自动化测试之八大元素定位方式(python3.10+selenium4)_自动化测试tag_name-程序员宅基地
技术标签: python 自动化测试 chrome Powered by 金山文档 自动化 测试工具 开发语言
一、元素定位的目的
元素的定位是自动化测试核心。要操作一个对象,首先要识别定位或找到这个对象。为了实现网页整体布局,我们先要知道,一个元素,是如何定位到页面上的某个位置的,这就是元素定位。
二、八大元素定位法
系统环境
Windows 11
python3.10.5
selenium 4.8.0
注意:以下每种定位方式均有一个案例来展现。
1、id定位元素
id是当前整个HTML页面中唯一的,所以可以通过id属性来唯一定位一个元素,是首选的元素定位方式。首先打开百度页面,通过右击->检查或者快捷键F12打开开发者工具,定位到百度搜索框的位置。然后通过send_key输入关键词,自动点击“百度一下”进行搜索,最后退出浏览器。通过该案例能够学会此定位元素方法。

from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com/")
# 定位到百度搜索框通过id定位元素的方式
# .send_keys()发送关键词
driver.find_element(By.ID, "kw").send_keys("python")
# 通过id定位到百度一下按钮,点击一下
driver.find_element(By.ID, "su").click()
# 延时3秒
sleep(3)
# 退出浏览器
driver.quit()
2、name元素定位
根据元素的name来定位属性,但name并不是唯一的。
name方式:1、元素中必须要有name的属性 2、name的属性在页面中如果是唯一的,那么可以准确的定位到元素(不是唯一的,默认返回的是第一个元素)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com/")
# 定位到百度搜索框通过name定位元素的方式
# name方式:1、元素中必须要有name的属性 2、name的属性在页面中如果是唯一的,那么可以准确的定位到元素(不是唯一的,默认返回的是第一个元素)
driver.find_element(By.NAME, "wd").send_keys("python")
# 通过id定位到百度一下按钮,点击一下
driver.find_element(By.ID, "su").click()
# 延时3秒
sleep(3)
# 退出浏览器
driver.quit()
3、class_name元素定位
根据Class定位属性,主要是用来元素进行分组,并对这一级元素设置相同的样式。所以class属性在当前html页面当中,也是不能唯一定位到一个元素的。
class_name定位元素:1、在元素中需要有class的属性;2、class的属性值不是唯一的,那么不能唯一的定位到指定的元素。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com/")
# 定位到百度搜索框通过class定位元素的方式
# class_name定位元素:1、在元素中需要有class的属性;2、class的属性值不是唯一的,那么不能唯一的定位到指定的元素
driver.find_element(By.CLASS_NAME, "s_ipt").send_keys("python")
# 通过id定位到百度一下按钮,点击一下
driver.find_element(By.ID, "su").click()
# 延时3秒
sleep(3)
# 退出浏览器
driver.quit()
4、tag_name元素定位
tag_name是通过标签名称来定位的,如<input>标签。
tag_name定位元素:标签名是会重复,默认返回的是第一个符合的元素。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.taobao.com/")
# 定位到百度搜索框通过tag_name定位元素的方式
# tag_name定位元素:1、标签名是会重复,默认返回的是第一个符合的元素
driver.find_element(By.TAG_NAME, "input").send_keys("三体")
# 延时3秒
sleep(3)
# 退出浏览器
driver.quit()
5、link_text元素定位
link_text 只能使用精准的匹配(a标签的全部文本内容)。
link_text定位:必须根据链接上完整的文本内容去进行定位。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com/")
# 定位到百度搜索框通过link_text定位元素的方式
# link_text定位元素:1、必须根据链接上完整的文本内容去进行定位。
driver.find_element(By.LINK_TEXT, "新闻").click()
# 延时3秒
sleep(3)
# 退出浏览器
driver.quit()
6、partial_link_text元素定位
partial_link_text可以使用精准或模糊匹配,如果使用模糊匹配最好能使用可以唯一的关键字;如果有多个值,默认返回第一个值。
partial_link_text定位:定位的链接文本内容在整个页面当中唯一的出现一次,那么可以准确定位到元素,否则默认返回第一个值。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com/")
# 定位到百度输入框,搜索热点新闻
driver.find_element(By.ID, "kw").send_keys("热点新闻")
# 定位到百度一下按钮,并且点击
driver.find_element(By.ID, "su").click()
# 停留3秒,加载页面
sleep(3)
# 从返回的结果页面,通过模糊匹配定位到包含了“腾讯网”的超连接
# partial_link_text定位:定位的链接文本内容在整个页面当中唯一的出现一次,那么可以准确定位到元素,否则默认返回第一个
# .click()点击的操作
driver.find_element(By.PARTIAL_LINK_TEXT, "腾讯网").click()
# 延时3秒
sleep(5)
# 退出浏览器
driver.quit()
7、xpath元素定位
7-1、xpath简介
xpath即是XML Path的简称,它是一门在XML文档中查找元素信息的语言。
7-2、使用xpath目的
在前面写的定位方式不能实现的时候使用。
id、name、class_name定位前提是要有这个属性,否则不能定位。
tag_name方式如果有很多相同的标签名,定位不方便。
link的定位方式只是针对超链接的。
7-3、xpath语法
xpath语法 |
|
表达式 |
说明 |
/aaa |
选取根节点为aaa的元素 |
/aaa/bbb |
选取aaa标签下的bbb标签 |
//aaa |
选取所有aaa的标签元素 |
//aaa/bbb |
选取所有父元素为aaa的bbb元素 |
. |
选取当前节点 |
.. |
选取当前节点的父节点 |
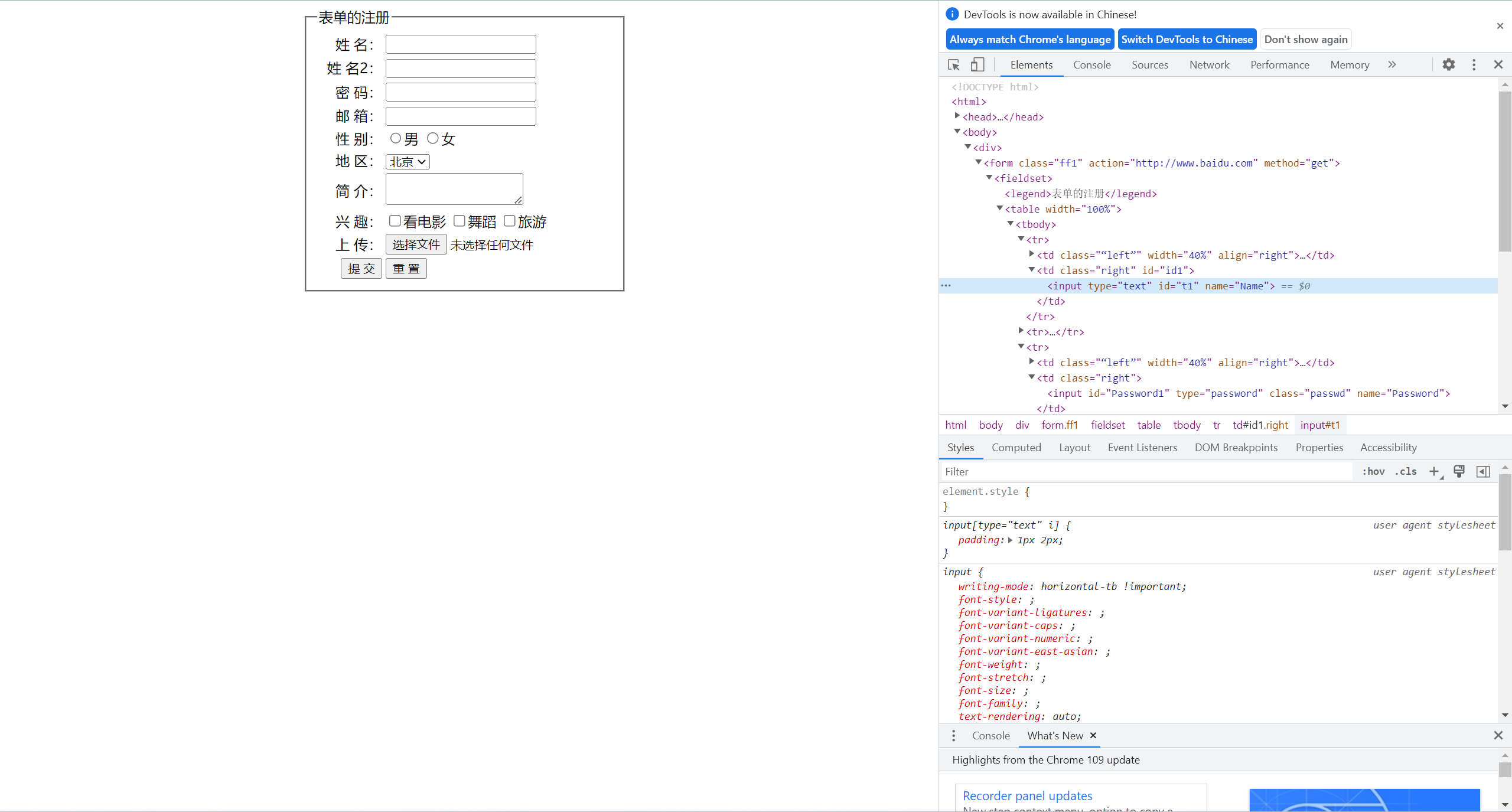
注意:以下方式大部分使用该案例。
7-4-1、xpath定位方式一(绝对路径)
语法:以单斜杠开头逐级开始编写,不能跳级。如:("html/body/div/div/form/input")。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# 定位到姓名输入框
# xpath定位方式一:绝对路径
driver.find_element(By.XPATH, "html/body/div/form/fieldset/table/tbody/tr/td/input").send_keys("admin")
# 延时3秒
sleep(5)
# 退出浏览器
driver.quit()
7-4-2、xpath定位方式二(相对路径)
相对路径是只给出元素路径的部分信息,在 html 的任意层次中寻找符合条件的元素。(元素名不知道,可用*)语法:以双斜杠开头,双斜杠后边跟元素名称。如://input。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# 定位到多行文本输入框(简介)
# xpath定位方式二:相对路径
driver.find_element(By.XPATH, "//textarea").send_keys("这是一个简介。")
# 延时3秒
sleep(5)
# 退出浏览器
driver.quit()
7-4-3、xpath定位方式三(路径结合属性)
语法://input[@id='id值']。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# 定位到密码输入框
# xpath定位方式三:路径结合属性的形式(定位到密码输入框)
driver.find_element(By.XPATH, "//input[@id='Password1']").send_keys("123456789")
# 延时3秒
sleep(5)
# 退出浏览器
driver.quit()
7-4-4、xpath定位方式四(文本内容匹配)
语法://a[text()="新闻"],标签为a文本信息为"新闻"。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get("https://www.hao123.com/")
# 延时3秒
sleep(3)
# xpath定位方式四:文本内容匹配(定位到hao123当中的京东链接)
driver.find_element(By.XPATH, "//a[text()='京东']").click()
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
7-4-5、xpath定位方式五(部分文本信息包含匹配)
语法://a[contains(text(),"新")] 或者 //a[contains(text(),"闻")]
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get("https://www.hao123.com/")
# 延时3秒
sleep(3)
# xpath定位方式五:部分文本内容进行匹配(定位到hao123当中的哔哩哔哩链接)
driver.find_element(By.XPATH, "//a[contains(text(), '哔哩')]").click()
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
7-4-6、xpath定位方式六(路径结合逻辑)
语法://标签名[@属性名='属性值' and @属性名='属性值']
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# xpath定位方式六:通过多个属性定位到姓名2输入框
driver.find_element(By.XPATH, "//input[@name='Name' and @id='t2']").send_keys("第二个姓名")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
7-4-7、xpath定位方式七(通过父级定位子级元素)
语法://标签名(或*)[@父级属性名='父级属性值']/input。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# xpath定位方式七:通过父级定位子级元素
driver.find_element(By.XPATH, "//td[@id='id1']/input").send_keys("通过父级定位到子级")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
7-4-8、xpath定位方式八(直接复制法)
通过手动定位到的标签,点击右击复制xpath元素,直接复制到代码里。如下所示。
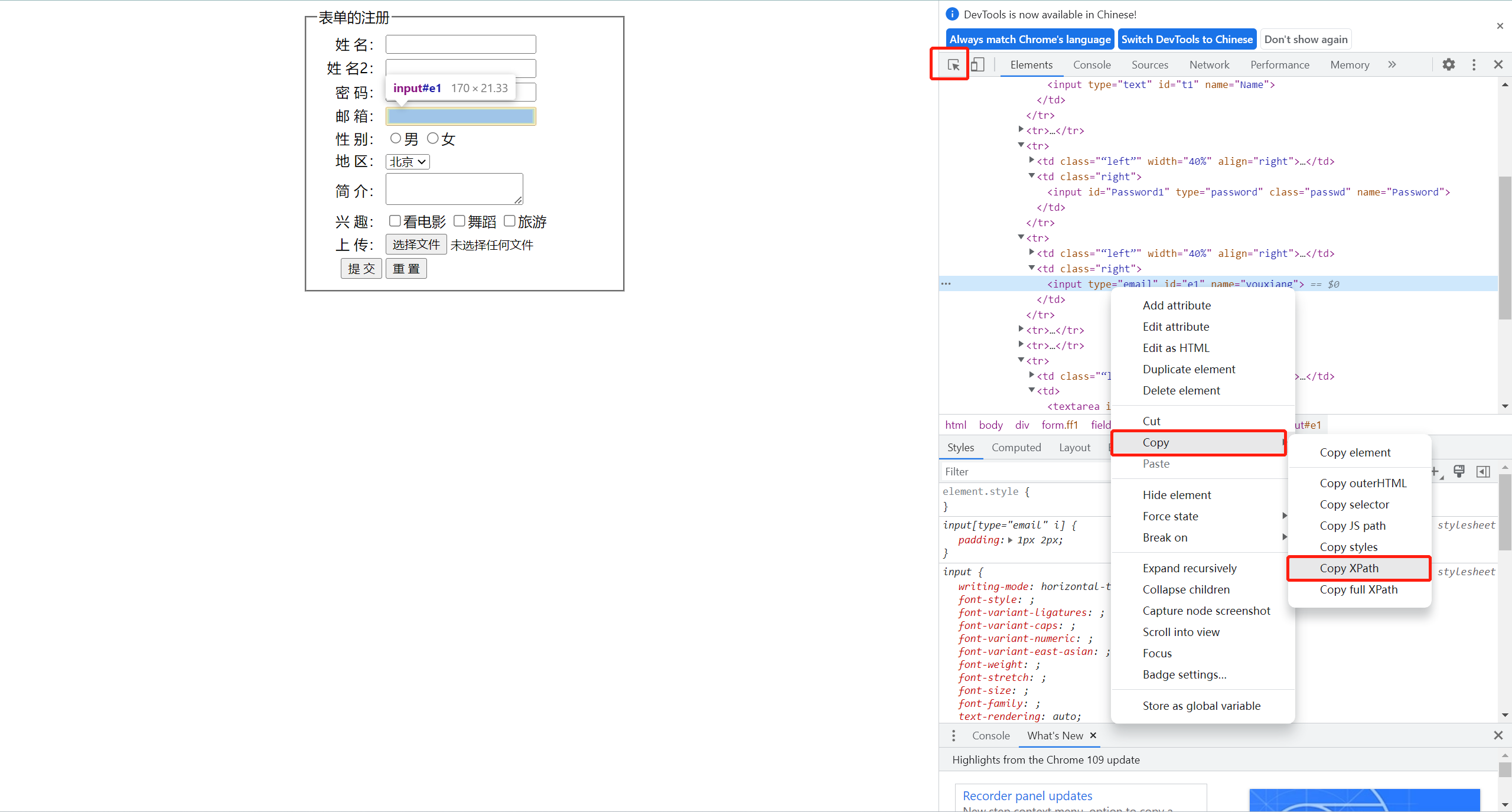
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# xpath定位方式七:通过父级定位子级元素
driver.find_element(By.XPATH, "//*[@id='e1']").send_keys("直接复制定位到邮箱")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
8、CSS选择器定位
8-1、CSS选择器简介
CSS是一种标记语言,在CSS标记语言中找元素使用CSS选择器,极力推荐使用CSS,CSS查找效率高,语法简单。
8-2、CSS选择器定位方式(十四种)
id选择器(语法:#id,如:#a1)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# 定位到姓名输入框
# css定位方式一:id选择器定位
driver.find_element(By.CSS_SELECTOR, "#t1").send_keys("CSS选择器")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
class选择器(语法:.class,如:.cA)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# 定位到密码输入框
# css定位方式二:class选择器定位(密码框)
driver.find_element(By.CSS_SELECTOR, ".passwd").send_keys("class")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
元素选择器(语法:element,如:input)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# css定位方式三:元素选择器定位(标签名定位)(定位到简介多行文本框)
driver.find_element(By.CSS_SELECTOR, "textarea").send_keys("这是元素选择器定位。")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
通用选择器(语法:*,用于匹配任何元素)
(无代码演示)
多元素选择器E,F(E,F同时匹配所有E元素或F元素,E和F之间用逗号分隔)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# css定位方式五:多元素选择器(同时定位到姓名和密码输入框)
# find_elements(By.CSS_SELECTOR, "元素")返回的是一个列表类型的元素,如果想定位到具体的元素,可以通过索引去拿(索引是从0开始)
driver.find_elements(By.CSS_SELECTOR, "#t1,.passwd")[1].send_keys("5201314")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
后代元素选择器E F(匹配所有属于E元素后代的F元素,E和F之间用空格分隔)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# css定位方式六:后代选择器(定位到多行文本输入框,简介)
# 后代选择器,可以隔代,可以通过父与子的关系定位,还可以通过爷爷与孙子的关系定位
driver.find_element(By.CSS_SELECTOR, "tr textarea").send_keys("这是后代选择器定位。")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
子元素选择器E>F(匹配所有E元素的子元素F)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# css定位方式七:子元素选择器(定位到多行文本输入框,简介)
# 子元素选择器是必须直接子级才可以定位,隔代则定位不了
driver.find_element(By.CSS_SELECTOR, "td>textarea").send_keys("子元素选择器定位。")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
毗邻元素选择器E+F(匹配紧随E元素之后的同级元素F,只匹配第一个)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class7\test02.html")
# css定位方式八:毗邻元素选择器(定位到表单test里面的input标签)
driver.find_element(By.CSS_SELECTOR, "p+input").send_keys("毗邻元素选择器")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
同级元素器E~F(E~F匹配所有在E元素之后的同级F元素)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class7\test02.html")
# css定位方式九:同级元素选择器(定位到表单test2里面的input标签)
driver.find_element(By.CSS_SELECTOR, "p~input").send_keys("同级元素选择器")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
标签名[属性名='属性值'](指定标签名下的符合[]里面属性条件的元素,区分大小写)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# css定位方式十:标签结合属性定位元素:标签名[属性名='属性值']
driver.find_element(By.CSS_SELECTOR, "input[id='Password1']").send_keys("123456789")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
标签名[属性名^='a'](属性值以a开头的标签元素,区分大小写)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# css定位方式十一:标签名结合属性定位元素:标签名[属性名^='a'](属性值以a开头)
# 案例:定位到第一个表单注册页面的密码输入框
driver.find_element(By.CSS_SELECTOR, "input[name^='P']").send_keys("123456789")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
标签名[属性名$='a'](属性的值以a结尾的指定标签名的元素,区分大小写)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# css定位方式十二:标签名结合属性定位元素:标签名[属性名$='a'](属性值以a结尾)
# 案例:定位到第一个表单注册页面的密码输入框
driver.find_element(By.CSS_SELECTOR, "input[name$='d']").send_keys("123456789")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
标签名[属性名*='a'](属性的值包括a 的指定标签的元素)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# css定位方式十三:标签名结合属性定位元素:标签名[属性名*='a'](属性值包含a)
# 案例:定位到第一个表单注册页面的密码输入框
driver.find_element(By.CSS_SELECTOR, "input[name*='w']").send_keys("123456789")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
标签名[属性1='a'][属性2*='b']
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# css定位方式十四:标签名结合多个属性定位:标签名[属性1='a'][属性2*='b']
# 案例:定位到第一个表单注册页面的姓名2输入框
driver.find_element(By.CSS_SELECTOR, "input[name='Name'][id='t2']").send_keys("123456789")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
三、总结
极力推荐使用CSS选择器定位。原因:CSS查找效率高,语法简单。如果有ID属性,使用#id。如果没有id属性,使用其他有的属性(能代表唯一的属性),如果属性都代表不了唯一,使用层级。如果CSS定位解决不了,使用xpath定位方式。
本博主还整合了以上的演示方法源码,可供大家参考

智能推荐
前端开发之vue-grid-layout的使用和实例-程序员宅基地
文章浏览阅读1.1w次,点赞7次,收藏34次。vue-grid-layout的使用、实例、遇到的问题和解决方案_vue-grid-layout
Power Apps-上传附件控件_powerapps点击按钮上传附件-程序员宅基地
文章浏览阅读218次。然后连接一个数据源,就会在下面自动产生一个添加附件的组件。把这个控件复制粘贴到页面里,就可以单独使用来上传了。插入一个“编辑”窗体。_powerapps点击按钮上传附件
C++ 面向对象(Object-Oriented)的特征 & 构造函数& 析构函数_"object(cnofd[\"ofdrender\"])十条"-程序员宅基地
文章浏览阅读264次。(1) Abstraction (抽象)(2) Polymorphism (多态)(3) Inheritance (继承)(4) Encapsulation (封装)_"object(cnofd[\"ofdrender\"])十条"
修改node_modules源码,并保存,使用patch-package打补丁,git提交代码后,所有人可以用到修改后的_修改 node_modules-程序员宅基地
文章浏览阅读133次。删除node_modules,重新npm install看是否成功。在 package.json 文件中的 scripts 中加入。修改你的第三方库的bug等。然后目录会多出一个目录文件。_修改 node_modules
【】kali--password:su的 Authentication failure问题,&sudo passwd root输入密码时Sorry, try again._password: su: authentication failure-程序员宅基地
文章浏览阅读883次。【代码】【】kali--password:su的 Authentication failure问题,&sudo passwd root输入密码时Sorry, try again._password: su: authentication failure
整理5个优秀的微信小程序开源项目_微信小程序开源模板-程序员宅基地
文章浏览阅读1w次,点赞13次,收藏97次。整理5个优秀的微信小程序开源项目。收集了微信小程序开发过程中会使用到的资料、问题以及第三方组件库。_微信小程序开源模板
随便推点
Centos7最简搭建NFS服务器_centos7 搭建nfs server-程序员宅基地
文章浏览阅读128次。Centos7最简搭建NFS服务器_centos7 搭建nfs server
Springboot整合Mybatis-Plus使用总结(mybatis 坑补充)_mybaitis-plus ruledataobjectattributemapper' and '-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏3次。前言mybatis在持久层框架中还是比较火的,一般项目都是基于ssm。虽然mybatis可以直接在xml中通过SQL语句操作数据库,很是灵活。但正其操作都要通过SQL语句进行,就必须写大量的xml文件,很是麻烦。mybatis-plus就很好的解决了这个问题。..._mybaitis-plus ruledataobjectattributemapper' and 'com.picc.rule.management.d
EECE 1080C / Programming for ECESummer 2022 Laboratory 4: Global Functions Practice_eece1080c-程序员宅基地
文章浏览阅读325次。EECE 1080C / Programming for ECESummer 2022Laboratory 4: Global Functions PracticePlagiarism will not be tolerated:Topics covered:function creation and call statements (emphasis on global functions)Objective:To practice program development b_eece1080c
洛谷p4777 【模板】扩展中国剩余定理-程序员宅基地
文章浏览阅读53次。被同机房早就1年前就学过的东西我现在才学,wtcl。设要求的数为\(x\)。设当前处理到第\(k\)个同余式,设\(M = LCM ^ {k - 1} _ {i - 1}\) ,前\(k - 1\)个的通解就是\(x + i * M\)。那么其实第\(k\)个来说,其实就是求一个\(y\)使得\(x + y * M ≡ a_k(mod b_k)\)转化一下就是\(y * M ...
android 退出应用没有走ondestory方法,[Android基础论]为何Activity退出之后,系统没有调用onDestroy方法?...-程序员宅基地
文章浏览阅读1.3k次。首先,问题是如何出现的?晚上复查代码,发现一个activity没有调用自己的ondestroy方法我表示非常的费解,于是我检查了下代码。发现再finish代码之后接了如下代码finish();System.exit(0);//这就是罪魁祸首为什么这样写会出现问题System.exit(0);////看一下函数的原型public static void exit (int code)//Added ..._android 手动杀死app,activity不执行ondestroy
SylixOS快问快答_select函数 导致堆栈溢出 sylixos-程序员宅基地
文章浏览阅读894次。Q: SylixOS 版权是什么形式, 是否分为<开发版税>和<运行时版税>.A: SylixOS 是开源并免费的操作系统, 支持 BSD/GPL 协议(GPL 版本暂未确定). 没有任何的运行时版税. 您可以用她来做任何 您喜欢做的项目. 也可以修改 SylixOS 的源代码, 不需要支付任何费用. 当然笔者希望您可以将使用 SylixOS 开发的项目 (不需要开源)或对 SylixOS 源码的修改及时告知笔者.需要指出: SylixOS 本身仅是笔者用来提升自己水平而开发的_select函数 导致堆栈溢出 sylixos