>> x_3 = x_3.to(device) # 将张量转移到指定设备上
>>> x_3.device
device(type='cuda', index=0)
>>> x_5 = torch.ones(3,3,device=device) # 创建张量时指定张量
>>> print(x_5)
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], device='cuda:0')
小结
本节中主要介绍了如何搭建 PyTorch+Gym 强化学习环境,同时讲解了如何使用 Gym 环境,包括使用 make() 创建指定环境、reset() 方法重置游戏环境、render() 方法渲染环境、sample() 方法采样随机动作以及 step() 方法使用指定动作返回新的环境状态等,最后还介绍了 PyTorch 的基础知识,为之后使用 PyTorch 进行强化学习实战奠定基础。
智能推荐
hive使用适用场景_大数据入门:Hive应用场景-程序员宅基地
文章浏览阅读5.8k次。在大数据的发展当中,大数据技术生态的组件,也在不断地拓展开来,而其中的Hive组件,作为Hadoop的数据仓库工具,可以实现对Hadoop集群当中的大规模数据进行相应的数据处理。今天我们的大数据入门分享,就主要来讲讲,Hive应用场景。关于Hive,首先需要明确的一点就是,Hive并非数据库,Hive所提供的数据存储、查询和分析功能,本质上来说,并非传统数据库所提供的存储、查询、分析功能。Hive..._hive应用场景
zblog采集-织梦全自动采集插件-织梦免费采集插件_zblog 网页采集插件-程序员宅基地
文章浏览阅读496次。Zblog是由Zblog开发团队开发的一款小巧而强大的基于Asp和PHP平台的开源程序,但是插件市场上的Zblog采集插件,没有一款能打的,要么就是没有SEO文章内容处理,要么就是功能单一。很少有适合SEO站长的Zblog采集。人们都知道Zblog采集接口都是对Zblog采集不熟悉的人做的,很多人采取模拟登陆的方法进行发布文章,也有很多人直接操作数据库发布文章,然而这些都或多或少的产生各种问题,发布速度慢、文章内容未经严格过滤,导致安全性问题、不能发Tag、不能自动创建分类等。但是使用Zblog采._zblog 网页采集插件
Flink学习四:提交Flink运行job_flink定时运行job-程序员宅基地
文章浏览阅读2.4k次,点赞2次,收藏2次。restUI页面提交1.1 添加上传jar包1.2 提交任务job1.3 查看提交的任务2. 命令行提交./flink-1.9.3/bin/flink run -c com.qu.wc.StreamWordCount -p 2 FlinkTutorial-1.0-SNAPSHOT.jar3. 命令行查看正在运行的job./flink-1.9.3/bin/flink list4. 命令行查看所有job./flink-1.9.3/bin/flink list --all._flink定时运行job
STM32-LED闪烁项目总结_嵌入式stm32闪烁led实验总结-程序员宅基地
文章浏览阅读1k次,点赞2次,收藏6次。这个项目是基于STM32的LED闪烁项目,主要目的是让学习者熟悉STM32的基本操作和编程方法。在这个项目中,我们将使用STM32作为控制器,通过对GPIO口的控制实现LED灯的闪烁。这个STM32 LED闪烁的项目是一个非常简单的入门项目,但它可以帮助学习者熟悉STM32的编程方法和GPIO口的使用。在这个项目中,我们通过对GPIO口的控制实现了LED灯的闪烁。LED闪烁是STM32入门课程的基础操作之一,它旨在教学生如何使用STM32开发板控制LED灯的闪烁。_嵌入式stm32闪烁led实验总结
Debezium安装部署和将服务托管到systemctl-程序员宅基地
文章浏览阅读63次。本文介绍了安装和部署Debezium的详细步骤,并演示了如何将Debezium服务托管到systemctl以进行方便的管理。本文将详细介绍如何安装和部署Debezium,并将其服务托管到systemctl。解压缩后,将得到一个名为"debezium"的目录,其中包含Debezium的二进制文件和其他必要的资源。注意替换"ExecStart"中的"/path/to/debezium"为实际的Debezium目录路径。接下来,需要下载Debezium的压缩包,并将其解压到所需的目录。
Android 控制屏幕唤醒常亮或熄灭_android实现拿起手机亮屏-程序员宅基地
文章浏览阅读4.4k次。需求:在诗词曲文项目中,诗词整篇朗读的时候,文章没有读完会因为屏幕熄灭停止朗读。要求:在文章没有朗读完毕之前屏幕常亮,读完以后屏幕常亮关闭;1.权限配置:设置电源管理的权限。
随便推点
目标检测简介-程序员宅基地
文章浏览阅读2.3k次。目标检测简介、评估标准、经典算法_目标检测
记SQL server安装后无法连接127.0.0.1解决方法_sqlserver 127 0 01 无法连接-程序员宅基地
文章浏览阅读6.3k次,点赞4次,收藏9次。实训时需要安装SQL server2008 R所以我上网上找了一个.exe 的安装包链接:https://pan.baidu.com/s/1_FkhB8XJy3Js_rFADhdtmA提取码:ztki注:解压后1.04G安装时Microsoft需下载.NET,更新安装后会自动安装如下:点击第一个傻瓜式安装,唯一注意的是在修改路径的时候如下不可修改:到安装实例的时候就可以修改啦数据..._sqlserver 127 0 01 无法连接
js 获取对象的所有key值,用来遍历_js 遍历对象的key-程序员宅基地
文章浏览阅读7.4k次。1. Object.keys(item); 获取到了key之后就可以遍历的时候直接使用这个进行遍历所有的key跟valuevar infoItem={ name:'xiaowu', age:'18',}//的出来的keys就是[name,age]var keys=Object.keys(infoItem);2. 通常用于以下实力中 <div *ngFor="let item of keys"> <div>{{item}}.._js 遍历对象的key
粒子群算法(PSO)求解路径规划_粒子群算法路径规划-程序员宅基地
文章浏览阅读2.2w次,点赞51次,收藏310次。粒子群算法求解路径规划路径规划问题描述 给定环境信息,如果该环境内有障碍物,寻求起始点到目标点的最短路径, 并且路径不能与障碍物相交,如图 1.1.1 所示。1.2 粒子群算法求解1.2.1 求解思路 粒子群优化算法(PSO),粒子群中的每一个粒子都代表一个问题的可能解, 通过粒子个体的简单行为,群体内的信息交互实现问题求解的智能性。 在路径规划中,我们将每一条路径规划为一个粒子,每个粒子群群有 n 个粒 子,即有 n 条路径,同时,每个粒子又有 m 个染色体,即中间过渡点的_粒子群算法路径规划
量化评价:稳健的业绩评价指标_rar 海龟-程序员宅基地
文章浏览阅读353次。所谓稳健的评估指标,是指在评估的过程中数据的轻微变化并不会显著的影响一个统计指标。而不稳健的评估指标则相反,在对交易系统进行回测时,参数值的轻微变化会带来不稳健指标的大幅变化。对于不稳健的评估指标,任何对数据有影响的因素都会对测试结果产生过大的影响,这很容易导致数据过拟合。_rar 海龟
IAP在ARM Cortex-M3微控制器实现原理_value line devices connectivity line devices-程序员宅基地
文章浏览阅读607次,点赞2次,收藏7次。–基于STM32F103ZET6的UART通讯实现一、什么是IAP,为什么要IAPIAP即为In Application Programming(在应用中编程),一般情况下,以STM32F10x系列芯片为主控制器的设备在出厂时就已经使用J-Link仿真器将应用代码烧录了,如果在设备使用过程中需要进行应用代码的更换、升级等操作的话,则可能需要将设备返回原厂并拆解出来再使用J-Link重新烧录代码,这就增加了很多不必要的麻烦。站在用户的角度来说,就是能让用户自己来更换设备里边的代码程序而厂家这边只需要提供给_value line devices connectivity line devices