9、Elasticsearch7.6.1 ES与HDFS相互转存数据-ES-Hadoop-程序员宅基地
技术标签: 大数据相关组件介绍 elasticsearch es数据写入hdfs hdfs es-hadoop 全文检索 hadoop 日志分析
Elasticsearch 系列文章
1、介绍lucene的功能以及建立索引、搜索单词、搜索词语和搜索句子四个示例实现
2、Elasticsearch7.6.1基本介绍、2种部署方式及验证、head插件安装、分词器安装及验证
3、Elasticsearch7.6.1信息搜索示例(索引操作、数据操作-添加、删除、导入等、数据搜索及分页)
4、Elasticsearch7.6.1 Java api操作ES(CRUD、两种分页方式、高亮显示)和Elasticsearch SQL详细示例
5、Elasticsearch7.6.1 filebeat介绍及收集kafka日志到es示例
6、Elasticsearch7.6.1、logstash、kibana介绍及综合示例(ELK、grok插件)
7、Elasticsearch7.6.1收集nginx日志及监测指标示例
8、Elasticsearch7.6.1收集mysql慢查询日志及监控
9、Elasticsearch7.6.1 ES与HDFS相互转存数据-ES-Hadoop
文章目录
本文简单的介绍了ES-hadoop组件功能使用,即通过ES-hadoop实现相互数据写入示例。
本文依赖es环境、hadoop环境好用。
本文分为三部分,即ES-hadoop介绍、ES数据写入hadoop和hadoop数据写入ES。
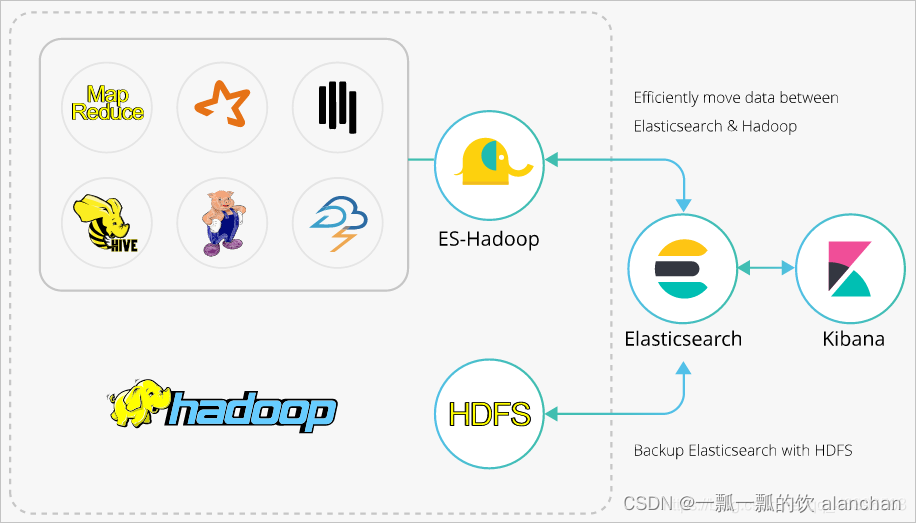
一、ES-Hadoop介绍
ES-Hadoop是Elasticsearch推出的专门用于对接Hadoop生态的工具,可以让数据在Elasticsearch和Hadoop之间双向移动,无缝衔接Elasticsearch与Hadoop服务,充分使用Elasticsearch的快速搜索及Hadoop批处理能力,实现交互式数据处理。
本文介绍如何通过ES-Hadoop实现Hadoop的Hive服务读写Elasticsearch数据。
Hadoop生态的优势是处理大规模数据集,但是其缺点也很明显,就是当用于交互式分析时,查询时延会比较长。而Elasticsearch擅长于交互式分析,对于很多查询类型,特别是对于Ad-hoc查询(即席查询),可以达到秒级。ES-Hadoop的推出提供了一种组合两者优势的可能性。使用ES-Hadoop,您只需要对代码进行很小的改动,即可快速处理存储在Elasticsearch中的数据,并且能够享受到Elasticsearch带来的加速效果。
ES-Hadoop的原理是将Elasticsearch作为MR、Spark或Hive等数据处理引擎的数据源,在计算存储分离的架构中扮演存储的角色。这和 MR、Spark或Hive的数据源并无差异,但相对于这些数据源,Elasticsearch具有更快的数据选择过滤能力。这种能力正是分析引擎最为关键的能力之一。
二、ES写入HDFS
假设es中已经存储具体索引数据,下面仅仅是将es的数据读取并存入hdfs中。
1、txt文件格式写入
1)、pom.xml
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop</artifactId>
<version>7.6.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>7.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-httpclient/commons-httpclient -->
<dependency>
<groupId>commons-httpclient</groupId>
<artifactId>commons-httpclient</artifactId>
<version>3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.google.code.gson/gson -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.10.1</version>
</dependency>
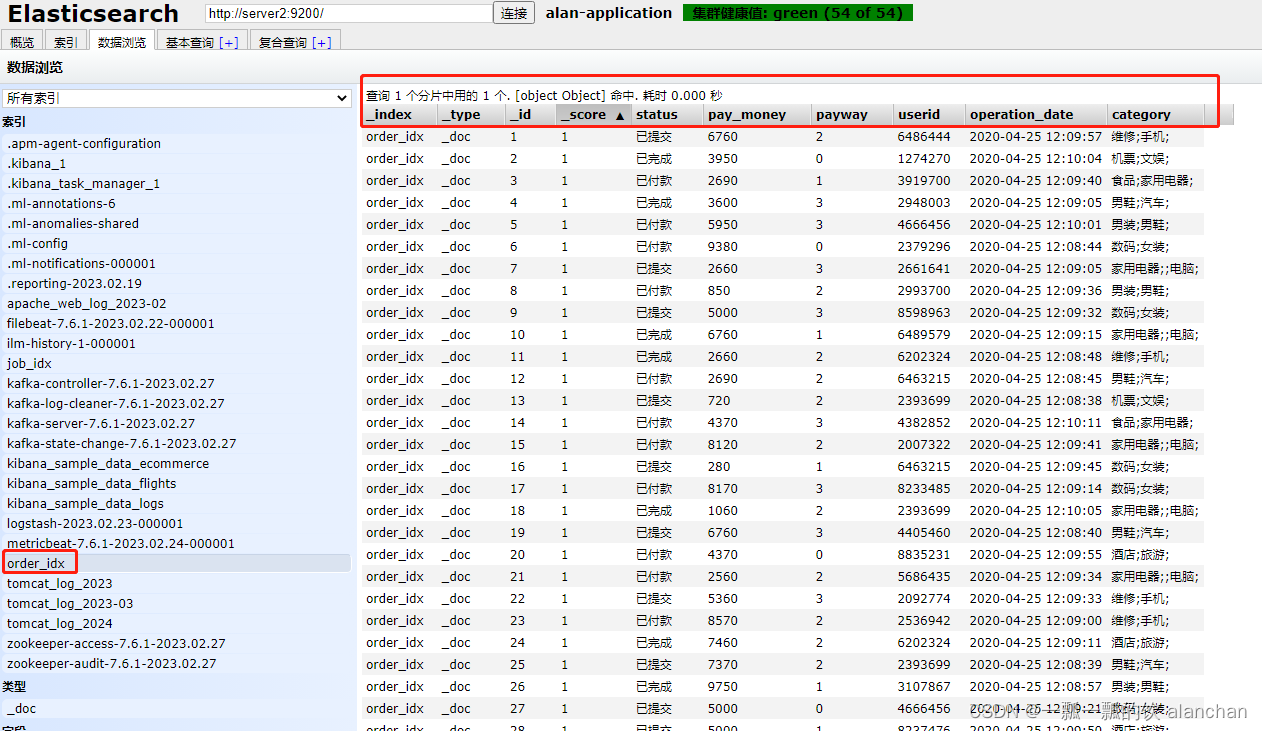
2)、示例1:order_idx
将ES中的order_idx索引数据存储至hdfs中,其中hdfs是HA。hdfs中是以txt形式存储的,其中数据用逗号隔离
- 其数据结构
key 5000,value {
status=已付款, pay_money=3820.0, payway=3, userid=4405460,operation_date=2020-04-25 12:09:51, category=维修;手机;}
- 实现
import java.io.IOException;
import java.util.Iterator;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.elasticsearch.hadoop.mr.EsInputFormat;
import org.elasticsearch.hadoop.mr.LinkedMapWritable;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class ESToHdfs extends Configured implements Tool {
private static String out = "/ES-Hadoop/test";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ESToHdfs(), args);
System.exit(status);
}
static class ESToHdfsMapper extends Mapper<Text, LinkedMapWritable, NullWritable, Text> {
Text outValue = new Text();
protected void map(Text key, LinkedMapWritable value, Context context) throws IOException, InterruptedException {
// log.info("key {} , value {}", key.toString(), value);
Order order = new Order();
// order.setId(Integer.parseInt(key.toString()));
Iterator it = value.entrySet().iterator();
order.setId(key.toString());
String name = null;
String data = null;
while (it.hasNext()) {
Map.Entry entry = (Map.Entry) it.next();
name = entry.getKey().toString();
data = entry.getValue().toString();
switch (name) {
case "userid":
order.setUserid(Integer.parseInt(data));
break;
case "operation_date":
order.setOperation_date(data);
break;
case "category":
order.setCategory(data);
break;
case "pay_money":
order.setPay_money(Double.parseDouble(data));
break;
case "status":
order.setStatus(data);
break;
case "payway":
order.setPayway(data);
break;
}
}
//log.info("order={}", order);
outValue.set(order.toString());
context.write(NullWritable.get(), outValue);
}
}
@Data
static class Order {
// key 5000 value {status=已付款, pay_money=3820.0, payway=3, userid=4405460, operation_date=2020-04-25 12:09:51, category=维修;手机;}
private String id;
private int userid;
private String operation_date;
private String category;
private double pay_money;
private String status;
private String payway;
public String toString() {
return new StringBuilder(id).append(",").append(userid).append(",").append(operation_date).append(",").append(category).append(",").append(pay_money).append(",")
.append(status).append(",").append(payway).toString();
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
conf.set("fs.defaultFS", "hdfs://HadoopHAcluster");
conf.set("dfs.nameservices", "HadoopHAcluster");
conf.set("dfs.ha.namenodes.HadoopHAcluster", "nn1,nn2");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn1", "server1:8020");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn2", "server2:8020");
conf.set("dfs.client.failover.proxy.provider.HadoopHAcluster", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
System.setProperty("HADOOP_USER_NAME", "alanchan");
conf.setBoolean("mapred.map.tasks.speculative.execution", false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution", false);
conf.set("es.nodes", "server1:9200,server2:9200,server3:9200");
// ElaticSearch 索引名称
conf.set("es.resource", "order_idx");
// 查询索引中的所有数据,也可以加条件
conf.set("es.query", "{ \"query\": {\"match_all\": { }}}");
Job job = Job.getInstance(conf, ESToHdfs.class.getName());
// 设置作业驱动类
job.setJarByClass(ESToHdfs.class);
// 设置ES的输入类型
job.setInputFormatClass(EsInputFormat.class);
job.setMapperClass(ESToHdfsMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, new Path(out));
job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
}
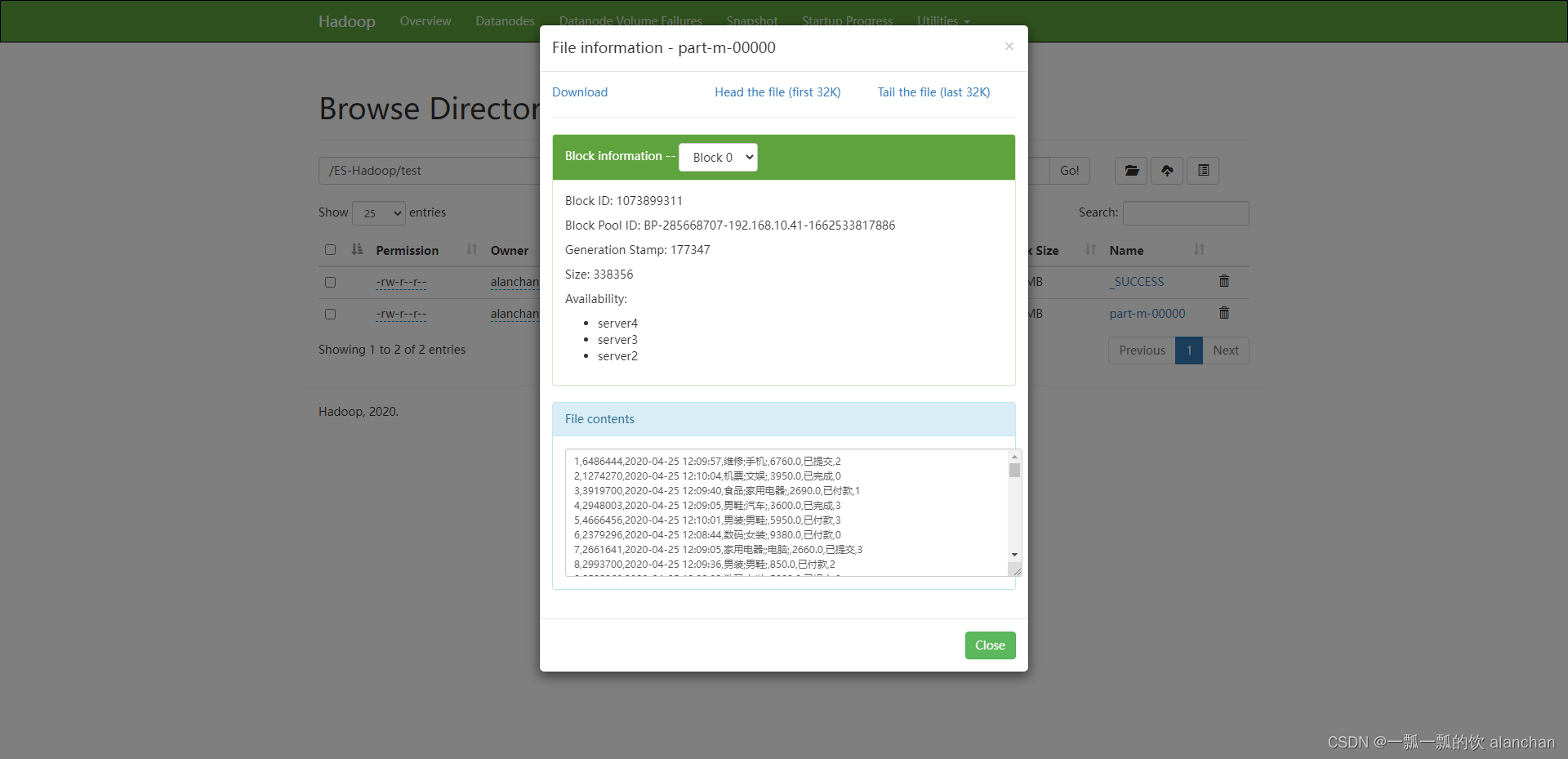
- 验证
结果如下图
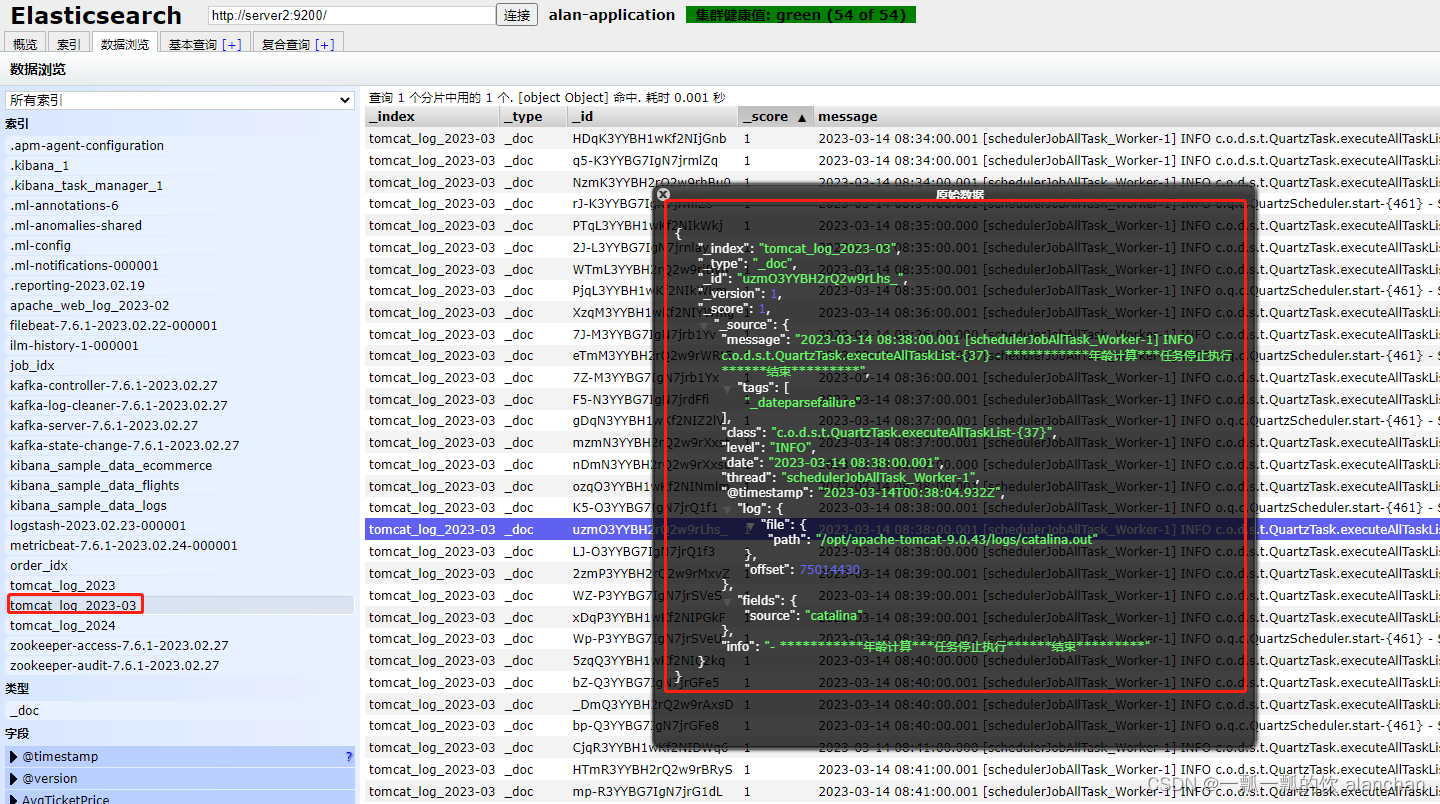
3)、示例2:tomcat_log_2023-03
将ES中的tomcat_log_2023-03索引数据存储至hdfs中,其中hdfs是HA。hdfs中是以txt形式存储的,其中数据用逗号隔离
- 其数据结构
key Uzm_44YBH2rQ2w9r5vqK , value {
message=2023-03-15 13:30:00.001 [schedulerJobAllTask_Worker-1] INFO c.o.d.s.t.QuartzTask.executeAllTaskList-{
37} - 生成消息记录任务停止执行结束*******, tags=[_dateparsefailure], class=c.o.d.s.t.QuartzTask.executeAllTaskList-{
37}, level=INFO, date=2023-03-15 13:30:00.001, thread=schedulerJobAllTask_Worker-1, fields={
source=catalina}, @timestamp=2023-03-15T05:30:06.812Z, log={
file={
path=/opt/apache-tomcat-9.0.43/logs/catalina.out}, offset=76165371}, info=- 生成消息记录任务停止执行结束*******}
- 实现
import java.io.IOException;
import java.util.Iterator;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.elasticsearch.hadoop.mr.EsInputFormat;
import org.elasticsearch.hadoop.mr.LinkedMapWritable;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class ESToHdfs2 extends Configured implements Tool {
private static String out = "/ES-Hadoop/tomcatlog";
static class ESToHdfs2Mapper extends Mapper<Text, LinkedMapWritable, NullWritable, Text> {
Text outValue = new Text();
protected void map(Text key, LinkedMapWritable value, Context context) throws IOException, InterruptedException {
// log.info("key {} , value {}", key.toString(), value);
TomcatLog tLog = new TomcatLog();
Iterator it = value.entrySet().iterator();
String name = null;
String data = null;
while (it.hasNext()) {
Map.Entry entry = (Map.Entry) it.next();
name = entry.getKey().toString();
data = entry.getValue().toString();
switch (name) {
case "date":
tLog.setDate(data.replace('/', '-'));
break;
case "thread":
tLog.setThread(data);
break;
case "level":
tLog.setLogLevel(data);
break;
case "class":
tLog.setClazz(data);
break;
case "info":
tLog.setLogMsg(data);
break;
}
}
outValue.set(tLog.toString());
context.write(NullWritable.get(), outValue);
}
}
@Data
static class TomcatLog {
private String date;
private String thread;
private String logLevel;
private String clazz;
private String logMsg;
public String toString() {
return new StringBuilder(date).append(",").append(thread).append(",").append(logLevel).append(",").append(clazz).append(",").append(logMsg).toString();
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ESToHdfs2(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
conf.set("fs.defaultFS", "hdfs://HadoopHAcluster");
conf.set("dfs.nameservices", "HadoopHAcluster");
conf.set("dfs.ha.namenodes.HadoopHAcluster", "nn1,nn2");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn1", "server1:8020");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn2", "server2:8020");
conf.set("dfs.client.failover.proxy.provider.HadoopHAcluster", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
System.setProperty("HADOOP_USER_NAME", "alanchan");
conf.setBoolean("mapred.map.tasks.speculative.execution", false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution", false);
conf.set("es.nodes", "server1:9200,server2:9200,server3:9200");
// ElaticSearch 索引名称
conf.set("es.resource", "tomcat_log_2023-03");
conf.set("es.query", "{\"query\":{\"bool\":{\"must\":[{\"match_all\":{}}],\"must_not\":[],\"should\":[]}},\"from\":0,\"size\":10,\"sort\":[],\"aggs\":{}}");
Job job = Job.getInstance(conf, ESToHdfs2.class.getName());
// 设置作业驱动类
job.setJarByClass(ESToHdfs2.class);
job.setInputFormatClass(EsInputFormat.class);
job.setMapperClass(ESToHdfs2Mapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, new Path(out));
job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
}
- 验证
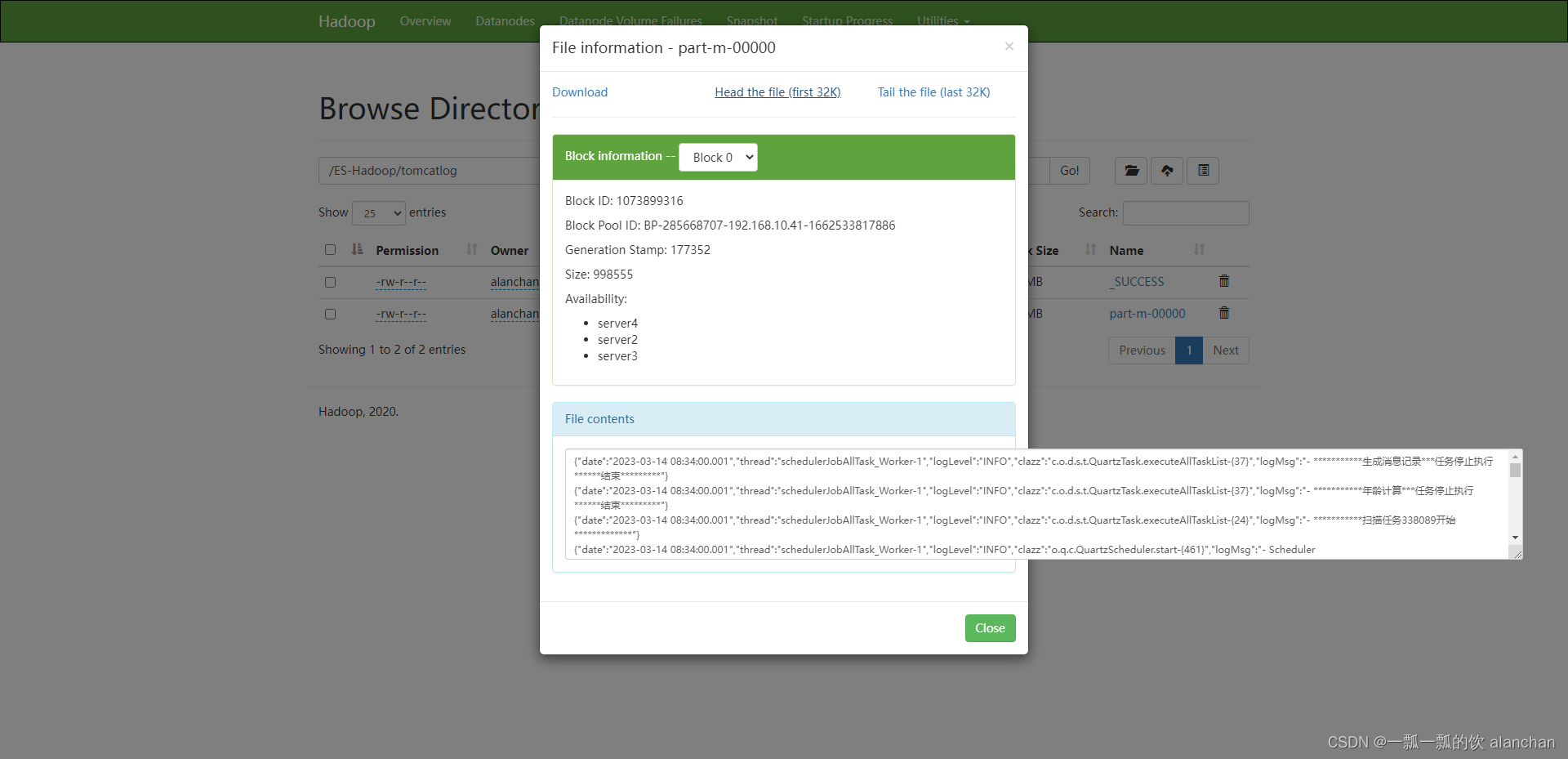
2、json文件格式写入
将ES中的tomcat_log_2023-03索引数据存储至hdfs中,其中hdfs是HA。hdfs中是以json形式存储的
- 其数据结构
key Uzm_44YBH2rQ2w9r5vqK , value {
message=2023-03-15 13:30:00.001 [schedulerJobAllTask_Worker-1] INFO c.o.d.s.t.QuartzTask.executeAllTaskList-{
37} - 生成消息记录任务停止执行结束*******, tags=[_dateparsefailure], class=c.o.d.s.t.QuartzTask.executeAllTaskList-{
37}, level=INFO, date=2023-03-15 13:30:00.001, thread=schedulerJobAllTask_Worker-1, fields={
source=catalina}, @timestamp=2023-03-15T05:30:06.812Z, log={
file={
path=/opt/apache-tomcat-9.0.43/logs/catalina.out}, offset=76165371}, info=- 生成消息记录任务停止执行结束*******}
- 实现
import java.io.IOException;
import java.util.Iterator;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.elasticsearch.hadoop.mr.EsInputFormat;
import org.elasticsearch.hadoop.mr.LinkedMapWritable;
import com.google.gson.Gson;
import lombok.Data;
public class ESToHdfsByJson extends Configured implements Tool {
private static String out = "/ES-Hadoop/tomcatlog_json";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ESToHdfsByJson(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
conf.set("fs.defaultFS", "hdfs://HadoopHAcluster");
conf.set("dfs.nameservices", "HadoopHAcluster");
conf.set("dfs.ha.namenodes.HadoopHAcluster", "nn1,nn2");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn1", "server1:8020");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn2", "server2:8020");
conf.set("dfs.client.failover.proxy.provider.HadoopHAcluster", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
System.setProperty("HADOOP_USER_NAME", "alanchan");
conf.setBoolean("mapred.map.tasks.speculative.execution", false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution", false);
conf.set("es.nodes", "server1:9200,server2:9200,server3:9200");
// ElaticSearch 索引名称
conf.set("es.resource", "tomcat_log_2023-03");
conf.set("es.query", "{\"query\":{\"bool\":{\"must\":[{\"match_all\":{}}],\"must_not\":[],\"should\":[]}},\"from\":0,\"size\":10,\"sort\":[],\"aggs\":{}}");
Job job = Job.getInstance(conf, ESToHdfs2.class.getName());
// 设置作业驱动类
job.setJarByClass(ESToHdfsByJson.class);
job.setInputFormatClass(EsInputFormat.class);
job.setMapperClass(ESToHdfsByJsonMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, new Path(out));
job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
static class ESToHdfsByJsonMapper extends Mapper<Text, LinkedMapWritable, NullWritable, Text> {
Text outValue = new Text();
private Gson gson = new Gson();
protected void map(Text key, LinkedMapWritable value, Context context) throws IOException, InterruptedException {
// log.info("key {} , value {}", key.toString(), value);
TomcatLog tLog = new TomcatLog();
// tLog.setId(key.toString());
Iterator it = value.entrySet().iterator();
String name = null;
String data = null;
while (it.hasNext()) {
Map.Entry entry = (Map.Entry) it.next();
name = entry.getKey().toString();
data = entry.getValue().toString();
switch (name) {
case "date":
tLog.setDate(data.replace('/', '-'));
break;
case "thread":
tLog.setThread(data);
break;
case "level":
tLog.setLogLevel(data);
break;
case "class":
tLog.setClazz(data);
break;
case "info":
tLog.setLogMsg(data);
break;
}
}
outValue.set(gson.toJson(tLog));
context.write(NullWritable.get(), outValue);
}
}
@Data
static class TomcatLog {
// private String id ;
private String date;
private String thread;
private String logLevel;
private String clazz;
private String logMsg;
}
}
- 验证
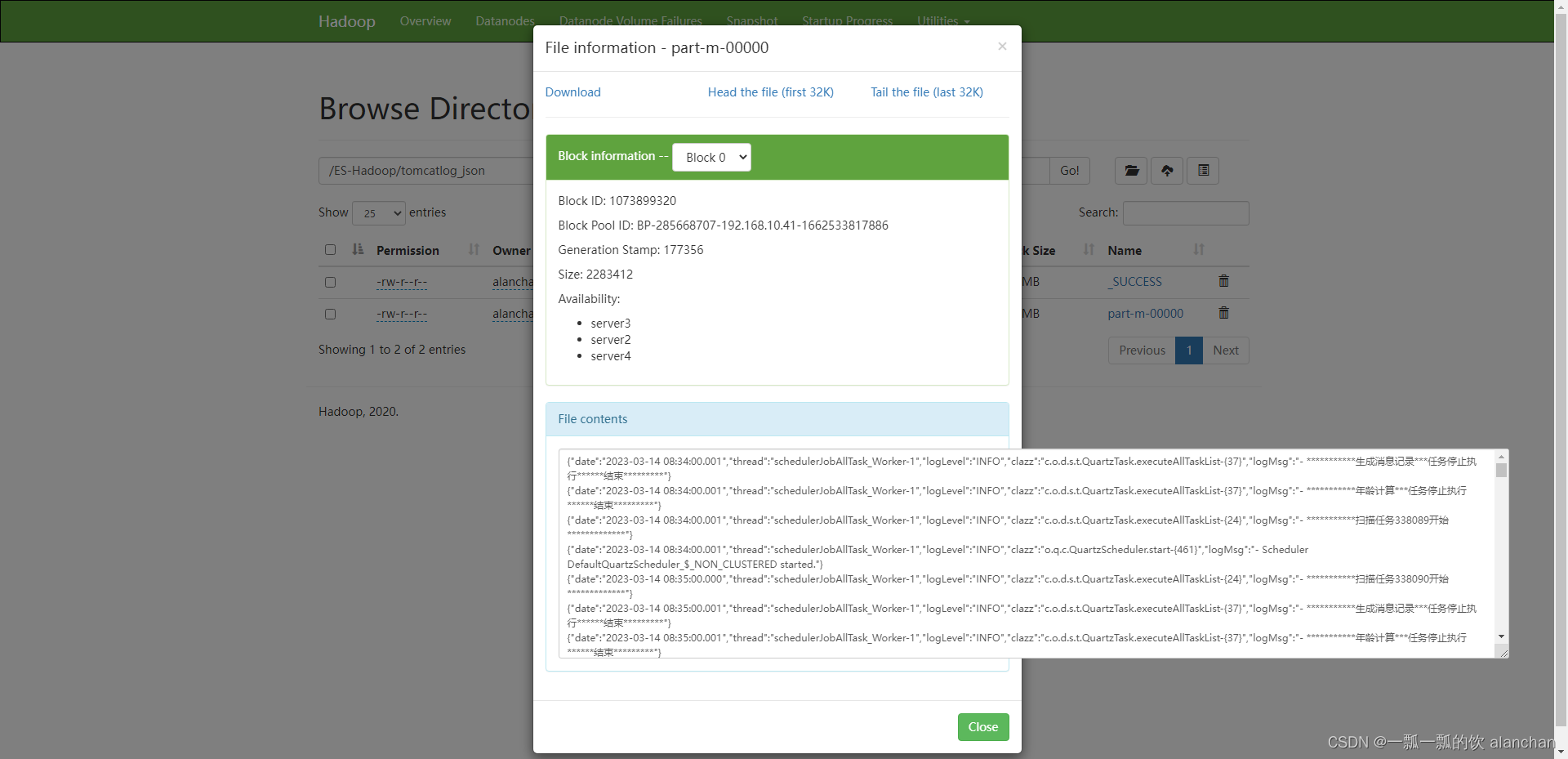
三、HDFS写入ES
本示例以上述例子中存入hdfs的数据。经过测试,ES只能将json的数据导入。
pom.xml参考上述例子
1、txt文件写入
先将数据转换成json后存入
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.elasticsearch.hadoop.mr.EsOutputFormat;
import com.google.gson.Gson;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class HdfsTxtDataToES extends Configured implements Tool {
private static String out = "/ES-Hadoop/tomcatlog";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new HdfsTxtDataToES(), args);
System.exit(status);
}
@Data
static class TomcatLog {
private String date;
private String thread;
private String logLevel;
private String clazz;
private String logMsg;
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
conf.set("fs.defaultFS", "hdfs://HadoopHAcluster");
conf.set("dfs.nameservices", "HadoopHAcluster");
conf.set("dfs.ha.namenodes.HadoopHAcluster", "nn1,nn2");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn1", "server1:8020");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn2", "server2:8020");
conf.set("dfs.client.failover.proxy.provider.HadoopHAcluster", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
System.setProperty("HADOOP_USER_NAME", "alanchan");
conf.setBoolean("mapred.map.tasks.speculative.execution", false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution", false);
conf.set("es.nodes", "server1:9200,server2:9200,server3:9200");
// ElaticSearch 索引名称,可以不提前创建
conf.set("es.resource", "tomcat_log_2024");
// Hadoop上的数据格式为JSON,可以直接导入
conf.set("es.input.json", "yes");
Job job = Job.getInstance(conf, HdfsTxtDataToES.class.getName());
// 设置作业驱动类
job.setJarByClass(HdfsTxtDataToES.class);
// 设置EsOutputFormat
job.setOutputFormatClass(EsOutputFormat.class);
job.setMapperClass(HdfsTxtDataToESMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(out));
job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
static class HdfsTxtDataToESMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
Text outValue = new Text();
TomcatLog tLog = new TomcatLog();
Gson gson = new Gson();
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
log.info("key={},value={}", key, value);
// date:2023-03-13 17:33:00.001,
// thread:schedulerJobAllTask_Worker-1,
// loglevel:INFO,
// clazz:o.q.c.QuartzScheduler.start-{461},
// logMsg:- Scheduler DefaultQuartzScheduler_$_NON_CLUSTERED started.
String[] lines = value.toString().split(",");
tLog.setDate(lines[0]);
tLog.setThread(lines[1]);
tLog.setLogLevel(lines[2]);
tLog.setClazz(lines[3]);
tLog.setLogMsg(lines[4]);
outValue.set(gson.toJson(tLog));
context.write(NullWritable.get(), outValue);
}
}
}
2、json文件写入
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.elasticsearch.hadoop.mr.EsOutputFormat;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class HdfsJsonDataToES extends Configured implements Tool {
private static String out = "/ES-Hadoop/tomcatlog_json";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new HdfsJsonDataToES(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
conf.set("fs.defaultFS", "hdfs://HadoopHAcluster");
conf.set("dfs.nameservices", "HadoopHAcluster");
conf.set("dfs.ha.namenodes.HadoopHAcluster", "nn1,nn2");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn1", "server1:8020");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn2", "server2:8020");
conf.set("dfs.client.failover.proxy.provider.HadoopHAcluster", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
System.setProperty("HADOOP_USER_NAME", "alanchan");
conf.setBoolean("mapred.map.tasks.speculative.execution", false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution", false);
conf.set("es.nodes", "server1:9200,server2:9200,server3:9200");
// ElaticSearch 索引名称,可以不提前创建
conf.set("es.resource", "tomcat_log_2023");
//Hadoop上的数据格式为JSON,可以直接导入
conf.set("es.input.json", "yes");
Job job = Job.getInstance(conf, HdfsJsonDataToES.class.getName());
// 设置作业驱动类
job.setJarByClass(HdfsJsonDataToES.class);
job.setOutputFormatClass(EsOutputFormat.class);
job.setMapperClass(HdfsJsonDataToESMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(out));
job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
static class HdfsJsonDataToESMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
log.info("key={},value={}",key,value);
context.write(NullWritable.get(), value);
}
}
}
以上,简单的介绍了ES-hadoop组件功能使用,即通过ES-hadoop实现相互数据写入示例。
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法