【k8s】【Prometheus】_prometheus导入json-程序员宅基地
技术标签: kubernetes 容器 云玩家-K8S&docker prometheus
环境
k8s v1.18.0
192.168.79.31 master
192.168.79.32 node-1
192.168.79.33 node-2
一、Prometheus 对 kubernetes 的监控
1.1 node-exporter 组件安装和配置
node-exporter 可以采集机器(物理机、虚拟机、云主机等)的监控指标数据,能够采集到的指标包括 CPU, 内存,磁盘,网络,文件数等信息。
安装:
kubectl create namespace monitor-sa
docker load -i node-exporter.tar.gz
node-exporter.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitor-sa
labels:
name: node-exporter
spec:
selector:
matchLabels:
name: node-exporter
template:
metadata:
labels:
name: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
containers:
- name: node-exporter
image: prom/node-exporter:v0.16.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9100
resources:
requests:
cpu: 0.15
securityContext:
privileged: true
args:
- --path.procfs #配置挂载宿主机(node 节点)的路径
- /host/proc
- --path.sysfs #配置挂载宿主机(node 节点)的路径
- /host/sys
- --collector.filesystem.ignored-mount-points #通过正则表达式忽略某些文件系统挂载点的信息收集
- '"^/(sys|proc|dev|host|etc)($|/)"'
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
#解释:
hostNetwork、hostIPC、hostPID 都为 True 时,表示这个 Pod 里的所有容器,会直接使用宿主机的网络,直接与宿主机进行 IPC(进程间通信)通信,可以看到宿主机里正在运行的所有进程。
加入了 hostNetwork:true 会直接将我们的宿主机的 9100 端口映射出来,从而不需要创建 service 在我们的宿主机上就会有一个 9100 的端口

1.2 通过 node-exporter 采集数据
curl http://主机 ip:9100/metrics
curl http://192.168.79.31:9100/metrics | grep node_cpu_seconds
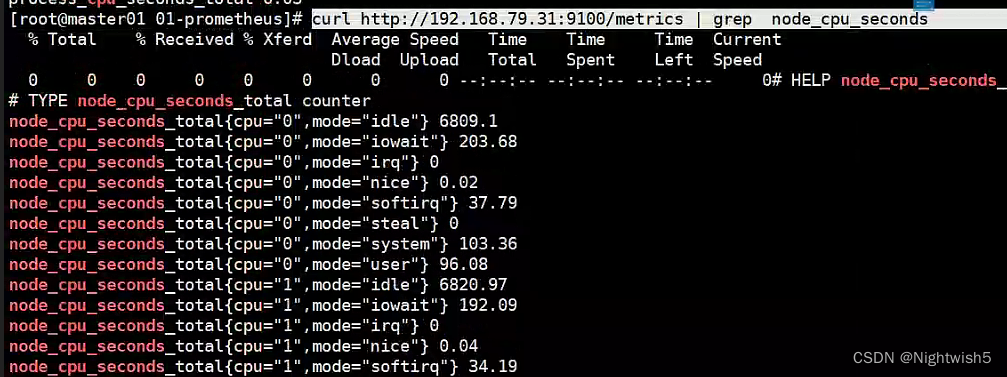
#HELP:解释当前指标的含义,上面表示在每种模式下 node 节点的 cpu 花费的时间,以 s 为单位
#TYPE:说明当前指标的数据类型,上面是 counter 类型
node_cpu_seconds_total{
cpu="0",mode="idle"} :
cpu0 上 idle 进程占用 CPU 的总时间,CPU 占用时间是一个只增不减的度量指标,从类型中也可以看
出 node_cpu 的数据类型是 counter(计数器) 。counter 计数器:只是采集递增的指标
[root@master01 01-prometheus]# curl http://192.168.79.31:9100/metrics | grep node_load
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 95166 100 95166 0 0 13.0M 0 --:--:-- --:--:-- --:--:-- 15.1M
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 0.28
node_load1 该指标反映了当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的
使用而变化,因此 node_load1 反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指
标类型为 gauge(标准尺寸)
gauge 标准尺寸:统计的指标可增加可减少
二、Prometheus server 安装和配置
2.1 创建 sa 账号,对 sa 做 rbac 授权
kubectl create serviceaccount monitor -n monitor-sa
kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
监控的有:
job_name:
kubernetes-node
kubernetes-node-cadvisor
kubernetes-apiserver
kubernetes-service-endpoints
将 docker load -i prometheus-2-2-1.tar.gz上传到node-1 ,由于prometheus-dp.yaml指定了nodeName, 可根据情况弄。
并 mkdir /data && chmod 777 /data/
#一些补充:
#查看token
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep default | awk '{print $1}')
#查看ca.crt证书
kubectl config view --raw=true | grep -oP "(?<=certificate-authority-data:\s).+" | base64 -d > /usr/local/share/ca-certificates/kubernetes.crt
update-ca-certificates
#根据实际情况写: 二进制部署k8s和 kubeadm部署k8s, 这两文件位置有所不同。
#/etc/kubernetes/pki/ca.crt
#/etc/kubernetes/pki/token
上面这段话/路径是错误的,当时没理解,以为是master,node1,node2节点上的ca.crt和token 。有丶臊皮。
不然报错:
Prometheus的target页面中 kubernetes-apiserver报错 Get https://192.168.79.31:6443/metrics: x509: certificate signed by unknown authority
和
Prometheus出现 Get https://192.168.79.31:6443/metrics: unable to read bearer token file /etc/kubernetes/pki/token: open /etc/kubernetes/pki/token: no such file or directory
下面cfg的详细解释, 《Prometheus构建企业级监控系统》的19页
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
#下图是pod(Prometheus-server)里面自身带有的文件,所以要写这个绝对路径

2.2 prometheus-cfg.yaml
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitor-sa
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs:
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-node-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
2.3 prometheus-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-server
namespace: monitor-sa
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
component: server
#matchExpressions:
#- {key: app, operator: In, values: [prometheus]}
#- {key: component, operator: In, values: [server]}
template:
metadata:
labels:
app: prometheus
component: server
annotations:
prometheus.io/scrape: 'false'
spec:
nodeName: node-1
serviceAccountName: monitor
containers:
- name: prometheus
image: prom/prometheus:v2.2.1
imagePullPolicy: IfNotPresent
command:
- prometheus
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.path=/prometheus
- --storage.tsdb.retention=720h
- --web.enable-lifecycle
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: /etc/prometheus/prometheus.yml
name: prometheus-config
subPath: prometheus.yml
- mountPath: /prometheus/
name: prometheus-storage-volume
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
items:
- key: prometheus.yml
path: prometheus.yml
mode: 0644
- name: prometheus-storage-volume
hostPath:
path: /data
type: Directory
2.4 prometheus-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitor-sa
labels:
app: prometheus
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
protocol: TCP
selector:
app: prometheus
component: server
2.5 访问Prometheus server
http://192.168.79.32:32732/graph 和status --> targets页面
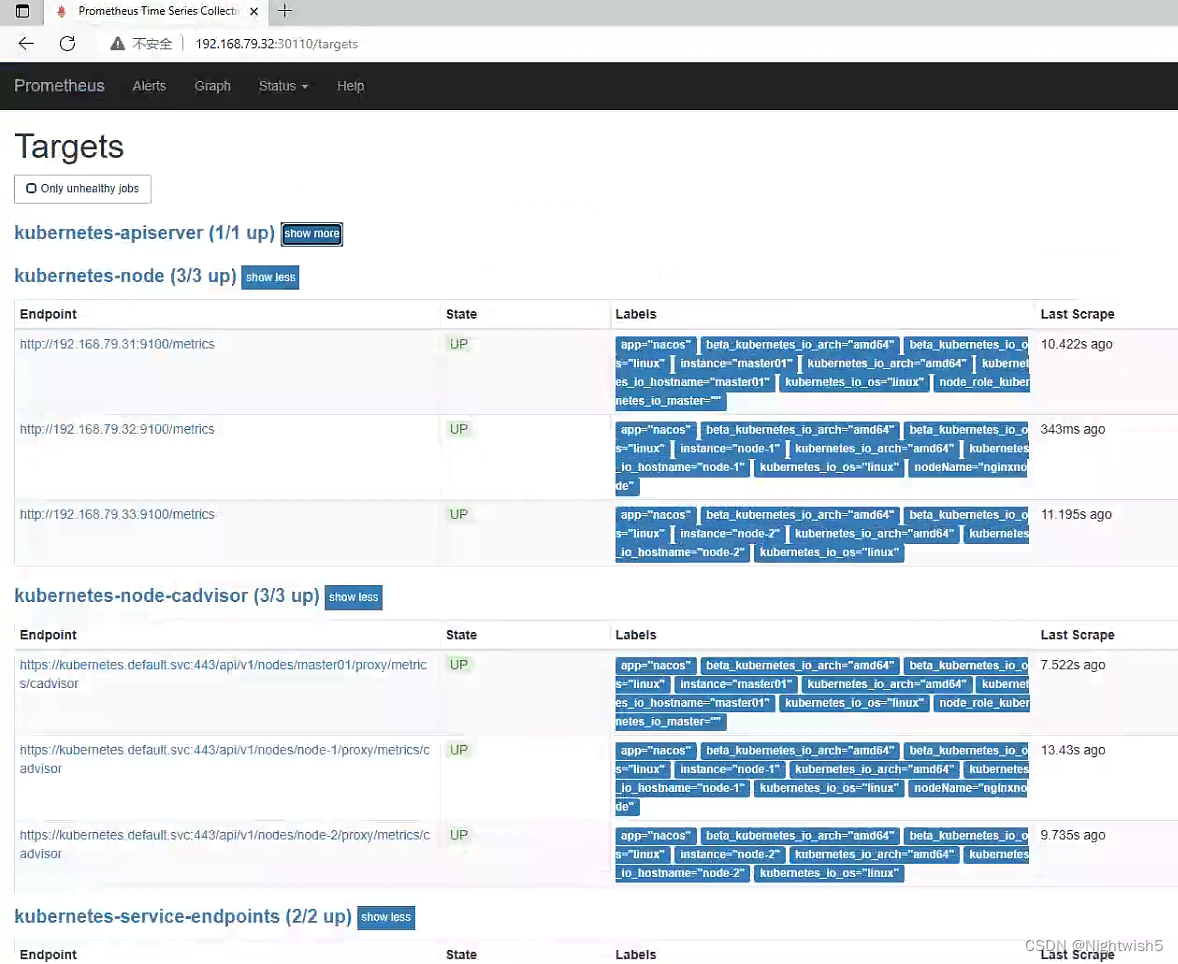
一些细节:
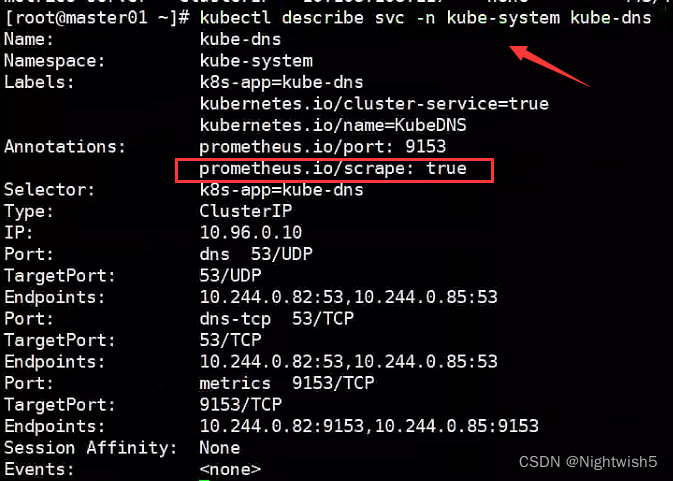
根据svc的annotations来监控到,如果该annotations有prometheus.io/scrape: true,则监控抓取数据
kubectl describe svc -n kube-system kube-dns (例子)
---》 prometheus.io/scrape: true
2.6 Prometheus 热加载
热加载命令:
curl -X POST http://10.244.121.4:9090/-/reload
#这个IP:9090 是: kubectl get pods -n monitor-sa -owide -l app=prometheus
#但热加载速度比较慢,可以暴力重启(先delete,后apply ) prometheus-server
kubectl delete -f prometheus-cfg.yaml
kubectl delete -f prometheus-deploy.yaml
kubectl apply -f prometheus-cfg.yaml
kubectl apply -f prometheus-deploy.yaml
三、安装UI界面grafana
docker load -i heapster-grafana-amd64_v5_0_4.tar.gz
3.1 01-grafana-dp.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: grafana
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
containers:
- name: grafana
image: k8s.gcr.io/heapster-grafana-amd64:v5.0.4
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- name: ca-certificates
mountPath: /etc/ssl/certs
readOnly: true
- name: grafana-storage
mountPath: /var
env:
- name: INFLUXDB_HOST
value: monitoring-influxdb
- name: GF_SERVER_HTTP_PORT
value: "3000"
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
value: /
volumes:
- name: ca-certificates
hostPath:
path: /etc/ssl/certs
- name: grafana-storage
emptyDir: {
}
3.2 02-grafana-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-grafana
name: monitoring-grafana
namespace: kube-system
spec:
ports:
- port: 80
targetPort: 3000
selector:
k8s-app: grafana
type: NodePort

访问grafana
http://192.168.79.31:32671/?orgId=1
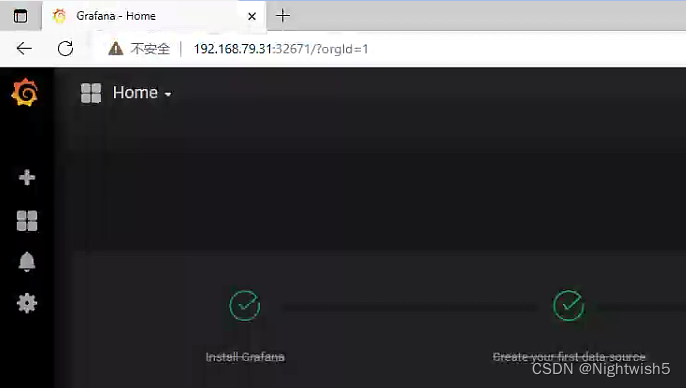
3.3 配置 grafana 界面:
选择 Create your first data source
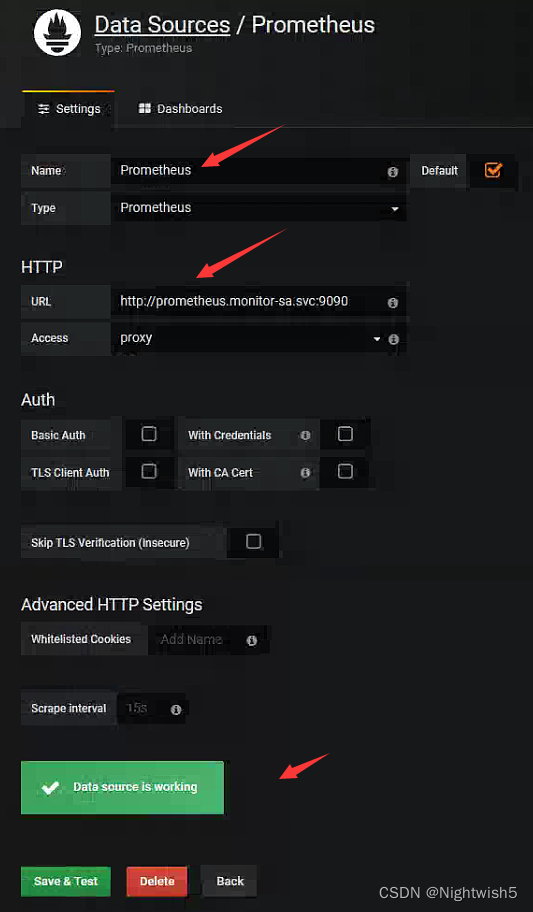
[root@master01 02-grafana]# dig @10.96.0.10 prometheus.monitor-sa.svc.cluster.local +short
10.107.214.53
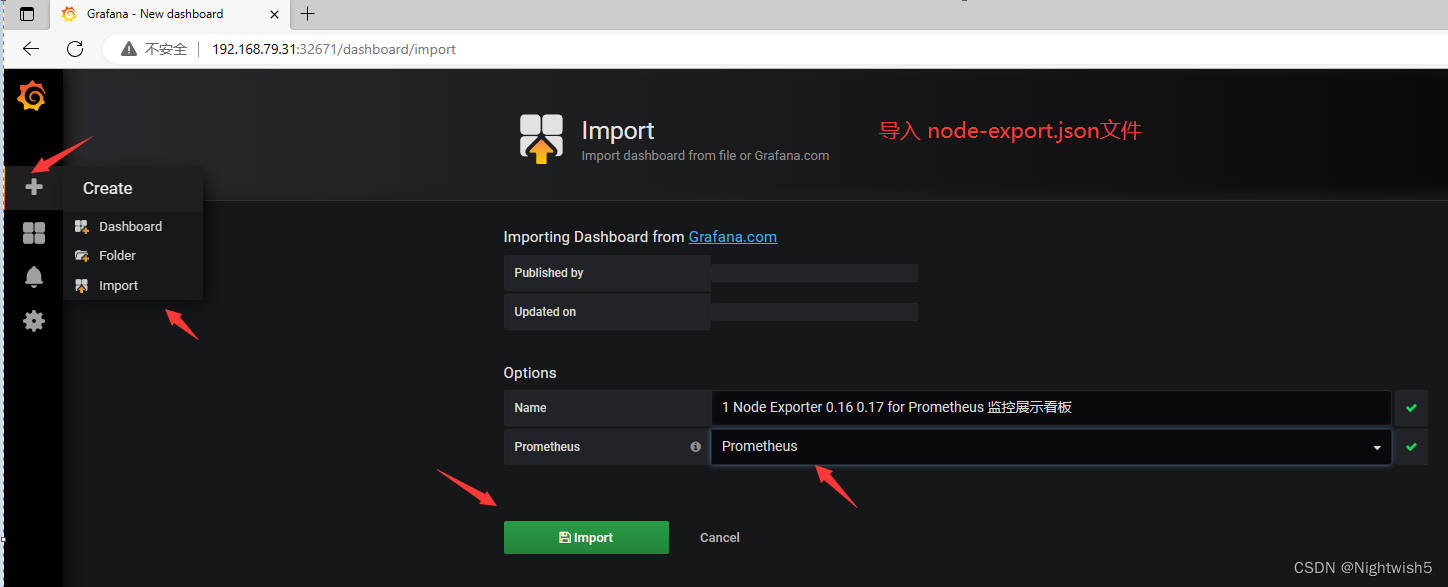
导入监控模板
获取监控模板地址:
https://grafana.com/dashboards?dataSource=prometheus&search=kubernetes
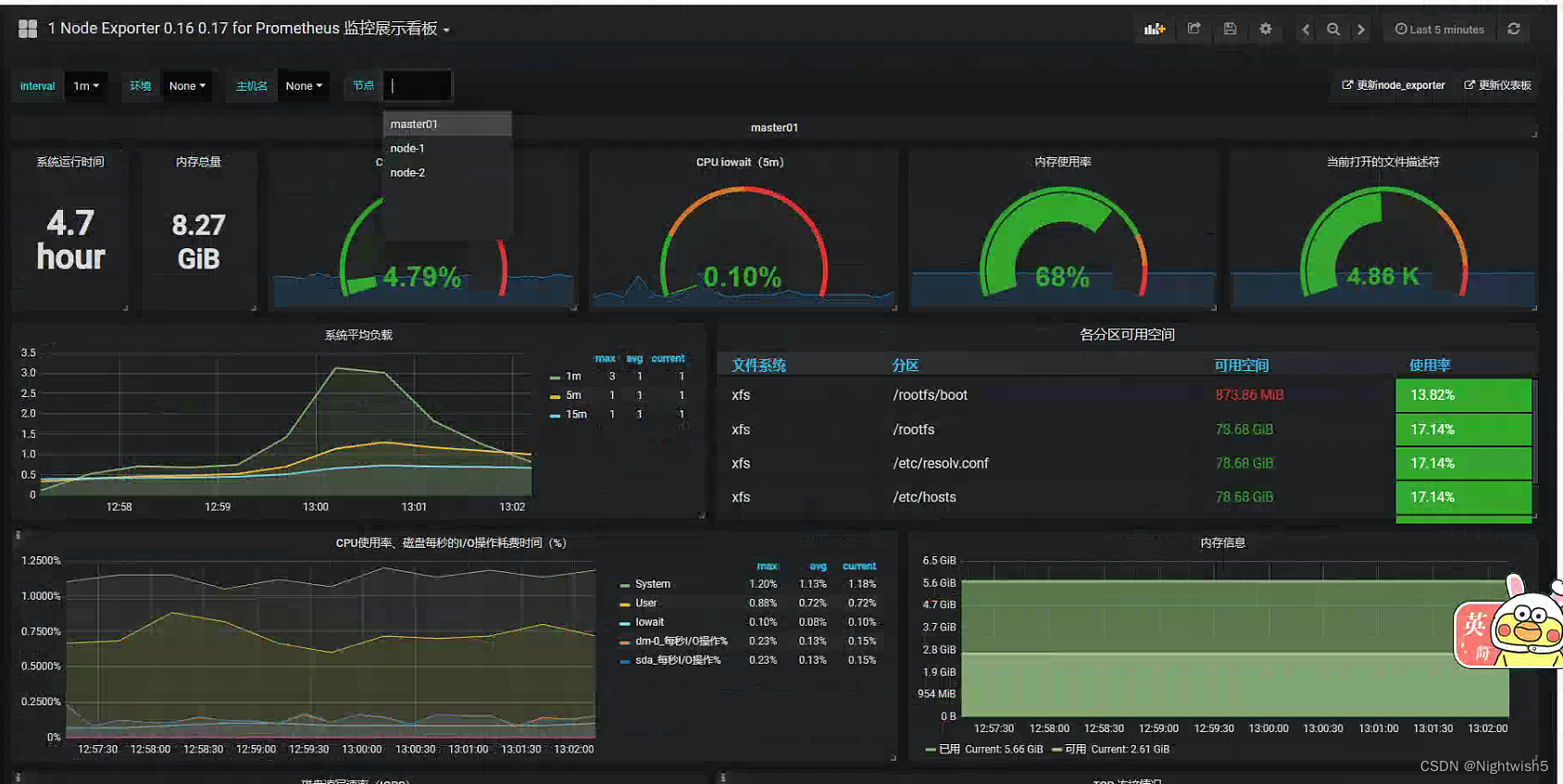
效果:
扩展:如果 Grafana 导入 Prometheus模板 之后,发现有的仪表盘没有数据,如何排查?
1、打开 grafana 界面,找到仪表盘对应无数据的图标 ,edit
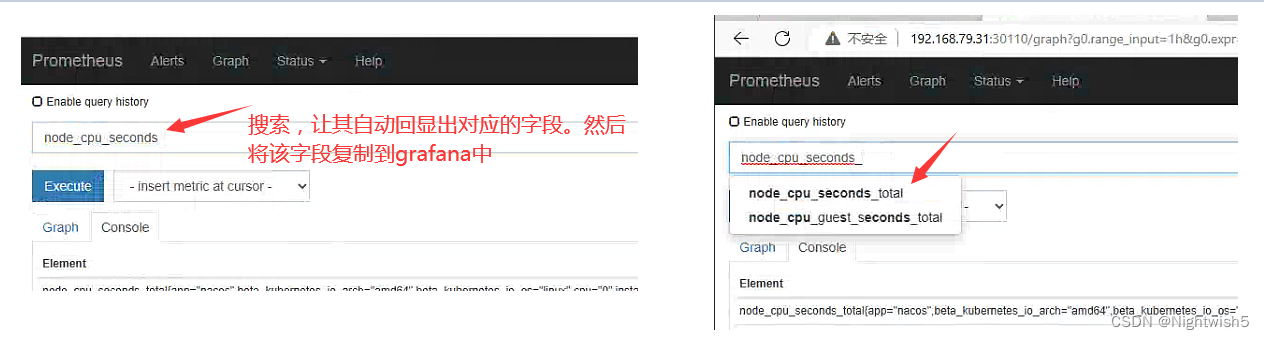
node_cpu_seconds_total 就是 grafana 上采集的 cpu 的时间,需要到 prometheus ui 界面看看采集的指标是否是 node_cpu_seconds_total
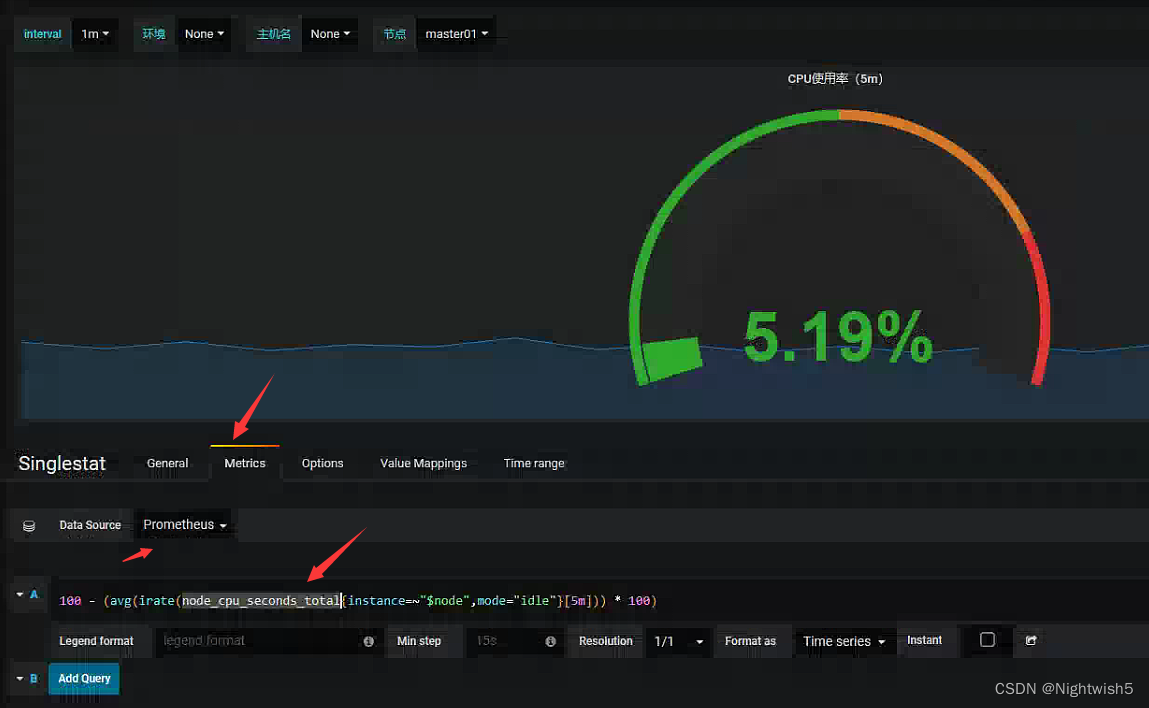
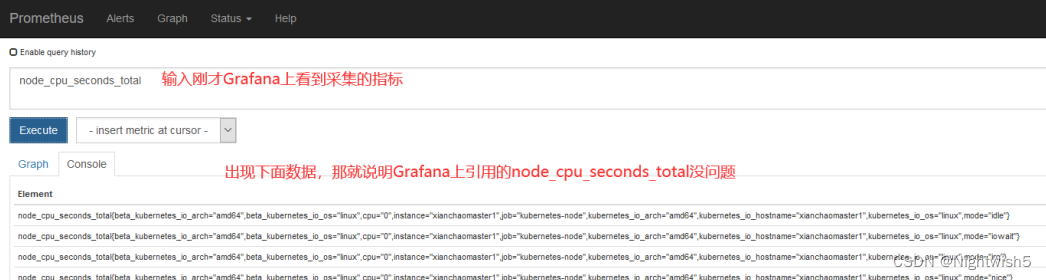
如果在 prometheus ui 界面输入 node_cpu_seconds_total 没有数据,那就看看是不是 prometheus采集的数据是 node_cpu_seconds_totals,怎么看呢?
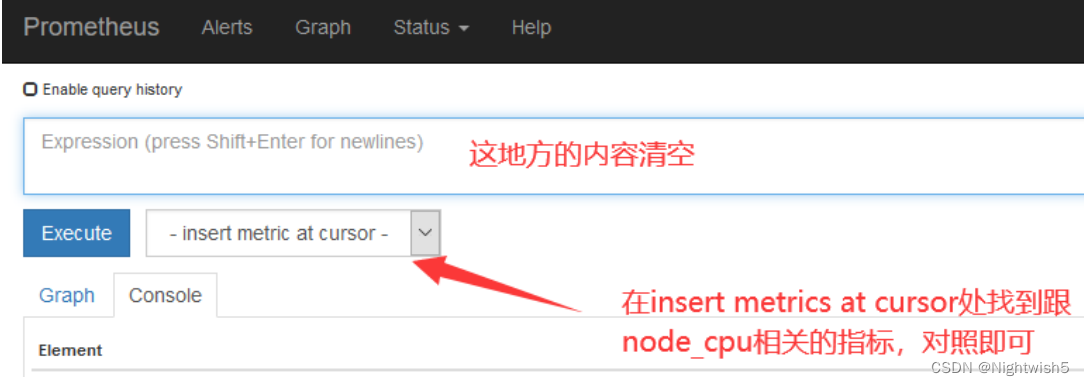
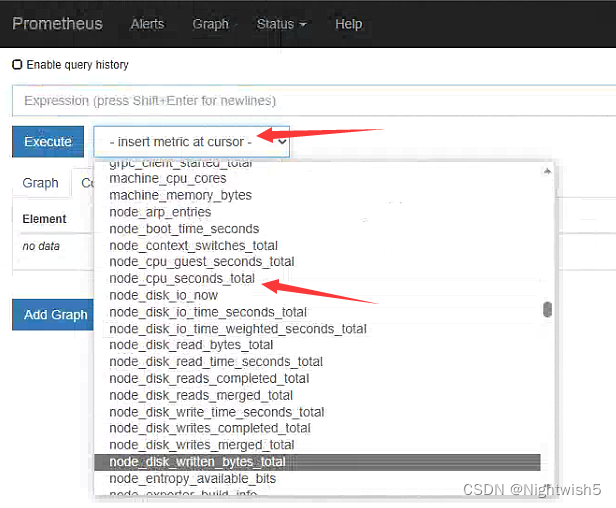
4、安装 kube-state-metrics 组件
kube-state-metrics概念:
kube-state-metrics 通过监听 API Server 生成有关资源对象的状态指标,比如 Deployment、Node、Pod。主要关注的是业务相关的一些元数据,比如 Deployment、Pod、副本状态等;调度了多少个 replicas?现在可用的有几个?多少个 Pod 是 running/stopped/terminated 状态?Pod 重启了多少次?有多少 job 在运行中。
4.1 kube-state-metrics-rbac.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
rules:
- apiGroups: [""]
resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"]
verbs: ["list", "watch"]
- apiGroups: ["extensions"]
resources: ["daemonsets", "deployments", "replicasets"]
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources: ["statefulsets"]
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources: ["cronjobs", "jobs"]
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources: ["horizontalpodautoscalers"]
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
4.2 kube-state-metrics-dp.yaml
docker load -i kube-state-metrics_1_9_0.tar.gz
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: quay.io/coreos/kube-state-metrics:v1.9.0
ports:
- containerPort: 8080
4.3 kube-state-metrics-svc.yaml
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: 'true'
name: kube-state-metrics
namespace: kube-system
labels:
app: kube-state-metrics
spec:
ports:
- name: kube-state-metrics
port: 8080
protocol: TCP
selector:
app: kube-state-metrics
部署成功后,Prometheus-server的target变化:
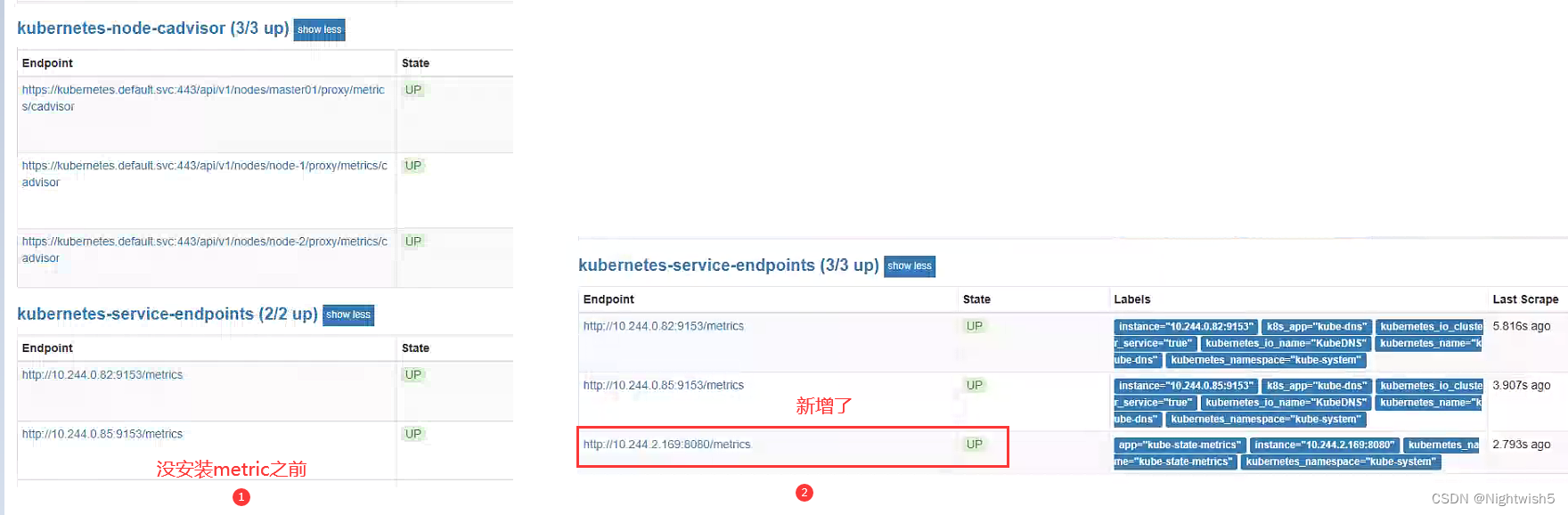
4.4 导入json文件
在 grafana web 界面导入
导入 Kubernetes Cluster (Prometheus)-1577674936972.json 文件
和 Kubernetes cluster monitoring (via Prometheus) (k8s 1.16)-1577691996738.json
第一个:Kubernetes Cluster (Prometheus)-1577674936972.json 文件:
界面: (等下处理这个 N/A)
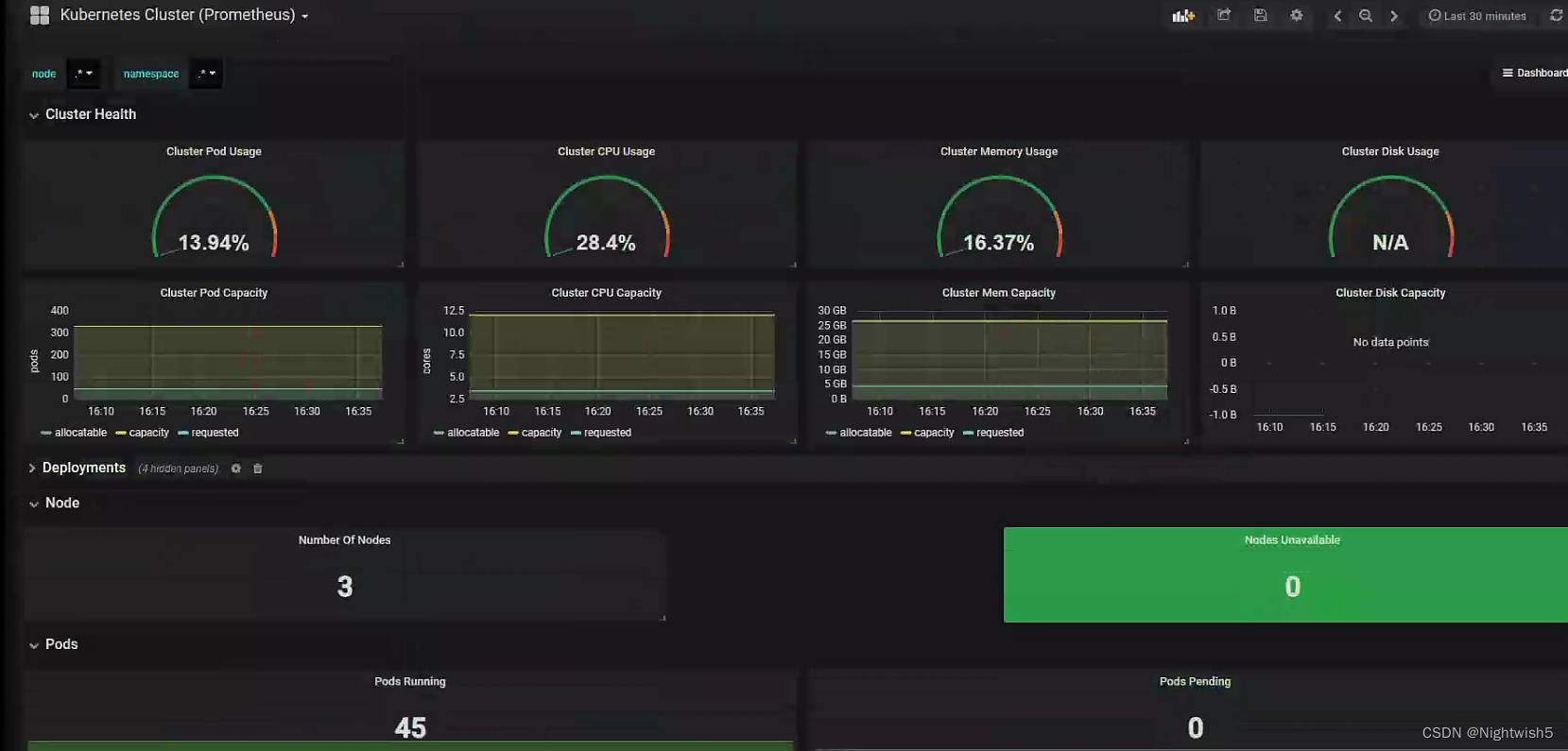
处理N/A情况:

根据grafana-server的查询框提示,改成:
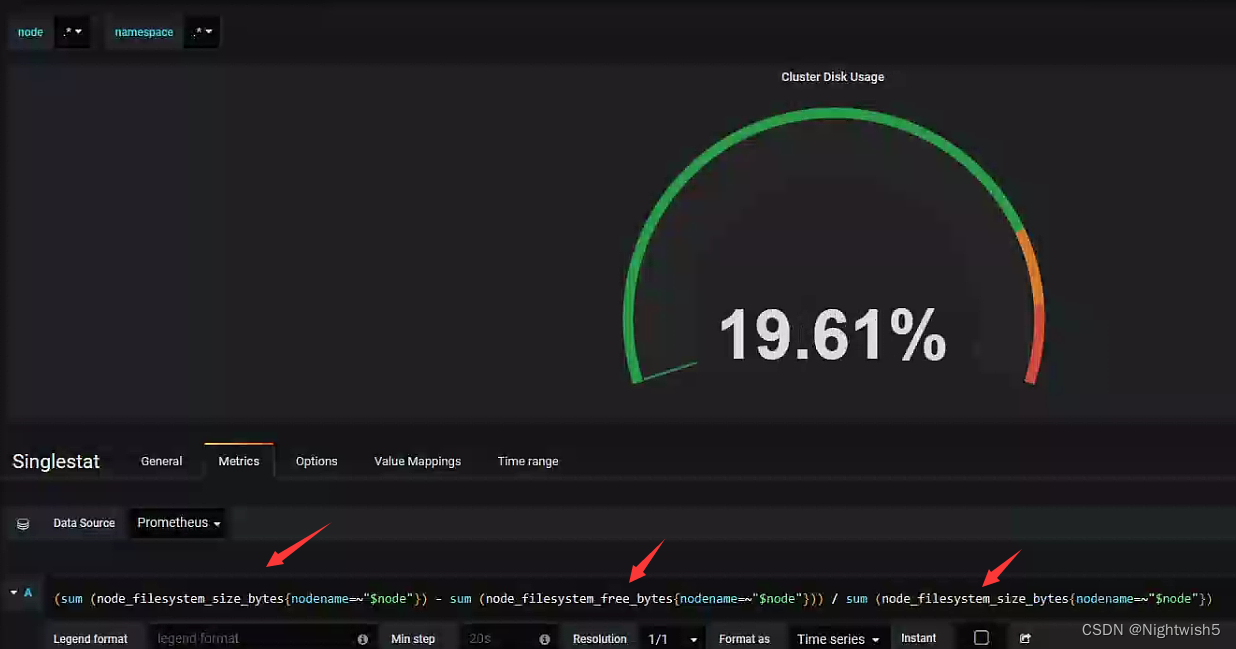
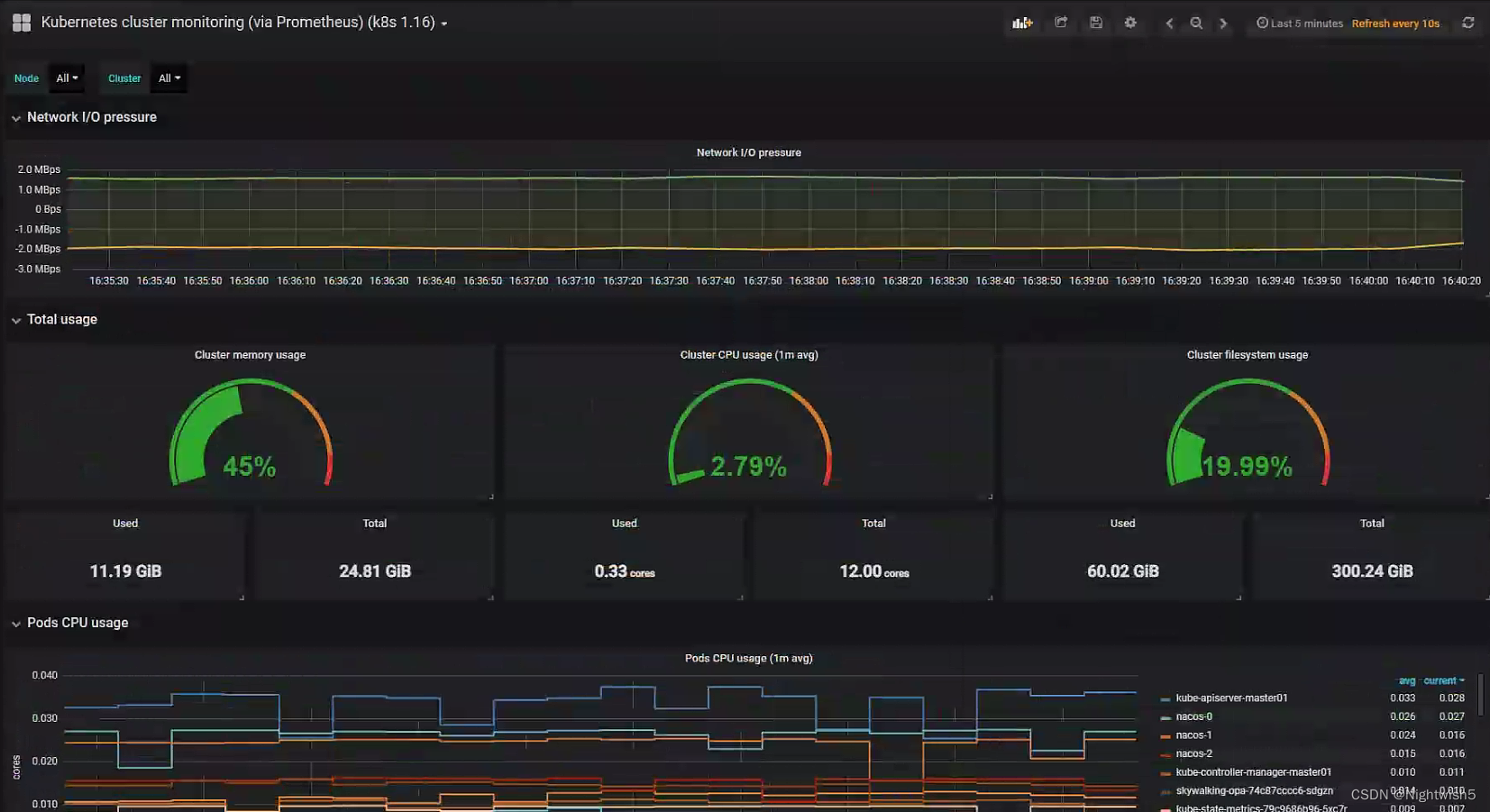
第二个:Kubernetes cluster monitoring (via Prometheus) (k8s 1.16)-1577691996738.json:
界面:
智能推荐
隐藏导航区虚拟按键-程序员宅基地
文章浏览阅读565次。RK3399平台 Android6.0diff --git a/core/res/res/values/dimens.xml b/core/res/res/values/dimens.xmlold mode 100644new mode 100755index 8635a4f..cecd19e--- a/core/res/res/values/dimens.xml+++ b/core...
SpringBoot + MyBatis + MySql利用 aop 实现读写分离-程序员宅基地
文章浏览阅读413次。前几个月做了一个项目,但是目前只部署到了一台服务器上面,所以我总感觉会出点问题,特别是数据库那一块,后期数据量大起来了以后,这一块应该是一个比较大的瓶颈,所以未雨绸缪,先把AOP实现读写分离那一块实现了,以后需要的时候再加上去就行了。本人菜鸡,本科还没毕业,希望各位大佬嘴下留情。SpringBoot 版本:<parent> <groupId>org.spr...
python-opencv之形态学操作(腐蚀和膨胀)原理详解-程序员宅基地
文章浏览阅读7.2k次,点赞2次,收藏38次。python-opencv之形态学操作(腐蚀和膨胀)原理详解
如何计算基因表达中的Fold Change值?_fold change怎么算-程序员宅基地
文章浏览阅读4.9w次,点赞3次,收藏51次。1、差异表达基因分析:差异倍数(fold change), 差异的显著性(P-value) | 火山图https://www.cnblogs.com/leezx/p/7132099.html2、Fold Change和t分布(重点,有讲到原理)https://www.cnblogs.com/daimakun/p/5139711.html3、Bioconductor分析基因芯片数据..._fold change怎么算
Linux应用程序怎么创建proc,Linux-什么时候创建/ proc / PID?-程序员宅基地
文章浏览阅读64次。我正在编写一个Bash脚本来监视进程并检测它何时崩溃.为此,我正在监视/ proc目录;start_my_process;my_process_id=$!;until [[ ! -d "/proc/$my_process_pid" ]]; do# alert the process is dead and restart it...done我能保证在Bash完成执行命令以启动进程之前,将在/ pr..._/proc节点什么时候写
winXP vc6行号显示插件-VC6LineNumberAddin方法-可用-无需注册-程序员宅基地
文章浏览阅读107次。winXP vc6行号显示插件-VC6LineNumberAddin方法-可用-无需注册 1.VC6LineNumberAddin 修改日期是2008.6.3可用,其它需要注册码http://codefish.googlecode.com/files/VC%E6..._vc6linenumberaddin 注册码
随便推点
算法导论 第四章:分治法(一)_分治法的地位-程序员宅基地
文章浏览阅读746次。无论是在生活中还是在计算机科学中,“分而治之”的思想占据着举足轻重的地位,其原理如下: 1)将一个复杂的问题分成若干个相同或相似的子问题 2)递归求解子问题,当子问题规模很小时,可直接求解 3)将所有子问题的解合并,即为原问题的解 两个例子:1.最大子数组问题(maximum-subarray problem) 即一段非空的,连续的有最大和的一_分治法的地位
ESP32网络开发实例-HTTP-GET请求-程序员宅基地
文章浏览阅读1.5k次,点赞5次,收藏2次。在本文中,我们将介绍如使用ESP32向 ThingSpeak 和 openweathermap.org 等常用 API 发出 HTTP GET 请求。
uni-app获取dom节点信息-程序员宅基地
文章浏览阅读9.5k次,点赞17次,收藏29次。uni-app获取dom节点信息
CentOS7 部署 RAID 磁盘阵列-程序员宅基地
文章浏览阅读605次,点赞15次,收藏26次。即使是面试跳槽,那也是一个学习的过程。只有全面的复习,才能让我们更好的充实自己,武装自己,为自己的面试之路不再坎坷!今天就给大家分享一个Github上全面的Java面试题大全,就是这份面试大全助我拿下大厂Offer,月薪提至30K!我也是第一时间分享出来给大家,希望可以帮助大家都能去往自己心仪的大厂!为金三银四做准备!
7-2 模拟EXCEL排序 (25分) PTA-程序员宅基地
文章浏览阅读1k次。7-2 模拟EXCEL排序 (25分)Excel可以对一组纪录按任意指定列排序。现请编写程序实现类似功能。输入格式:输入的第一行包含两个正整数N(≤105 ) 和C,其中N是纪录的条数,C是指定排序的列号。之后有 N行,每行包含一条学生纪录。每条学生纪录由学号(6位数字,保证没有重复的学号)、姓名(不超过8位且不包含空格的字符串)、成绩([0, 100]内的整数)组成,相邻属性用1个空格隔开。输出格式:在N行中输出按要求排序后的结果,即:当C=1时,按学号递增排序;当C=2时,按姓名的非_7-2 模拟excel排序
MIUI和Android的关系,小米:MIUI版本和Android版本没有对应关系-程序员宅基地
文章浏览阅读1.9k次。由于不能吃上最新系统,昨天小米论坛还短暂被爆,论坛内也不断出现质疑的帖子。后来在昨晚约9点时,小米论坛管理员终于发帖回应了系统版本之事,称纠结系统版本意义不大。我们发现部分用户在询问MIUI版本号和安卓版本之间的关联。其实,MIUI有着自己的内核、功能演进机制。事实上,很多时候MIUI的功能演进往往领先于安卓原生版本,如权限管理、陌生来电标记、对其唤醒省电机制、全局支持Emoji等,MIUI都远早..._刷机 安卓版本和miui版本关系