ONNXRuntime (Python) GPU 部署配置记录_onnxruntime-gpu-程序员宅基地
技术标签: AI/ML/DL 深度学习 pytorch 人工智能
0. 前言

最近偶尔捣鼓了一下onnxruntime-gpu(python版本)的服务端部署,于是打算简单记录一下一些关键步骤,免得以后忘了。确实,有些时候我们并不全是需要把模型转成MNN/ncnn/TNN后走移动端部署那套,服务端的部署也是个很重要的场景。比较常用的服务端部署方案包括tensorrt、onnxruntime-gpu等等。onnxruntime-gpu版本可以说是一个非常简单易用的框架,因为通常用pytorch训练的模型,在部署时,会首先转换成onnx,而onnxruntime和onnx又是有着同一个爸爸,无疑,在op的支持上肯定是最好的。采用onnxruntime来部署onnx模型,不需要经过任何二次的模型转换。当然,不同的推理引擎会有不同优势,这里就不做对比了,这篇短文主要记录一下onnxruntime-gpu版本配置的一些主要步骤。
1. 基础镜像选择
这一步很重要,只有选择了正确的基础镜像,你才能顺利地使用onnxruntime-gpu版本。onnxruntime-gpu版本依赖于cuda库,因此你选择的镜像中必须要包含cuda库(动态库),否则就算能顺利安装onnxruntime-gpu版本,也无法真正地使用到GPU。进入docker hub 搜索pytorch的镜像,我们看到有很多选择,比如1.8.0版本的,就有cuda10.2、cuda11.1的devel和runtime版本。看到下面这张图。你需要选择的是带有cuda库的devel版本。
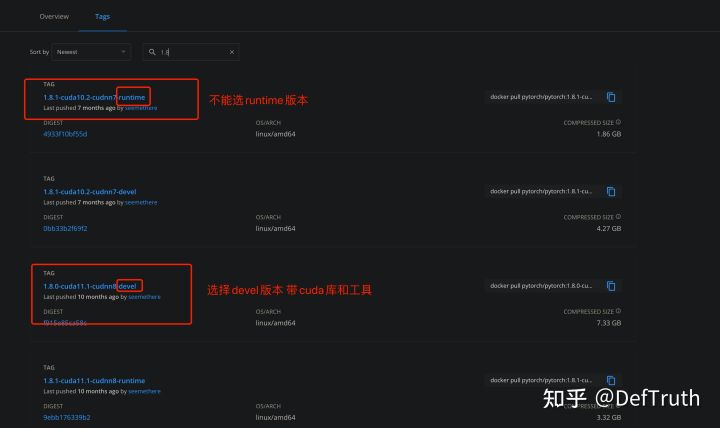
下载合适的镜像(看你驱动版本的高低进行选择)
docker pull pytorch/pytorch:1.8.0-cuda11.1-cudnn8-devel # 如果你的nvidia驱动较高
docker pull pytorch/pytorch:1.8.1-cuda10.2-cudnn7-devel # 如果你的nvidia驱动较低2. 关于runtime和devel的补充
【更新:2022/01/18】以上第1节是文章关于runtime和devel选择的原文。经【小白】大佬提醒,这段理解存在一定的错误。因此这里补充一下学到的新知识~ 选择devel的原因之一是之前发现用runtime版本出现无法使用的问题,换成devel后就正常的,之二是,查到一些相关的教程里面提到需要export导出CUDA库所在的路径到PATH,那么就需要devel版本里面的cuda库。经【小白】大佬指出,runtime版本有问题,“大概是依赖版本问题,这东西重来不提示版本不对,靠自己把握。devel用来编译,runtime用来发版本。” 官方的docker构建脚本在:
因此,如果你只是使用pip进行安装,那么runtime版本和devel版本的pytorch镜像都是可行的。如果你需要自己从源码进行构建,那么就需要devel版本。
3. 正确启动Docker镜像
注意,首先你需要通过nvidia-docker启动并登录pytorch1.8.0的容器,使用docker启动将无法获取GPU信息。
GPU_ID=0
CONTAINER_NAME=onnxruntime_gpu_test
nvidia-docker run -idt -p ${PORT2}:${PORT1} \ # 指定你想设置的映射端口;idt中的d表示后台运行,去掉d表示不后台运行
-v ${SERVER_DIR}:${CONTAINER_DIR} \ # 挂载共享目录 如果需要 不需要的可以去掉这句
--shm-size=16gb --env NVIDIA_VISIBLE_DEVICES="${GPU_ID}" \ # 指定GPU_ID
--name="${CONTAINER_NAME}" pytorch/pytorch:1.8.0-cuda11.1-cudnn8-devel # 指定后台启动的镜像安装nvidia-docker有很多参考,这里就不重复了。比如
Ubuntu16.04安装nvidia-docker24 赞同 · 10 评论文章
需要注意的是,首先你得确保宿主机的显卡驱动等是正常的,否则在容器内无法使用GPU,比如
nvidia-smi # 看看是否识别到GPU
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.118.02 Driver Version: 440.118.02 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P40 Off | 00000000:88:00.0 Off | 0 |
| N/A 26C P8 10W / 250W | 10MiB / 22919MiB | 0% Default |
+-------------------------------+----------------------+----------------------+关于nvidia驱动的安装,也有很多文章可以参考,也不重复了。比如
Ubuntu 18.04 安装 NVIDIA 显卡驱动517 赞同 · 203 评论文章正在上传…重新上传取消
4. 安装onnxruntime-gpu版本
进入容器后,通过pip安装gpu版本的onnxruntime。如果前面的步骤都没有问题的话,这个步骤应该会很顺利。
pip install onnxruntime-gpu # 安装GPU版本先确认下onnxruntime是否真的能用到你的GPU,如果能获取 TensorrtExecutionProvider 和 CUDAExecutionProvider,那么恭喜你!一切正常!你可以愉快地进行GPU推理部署了。
root@xxx:/workspace# python
Python 3.8.8 (default, Feb 24 2021, 21:46:12)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import onnxruntime
>>> onnxruntime.get_device()
'GPU'
>>> onnxruntime.get_available_providers()
['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider']
>>> exit()如果你发现无法使用GPU,可以尝试增加以下设置。
export PATH=/usr/local/cuda-11.1/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.1/lib64:$LD_LIBRARY_PATH5. TensorrtExecutionProvider何时有效
【更新:2022/01/18】以上第4节是文章关于 TensorrtExecutionProvider 和 CUDAExecutionProvider使用的原文。经【小白】大佬提醒,TensorrtExecutionProvider 并不一定会被执行,官方文档有提到,通过pip安装的onnxruntime-gpu,只能用到 CUDAExecutionProvider 进行加速。只有从源码编译的onnxruntime-gpu 才能用TensorrtExecutionProvider进行加速(这个我还没试过,之后有时间再来填源码编译的坑~)。官方文档如下:
Official Python packages on Pypi only support the default CPU (MLAS)
and default GPU (CUDA) execution providers. For other execution providers,
you need to build from source. The recommended instructions build the
wheel with debug info in parallel. Tune performance我们也可以来看看onnxruntime python的一小段源码:
def _create_inference_session(self, providers, provider_options):
available_providers = C.get_available_providers()
# validate providers and provider_options before other initialization
providers, provider_options = check_and_normalize_provider_args(providers,
provider_options,
available_providers)
# Tensorrt can fall back to CUDA. All others fall back to CPU.
if 'TensorrtExecutionProvider' in available_providers:
self._fallback_providers = ['CUDAExecutionProvider', 'CPUExecutionProvider']
else:
self._fallback_providers = ['CPUExecutionProvider']以及,一段初始化调用_fallback_providers的逻辑。
try:
self._create_inference_session(providers, provider_options)
except RuntimeError:
if self._enable_fallback:
print("EP Error using {}".format(self._providers))
print("Falling back to {} and retrying.".format(self._fallback_providers))
self._create_inference_session(self._fallback_providers, None)
# Fallback only once.
self.disable_fallback()
else:
raise可以看到,TensorrtExecutionProvider可以回退到CUDAExecutionProvider。如果你设置了TensorrtExecutionProvider,那么onnxruntime会首先尝试使用包含TensorrtExecutionProvider的providers构建InferenceSession,如果失败的话,则回退到只使用['CUDAExecutionProvider','CPUExecutionProvider'],并且打印两句log:
print("EP Error using {}".format(self._providers))
print("Falling back to {} and retrying.".format(self._fallback_providers))emmmm......,不过在我的使用中(pip 安装的 onnxruntime-gpu最新版),并没有打印这两句log,所以是用到了TensorrtExecutionProvider???不太清楚是不是新版本优化了这个问题。
6. 使用举例
用法其实很简单,只要在新建InferenceSession的时候,加入 TensorrtExecutionProvider 和 CUDAExecutionProvider 就可以了。以下这行代码,无论是CPU还是GPU部署,都是通用的。在跑推理的时候,检查一下显存占用有没有起来,有就说明一切正常。
self.session = onnxruntime.InferenceSession(
"YOUR-ONNX-MODEL-PATH",
providers=onnxruntime.get_available_providers()
)如果 要可变可以控制providers,例如:
if device == 'cpu':
providers = ['CPUExecutionProvider']
elif device == 'gpu':
providers = ['CUDAExecutionProvider', 'CPUExecutionProvider']ONNXRuntime-gpu可能无法使用GPU,与CUDA的关系参考:CUDA - onnxruntime
6. 效率对比
简单罗列一下我使用onnxruntime-gpu推理的性能(只是和cpu简单对比下,不是很严谨,暂时没有和其他推理引擎作对比)
| CPU | GPU | 次数 | 提速 |
|---|---|---|---|
| 2637ms(16thread) | 131ms | 100 | 15-20x |
智能推荐
我们应如何度过自己的大学生活?_如何度过大学生活1000字-程序员宅基地
文章浏览阅读3.1k次。我们应如何度过自己的大学生活? 踏着九月的烈日,我们成功地来到了河南理工大学,开始了我们的大学生活,那么你可曾想过,我们到底应该如何度过我们的大学生活才算有意义呢? 可曾记得高中老师说的最多的一句话:“好好学吧!上了大学就轻松了!”每当听到这句话时都会给我们莫大的鼓励,也让我们对大学充满了憧憬。那么大学生活真如高中老师说的那样轻松吗?其实不然!高中老师所谓的轻松只是在一定程度上正课的时..._如何度过大学生活1000字
python snownlp情感分析简易demo(分享),没有我Python干不成的事!_snowlp情感分析代码-程序员宅基地
文章浏览阅读745次。SnowNLP是国人开发的python类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。注意本程序都是处理的unicode编码,所以使用时请自行decode成unicode。MIT许可下发行。其github主页可能有些不准确,我也是随便提取的数据,不过snownlp还是号称情感分析准确很高的!_snowlp情感分析代码
命令行安装todesk_todesk命令行csdn-程序员宅基地
文章浏览阅读653次,点赞10次,收藏7次。要想通过命令行安装todesk,也是比较简单的。_todesk命令行csdn
如何开发一个个人微信小程序,微信小程序开发入门教程_微信小程序怎么开发自己的小程序-程序员宅基地
文章浏览阅读10w+次,点赞183次,收藏1.1k次。做任何程序开发要首先找到其官方文档,我们先来看看其有哪些官方文档。微信小程序开发文档链接为:https://mp.weixin.qq.com/debug/wxadoc/dev/index.html,如下图:这里就是做微信小程序开发的全部官方文档。知道了文档的位置,下面我们来介绍下如何做一个微信小程序开发:第一步:下载微信小程序开发者工具并安装,下载路径:https://mp.weix..._微信小程序怎么开发自己的小程序
前端解决浏览器直接打开图片URL,下载问题_前端想要通过url下载但是打开了网页-程序员宅基地
文章浏览阅读1w次,点赞3次,收藏7次。本周做的项目中有一个下载图片的功能,拿到后台返回的url,像文件一样,直接window.open,发现图片没有像文件一样被下载,而是重新打开了一个页面展示图片。然后我尝试了转成base64等方法也还是有跨域的问题。后来就想着自己把这个url,发送给Node,node转成数据流返回给我,我再下载。话不多说,上代码:vue前端代码: downZip (urls) { ..._前端想要通过url下载但是打开了网页
什么是内部类?成员内部类、静态内部类、局部内部类和匿名内部类的区别及作用?_成员内部类和局部内部类的区别-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏42次。一、什么是内部类?or 内部类的概念内部类是定义在另一个类中的类;下面类TestB是类TestA的内部类。即内部类对象引用了实例化该内部对象的外围类对象。public class TestA{ class TestB {}}二、 为什么需要内部类?or 内部类有什么作用?1、 内部类方法可以访问该类定义所在的作用域中的数据,包括私有数据。2、内部类可以对同一个包中的其他类隐藏起来。3、 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。三、 内部类的分类成员内部_成员内部类和局部内部类的区别
随便推点
语义分割入门的总结-程序员宅基地
文章浏览阅读740次。点击上方“小白学视觉”,选择加"星标"或“置顶”重磅干货,第一时间送达作者:Yanpeng Sunhttps://zhuanlan.zhihu.com/p/74318967声明:仅做学术分..._语义分割两个目标重合怎么
SpringBoot实践(三十五):JVM信息分析_怎样查看springboot项目的jvm状态-程序员宅基地
文章浏览阅读902次。JVM分析可以也可以使用,那么什么时候用到jvm信息分析呢,一般生产测试环境,能够最大化将问题暴露,但是总有些问题只有生产运行很长时间后才会被发现,jvm分析经常用于运行了很久的系统有异常情况时的调优,比如堆内存本身分配不合理,新生代中eden比例太低等。_怎样查看springboot项目的jvm状态
基于springboot+vue的戒毒所人员管理系统 毕业设计-附源码251514_戒毒所管理系统-程序员宅基地
文章浏览阅读288次。戒毒所人员管理系统的开发是采用java语言,基于MVVM模式进行开发,采取MySQL作为后台数据的主要存储单元,采用Springboot框架实现了本系统的全部功能。戒毒所人员管理系统,具有戒毒人员管理、尿检管理、戒毒管理、治疗分类、社会跟踪等功能,本系统代码的复用率高,系统维护代价小,具有方便、灵活、高效等特征。_戒毒所管理系统
【LeetCode】面试题57 - II. 和为s的连续正数序列_leet code 和为s的正数序列 java-程序员宅基地
文章浏览阅读174次。来源:力扣(LeetCode)链接:https://leetcode-cn.com/problems/he-wei-sde-lian-xu-zheng-shu-xu-lie-lcof题目描述:输入一个正整数 target ,输出所有和为 target 的连续正整数序列(至少含有两个数)。序列内的数字由小到大排列,不同序列按照首个数字从小到大排列。示例 1:输入:target = 9..._leet code 和为s的正数序列 java
java spark的使用和配置_使用java调用spark注册进去的程序-程序员宅基地
文章浏览阅读3.3k次。前言spark在java使用比较少,多是scala的用法,我这里介绍一下我在项目中使用的代码配置详细算法的使用请点击我主页列表查看版本jar版本说明spark3.0.1scala2.12这个版本注意和spark版本对应,只是为了引jar包springboot版本2.3.2.RELEASEmaven<!-- spark --> <dependency> <gro_使用java调用spark注册进去的程序
汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用_uds协议栈 源代码-程序员宅基地
文章浏览阅读4.8k次。汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用,代码精简高效,大厂出品有量产保证。:139800617636213023darcy169_uds协议栈 源代码