论文阅读 Vision Transformer - VIT_vision transformer论文-程序员宅基地
技术标签: 论文阅读 深度学习 transformer papers
1 摘要
1.1 核心
通过将图像切成patch线形层编码成token特征编码的方法,用transformer的encoder来做图像分类
2 模型架构
2.1 概览
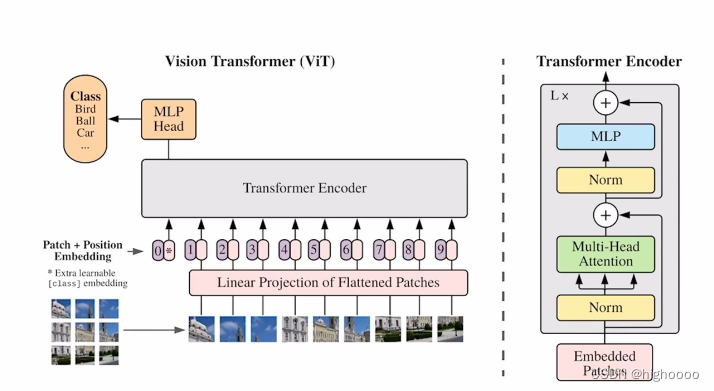
2.2 对应CV的特定修改和相关理解
解决问题:
- transformer输入限制: 由于自注意力+backbone,算法复杂度为o(n²),token长度一般要<512才足够运算
解决:a) 将图片转为token输入 b) 将特征图转为token输入 c)√ 切patch转为token输入 - transformer无先验知识:卷积存在平移不变性(同特征同卷积核同结果)和局部相似性(相邻特征相似结果),
而transformer无卷积核概念,只有整个编解码器,需要从头学
解决:大量数据训练 - cv的各种自注意力机制需要复杂工程实现:
解决:直接用整个transformer模块 - 分类head:
解决:直接沿用transformer cls token - position编码:
解决:1D编码
pipeline:
224x224输入切成16x16patch进行位置编码和线性编码后增加cls token 一起输入的encoder encoder中有L个selfattention模块
输出的cls token为目标类别
3 代码
如果理解了transformer,看完这个结构感觉真的很简单,这篇论文也只是开山之作,没有特别复杂的结构,所以想到代码里看看。
import torch
from torch import nn
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
# helpers
def pair(t):
return t if isinstance(t, tuple) else (t, t)
# classes
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.norm = nn.LayerNorm(dim)
self.attend = nn.Softmax(dim = -1)
self.dropout = nn.Dropout(dropout)
# linear(1024 , 3072)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
# [1, 65, 1024]
x = self.norm(x)
# [1, 65, 1024]
qkv = self.to_qkv(x).chunk(3, dim = -1)
# self.to_qkv(x) [1, 65, 3072]
# self.to_qkv(x).chunk(3,-1) [3, 1, 65, 1024]
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
# q,k,v [1, 65, 1024] -> [1, 16, 65, 64]
# 把 65个1024的特征分为 heads个65个d维的特征 然后每个heads去分别有自己要处理的隐藏层,对不同的特征建立不同学习能力
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
# [1, 16, 65, 64] * [1, 16, 64, 65] -> [1, 16, 65, 65]
# scale 保证在softmax前所有的值都不太大
attn = self.attend(dots)
# softmax [1, 16, 65, 65]
attn = self.dropout(attn)
# dropout [1, 16, 65, 65]
out = torch.matmul(attn, v)
# out [1, 16, 65, 64]
out = rearrange(out, 'b h n d -> b n (h d)')
# out [1, 65, 1024]
return self.to_out(out)
# out [1, 65, 1024]
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout),
FeedForward(dim, mlp_dim, dropout = dropout)
]))
def forward(self, x):
# [1, 65, 1024]
for attn, ff in self.layers:
# [1, 65, 1024]
x = attn(x) + x
# [1, 65, 1024]
x = ff(x) + x
# [1, 65, 1024]
return self.norm(x)
# shape不会改变
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
assert pool in {
'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
# num_patches 64
# patch_dim 3072
# dim 1024
self.to_patch_embedding = nn.Sequential(
#Rearrange是einops中的一个方法
# einops:灵活和强大的张量操作,可读性强和可靠性好的代码。支持numpy、pytorch、tensorflow等。
# 代码中Rearrage的意思是将传入的image(3,224,224),按照(3,(h,p1),(w,p2))也就是224=hp1,224 = wp2,接着把shape变成b (h w) (p1 p2 c)格式的,这样把图片分成了每个patch并且将patch拉长,方便下一步的全连接层
# 还有一种方法是采用窗口为16*16,stride 16的卷积核提取每个patch,然后再flatten送入全连接层。
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim),
nn.LayerNorm(dim),
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Linear(dim, num_classes)
def forward(self, img):
# 1. [1, 3, 256, 256] 输入img
x = self.to_patch_embedding(img)
# 2. [1, 64, 1024] patch embd
b, n, _ = x.shape
# 3. [1, 1, 1024] cls_tokens
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
# 4. [1, 65, 1024] cat [cls_tokens, x]
x = torch.cat((cls_tokens, x), dim=1)
# 5. [1, 65, 1024] add [x] [pos_embedding]
x += self.pos_embedding[:, :(n + 1)]
# 6. [1, 65, 1024] dropout
x = self.dropout(x)
# 7. [1, 65, 1024] N * transformer
x = self.transformer(x)
# 8. [1,1024] cls_x output
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
# 9. [1,1024] cls_x output mean
x = self.to_latent(x)
# 10.[1,1024] nn.Identity()不改变输入和输出 占位层
return self.mlp_head(x)
# 11.[1,cls] mlp_cls_head
4 总结
multihead和我原有的理解偏差修正。
我以为的是QKV会有N块相同的copy(),每一份去做后续的linear等操作。
代码里是直接用linear将QKV分为一整个大块,用permute/rearrange的操作切成了N块,f(Q,K)之后再恢复成一整个大块,很强。
智能推荐
金蝶云星空组合表头显示的列太多(超过35列),如何取消该控制?_金蝶云星空组合表头显示的列太多,将取消组合表头的显示格式-程序员宅基地
文章浏览阅读998次。using Kingdee.BOS.ServiceHelper;using Kingdee.BOS.Util;using System.Collections.Generic;using System.Linq;using System.Text;using System.Threading.Tasks;using Kingdee.BOS.Core.Bill.PlugIn;using System.ComponentModel;namespace Kingdee.DH.Test{ _金蝶云星空组合表头显示的列太多,将取消组合表头的显示格式
Cocos2d-x 3(11)-程序员宅基地
文章浏览阅读663次,点赞8次,收藏15次。显示状态文本end– 注册脚本回调方法xhr:send() – 发送请求end– 测试Get的标签local itemGet = cc.MenuItemLabel:create(labelGet) – 菜单标签itemGet:registerScriptTapHandler(onMenuGetClicked) – 菜单点击事件menuRequest:addChild(itemGet) – 添加菜单项–Post。
nested exception is feign.RetryableException: Incomplete output stream executing POST http://-程序员宅基地
文章浏览阅读3.1k次,点赞7次,收藏9次。nested exception is feign.RetryableException: Incomplete output stream executing POST http://_incomplete output stream executing post
【密码登录】基于matlab GUI密码登录【含Matlab源码 2701期】-程序员宅基地
文章浏览阅读487次。密码登录完整的代码,方可运行;可提供运行操作视频!适合小白!
SitePoint Podcast#178:Web设计过程和创造力-程序员宅基地
文章浏览阅读179次。Episode 178 ofThe SitePoint Podcastis now available! This week our regular interview host Louis Simoneau (@rssaddict) interviews Giovanni Difeterici (@giodif) about his new book for SitePoint, The W..._podcast web
5个必须了解的Python AI库-程序员宅基地
文章浏览阅读586次,点赞8次,收藏15次。NumPy(Numerical Python)是Python编程语言的一个扩展库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。NumPy是科学计算中一个重要的库,被广泛应用于进行数值计算的各个科学领域,是许多高级数学运算和机器学习库的基础框架。NumPy提供了一个高性能的多维数组对象ndarray,及对这些数组执行的快速操作。这些数组的数据结构可以帮助Python处理大量数据,因此NumPy在大数据分析和深度学习中扮演着核心角色。
随便推点
pcie总线与cpci总线_PCIe技术专题——PCIe总线数据链路层-程序员宅基地
文章浏览阅读588次。1.数据链路层数据链路层的主要功能包括:· 接收来自处理层的报文,重新封装后交给物理层,或者把物理层接收到的报文界封装后交给处理层。· 为TLP报文产生LCRC 。· 通过ACK/NAK协议实现传输保证传输,并实现传输重试。· 流量控制(Flow Control)· 电源管理1.1 数据链路层的报文格式数据链路层会给接收到的处理层的报文增加一个序列号,并产生LCRC来保证报文的正确性,其格式如下:..._pcie sequence_num
嵌入式Linux开发的前世与今生——基本概述,2024年最新【原理+实战+视频+源码】-程序员宅基地
文章浏览阅读679次,点赞5次,收藏6次。在不同应用领域中,嵌入式系统的执行装置一般是不同的,应该根据具体的应用场合和系统所要求实现的功能选择不同的设备和执行装置。是一段嵌入式目标代码中的程序,系统复位后首先执行,相当于用户的主程序,用户的其他应用程序都建立在OS之上;是一个标准的内核,它将CPU时钟、中断、I/O、定时器等资源都封装起来,留给用户的是一个标准的API函数接口。文件的元数据,也就是文件的相关信息,和文件本身是两个不同 的概念。它包含的是诸如文件的大小、拥有者、创建时间、磁盘位置等和文件相关的信息。总之,“一切皆文件”。
计算机视觉论文-2021-07-19_a survey on deep domain adaptation and tiny object-程序员宅基地
文章浏览阅读845次。本专栏是计算机视觉方向论文收集积累,时间:2021年7月19日,来源:paper digest欢迎关注原创公众号【计算机视觉联盟】,回复【西瓜书手推笔记】可获取我的机器学习纯手推笔记!直达笔记地址:机器学习手推笔记(GitHub地址)1, TITLE:Optical Inspection of The Silicon Micro-strip Sensors for The CBM Experiment Employing Artificial IntelligenceAUTHO..._a survey on deep domain adaptation and tiny object detection challenges, tec
JAVA毕业设计个人财务管理系统计算机源码+lw文档+系统+调试部署+数据库-程序员宅基地
文章浏览阅读384次。JAVA毕业设计个人财务管理系统计算机源码+lw文档+系统+调试部署+数据库。前端技术:Layui、HTML、CSS、JS、JQuery等技术。JSP超市进销存系统的设计与实现sqlserver。ssm攀枝花市房屋租售信息管理平台的设计与实现。ssm基于个人阅读习惯的个性化推荐系统研究。ssm基于SSM框架的学习资料校内共享平台。ssm基于javaweb的家庭财务管理系统。
根据特征矩阵进行聚合_矩阵运算实现消息聚合和传递-程序员宅基地
文章浏览阅读377次。N:边数, V:节点数, s:节点的特征维度目的,将节点i的所有相邻节点的特征求和聚集起来,作为i的特征表示 def forward(self, H, X_node): # H : (N, s) -> (V, s) # X_node : (N, ) mask = torch.stack([X_node] * self.V, 0) # (V, N) mask = mask.float() - torch.unsq..._矩阵运算实现消息聚合和传递
freemarker模板引擎-程序员宅基地
文章浏览阅读5.3k次。freemarker的简单使用_freemarker模板引擎