OPENAI-Baeslines-详解(三)-DDPG中文_ddpg保留的参数文件是-程序员宅基地
技术标签: baseline
Zee带你看代码系列
学习强化学习,码代码的能力必须要出众,要快速入门强化学习 搞清楚其中真正的原理,读源码是一个最简单的最直接的方式。最近创建了一系列该类型文章,希望对大家有多帮助。
传送门
另外,我会将所有的文章及所做的一些简单项目,放在我的个人网页上。
水平有限,可能有理解不到位的地方,希望大家主动沟通交流。
邮箱:[email protected]
Thanks for reading, and enjoy yourself。
DDPG
DDPG 深度确定性策略梯度下降算法。论文链接。采用了Actor-Critic 架构,可以有效的处理连续域的问题。
同时,其actor的确定性动作输出,提高了采样的有效性。
Actor-Critic and DPG
强化学习算法的主要目标是去学习一个策略,来指导agent与环境交互从而得到更好的收益。策略 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s)是以 θ \theta θ为参数的概率分布,代表不同状态下所采用的动作的概率分布。在学习的过程中不断的改变该函数的参数 θ \theta θ,从而改变应对环境的策略,以得到更好的奖励。当策略固定时,其所遍历的状态动作概率可以表示为
p θ ( s 1 , a 1 , … , s T , a T ) ⎵ p θ ( τ ) = p ( s 1 ) ∏ t = 1 T π θ ( a t ∣ s t ) p ( s t + 1 ∣ s t , a t ) \underbrace {
{p_\theta }\left( {
{
{\bf{s}}_1},{
{\bf{a}}_1}, \ldots ,{
{\bf{s}}_T},{
{\bf{a}}_T}} \right)}_{
{p_\theta }(\tau )} = p\left( {
{
{\bf{s}}_1}} \right)\prod\limits_{t = 1}^T {
{\pi _\theta }} \left( {
{
{\bf{a}}_t}|{
{\bf{s}}_t}} \right)p\left( {
{
{\bf{s}}_{t + 1}}|{
{\bf{s}}_t},{
{\bf{a}}_t}} \right) pθ(τ)
pθ(s1,a1,…,sT,aT)=p(s1)t=1∏Tπθ(at∣st)p(st+1∣st,at)
对单个状态而言,其到达概率为:
ρ π ( s ′ ) = ∫ S ∑ t = 1 ∞ γ t − 1 p 1 ( s ) p ( s → s ′ , t , π ) d s \rho^{\pi}(s')=\int_{\mathcal{S}} \sum_{t=1}^{\infty} \gamma^{t-1} p_{1}(s) p\left(s \rightarrow s^{\prime}, t, \pi\right) \mathrm{d} s ρπ(s′)=∫St=1∑∞γt−1p1(s)p(s→s′,t,π)ds
那么在策略 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s)下得到的期望收益可以表示为:
J ( π θ ) = ∫ S ρ π ( s ) ∫ A π θ ( s , a ) r ( s , a ) d a d s = E s ∼ ρ π , a ∼ π θ [ r ( s , a ) ] \begin{aligned} J\left(\pi_{\theta}\right) &=\int_{\mathcal{S}} \rho^{\pi}(s) \int_{\mathcal{A}} \pi_{\theta}(s, a) r(s, a) \mathrm{d} a \mathrm{d} s \\ &=\mathbb{E}_{s \sim \rho^{\pi}, a \sim \pi_{\theta}}[r(s, a)] \end{aligned} J(πθ)=∫Sρπ(s)∫Aπθ(s,a)r(s,a)dads=Es∼ρπ,a∼πθ[r(s,a)]
实际上 DDPG是DPG算法利用深度神经网络去逼进 策略 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s)和期望 Q Q Q。 Q Q Q函数的更新 需要与DQN类似:
Q ∗ ( s , a ) = Q ( s , a ) + α ( r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ) Q^{*}(s, a)=Q(s, a)+\alpha\left(r+\gamma \max _{a^{\prime}} Q\left(s^{\prime}, a^{\prime}\right)-Q(s, a)\right) Q∗(s,a)=Q(s,a)+α(r+γa′maxQ(s′,a′)−Q(s,a))
所以 Q Q Q函数更新的loss可以表示为:
L ( θ ) = E [ ( r + γ max a ′ Q ( s ′ , a ′ ; θ ) − Q ( s , a ; θ ) ) 2 ] L(\theta)=E\left[\left(r+\gamma \max _{a^{\prime}} Q\left(s^{\prime}, a^{\prime} ; \theta\right)-Q(s, a ; \theta)\right)^{2}\right] L(θ)=E[(r+γa′maxQ(s′,a′;θ)−Q(s,a;θ))2]
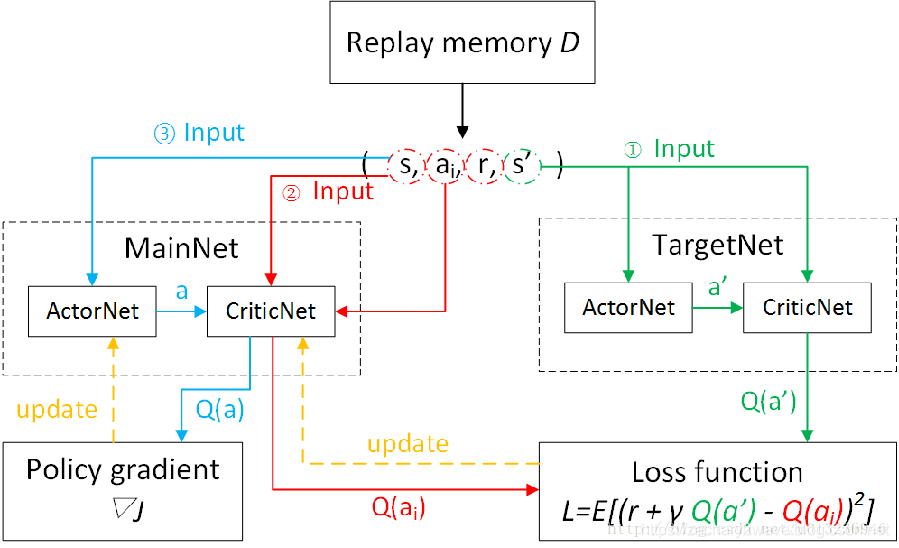
这样我们需要2组神经网络,其中一组 用来生成现在的状态S和动作A 另一组 用于生成 未来 Q Q Q函数估值 Q ( s ′ , a ′ ; θ ) Q\left(s^{\prime}, a^{\prime} ; \theta\right) Q(s′,a′;θ) 一组用于更新当前 Q ( s , a ; θ ) Q(s, a ; \theta) Q(s,a;θ)网络。
这个图盗的 ,但是原图在哪 我忘记了。
调用DDPG
根据OPENAI-Baeslines-详解(一)中,需要在learning中传入的DDPG的参数。
在DDPG进行学习的时候,分为多个epoch。
每个epoch 中 有进行 多个cycles ,每个cycles ,进行rollout次采样 、train_steps次训练和eval_steps次评估。
total_step = epochs * epoch_cycles* rollout
总步数= 总回合数 * 每个回合的循环运行次数 * 每个回合与环境交互的次数。
一个回合 不等于 一个episode 。
由于可以使用多个环境并行采样,所以 在一个cycle中 多个环境同时采样,每个环境都采样rollout次,无论这个环境是否done。
有可能这个环境已经提前done了 ,他也要继续采样,到rollout次结束。
训练步数和 评估步数是不算在其中的
- 必备参数
network, env,
seed=None,
# 总步数 和总回合数 只能存在一个
# 若两个都不存在,那么epoch为500
total_timesteps=None, # 总步数
nb_epochs=None, # 总回合数
nb_epoch_cycles=20, # 每个回合的循环运行次数
nb_rollout_steps=100, # 每个回合与环境交互的次数
nb_train_steps=50, # 每个回合训练次数
nb_eval_steps=100, # 每个回合的评估次数
eval_env=None, # 在每个回合训练完成之后,开始测试环境的步数。
render=False, # 是否显示交互
render_eval=False,
noise_type='adaptive-param_0.2',
- 超参数
gamma=0.99,
critic_l2_reg=1e-2, # critic正则化约束
actor_lr=1e-4, # actor 学习率
critic_lr=1e-3, # critic 学习率
tau=0.01, # 软切换 的参数
**network_kwarg # 网络参数
- 技巧参数参数
reward_scale=1.0, # 奖励的剪裁
normalize_returns=False, #
normalize_observations=True, # 是否对噪声归一化
popart=False, # 自适应Q值剪裁
clip_norm=None, # 将输出的模裁剪到一定范围内
#如果输出的为t 那么操作为t * clip_norm / l2norm(t)
batch_size=64, # per MPI worker
param_noise_adaption_interval=50,3
观察baseline中的输出
再运行程序的最后会得到progress.csv 输出的结果分为三个方面:
-
样本的输出
- ‘ret_rms_mean’,‘ret_rms_std’
- ‘obs_rms_mean’,‘obs_rms_std’ # 固定样本的观察的 均值 和 方差
- ‘reference_Q_mean’,‘reference_Q_std’
固定样本的Q值的 均值 和 方差 由样本的动作和状态 经由 critic 直接进行计算。 - ‘reference_actor_Q_mean’,‘reference_actor_Q_std’
固定样本的Q值 的 均值 和 方差 由样本状态 经由actor 输出动作 然后 给critic 进行计算。 - ‘reference_action_mean’ ‘reference_action_std’
动作均值和方差 - ‘reference_perturbed_action_mean’ ‘reference_perturbed_action_std’
加入噪声之后的动作均值和方差
-
本次epoch 的样本的输出
- ‘rollout/return’ # 从训练开始到现在的奖励均值
- ‘rollout/return_std’ # 从训练开始到现在的奖励方差
- ‘rollout/return_history’ # 100步 奖励均值
- ‘rollout/return_history_std’ # 100步 奖励方差
- ‘rollout/episode_steps’ # 从训练开始到现在的 每个episode 的步数。
- ‘rollout/actions_mean’ # 从训练开始到现在的动作平均
- ‘rollout/Q_mean’ # 从训练开始到现在的Q值平均
-
总共的
-
‘train/loss_actor’ # 本epoch 的actor的loss
-
‘train/loss_critic’ # 本epoch 的critic的loss
-
‘train/param_noise_distance’ # 本epoch 的actor的loss
-
‘total/duration’ # 总共持续的时间
-
‘total/steps_per_second’ # 每一步所花的时间
-
‘total/episodes’ # 总共完成的回合数
-
‘rollout/episodes’
一个epoch完成的回合数 episodes(这边有一个小bug,弟124行的 epoch_episodes = 0 应该在for循环下面)
-
‘rollout/actions_std’ # 动作平均
-
Baseline 中的DDPG
DDPG文件夹下包含以下5个文件:
- ddpg 主要程序 主要是 runner
- ddpg—learner DDPG算法核心 主要是生成agent
- memory 记忆库
- models 神经网络
- noise 增加噪声
DDPG 主程序
初始化
建立网络 63~65行
memory = Memory(limit=int(1e6), action_shape=env.action_space.shape, observation_shape=env.observation_space.shape) # 创建记忆库
critic = Critic(network=network, **network_kwargs) # critic 网络
actor = Actor(nb_actions, network=network, **network_kwargs) # actor 网络
67~84行 创建noise模型 ,noise 主要作用是用于增大探索
89行 调用ddpg—learner 创建agent 并开始循环与环境交互。
这里可以同时对多个环境 进行探索。
每个循环 有 epoch 、cycle、
每个epoch 需要有多个cycle 每个 cycle 中 rollout_step 次与环境交互 train_step 次进行训练。
for epoch in range(nb_epochs):
for cycle in range(nb_epoch_cycles):
与环境交换阶段
# reset环境
if nenvs > 1:
agent.reset()
for t_rollout in range(nb_rollout_steps):
# 输出动作
action, q, _, _ = agent.step(obs, apply_noise=True, compute_Q=True)
# 动作都是归一化在-1到1之间
new_obs, r, done, info = env.step(max_action * action)
t += 1
if rank == 0 and render:
env.render()
episode_reward += r
episode_step += 1
# 存进memory
epoch_actions.append(action)
epoch_qs.append(q)
agent.store_transition(obs, action, r, new_obs, done)
# 新旧 状态更新
obs = new_obs
for d in range(len(done)): # 对每一个agent进行reset
if done[d]:
if nenvs == 1:
agent.reset()
训练阶段
for t_train in range(nb_train_steps):
# 噪声更新
if memory.nb_entries >= batch_size and t_train % param_noise_adaption_interval == 0:
distance = agent.adapt_param_noise()
epoch_adaptive_distances.append(distance)
# agent 训练
cl, al = agent.train()
##### ddpg—learner
该类下,主要包含了各种DDPG中所需要包含的操作,包括利用状态值的actor 和critic 的 前向传播
、保存数据到经验池、从经验池提取数据 进行 后向传播训练、噪声的增加以及初始化等工作。
1、创建target—net、及其更新函数
创建target—network 120-126行
target_actor = copy(actor)
target_actor.name = 'target_actor'
self.target_actor = target_actor
target_critic = copy(critic)
target_critic.name = 'target_critic'
self.target_critic = target_critic
创建 target—net的更新
# 先创建单个网络函数 36行定义的函数
def get_target_updates(vars, target_vars, tau)
# 返回的是两组操作op,一组是硬更新 一组是软更新。
# 每组更新都是一个对每一个参数 进行 更新。
return tf.group(*init_updates), tf.group(*soft_updates)
# 2个网络的更新函数 149行 class 中定义的函数
def setup_target_network_updates(self)
可以得到self.target_init_updates self.target_soft_updates
2、actor 和critic 的 前向传播
128行 首先需要创建loss 以及 创建actor 与 critic之间的链接
# actor
self.actor_tf = actor(normalized_obs0)
# critic 输入中的动作位置 为placeholder
self.normalized_critic_tf = critic(normalized_obs0, self.actions)
self.critic_tf = denormalize(tf.clip_by_value(self.normalized_critic_tf,self.return_range[0], self.return_range[1]), self.ret_rms)
# critic 输入中的动作位置 为actor的输出
self.normalized_critic_with_actor_tf = critic(normalized_obs0, self.actor_tf, reuse=True)
self.critic_with_actor_tf =denormalize(tf.clip_by_value(self.normalized_critic_with_actor_tf, self.return_range[0], self.return_range[1]), self.ret_rms)
# target Q值计算
Q_obs1 = denormalize(target_critic(normalized_obs1, target_actor(normalized_obs1)), self.ret_rms)
self.target_Q = self.rewards + (1. - self.terminals1) * gamma * Q_obs1
259行 step 函数 是在每次交互过程中 ,根据当前状态 前向传输。根据当前状态 求取动作和Q值
def step(self, obs, apply_noise=True, compute_Q=True):
feed_dict = {
self.obs0: U.adjust_shape(self.obs0, [obs])}# 送入数据
# 利用网络计算动作和Q值
action, q = self.sess.run([actor_tf, self.critic_with_actor_tf], feed_dict=feed_dict)
# 之后是为了增加噪声
noise = self.action_noise()
action += noise
action = np.clip(action, self.action_range[0], self.action_range[1])
3、反向传播
172 行 创建actor 网络训练
∇ θ J ( π θ ) \nabla_{\theta} J\left(\pi_{\theta}\right) ∇θJ(πθ)是 Q Q Q对actor的参数求导数。
采用的是 利用action 的输出作为输入的critic的输出
因为经验回放 更新actor的时候是对当前actor的参数求导,所以必须对当前actor输入state 然后求得action 再将此时的action和state 送入critic ,并最后得到Q值 来更新 actor 参数。
def setup_actor_optimizer(self):
self.actor_loss = -tf.reduce_mean(self.critic_with_actor_tf)# Q值
self.actor_grads = U.flatgrad(self.actor_loss, self.actor.trainable_vars, clip_norm=self.clip_norm) # 计算梯度
self.actor_optimizer = MpiAdam(var_list=self.actor.trainable_vars,beta1=0.9, beta2=0.999, epsilon=1e-08)
183 行 创建critic 网络训练
更新critic的时候,从经验库中取得的数据,其reward 是当时state-action所得到的,而此时critic网络参数经由多次训练之后,发生了非常大的变化, 所以必须用当前的网络在计算一遍Q值然后,利用当前target 网络Q值和 当前 main 网络Q值 加上当时的reward 重新计算。
def setup_critic_optimizer(self):
normalized_critic_target_tf = tf.clip_by_value(normalize(self.critic_target, self.ret_rms), self.return_range[0], self.return_range[1])
self.critic_loss = tf.reduce_mean(tf.square(self.normalized_critic_tf - normalized_critic_target_tf))
# 187-196 在这里会对critic的loss 增加 l2 约束。
self.critic_grads = U.flatgrad(self.critic_loss, self.critic.trainable_vars, clip_norm=self.clip_norm) # 计算梯度
self.critic_optimizer = MpiAdam(var_list=self.critic.trainable_vars,
beta1=0.9, beta2=0.999, epsilon=1e-08) # 反向训练
289 行 train
def train(self):
# 经验池随机采样
batch = self.memory.sample(batch_size=self.batch_size)
ops = [self.actor_grads, self.actor_loss, self.critic_grads, self.critic_loss]
# 根据采样数据重新计算Q值等。
actor_grads, actor_loss, critic_grads, critic_loss = self.sess.run(ops, feed_dict={
self.obs0: batch['obs0'],
self.actions: batch['actions'],
self.critic_target: target_Q,
})
# 训练328 行
self.actor_optimizer.update(actor_grads, stepsize=self.actor_lr)
self.critic_optimizer.update(critic_grads, stepsize=self.critic_lr)
4、噪声
噪声主要是为了增加action的探索作用。噪声主要有两种 一种是 静态参数的 一种是 动态参数(未使用)
噪声的生成主要是通过首先对actor 进行 copy (155行函数)
def setup_param_noise(self, normalized_obs0):
param_noise_actor = copy(self.actor)
self.perturbed_actor_tf = param_noise_actor(normalized_obs0)
然后对copy后的actor的输出增加噪声
#50 行
def get_perturbed_actor_updates(actor, perturbed_actor, param_noise_stddev):
# 增加均值为零 方差为param_noise_stddev的 高斯噪声
updates.append(tf.assign(perturbed_var, var + tf.random_normal(tf.shape(var), mean=0., stddev=param_noise_stddev)))
执行增加噪声, 在step函数中直接选择
#259行
if self.param_noise is not None and apply_noise:
actor_tf = self.perturbed_actor_tf # 注意 这里只选择了参数固定的噪声。
else:
actor_tf = self.actor_tf
其他函数 def reset(self):# 初始化噪声
5、功能函数
# 初始化 将所有网络初始化、优化器初始化、硬更新一次target网络
def initialize(self, sess):
# 软更新target_net
def update_target_net(self):
# 通过从 数据库中采样数据并得到所有结果的函数
def setup_stats(self):
def get_stats(self):
智能推荐
强大的USB协议分析工具_lecroy usb advisor bus and protocol analyzer-程序员宅基地
文章浏览阅读1.2w次,点赞14次,收藏72次。2020年最后一天了,感谢大家一年来对我文章的支持,有你们的支持就是我强大的动力。今天来给大家介绍一个USB 协议分析软件LeCroy USB Advisor,软件安装包下载连接如下:链接:https://pan.baidu.com/s/12qBCOjuy4i8kr1MHjBrfYQ提取码:2rpx这个软件对于USB协议学习有很大帮助,下面就给大家介绍这个软件的强大作用:(1)软件主界面(2)USB传输、事务、包协议显示(序号和具体域的细节)(3)协议可折叠(4)每个具体包可查看差分_lecroy usb advisor bus and protocol analyzer
[C/C++]_[使用libiconv库转换字符编码]_c++ 使用libiconv 转越南语-程序员宅基地
文章浏览阅读6.8k次。场景:1.在windows上我们可以通过WideCharToMultiByte和MultiByteToWideChar直接转换或间接转换编码,但是在linux或mac上却没有那么方便的系统api了,这时候可以使用libiconv库来进行转码,质量还是很高的。2.以下我们把utf8编码字符串转换为utf16-le(小端序)编码。#include #include #inclu_c++ 使用libiconv 转越南语
matlab实现潮流计算可视化,基于MATLAB的复杂潮流计算(喜欢就下吧)最新版-程序员宅基地
文章浏览阅读759次。随着农网改造的进行其目是校验系统是否能安全运行,即是否有过负荷元件或电压过低母线等。原则上讲潮流计算 matlab,静态安全分析也可用潮流计算来代替。但是一般静态安全分析需要校验状态数非常多,用严格潮流计算来分析这些状态往往计算量过大,因此不得不寻求一些特殊算法以满足要求。利用电子数字计算机进行电力系统潮流计算从世纪年代中期就己开始,此后,潮流计算曾采用了各种不同方法,这些方法发展主要是围绕着对潮..._潮流解可视化matlab
【Android】轮播图图片的本地保存及读取_如何保存轮播图-程序员宅基地
文章浏览阅读2k次,点赞2次,收藏4次。一、轮播图控件及图片加载对于Android端的轮播图控件,我这边选用的是banner库//轮播图compile 'com.youth.banner:banner:1.4.9'//Glidecompile 'com.github.bumptech.glide:glide:3.8.0'二、banner初始化1.引入banner布局 <com.youth...._如何保存轮播图
微信java版本之扫码关注公众号(带参数的临时二维码)_临时二维码 java 带字符串的 参数-程序员宅基地
文章浏览阅读2.1w次。1.生成带参数的二维码接口介绍为了满足用户渠道推广分析的需要,公众平台提供了生成带参数二维码的接口。使用该接口可以获得多个带不同场景值的二维码,用户扫描后,公众号可以接收到事件推送。目前有2种类型的二维码,分别是临时二维码和永久二维码,前者有过期时间,最大为1800秒,但能够生成较多数量,后者无过期时间,数量较少(目前参数只支持1--100000)。两种二维码分别适用于帐号绑定、用_临时二维码 java 带字符串的 参数
php截取前10个字,php中如何截取前几个字符的方法-程序员宅基地
文章浏览阅读2k次。php中如何截取前几个字符的方法发布时间:2020-08-13 09:40:51来源:亿速云阅读:106作者:小新php中如何截取前几个字符的方法?这个问题可能是我们日常学习或工作经常见到的。希望通过这个问题能让你收获颇深。下面是小编给大家带来的参考内容,让我们一起来看看吧!php截取前几个字符的方法:可以利用substr()函数来截取。substr()函数用于返回字符串的提取部分,如果失败则返回..._php取前十个字符
随便推点
vue 移动端h5项目使用 vue-luck-draw 插件实现大转盘抽奖-程序员宅基地
文章浏览阅读5.4k次。文档地址: https://100px.net/docs/wheel/blocks.html实现效果如下:使用:1.安装插件:npm install vue-luck-draw。2.引入插件:在 main.js 文件中全局加载插件;或者在组件中按需引入插件。// 完整加载import LuckDraw from 'vue-luck-draw'Vue.use(LuckDraw)// 按需引入import { LuckyWheel, LuckyGrid } from 'vue-luck-d_vue-luck-draw
计算机毕业设计 基于HTML+CSS+JavaScript 大气的甜品奶茶美食餐饮文化网页设计与实现23页面_基于html的餐饮企业网站的设计与实现论文-程序员宅基地
文章浏览阅读132次。静态网站的编写主要是用HTML DIV+CSS JS等来完成页面的排版设计,常用的网页设计软件有Dreamweaver、EditPlus、HBuilderX、VScode 、Webstorm、Animate等等,用的最多的还是DW,当然不同软件写出的前端Html5代码都是一致的,本网页适合修改成为各种类型的产品展示网页,比如美食、旅游、摄影、电影、音乐等等多种主题,希望对大家有所帮助。 精彩专栏推荐 【作者主页——获取更多优质源码】 【_基于html的餐饮企业网站的设计与实现论文
SpringCloudGateway配置https_springcloud gateway实现ssl认证-程序员宅基地
文章浏览阅读4.9k次。一.生成证书证书本应是花钱买,客户端才能通过根CA仓库识别证书。如果是自定义生成的证书,客户端访问时,会提示不安全的链接 是否继续访问,或者客户端可以将证书导入自己的本地CA仓库。生成证书可以通过 openssl,或者jdk的工具keytool生成。使用openssl,参考:https://www.jianshu.com/p/0e9ee7ed6c1d ,先生成虚拟的CA,再生成证书,再用CA为证书签名使用keytool:keytool -genkeypair -alias ..._springcloud gateway实现ssl认证
MIDI效果器处理工具 - Blue Cat Audio PlugNScript v3.5.2 Win_blue cat软件-程序员宅基地
文章浏览阅读180次。Blue Cat 的 Plug’n Script 是一个音频和 MIDI 脚本插件和应用程序,可以通过编程来构建自定义效果或虚拟乐器,而无需退出您最喜欢的 DAW 软件。有了这个插件,你可以用很少的编程知识编写自己的插件。如果您不关心编程,Blue Cat 的 Plug’n Script 也可以用作带有现有脚本的常规多效果处理器,或者让其他人编写这个您多年来一直在寻找但在任何地方都找不到的非常特殊的实用程序。......_blue cat软件
oracle wm_concat 报 不存在的 LOB 值_不存在的lob值oracle11-程序员宅基地
文章浏览阅读837次。oracle 11g 使用wm_concat函数会变成clob类型,如果使用to_char后会报错 "不存在的 LOB 值"改为使用listagg(column,',')within group (order by column) 解决问题_不存在的lob值oracle11
WordArt Designer:基于用户驱动与大语言模型的艺术字生成_wordart designer:基于用户驱动与 #大语言模型 的 #艺术字 生成-程序员宅基地
文章浏览阅读3k次,点赞2次,收藏3次。本文介绍了一个基于用户驱动,依赖于大型语言模型(LLMs)的艺术字生成框架,WordArtDesigner。该系统包含四个关键模块:LLM引擎、SemTypo、Stlytypo和TextTypo模块。由gpt-3.5turbo驱动的LLM引擎可以解释用户输入,并为其他模块生成可操作的提示,从而将抽象概念转化为有形的设计。SemTypo模块使用语义概念优化字体设计,在艺术转换和可读性之间取得平衡。在SemTypo模块提供的语义布局的基础上,StyTypo模块辅助生成平滑、精细的图像。Tex_wordart designer:基于用户驱动与 #大语言模型 的 #艺术字 生成