Redis(分布式缓存详解)_redis分布式缓存-程序员宅基地
技术标签: Spring框架 分布式技术 缓存 数据库 分布式 redis
一、Redis简介
Redis:基于内存的键值存储系统,通常用作高性能的数据库、缓存和消息队列代理,是互联网广泛应用的存储中间件
特点:基于内存存储,读写性能高
Redis与MySQL区别
- Redis以键值对形式存储,MySQL以表格形式存储
- Redis存储在内存,MySQL存储在磁盘
- Redis存储高效,MySQL存储安全
- 锁的侧重点不同
1.1. 适用场景
作为一款高性能的数据库,Redis适用的场景很多
- 缓存:适合存储访问量大的热点数据(热销商品、热点资讯、热点文章等)。
- 消息队列:构建简单而高效的消息队列系统,适合处理大量实时消息,支持多个消费者并发处理消息。
- 会话存储:对于用户会话记录等重要性较低的数据进行高效存储。
- 延迟队列:使用zset的score来存储时间戳,对时间进行排序,当score小于等于预设值,则发送消息。
1.2. 常用数据类型
Redis有5种基本常用数据类型:
- 字符串 String
- 哈希 hash
- 列表 list
- 集合 set
- 有序集合 sorted set / zset
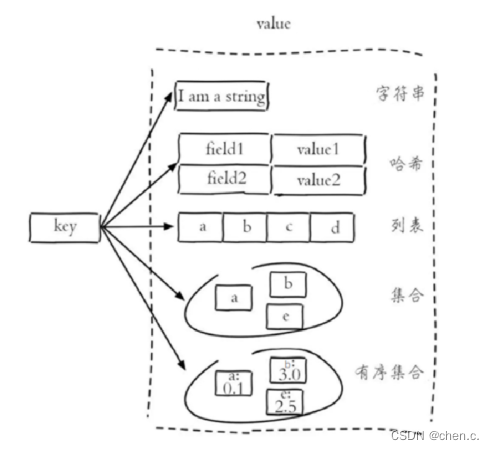
- 字符串(String):字符串类型,最简单的数据类型。
- 哈希(Hash):散列,类似于Java的HashMap结构。
- 列表(list):按照插入顺序排序,可重复,类似Java的LinkedList。
- 集合(set):无序集合,不可重复,类似Java的HashSet。
- 有序集合(sorted set / zset):集合中每个元素关联一个分值(score),根据分值升序排序,不可重复。
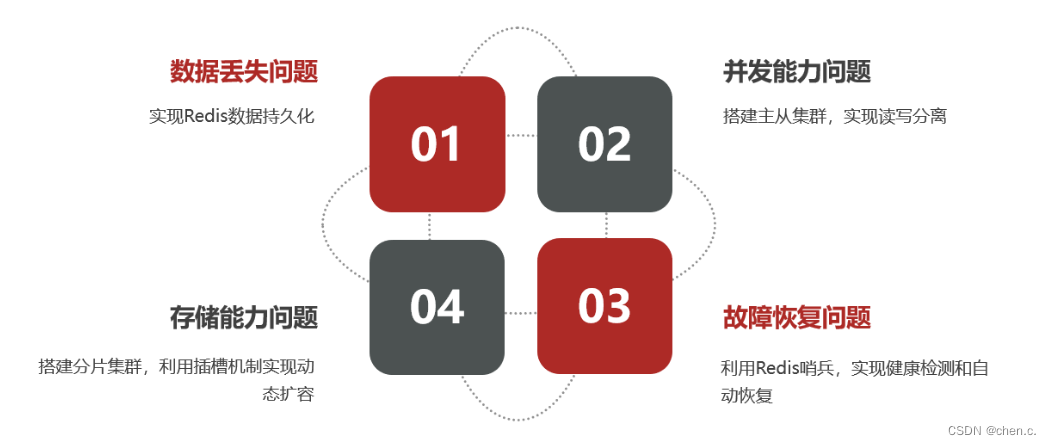
1.3. 单点Redis缺陷
单点(单节点)
单点Redis存在的主要缺陷
- 数据丢失:服务器重启,内存的数据可能丢失。
- 单点故障:如果Redis宕机,整个服务不可用,系统可用性大幅降低。
- 有限并发:Redis为单线程模型,每次仅能处理一个命令,虽然高效,但并发量可能成为系统性能的瓶颈。
- 有限存储:内存存储模式受限于物理服务器内存的限制,数据量剧增,影响系统性能。
二、持久化机制(解决数据丢失)
Redis中的持久化机制有两种
- RDB
- AOF
在Redis4.0支持RDB与AOF混合使用
2.1. RDB
RDB:Redis默认持久化机制,将内存中的数据以二进制格式快照的方式保存到硬盘的RDB文件中。
触发机制
执行指令,或者基于指定(默认)的时间间隔,指定修改次数触发。
- 执行save指令
- 执行bgsave指令
- Redis停机
- 触发RDB条件
1. save指令:输入save,立即执行一次RDB
save指令会导致主进程执行RDB,其他所有指令会被阻塞,适用于数据迁移。

2. bgsave指令:输入bgsave,开启异步RDB
指令执行后会开启异步的RDB,与主进程互不干扰

3. Redis停机:在Redis停机之前,会自动执行一次save指令,实现持久化机制
4. 触发RDB条件:Redis的conf文件中可以修改RDB触发条件
# 900秒内,如果至少有1个key被修改,则执行bgsave , 如果是save "" 则表示禁用RDB
save 900 1
save 300 10
save 60 10000
2.1.1. RDB优缺点
优点
- RDB适用于备份和灾难恢复。
- 将大规模数据集压缩成很小的快照。
- 加载速度比AOF快。
缺点
- RDB是定期生成快照,如果Redis宕机,最后一次快照的数据将会丢失。
- 数据量大时,生成RDB可能会使Redis停止服务一段时间。
- 对于频繁执行写操作,RDB可能导致较高的数据丢失。
2.2. AOF
AOF:以日志的形式记录每个操作,将操作追加到文件末尾,类似事务日志

触发机制
可以配置为每个写操作或每秒触发一次
2.2.1. AOF配置
Redis中,AOF默认是关闭状态,需要手动修改conf配置文件来开启AOF
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
AOF的指令记录评率也可以通过conf文件配置
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no
AOF文件重写
AOF会记录每一次操作,同时会出现一个问题:如果对同一个key多次写操作,存储量变大,造成资源浪费,只有最后一次写操作才会有意义。
通过bgrewriteaof指令,可以让AOF文件执行重写功能,达到存储最后一次写操作。

配置自动重写
在redis.conf中可以配置阈值,使Redis在触发阈值时自动重写AOF文件
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
2.2.2. AOF优缺点
优点
- 以追加的方式记录每个写操作,最大程度上避免数据丢失。
- AOF文件是一个完整的操作日志,可以通过重放日志来修复数据。
- 可以选择不同策略:fsync(每次写入都同步到磁盘)或每秒同步一次
缺点
- AOF文件通常比RDB文件大
- AOF恢复速度可能比RDB慢,特别是AOF文件很大的情况下
三、Redis集群
3.1. 主从(解决并发读)
主从:主从集群,提高Redis的可用性和扩展性
一主多从:主负责读写,从复制主数据。
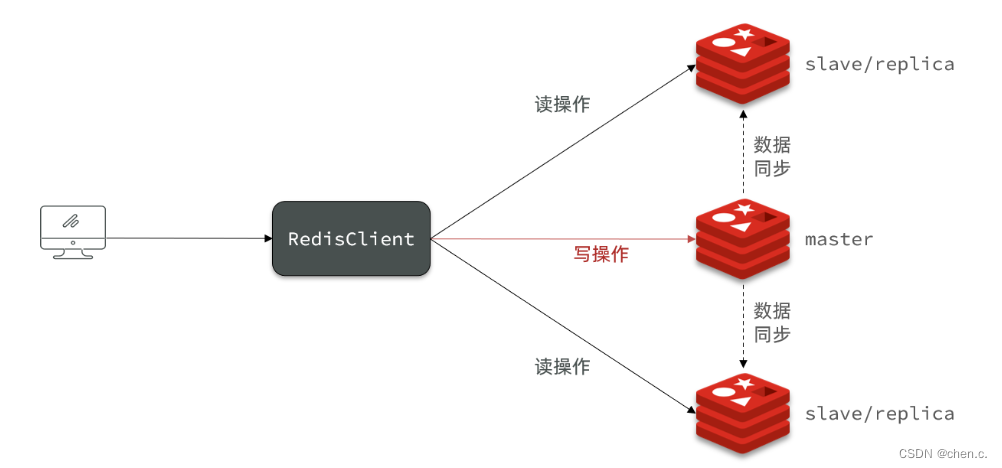
主从集群特点:
- 主节点负责读写,从节点复制主节点的数据。
- 从节点只能进行读操作。
- 主节点宕机,会在从节点中选举出一个新的主节点。
3.1.1. 主从数据同步原理
主从第一次建立连接时,会自动执行全量同步,将主节点(master)的所有数据都拷贝给从节点(slave)
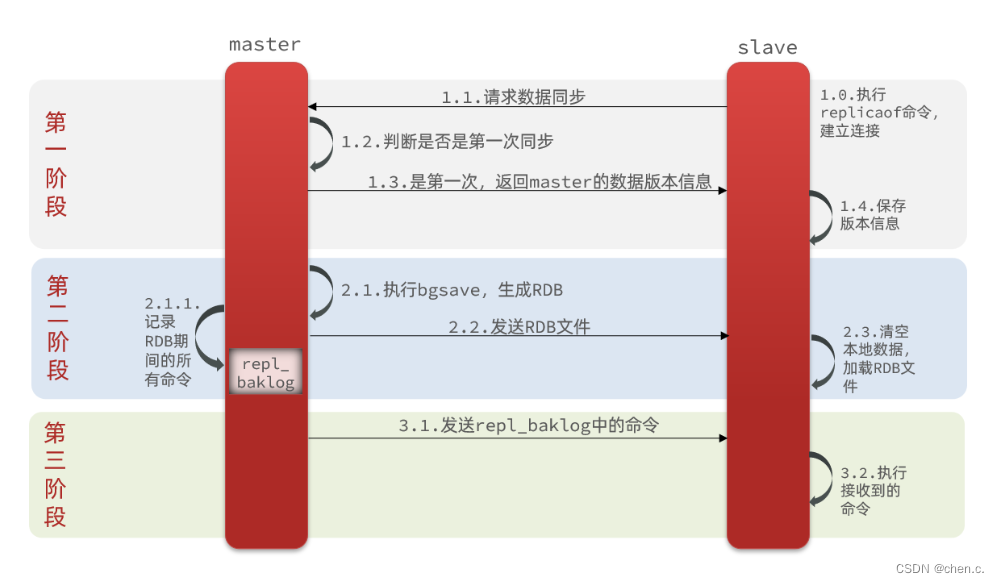
主从集群数据同步具体实现流程
- 新增slave集群,并发送增量同步请求
- master节点判断replid,如不一致,拒绝请求,并把完整数据生成RDB,发送到slave
- slave清空本地数据并加载master传来的RDB
- master将RDB期间执行的指令记录在repl_baklog,并持续将log中的指令发送到slave
- slave执行接收的指令,保持与master的同步
流程理解
最初的slave也是一个全新的集群(master),有自己的replid和offset,当它变成slave,与master建立起连接,发送自己的replid与offset到master。
这时master会对传来的replid和offset进行判断,如果和自己的不同,则说明它是一个全新的集群,就会将自己的replid和offset发送给新集群,并对其进行全量同步,然后新集群会将replid保存到本地,这样slave与master的replid一致了。
因此,master判断一个节点是否是第一次同步,判断的是replid是否一致。
知识点补充
Replication id:简写为replid,数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid。
offset: 偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master,说明slave数据落后于master,需要更新。
全量同步: 主从第一次连接所做的同步就是全量同步。master将完整数据生成RDB,发送到slave,后续指令则记录在repl_baklog,逐个发送给每个slave。
增量同步: 在现有的基础上,更新slave与master存在差异的部分数据,如下图所示

3.1.1. 选举机制
当主从集群的主节点故障(宕机)时,从节点可以自动选举出一个新的主节点。
从节点根据优先级、复制偏移量等因素选择新的主节点,当主节点恢复正常后,它将变为从节点,并同步新主节点的数据。
3.2. 哨兵(解决单点故障)
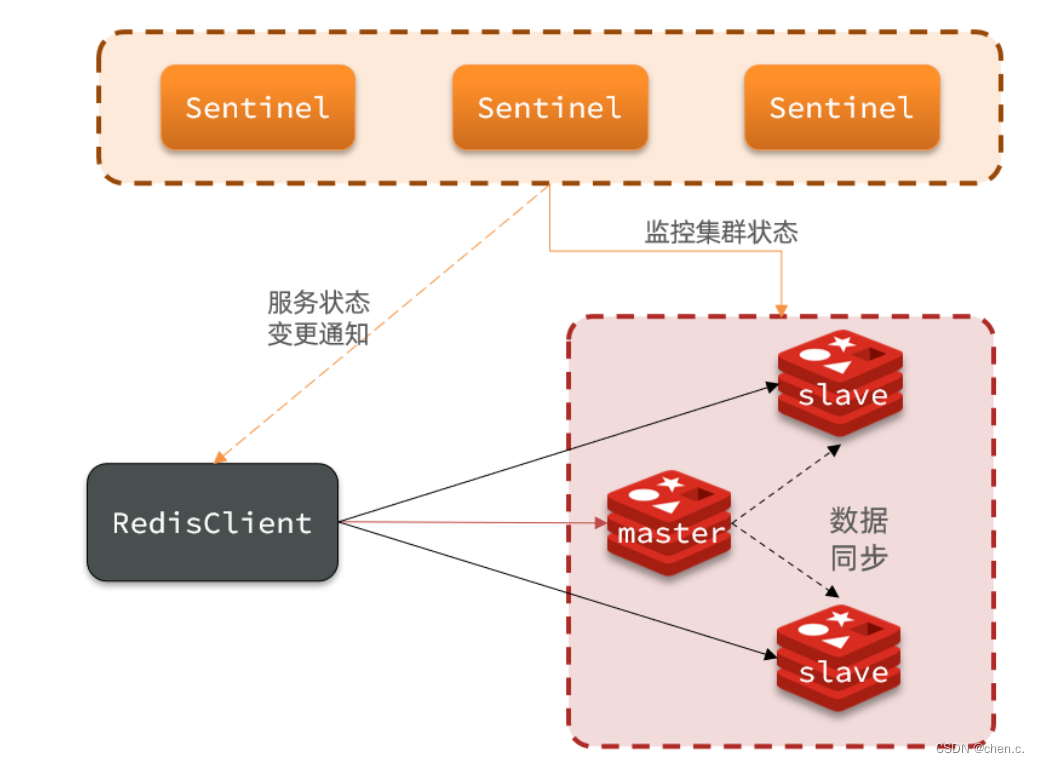
哨兵(Sentinel):哨兵集群,通过监控和自动故障转移来保证Redis的可靠性
组成
- 哨兵集群由多个哨兵节点和多个Redis实例组成。
职责
- 监控:sentinel节点负责监控master与slave的健康状态并进行故障检测和转移。
- 自动故障恢复:如果master故障,Sentinel会将一个slave提升为master,当故障的主节点恢复后,还是以新的master为主。
- 通知:sentinel充当客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给redis的客户端。
3.2.1. 监控原理
哨兵存在意义就是为了监控Redis主从集群的运行情况,在master或slave宕机的时候,进行故障的恢复。
- sentinel定期向master-slave发送心跳信号(ping),如果master-slave在指定时间没有响应信号,则代表当前sentinel认为该master主观下线。
- 当指定数量(一般过半)的sentinel都认为该实例主观下线,则该实例就被确认为客观下线,这时候sentinel就会选择一个从节点作为新的主节点,并将其切换到主节点状态。
- 故障转移过程中,sentinel会通知客户端新的master的地址,以确保客户端可以重连。
3.2.2. 故障恢复原理
一旦发现master故障,Sentinel需要在slave中选择一个相近的作为新的master。
master选举流程
- sentinel会判断slave节点与master节点断开时间的长短,如果超过指定值(down-after-milliseconds * 10),则会排除该slave节点。
- 再判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举。
- 如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高。
- 最后是判断slave节点的运行id大小,越小优先级越高。
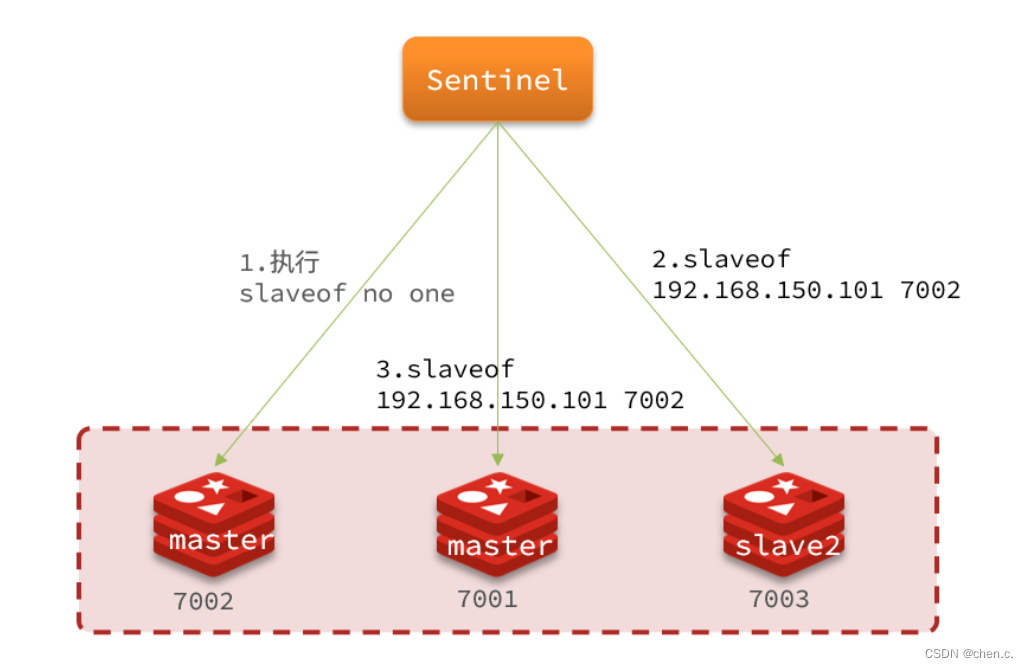
master切换流程
- sentinel给备选的slave节点发送slaveof no one指令,让其成为新的master。
- sentinel给其他的slave发送指令:slaveof 192.168.150.101 7002(master地址),让这些slave成为新master的从节点,并开始从master同步数据。
- sentinel将故障节点标记为slave,当故障节点恢复后会自动成为新master的从节点。
3.3. 分片集群(解决高并发读与高可用)
主从、哨兵解决了redis的高并发写,单点故障,但是还有两个常见的问题并没有解决:
- 高并发读
- 海量数据存储
这时就用到了一个新的集群:分片集群(cluster)
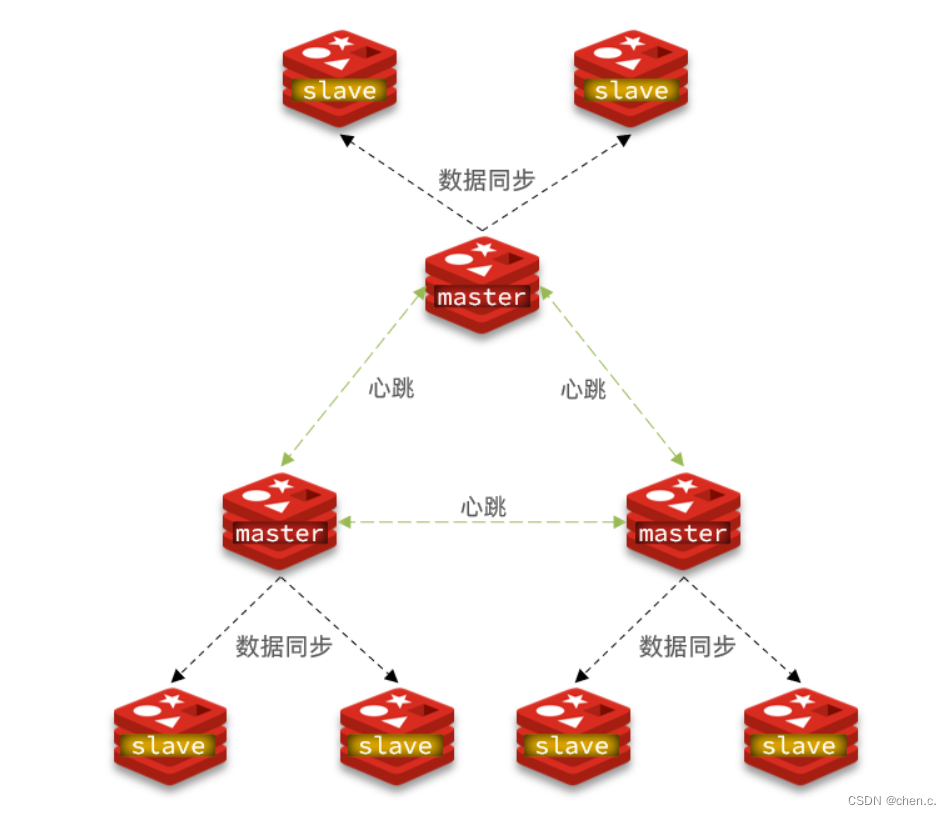
分片特征
- 在一个分片集群中,允许有多个master的存在,每个master存储不同的数据,且每个master下可以有多个slave节点;
- master之间也会通过ping检测彼此健康状态;
- 客户端访问任意的集群,最终都会被转发到正确节点。
3.3.1. 分片策略
cluster的存在意义是为了解决单点reids的存储与并发问题,因此需要把数据分散到各个master,类似数据库的分库。
cluster的分片策略有如下几种种:
- 哈希分片:根据键的哈希值将数据分配到不同节点,相同的键始终映射到同一个节点。
- 范围分片:通过分区键是否在范围内来进行分区,例如:存储区一分区键为1-1000,那么1-1000的数据就存储在区一。
- 一致性hash分区:redis的cluster集群没有采用一致性的哈希方案,它采用的是数据分片中的哈希槽来对数据进行存储与读取的。
3.3.2. 插槽原理
哈希槽:redis集群会预先分好16384(0-16383)个插槽(hash slot),当需要在redis集群放置一个key-value时,会根据CRC16算法得到相应的值,再决定将这个key放置在哪个插槽中。
假设主节点的数量为3,将redis集群的16384个槽位按自定义的规则区分配这三个节点,每个master复制一份槽位。
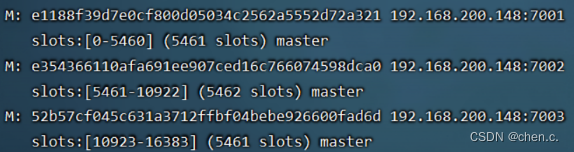
节点1槽位:0 - 5460
节点2槽位:5461 - 10922
节点3槽位:10923 - 16383
数据中的key与插槽绑定,而不是与节点,redis会根据key的有效部分计算插槽值。
注意!!!
slave是没有槽位的,只有master才会有槽位。
3.3.3. 故障转移
cluster也相应的有自己的故障处理机制
当一个master节点宕机或下线,cluster会使用复制机制保证数据的安全,sentinel会复制主节点的数据,当master故障,slave会被提升为新的master,故障的master恢复后,变为新的slave,并同步新的master数据。
正常三节点cluster
7001、7002、7003都是master,现在让7002宕机

疑似宕机

确定下线后自动提升一个slave为新的master

当7002再次启动,自动变为新的slave

3.3.4. 动态扩展
cluster允许动态添加或删除节点
- 添加:对现有数据进行重新分片和迁移,确保数据均分到新节点。
- 删除:将该节点的数据重新分配给其他节点。
四、分布式锁
什么是分布式锁?
分布式环境中,由于多个进程或节点之间的通信延迟、网络分区等因素影响,传统的单机锁机制已经无法满足分布式系统的需求,因此,分布式锁通常基于分布式存储系统或数据库等实现。
分布式锁核心:多个进程或节点同时访问共享的资源时,分布式锁能够确保只有一个进程或节点获取到锁(所有人用同一把锁),锁住线程,让程序串行执行,避免竞争冲突。
分布式锁的分类
- MySQL锁
- Redis锁
- ZooKeeper锁
MySQL锁:在数据库的层面,使用数据库的事务和行级锁来实现并发控制。
Redis锁与ZooKeeper锁:分布式储存系统层面:基本都基于它们的原子性操作和特性实现
注:
三种锁各有优缺,分布式系统存在CAP情况,任何一个分布式系统最多满足两种特效,无法同时满足三种特性。
4.1. Redis分布式锁
Redis分布式锁:利用redis提供的原子操作和特性来实现的一种分布式锁机制,用于解决多个线程或者线程间的互斥访问问题。
Redis锁核心依旧是让多个线程使用同一把锁,防止资源共抢的情况。
Redis锁核心思路
-
获取锁
-
互斥特性:确保只能有一个线程获取锁
-
非阻塞特性:尝试一次,成功返回true,失败返回false
-
-
释放锁
- 手动释放:手动释放锁
- 超时释放:添加锁的过期时间,到期自动释放
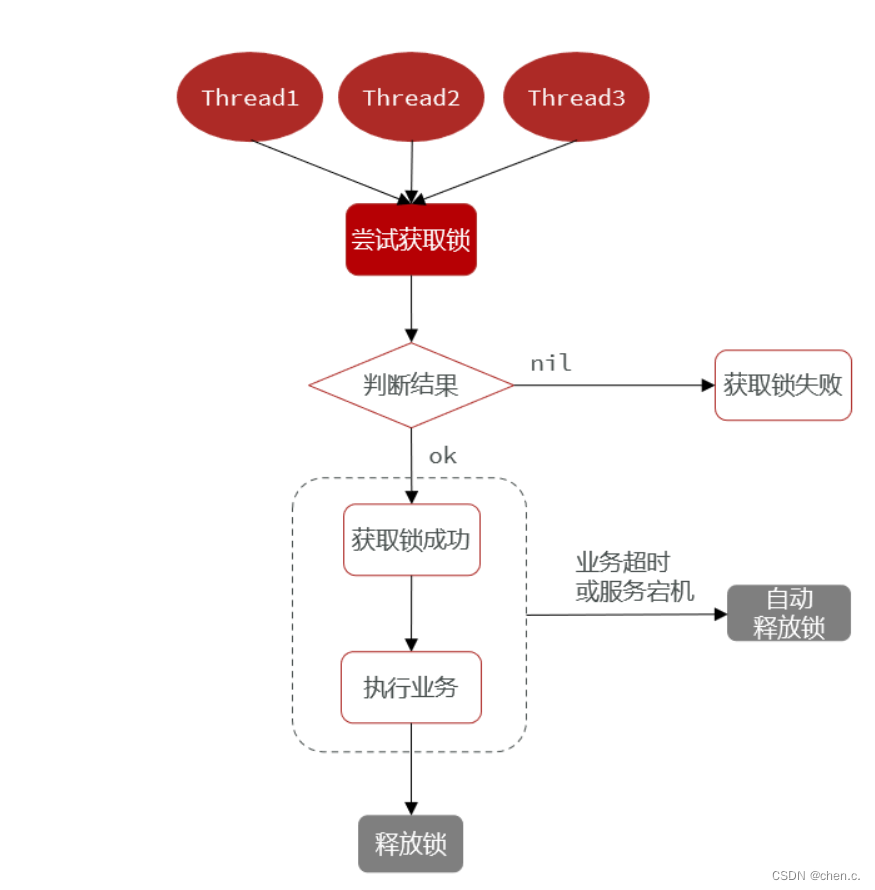
4.1.1. SETNX命令锁
SETNX命令锁:利用SETNX命令的原子性,通过判断返回值来确定是否成功获取到锁。
- 使用SETNX命令来设置一个键值对,如果键不存在,则设置成功,并返回1;如果已经存在,则设置失败,并返回0.
简单来说就是:插入key成功,表示获得锁,返回1;如果有人插入成功了,其他人则不能再次插入,必须等前面的人释放锁后才可继续插入,这时失败会返回0。
获取锁
- 互斥:确保只能有一个线程获取锁
# 添加锁,利用setnx的互斥特性
SETNX lock thread1
- 非阻塞:尝试一次,成功返回true,失败返回false
# 添加锁,NX是互斥,EX是设置超时时间
SET lock thread1 NX EX 10
释放锁
- 手动释放
# 释放锁,删除即可
DEL Key
- 超时释放:获取锁时添加一个超时时间
# 添加锁过期时间,避免服务宕机引起的死锁
EXPIRE lock 10
在Java中创建setnx锁
import org.springframework.data.redis.core.StringRedisTemplate;
import java.util.concurrent.TimeUnit;
/**
* 创建setnx锁
*/
public class RedisSetNxLock {
//定义锁的名称
private final String name;
private final StringRedisTemplate stringRedisTemplate;
public RedisSetNxLock(String name, StringRedisTemplate stringRedisTemplate) {
this.name = name;
this.stringRedisTemplate = stringRedisTemplate;
}
//定义当前key的前缀,大小写快捷键ctrl+shift+u
private static final String KEY_PREFIX="lock:";
/**
* 获取锁
*
* @param timeoutsec key的过期时间
* @return true表示拿到锁,false表示没有拿到锁
*/
public boolean tryLock(Long timeoutsec) {
//2.获取当前线程的id作为value值,保证唯一性
long threadId = Thread.currentThread().getId();
/**
* 1.获取锁
* setIfAbsent(K key, V value, long timeout, TimeUnit unit)
*
key –参数1表示redis中的key
value – 参数2表示redis中存储的值
timeout – 参数3表示key的过期时间
unit – 参数4表示时间单位
*/
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(KEY_PREFIX + name, threadId + "", timeoutsec, TimeUnit.MINUTES);
/**
* 这个是为了防止类型的拆箱,如果返回值为null的话,boolean类型会报错
* 意思:如果相等于则返回true,不想等于返回false,如果flag=null的话,也是返回false;
*/
return Boolean.TRUE.equals(flag);
}
/**
* 释放锁
*
*/
public void unLock() {
//通过手动释放锁
stringRedisTemplate.delete(KEY_PREFIX+name);
}
}
redis锁的原子性问题
现在线程1持有锁,执行业务逻辑过程中,准备删锁,而且已经走到了条件判断的过程中,但此时他的锁到期了,也会接着执行,但此时线程2已经进来了,而恰巧线程1的卡顿结束后,执行删除锁,这样的话相当于条件判断并没有起到作用,这就是redis锁的原子性问题。
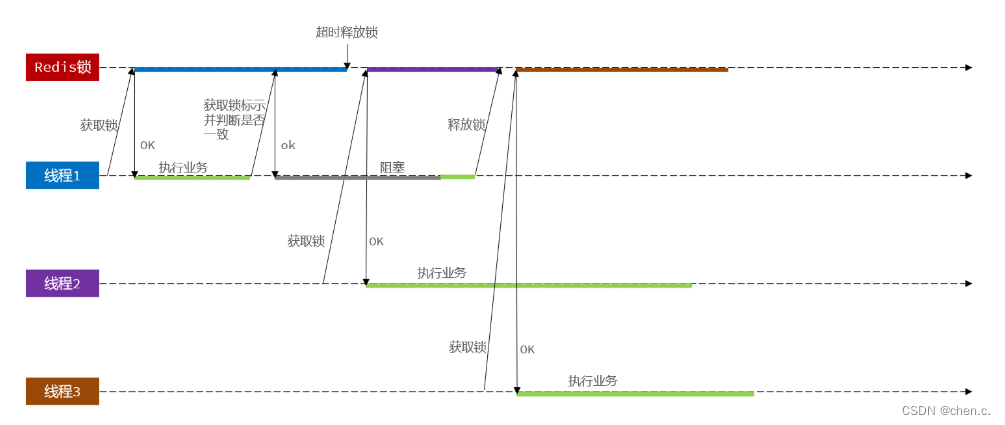
这种情况可以通过Lua脚本锁来解决。
4.1.2. Lua脚本锁
Lua脚本锁:用lua去编写多条redis语句,确保多条命令执行时的原子性。
- 使用Redis的EVAL命令执行Lua脚本,利用GETSET命令的原子性,对比当前值和期望值来获取锁,并设置新的值。
Lua脚本:一种轻量级的嵌入式脚本语言,常用于扩展应用程序的逻辑和功能。
4.1.3. RedLock算法锁
RedLock算法锁:Redlock在redis实例集群上实现的一种分布式锁算法,使用多把锁来防止单节点redis分布式锁宕机的问题。
Redlock算法的思路
- 使用N个独立且互不相干的集群节点(通常为主从架构)。
- 获取锁时,客户端会向这N个节点发起请求,在多数节点上获取锁,当获取到多数节点的锁后,即被认为成功获取锁。
- 释放锁时,客户端会向所有节点发送解锁请求,只有在大多数节点上成功解锁,锁才会被释放。
所以,Redlock算法与传统SETNX的区别是:在多数节点成功获取或解锁后才被认为有效,即使小部分的节点宕机,也不会影响到其他分布式锁的可用性。
4.2. Redission框架
SETNX锁的缺陷
- 不支持重入:SETNX锁是基于键的操作,不支持同一个客户端对同一个锁的重入,容易出现死锁和资源浪费的情况。
重入问题是指获得锁的线程可以再次进入到相同的锁代码中,可重入锁的意义在于防止死锁。
比如HashTable这样的代码,它的方法都是使用synchronized修饰的:假设它在一个方法内,调用另一个方法,如果此时它不可重入,就死锁了,所以可重入锁的主要意义是防止死锁,synchronized和lock锁都是可重入的。
-
没有超时释放机制:SETNX锁是没有内置的超时机制的,即如果一个用户得到锁,在操作过程中宕机了,其他客户端就无法获取锁了,又导致了死锁,所以每次使用SETNX锁时,都需要自己手动设置锁过期时间。
-
锁释放异常:如果用户已经获取锁,在释放锁前异常宕机,其他客户端无法判断锁是否释放,导致其他线程阻塞。
例如:redis提供了master-slave,向集群写数据时,master要异步的将数据同步给slave,而同步之前万一master宕机,就会出现死锁。
为了解决这些问题,可以使用Redission框架
Redission:分布式对象存储和服务的框架,基于Redis实现。
Redission提供了多种分布式锁的实现方式
- 基于Redis的分布式锁
- 基于RedLock算法的分布式锁
4.2.1. 基于Redis的分布式锁
前置配置
- 导入Redission相关依赖
- 配置Redis地址和端口
创建Redis分布式锁
- 创建RedissionClient对象,连接到redis节点(ip);
- 使用getLock方法获取锁对象(这里用的对象名叫"myLock");
- try-catch-finally中,使用tryLock方法获取锁,如果成功则执行业务;
- 执行完业务,通过unlock方法释放锁,并关闭redission。
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonLockExample {
public static void main(String[] args) {
// 创建Redisson配置对象
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
// 创建Redisson客户端
RedissonClient redisson = Redisson.create(config);
// 获取锁对象
RLock lock = redisson.getLock("myLock");
try {
// 尝试获取锁,并设置锁的超时时间为10秒
boolean locked = lock.tryLock(10, TimeUnit.SECONDS);
if (locked) {
// 成功获取到锁,执行业务逻辑
System.out.println("获取到锁,开始执行业务逻辑");
Thread.sleep(5000); // 模拟业务逻辑处理时间
} else {
// 获取锁失败,执行相应的处理逻辑
System.out.println("获取锁失败,执行相应的处理逻辑");
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 释放锁
lock.unlock();
System.out.println("释放锁");
}
// 关闭Redisson客户端
redisson.shutdown();
}
}
4.2.2. 基于RedLock算法的分布式锁
创建RedLock分布式锁
- 创建多个Redission对象,分别连接redis节点;
- 使用getLock方法获取多个不同锁对象;
- 在try-catch-finally中,调用RedissionRedLock.tryLock方法获取锁,如果成功,则执行业务;
- 业务执行完后,通过RedissionRedLock.unlock方法释放锁。
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import java.util.concurrent.TimeUnit;
public class RedissonLockExample {
public static void main(String[] args) {
// 创建Redisson配置对象
Config config1 = new Config();
config1.useSingleServer().setAddress("redis://127.0.0.1:6379");
Config config2 = new Config();
config2.useSingleServer().setAddress("redis://127.0.0.1:6380");
Config config3 = new Config();
config3.useSingleServer().setAddress("redis://127.0.0.1:6381");
// 创建Redisson客户端
RedissonClient redisson1 = Redisson.create(config1);
RedissonClient redisson2 = Redisson.create(config2);
RedissonClient redisson3 = Redisson.create(config3);
// 获取锁对象
RLock lock1 = redisson1.getLock("myLock");
RLock lock2 = redisson2.getLock("myLock");
RLock lock3 = redisson3.getLock("myLock");
// 尝试获取锁
try {
boolean locked = RedissonRedLock.tryLock(lock1, lock2, lock3, 10, TimeUnit.SECONDS);
if (locked) {
// 成功获取到锁,执行业务逻辑
System.out.println("获取到锁,开始执行业务逻辑");
Thread.sleep(5000); // 模拟业务逻辑处理时间
} else {
// 获取锁失败,执行相应的处理逻辑
System.out.println("获取锁失败,执行相应的处理逻辑");
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 释放锁
RedissonRedLock.unlock(lock1, lock2, lock3);
System.out.println("释放锁");
}
// 关闭Redisson客户端
redisson1.shutdown();
redisson2.shutdown();
redisson3.shutdown();
}
}
4.3. Watchdog机制
Watchdog(看门狗):Redis分布式锁中的一种机制机制,用于在分布式环境下对锁自动续期,以防止锁过期而被自动释放。
每个redis锁都有一个有效期,在锁的有效期内,有的线程会因为执行时间较长或遇到阻塞问题,可能会导致锁的持有时间超过了预期,从而造成其他线程在有效期内无法获取到锁,所以Redission优化了这一点,推出看门狗机制,定期延续锁期限,确保锁的延续。
机制
Redission的看门狗使用了Redis的PTTL命令来获取锁的剩余有效期,并在适当的时候发送PEXPIRE命令进行续期,默认续期时间是锁有效期的2/3,且续期操作在每次续期间隔的一半时间内执行,以此确保连续续期。
适用场景
-
分布式调度:通过watchdog延续锁,确保任务调度中,同一时刻只有一个节点执行任务,保持锁的有效性,防止任务执行时间过长导致锁被自动释放。
-
缓存预热:通过watchdog延续锁,确保在缓存预热过程中,锁的有效性,实现只有一个节点进行缓存数据的加载和初始化。
-
分布式限流:通过watchdog延续锁,确保在控制某个资源或服务并发访问量的时候,锁的有效性,防止因锁过期而导致并发访问超出限制。
-
分布式事务管理:通过watchdog延续锁,确保多个事务完成前多把锁保持有效,防止锁过期导致数据不一致。
五、Redis策略
Redis常用策略:
- 数据持久化策略:RDB(全量型)快照形式,定期机制;AOF(增量型)日志形式,追加机制。
- 复制策略:主从复制,将master数据以RDB方式复制到slave。
- 分片策略:分片集群,海量数据分散到各个集群。
- 数据过期策略:定期处理过期数据,释放缓存。
- 数据淘汰策略:
5.1. 数据过期策略(Key过期)
在使用redis的时候,通常会设置数据的过期时间,过了有效期,依旧留在redis内部,这样不断地累积,redis缓存过多,会导致性能降低,为了避免这种现象发生,redis提供了清除过期数据的策略。
redis的数据过期策略:
- 定时删除(Expired by Time):设置键的过期时间,到达指定时间后自动删除该键,是redis最常用的过期策略。
- 惰性删除(Expired by Access):
- 定期删除(Expired by Sampling):定期对Key检查,删除里面过期的Key(从一定量的数据库中取一部分随机数据进行检查,删除其中的过期键)。
5.1.1. 定时删除策略
定时删除策略
通过设置键过期时间来控制数据生命周期,当键的过期时间到达,redis自动删除该键。
以Lettuce客户端为例
- 实例化RedisClient对象,使用connect方法连接redis;
- 获取同步执行的RedisCommands对象,使用expire命令(方法)设置键的过期时间;
- 通过shutdown关闭RedisClient连接。
import io.lettuce.core.RedisClient;
import io.lettuce.core.api.StatefulRedisConnection;
import io.lettuce.core.api.sync.RedisCommands;
public class RedisExample {
public static void main(String[] args) {
// 创建RedisClient实例
RedisClient client = RedisClient.create("redis://localhost:6379");
// 创建Redis连接
try (StatefulRedisConnection<String, String> connection = client.connect()) {
// 获取同步的RedisCommands对象
RedisCommands<String, String> commands = connection.sync();
// 设置键的过期时间(以秒为单位)
String key = "myKey";
int seconds = 60; // 设置为60秒后过期
commands.expire(key, seconds);
} finally {
// 关闭RedisClient连接
client.shutdown();
}
}
}
5.1.2. 惰性刪除策略
惰性刪除策略
在访问键的时候检查其过期时间,并在需要时进行删除的策略。
以Lettuce客户端为例
- 创建Redisclient实例,通过
connect方法建立redis连接 - 获取响应式
RedisReactiveCommands对象 - 使用惰性删除策略时,先使用set命令设置键的值,后使用
expire命令设置键的过期时间(这里使用了Mono.when和block方法来合并和等待执行结果)。 - 执行其他业务时,使用
ttl命令来获取键的剩余过期时间,通过map操作将过期时间小于0的结果映射为true,默认值设为true,并返回Mono<Boolean>类型,然后通过订阅该Mono对象,在延迟一段时间后输出过期状态。 - 最后使用del命令删除键,并通过
Mono.when和block方法合并和等待删除命令的执行结果。
import io.lettuce.core.RedisClient;
import io.lettuce.core.api.StatefulRedisConnection;
import io.lettuce.core.api.reactive.RedisReactiveCommands;
import reactor.core.publisher.Mono;
import java.time.Duration;
import java.util.concurrent.TimeUnit;
public class RedisExample {
public static void main(String[] args) throws InterruptedException {
// 创建RedisClient实例
RedisClient client = RedisClient.create("redis://localhost:6379");
// 创建Redis连接
try (StatefulRedisConnection<String, String> connection = client.connect()) {
// 获取响应式RedisReactiveCommands对象
RedisReactiveCommands<String, String> reactiveCommands = connection.reactive();
// 定义键和过期时间
String key = "myKey";
int expirationSeconds = 60; // 过期时间60秒
// 设置键
Mono<String> setCommand = reactiveCommands.set(key, "myValue");
// 设置过期时间并订阅结果
Mono<String> expireCommand = reactiveCommands.expire(key, expirationSeconds);
// 合并执行结果
Mono.when(setCommand, expireCommand).block();
// ... 执行其他操作 ...
// 检查键是否过期
Mono<Boolean> isExpired = reactiveCommands.ttl(key)
.map(expiration -> expiration < 0)
.defaultIfEmpty(true);
// 延迟一段时间后输出过期状态
Thread.sleep(Duration.ofSeconds(5).toMillis());
isExpired.subscribe(expired -> {
if (expired) {
System.out.println("Key has expired.");
} else {
System.out.println("Key has not expired yet.");
}
});
// 删除键
Mono<Long> delCommand = reactiveCommands.del(key);
// 合并执行结果
Mono.when(delCommand).block();
} finally {
// 关闭RedisClient连接
client.shutdown();
}
}
}
5.1.3. 定期删除策略
定期删除策略
每隔一段时间,随机检查一批Key是否过期,如果Key已过期,则redis会删除该键,保证过期键在读取时被删除,不会对未访问的键进行删除。
以Lettuce客户端为例
- 实例化RedisClient对象,使用connect方法连接redis;
- 获取异步执行的RedisAsyncCommands对象;
- 使用ScanIterator循环遍历所有匹配的键,循环中,使用sync方法获取同步命令对象,方便检查键的剩余过期时间,如果键已过期,则使用异步命令对象删除键;
- 使用shutdown关闭redisclient连接。
注意!
在使用Lettuce库中,异步操作通常会立即返回,需要通过await()方法来等待异步操作完成,或使用响应式编程模型来处理异步结果。在示例中,通过flushCommands().await(Duration.ofSeconds(1))来等待异步删除操作完成。
import io.lettuce.core.RedisClient;
import io.lettuce.core.api.StatefulRedisConnection;
import io.lettuce.core.api.async.RedisAsyncCommands;
import io.lettuce.core.api.reactive.RedisReactiveCommands;
import io.lettuce.core.api.sync.RedisCommands;
import io.lettuce.core.scan.ScanCursor;
import io.lettuce.core.scan.ScanIterator;
import java.time.Duration;
public class RedisExample {
public static void main(String[] args) {
// 创建RedisClient实例
RedisClient client = RedisClient.create("redis://localhost:6379");
// 创建连接
try (StatefulRedisConnection<String, String> connection = client.connect()) {
// 使用异步命令处理
RedisAsyncCommands<String, String> asyncCommands = connection.async();
// 定期删除过期键
ScanCursor scanCursor = ScanCursor.INITIAL;
ScanIterator<String> scanIterator = ScanIterator
.scan(asyncCommands, ScanArgs.Builder.matches("*").count(100).build());
while (scanIterator.hasNext()) {
scanCursor = scanIterator.next();
for (String key : scanIterator.getKeys()) {
// 检查是否过期
RedisCommands<String, String> syncCommands = connection.sync();
if (syncCommands.ttl(key) < 0) {
// 删除过期键
asyncCommands.del(key);
}
}
}
// 同步删除操作
asyncCommands.flushCommands().await(Duration.ofSeconds(1));
} finally {
// 关闭连接
client.shutdown();
}
}
}
5.1.4. 延迟过期策略
延迟过期策略
当一个键到达有效期时,redis不会立即执行删除,而是将其标记为"待删除",等后台的异步任务定期清理这些待删除键。
在Redis中,没有内置的延迟过期策略,通过Scored Sorted Set(有序集合)来实现一种类似的延迟过期策略
以Lettuce客户端为例
使用一个有序集合delayedKeys来存储需要延迟过期的键。调用zadd方法将键添加到有序集合中,设置相关的过期时间。通过zadd命令,键的过期时间存储为成员的分数,使用当前时间戳加上延迟秒数计算得到,以毫秒为单位。
在执行其他操作时,可以使用zrank方法来检查键是否过期。如果返回值不等于-1,则表示键还未过期。如果返回值等于-1,则表示键已过期。
最后,在适当的时候可以使用del命令从Redis中删除键,并调用zrem命令从有序集合中移除该键。
import io.lettuce.core.RedisClient;
import io.lettuce.core.api.StatefulRedisConnection;
import io.lettuce.core.api.sync.RedisCommands;
import java.time.Duration;
public class RedisExample {
public static void main(String[] args) {
// 创建RedisClient实例
RedisClient client = RedisClient.create("redis://localhost:6379");
// 创建Redis连接
try (StatefulRedisConnection<String, String> connection = client.connect()) {
// 获取同步的RedisCommands对象
RedisCommands<String, String> commands = connection.sync();
// 定义键和过期时间
String key = "myKey";
int delayInSeconds = 60; // 延迟60秒过期
// 设置键并延迟过期
commands.zadd("delayedKeys", System.currentTimeMillis() + (delayInSeconds * 1000), key);
// ... 执行其他操作 ...
// 检查键是否过期
if (!commands.zrank("delayedKeys", key).equals(-1L)) {
// 键还未过期,执行相应操作
System.out.println("Key has not expired yet.");
} else {
// 键已过期,执行相应操作
System.out.println("Key has expired.");
}
// 删除过期键
commands.del(key);
// 在有序集合中移除该键
commands.zrem("delayedKeys", key);
} finally {
// 关闭RedisClient连接
client.shutdown();
}
}
}
5.2. 数据淘汰策略(内存不足)
当Redis的内存空间不足时,向Redis中添加新的Key,那么Redis就会按照某种规则将内存中的数据删除,以便新的数据存入进来,这种数据的删除规则就称为内存的淘汰策略。
常见的数据淘汰策略
淘汰具有过期时间的数据
- volatile-lru(least recently used):从已设置过期时间的数据集中挑选最近最少使用的数据淘汰。
- volatile-lfu(least frequently used):从已设置过期时间的数据集中挑选最不经常使用的数据淘汰。
- volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰。
- volatile-random:从已设置过期时间的数据集中任意选择数据淘汰。
淘汰全库数据
- allkeys-lru:当内存不足以容纳新写入内存时,在键空间中,移除最近最少使用的key(最常用)
- allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key。
- allkeys-random:从数据集中任意选择数据淘汰。
不淘汰
- no-eviction:禁止驱逐数据,当内存不足以容纳新写入数据时,写入操作会报错(没见人用过)。
- LUR:最少最近使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
- LFU:最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。
- volatile:设置了带过期时间的key。
- allkeys:表示所有的key。
常见配置
maxmemory-policy noeviction # 配置淘汰策略
maxmemory ?mb # 最大可使用内存,即占用物理内存的比例,默认为0,表示不限制。生产环境通常设置在50%以上。
maxmemory-samples count # 设置redis需要检查key的个数
六、Redis缓存问题
6.1. 缓存穿透
缓存穿透:指客户端请求的数据在缓存中和数据库中都不存在,请求穿过缓存,冲击数据库。
当客户端访问数据时,先请求redis,但redis此时并没有数据,那么请求就会继续访问到数据库,但此时数据库中也没有该数据,这个数据就穿透了缓存,直接访问数据库,而数据库承载的并发又远不如redis高,如果大量的请求同时访问这种不存在的数据,那么数据库受到的压力会非常大。
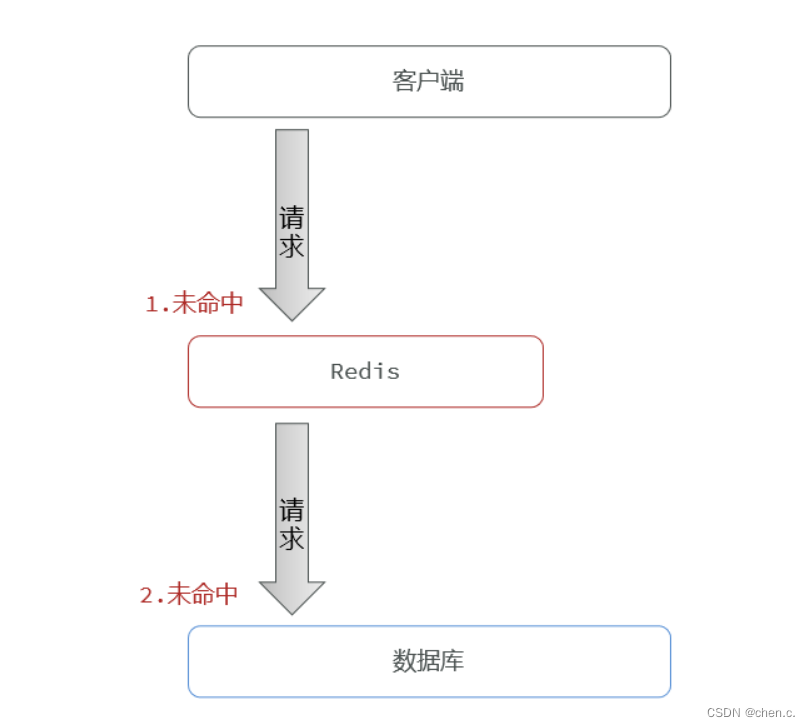
缓存穿透解决方案
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 缓存空对象 | 实现简单,维护方便 | 额外的内存消耗,可能造成短期的不一致 |
| 布隆过滤器 | 内存占用较少,没有多余的key | 实现复杂,存在误判可能 |
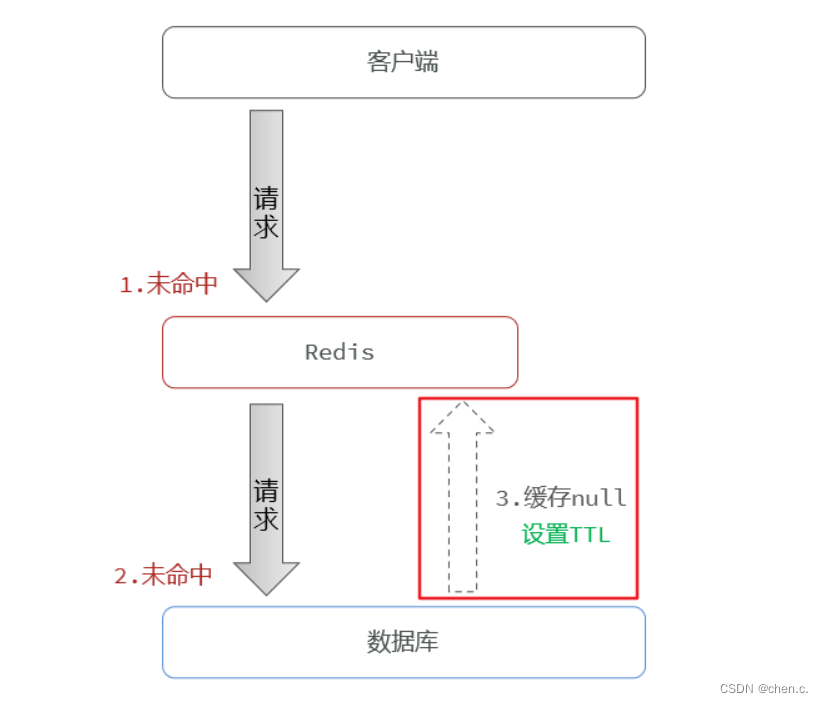
6.1.1. 缓存空对象
当访问一个不存在的数据时,把数据存入到redis中,设置为null,这样下次访问到这个不存在的数据时,就会在redis中找到这个数据,防止请求进入数据库。
6.1.1. 布隆过滤器
通过一个庞大的二进制数据,使用哈希思想去判断当前这个要查询的数据是否存在。
- 存在,则放行,这个请求访问redis,即便redis中的这个数据过期,数据库中也一定存在这个数据,在数据库中查询出来这个数据后,再将其放入redis中。
- 不存在,直接返回。
注意:布隆过滤器也会存在误判,因为它用的是哈希思想,可能会有哈希冲突的情况发生。
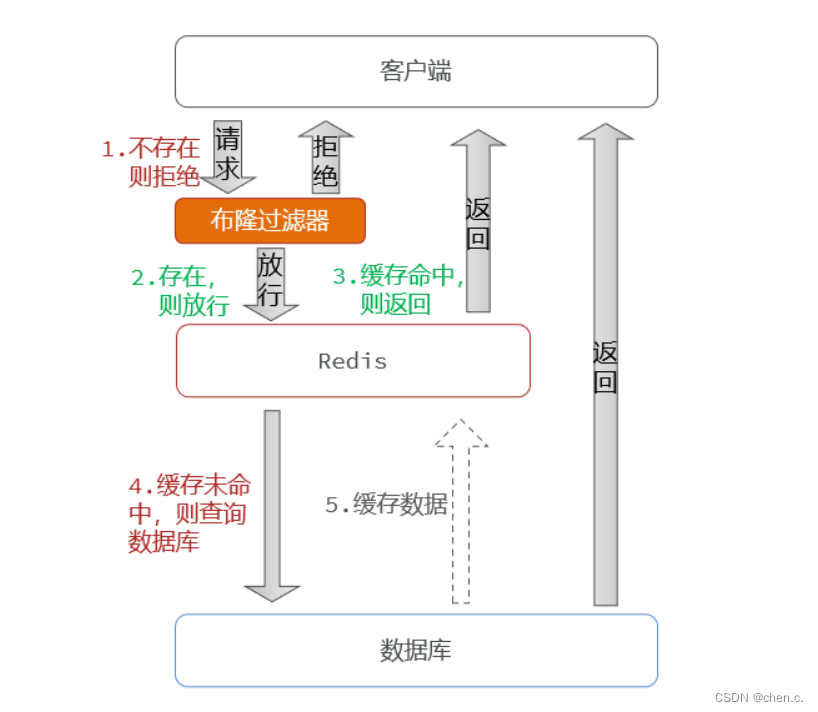
关于布隆过滤器
布隆过滤器(Bloom Filter)是 Redis 4.0 版本提供的新功能,它被作为插件加载到 Redis 服务器中,给 Redis 提供强大的去重功能
布隆过滤器(Bloom Filter)是一个高空间利用率的概率性数据结构,由二进制向量(即位数组)和一系列随机映射函数(即哈希函数)两部分组成。
布隆过滤器使用exists()来判断某个元素是否存在于自身结构中。当布隆过滤器判定某个值存在时,其实这个值只是有可能存在;当它说某个值不存在时,那这个值肯定不存在,这个误判概率大约在 1% 左右。
6.2. 缓存雪崩
缓存雪崩:指同一段时间内大量的缓存key同时失效(过期或者redis服务宕机),导致大量的请求直击数据库,给数据库造成巨大压力。
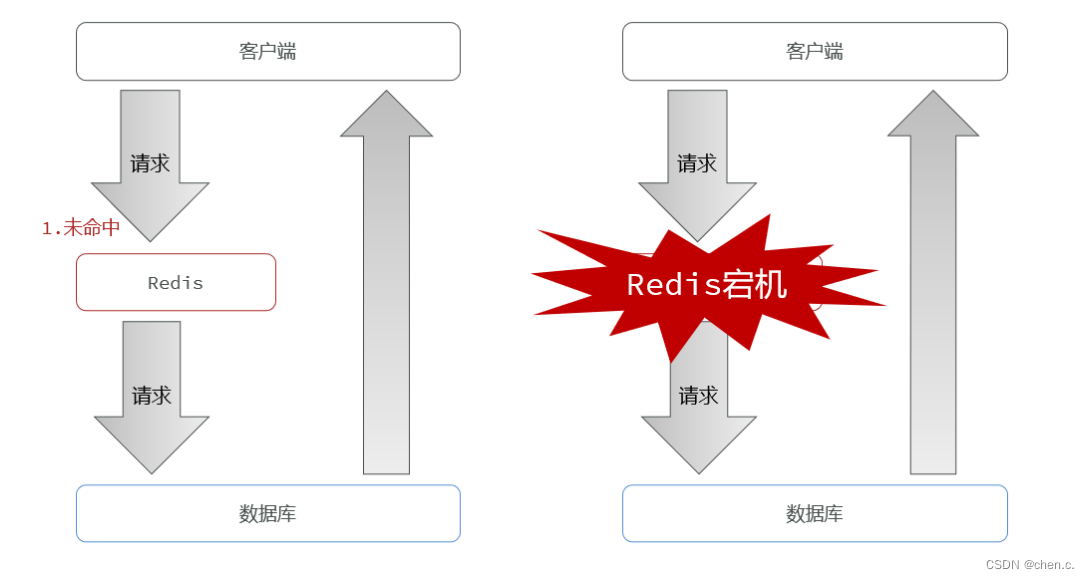
解决方案
- 给不同key的TTL添加随机值
- 保证不是所有的key都是同时过期。
- 利用Redis集群力高服务的可用性
- 保证至少一台redis服务是可用的。
- 给缓存业务添加降级限流策略
- 保证不了redis服务可用,就添加降级限流(redis漏桶算法)。
- 添加逻辑:不可用后提示报错,不再访问数据库。
- 给业务添加多级缓存
- 结合使用SpringCache
- JVM进程缓存
- Nginx + OpenResty多级缓存
6.3. 缓存击穿
缓存击穿:一个被高并发访问且缓存重建业务较为复杂的key突然失效,那么高并发请求就会瞬间直达数据库,这就叫缓存击穿。
如下图所示
假设:线程1在查询缓存没有命中,会去查数据库,然后将数据缓存到redis中,如果线程1走完了这个逻辑,那么其他线程再去执行的时候就会从缓存中加载这些数据了。
但假设,在线程1没有走完这些逻辑的时候,后续的线程2,3,4同时过来访问这个业务,那么此时线程2,3,4就不能从缓存中获取数据了,没有查询到缓存数据,那么同一时间去访问数据库,又对数据库造成了冲击。
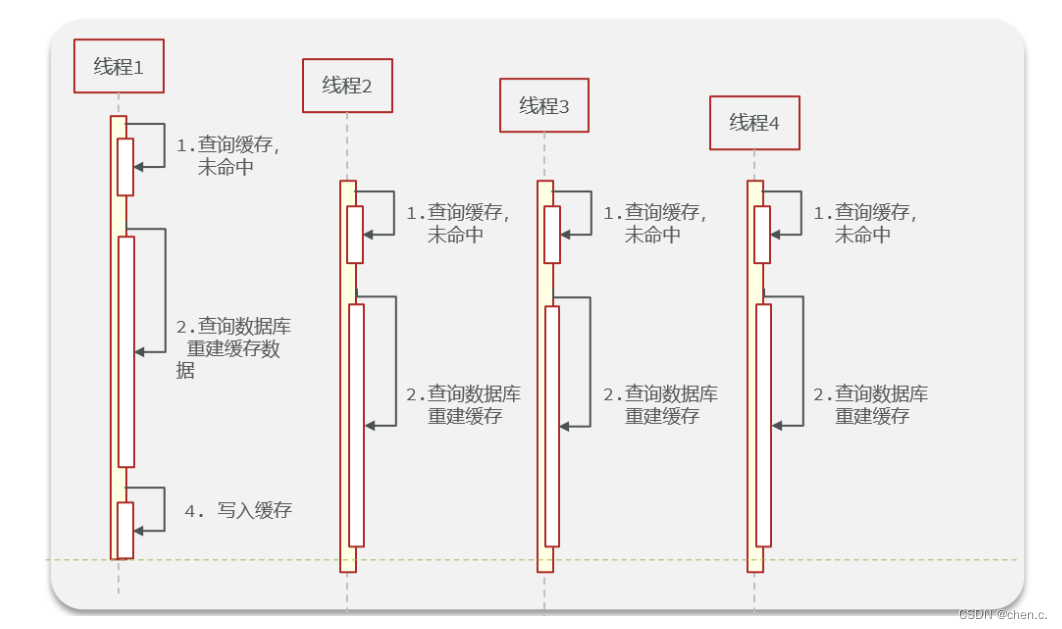
解决方案
- 互斥锁
- 逻辑过期
6.3.1. 互斥锁方案
假如线程1过来访问
- 查询缓存并没有命中
- 但是获取互斥锁成功
- 那么就可以去查询数据库,并写入缓存
- 最后释放锁
但是此时线程2如果在线程1没有执行完业务之前来访问的话
- 去查询缓存没有命中
- 但是由于这个锁此时线程1在使用并没有释放,那么此时就获取锁失败了
- 此时线程2就会进入休眠等待状态
- 直到线程1走完了业务,并释放锁之后,线程2获取锁,才可以继续执行后面业务。
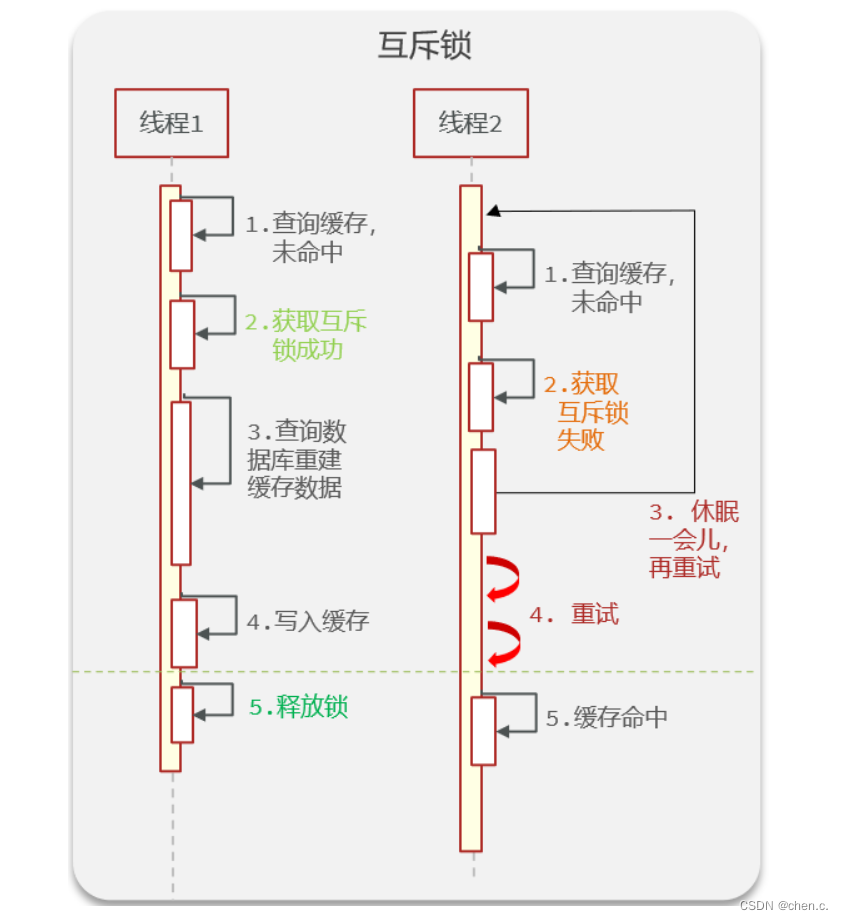
那么此时,就形成了只能有一个线程来访问业务,也就是一个一个的访问数据库,从而避免了访问数据库的压力,但是这也会影响查询的性能,因为此时会让查询的性能从并行变成了串行,此时性能较差。
6.3.2. 逻辑过期方案
缓存击穿原因分析:
我们之所以会出现这个缓存击穿问题,主要原因是在于我们对key设置了过期时间,假设我们不设置过期时间,其实就不会有缓存击穿的问题,但是不设置过期时间,这样数据不就一直占用我们内存了吗,我们可以采用逻辑过期方案。
缓存击穿分案分析:
1、我们把过期时间设置在 redis的value中,注意:这个过期时间并不会直接作用于redis,而是我们后续通过逻辑去处理。
假如:线程1来访问
- 第一步,查询缓存,此时数据时肯定存在的,只不过是逻辑时间过期的。
- 第二步,线程1也是要获取互斥锁的,但是其他线程就会进行阻塞。
- 第三步,为了降低阻塞,提高性能线程1会再开启一个新的线程2,然后进行查询数据库,然后写入数据到缓存中,最后释放锁
- 第四步,直接返回过期数据
假如:此时线程3来访问(线程3访问的时机是线程2刚开启,还没有释放锁)
- 第一步,此时从缓存中查询的数据还是逻辑过期数据
- 第二步,线程3也要获取互斥锁,但是线程2此时还没有释放,所以线程3获取锁失败
- 第三步,则直接返回过期数据
假如:此时线程4来访问,线程4访问的时机是线程2已经释放锁资源了,那么线程4就可以直接从缓存中获取最新数据(该数据,逻辑时间并未过期)
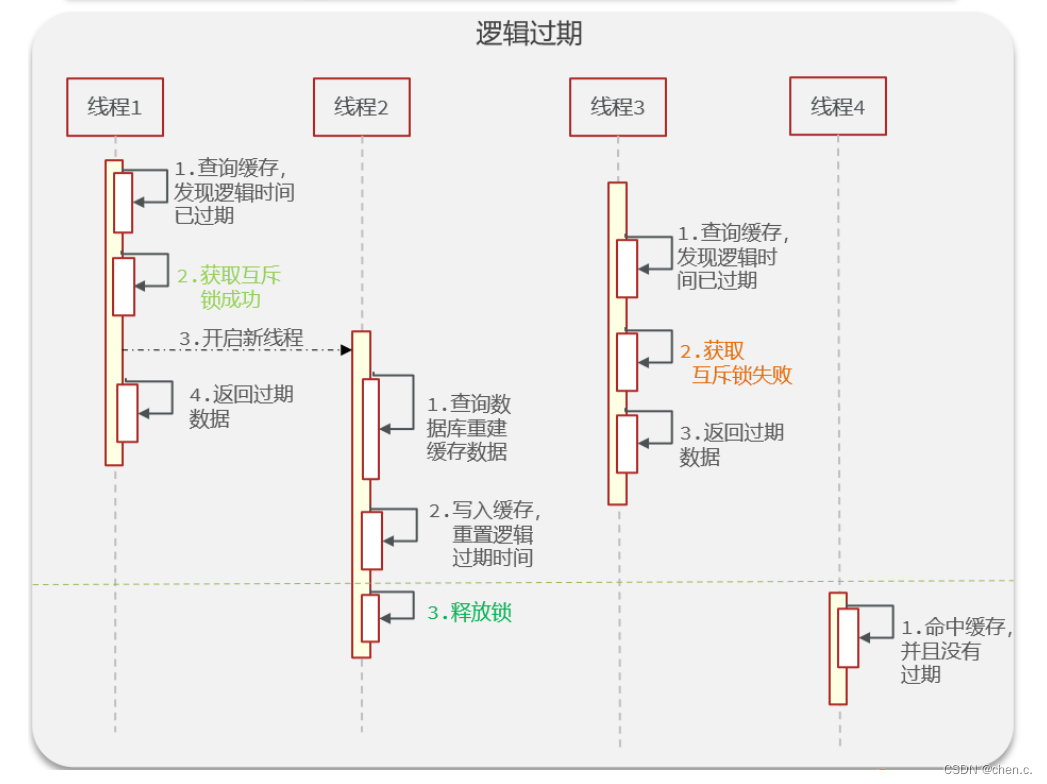
这种方案巧妙在于,异步的构建缓存,缺点在于在构建完缓存之前,返回的都是脏数据。
方案对比
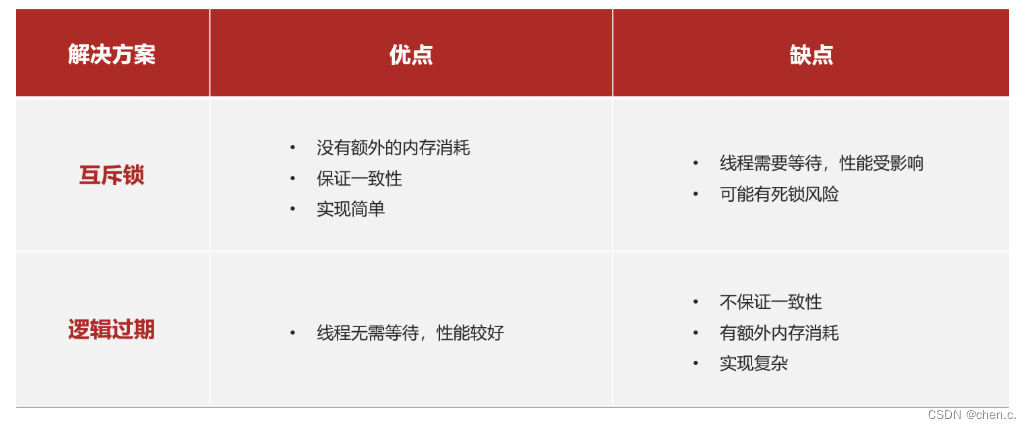
互斥锁方案:由于保证了互斥性,所以数据一致,且实现简单,因为仅仅只需要加一把锁而已,也没其他的事情需要操心,所以没有额外的内存消耗,缺点在于有锁就有死锁问题的发生,且只能串行执行性能肯定受到影响。
逻辑过期方案: 线程读取过程中不需要等待,性能好,有一个额外的线程持有锁去进行重构数据,但是在重构数据完成前,其他的线程只能返回之前的数据,且实现起来麻烦。
智能推荐
CH340系列介绍和STM32的BOOT模式选择烧录模式_ch340n-程序员宅基地
文章浏览阅读6.2k次,点赞7次,收藏33次。STM32入门必须要了解的知识。_ch340n
谷歌云盘将共享链接中的文件保存到自己的云盘中_谷歌云盘怎么保存别人分享的文件-程序员宅基地
文章浏览阅读1.5w次,点赞3次,收藏17次。如何将别人共享的谷歌云盘文件复制到自己的云盘?问题介绍工具使用问题介绍谷歌云盘google drive在接收别人共享的文件时,文件的所有者是原作者,被共享者虽然暂时是可以正常访问该文件的全部信息,但是一旦原有作者删除该文件,被共享者就不能够再访问该文件,因此此时需要将该文件复制到自己的云盘中,以防止内容过期。工具Google colab使用1、首先将分享文件的快捷方式添加到 My Drive 中2、进入google colab,绑定谷歌云盘,黑框所示,第三个图标(可能右侧会提示运行一个代码块_谷歌云盘怎么保存别人分享的文件
uniapp 实现app版本更新_uniapp封装js版本号更新-程序员宅基地
文章浏览阅读529次。在显示版本信息页面,增加点击事件,点击时调用检测版本方法。在登录成功以后调用之前写好的检测版本的js;在onLaunch周期里面更改为true;在登录界面获取这个变量,并更改为false。至此登录检测更新就可以了。_uniapp封装js版本号更新
局域网唤醒计算机,电脑远程开机_局域网唤醒电脑 | 茶杯猫-程序员宅基地
文章浏览阅读4.9k次。需要从你家的另一个房间快速打开你的电脑吗?有了局域网唤醒,你就可以了。下面是如何设置它以及为什么要使用它。有没有想过你可以把电脑从睡眠模式中唤醒,而不必费力地走过去,按下电源按钮?Wake-on-LAN允许您使用其网络连接打开计算机,因此您可以通过轻触按钮从家中的任何位置启动计算机。例如,我经常使用Chrome远程桌面访问楼上的工作站。但如果我的工作站在睡觉,我不需要上楼去打开它。LAN唤醒允许我..._局域网唤醒电脑开机
报名PMP考试需要满足哪些条件?-程序员宅基地
文章浏览阅读227次,点赞6次,收藏4次。项目经验这一点,PMP报考人员是需要有项目管理经验,而所说的具有多少小时的项目管理经验,指的是项目相关经验,比如参与项目研发、测试、交付、运维、技术支持、售前等,这个项目经验也是一个国际上的广义概念,万事皆成项目,做的任何工作都可以规划成是项目。
720云手机电动云台全新上市,让手机能自动拍摄亿万像素VR全景-程序员宅基地
文章浏览阅读638次,点赞21次,收藏14次。除了VR全景拍摄模式,720云手机电动云台还具有3D物体摄影、延时摄影的功能,亦可充当普通视频拍摄的稳定器。通过720云手机电动云台,希望为不同行业需要进行VR全景影像采集、VR全景营销宣传、VR展厅、VR全景工程等需求,提供一个简单、高效、可靠的全景拍摄解决方案,让每个人都能够轻松将VR全景这一独特的视觉技术运用到工作与生活之中。720云的手机电动云台,以其极简操作,超强的亿像素拍摄能力、坚固轻便的设计、极致的使用便捷性,为追求高质量全景图像的专业摄影师和爱好者带来了全新的创作体验。
随便推点
时光煮雨 Unity3D让物体动起来③—UGUI DoTween&Unity Native2D实现-程序员宅基地
文章浏览阅读55次。本文首发蛮牛,次发博客园。接系列 第一篇,第二篇,本文为第三篇,再次感谢“武装三藏”在前两篇无私且精彩的问题解答写在最前,时光煮雨,为了怀念以下引用曾今读过的一些教程文章 其实这3种动画都有它特定的使用场合。 第一种动画适合创建简单的对象位移及直接性质的属性更改(在后面的教程中,我还将更深入的挖掘Storyboard动画的潜力,动态创建更复杂的基于KeyFra..._unity3d物体动起来
自动更新Android应用后, app 进入后台重进会重启_安卓app每次启动会检测更新并自动更新后提升重启-程序员宅基地
文章浏览阅读4.2k次。[转]从Installer直接打开应用程序会出现Android系统bug2014-12-16阅读194 评论1问题现象:用Android系统自带的Installer安装完应用后,会有以下两个不同表现:1,用户直接在installer界面打开应用。然后按home键后台运行,此时如果再点击该应用的launcher图标或者快捷方式进入,会发现该应用又会从该应用第一个页_安卓app每次启动会检测更新并自动更新后提升重启
Vue--》超详细教程——vue-cli脚手架的搭建与使用_vue-cil脚架-程序员宅基地
文章浏览阅读4.4k次,点赞69次,收藏72次。它简化了程序员基于webpack创建工程化的Vue项目的工程。其好处就是简省了程序员花费时间去配置webpack,从而目标只需专注在撰写项目应用上。,基于vue-cli这个系统,我们就可以快速搭建好“(英文名:Singleagepplication)简称SPA,顾名思义指的是,所有的功能与交互都在这唯一的一个页面内完成。_vue-cil脚架
python给游戏增加音效-程序员宅基地
文章浏览阅读256次,点赞2次,收藏2次。模块在播放音效时可能会占用一定的系统资源,特别是在同时播放多个音效时。如果你的游戏需要频繁播放音效,你可能需要考虑优化音效管理,例如使用音效池或限制同时播放的音效数量。在上面的代码中,我们在射击时播放射击音效,在敌人被击中时播放爆炸音效。你可以根据游戏的实际情况在其他事件(如玩家死亡、关卡开始等)中添加音效播放。替换为你的音效文件的实际路径。如果你的音效文件是其他格式,确保它们与。Kimi: 为了增加音效播放功能,你需要首先确保你的音效文件(例如。格式)已经准备好,并且放在你的项目目录中。
深度网络二手市场在线推荐-程序员宅基地
文章浏览阅读78次。这篇文章的一个启发点是使用Siamese网络和注意力模型将不同类别的特征集成,从而解决数据缺失的问题,然而文章中没有具体讲出注意力模型的参数是如何训练的,即模型上层如何得知下层不同子模型的数据是否缺失,是通过逻辑判断?还是直接用0值训练?或者用各模型的数据单独训练注意力参数?原文地址 https://arxiv.org/abs/1809.02130本文地址:https://www.c..._二手交易平台分类深度学习
CS229吴恩达机器学习入门(全部编程习题的matlab答案\包含原始课件\做过标记的课件\上课网站\习题网站\自己总结的笔记)_cs229习题-程序员宅基地
文章浏览阅读1.7k次,点赞5次,收藏38次。吴恩达机器学习入门,十分适合第一次接触机器学习,或者想为深度学习打基础的同学。大家可以现在coursera上注册一个账号,可以设置每周的学习进度,有每章相应的课后习题和八个编程作业,可以提交编程作业来检查做的对不对,全部完成后会得到徽章,有几个题目图片https://www.coursera.org/learn/machine-learning/home/info刷新不出来,可以科学上网后就可以看到了。coursera网站:https://www.coursera.org/learn/machine_cs229习题