深度学习之梯度下降与优化_基于梯度下降在深度学习中分析-程序员宅基地
参考
pytorch学习系列(4):常用优化算法_ch ur h的博客深度学习各类优化器详解(动量、NAG、adam、Adagrad、adadelta、RMSprop、adaMax、Nadam、AMSGrad)_恩泽君的博客-程序员宅基地pytorch学习系列(4):常用优化算法_ch ur h的博客-程序员宅基地
一、问题的提出
大多数机器学习或者深度学习算法都涉及某种形式的优化。 优化指的是改变 以最小化或最大化某个函数
的任务。 我们通常以最小化
指代大多数最优化问题。
我们把要最小化或最大化的函数称为目标函数或准则。 当我们对其进行最小化时,我们也把它称为代价函数、损失函数或误差函数。
下面,我们假设一个损失函数为

其中 ![]() 然后要使得最小化它。
然后要使得最小化它。
θ表示X映射成Y的权重,x表示一次特征。假设x0=1,上式就可以写成:

分别使用表示第J个样本。我们计算的目的是为了让计算的值无限接近真实值y,即代价函数可以采用LMS算法
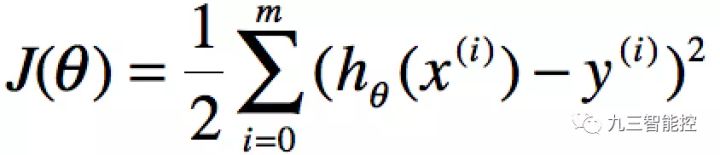
![]()
要获取J(θ)最小,即对J(θ)进行求导且为零:
总之,梯度下降是另一种优化的不错方式,比直接求导好很多。
二、梯度下降
梯度下降:我们知道曲面上方向导数的最大值的方向就代表了梯度的方向,因此我们在做梯度下降的时候,应该是沿着梯度的反方向进行权重的更新,可以有效的找到全局的最优解。这个的更新过程可以描述为

[表示的是步长或者说是学习率(learning rate)]
单个特征的迭代如下:
![]()
三、批量梯度下降
在每次更新时用所有样本,在梯度下降中,对于 的更新,所有的样本都有贡献,也就是参与调整,即:

当上式收敛时则退出迭代,何为收敛,即前后两次迭代的值不再发生变化了。一般情况下,会设置一个具体的参数,当前后两次迭代差值小于该参数时候结束迭代。
批梯度下降算法的步骤可以归纳为以下几步:
- 先确定向下一步的步伐大小,我们称为Learning rate ;
- 任意给定一个初始值:θ向量,一般为0向量;
- 确定一个向下的方向,并向下走预先规定的步伐,并更新θ向量;
- 当下降的高度小于某个定义的值,则停止下降;
四、随机梯度下降算法:
随机梯度下降算法每次迭代只是考虑让该样本点的J(θ)趋向最小,而不管其他的样本点,这样算法会很快,但是收敛的过程会比较曲折,整体效果上,大多数时候它只能接近局部最优解,而无法真正达到局部最优解。所以适合用于较大训练集的case。

即learning rate,决定的下降步伐,如果太小,则找到函数最小值的速度就很慢,如果太大,则可能会出现overshoot the minimum的现象;
- 当存在多个局部最优时,初始点不同,获得的最小值也不同,因此梯度下降求得的只是局部最小值;
- 越接近最小值时,下降速度越慢;
- 计算批梯度下降算法时候,计算每一个θ值都需要遍历计算所有样本,当数据量的时候这是比较费时的计算。
随机梯度下降法突出的是随机,其本质最主要的是依赖大数定理和minibatch数据随机性对于真实梯度的经验性估计。
更准确的说是切比雪夫不等式的衍生:切比雪夫不等式显示了随机变量的“几乎所有”值都会“接近”平均。切比雪夫不等式,对任何分布形状的数据都适用:

这里就是利用随机变量去估计实际分布下的梯度,minibatch越大,经验性梯度越接近真实梯度。
随机梯度下降(SGD)算法的收敛性分析(入门版-1) - 知乎
五、mini-batch梯度下降:
在每次更新时用b个样本,其实批量的梯度下降就是一种折中的方法,他用了一些小样本来近似全部的,其本质就是我1个指不定不太准,那我用个30个50个样本那比随机的要准不少了吧,而且批量的话还是非常可以反映样本的一个分布情况的。在深度学习中,这种方法用的是最多的,因为这个方法收敛也不会很慢,收敛的局部最优也是更多的可以接受!

(i+=10 应为i+=b)
总的来说,随机梯度下降一般来说效率高,收敛到的路线曲折,但一般得到的解是我们能够接受的,在深度学习中,用的比较多的是mini-batch梯度下降。
下面是loss的梯度图,三条线是三种梯度下降方法每下降一次的路线,蓝色是Batch Gradient Descent,紫色是Stochastic Gradient Descent,绿色是Mini-batch Gradient Descent。

进阶理解:
相较于GD,SGD能更有效的利用信息,特别是信息比较冗余的时候。举个例子,比如所有样本都需要向一个方向优化,GD优化一次需要对整个样本集迭代一次,而SGD只对一个样本优化就可以达到同样的效果。SGD相对于GD的另外一个优点是可以跳出局部最小值区域。
而mini-batch GD综合了两者的优点,既有了GD的向量化加速,还能像SGD更有效利用样本信息、可以跳出局部最小值区域的优点。另外,使用mini-batch,你还会发现不需要等待整个训练集被处理完就可以开始进行后续工作。
下面总结一下mini-batch的优点:
1.有向量化加速,加快了训练速度。
2.能有效利用样本信息,特别是信息比较冗余的时候。
3.有随机性,可以跳出局部最小值区域。
4.不需要等待整个训练集被处理完就可以开始进行后续工作。
下面是mini-batch的伪代码,中括号上标代表层数:

用法总结
首先,如果训练集较小,直接使用Batch Gradient Descent梯度下降法,样本集较小就没必要使用mini-batch梯度下降法,这里的少是说小于差不多2000个样本,这样比较适合使用Batch Gradient Descent梯度下降法。
样本数目较大的话,一般的mini-batch大小为64到512,考虑到电脑内存设置和使用的方式,如果mini-batch大小是2的次方,代码会运行地快一些。64到512的mini-batch比较常见。
六、梯度下降优化算法
对随机梯度下降法来说,可怕的不是局部最优点,而是山谷和鞍点两类地形。山谷顾名思义就是狭长的山间小道,左右两边是峭壁;鞍点的形状像是一个马鞍,一个方向上两头翘, 另一个方向上两头垂,而中心区域是一片近乎水平的平地。为什么随机梯度下降法最害怕遇上这两类地形呢?在山谷中,准确的梯度方向是沿山道向下,稍有偏离就会撞向山壁,而粗糙的梯度估计使得它在两山壁间来回反弹震荡,不能沿山道方向迅速下降,导致收敛不稳定和收敛速度慢。在鞍点处,随机梯度下降法会走入一片平坦之地(此时离最低点还很远,故也称plateau)。想象一下蒙着双眼只凭借脚底感觉坡度,如果坡度很明显,那么基本能估计出下山的大致方向;如果坡度不明显,则很可能走错方向。同样,在梯度近乎为零的区域,随机梯度下降法无法准确察觉出梯度的微小变化,结果就停滞下来。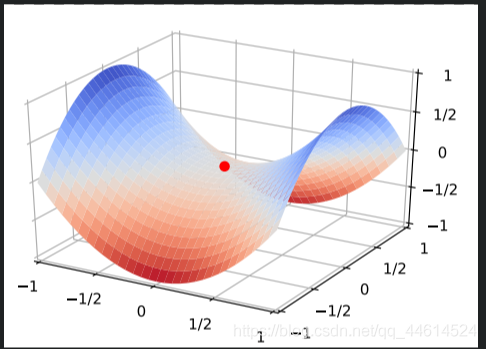
上图示例为鞍点
解决方案:动量(Momentum)方法、AdaGrad方法、Adam方法
分析:随机梯度下降本质上是采用迭代方式更新参数,每次迭代在当前位置的基础上,沿着某一方向迈一小步抵达下一位置,然后再下一位置重复上述步骤。随机梯度下降法的更新公式表示为:其中,当前估计的负梯度
表示步子的方向,学习速率 η ,控制步幅,改造的随机梯度下降法仍然基于这个更新公式。
6.1 动量(Momentum)方法 Gradient descent with Momentum
为了解决随机梯度下降法山谷震荡和鞍点停滞的问题,我们做一个简单的思维实验。想象一下纸团在山谷和鞍点处的运动轨迹,在山谷中纸团受重力作用沿山道滚下,两边是不规则的山壁,纸团不可避免地撞在山壁上,由于质量小受山壁弹力的干扰大,从一侧山壁反弹回来撞向另一侧山壁,结果来回震荡地滚下;如果当纸团来到鞍点的一片平坦之地时,还是由于质属小,速度很快减为零。纸团的情况和随机梯度下降法遇到的问题面直如出一辙。直观地,如果换成一个铁球,当沿着山谷滚下时,不容易受到途中旁力的干扰,轨迹会更稳更直;当来到鞍点中心处,在惯性作用下继续前行,从而有机会冲出这片平坦的陷阱,因此,有了动量方法,模型参数的迭代公式为:
具体来说,前进步伐,由两部分组成。一是学习速率 η乘以当前估计的梯度
;二是带衰减的前一次步伐
,这里,惯性就体现在对前一次步伐信息的重利用上。当前梯度就好比当前时刻受力产生的加速度,前一次步伐好比前一-时刻的速度,当前步伐好比当前时刻的速度。为了计算当前时刻的速度,应当考虑前一时刻速度和当前加速度共同作用 的结果,因此
直接依赖于
和
,而不仅仅是
。另外,衰减系数
扮演了阻力的作用。
由于刻画惯性的物理量是动量,这也是算法名字的由来。沿山谷滚下的铁球,会受到沿坡道向下的力和与左右山壁碰撞的弹力。向下的力稳定不变,产生的动量不断累积,速度越来越快;左右的弹力总是在不停切换,动量累积的结果是相互抵消,自然减弱了球的来回震荡。因此,与随机梯度下降法相比,动量方法的收敛速度更快,收敛曲线也更稳定,如下图示
在这里插入图片描述
因为mini-batch相比标准的梯度下降来说,更新参数更快,所以收敛过程会有浮动(loss下降曲线),使用动量梯度下降法可以减小该浮动,还能加速训练。
看下mini-batch GD with Momentum的公式:

越大,收敛过程越平滑,一般取值为0.8~0.999,0.9会是一个不错的选择。
基本的mini-batch SGD优化算法在深度学习取得很多不错的成绩。然而也存在一些问题需解决:
1. 选择恰当的初始学习率很困难。
2. 学习率调整策略受限于预先指定的调整规则。
3. 相同的学习率被应用于各个参数。
4. 高度非凸的误差函数的优化过程,如何避免陷入大量的局部次优解或鞍点。
6.2 自适应优化AdaGrad
针对简单的SGD及Momentum存在的问题,2011年John Duchi等发布了AdaGrad优化算法(Adaptive Gradient,自适应梯度),它能够对每个不同的参数调整不同的学习率,对频繁变化的参数以更小的步长进行更新,而稀疏的参数以更大的步长进行更新。
公式:
表示第t时间步的梯度(向量,包含各个参数对应的偏导数,
表示第i个参数t时刻偏导数)
表示第t时间步的梯度平方(向量,
由 各元素自己进行平方运算所得,即Element-wise)
与SGD的核心区别在于计算更新步长时,增加了分母:梯度平方累积和的平方根。此项能够累积各个参数 的历史梯度平方,采用“历史梯度平方和”来衡量不同参数的梯度的稀疏性,频繁更新的梯度,则累积的分母项逐渐偏大,那么更新的步长(stepsize)相对就会变小,而稀疏的梯度,则导致累积的分母项中对应值比较小,那么更新的步长则相对比较大。
分母中求和的形式实现了退火过程,这是很多优化技术中常见的策略,意味着随着时间的推移,学习速率越来越小。从而保证了算法的最终收敛
AdaGrad能够自动为不同参数适应不同的学习率(平方根的分母项相当于对学习率α进进行了自动调整,然后再乘以本次梯度),大多数的框架实现采用默认学习率α=0.01即可完成比较好的收敛。
优势:在数据分布稀疏的场景,能更好利用稀疏梯度的信息,比标准的SGD算法更有效地收敛。
缺点:主要缺陷来自分母项的对梯度平方不断累积,随之时间步地增加,分母项越来越大,最终导致学习率收缩到太小无法进行有效更新。
6.3 RMSProp root mean square prop
RMSProp是Geoffrey Hinton教授在教案中提到的算法,结合梯度平方的指数移动平均数来调节学习率的变化。能够在不稳定(Non-Stationary)的目标函数情况下进行很好地收敛。
Hinton教授讲述RMSProp算法的材料:
http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf
计算t时间步的梯度:
![]()
计算梯度平方的指数移动平均数(Exponential Moving Average),γ是遗忘因子(或称为指数衰减率),依据经验,默认设置为0.9。
指数移动平均(Exponential Moving Average)也叫权重移动平均(Weighted Moving Average),是一种给予近期数据更高权重的平均方法。参见指数移动平均(EMA)



梯度更新时候,与AdaGrad类似,只是更新的梯度平方的期望(指数移动均值),其中ε=10^-8,避免除数为0。默认学习率α=0.001。
![]()
优势:能够克服AdaGrad梯度急剧减小的问题,在很多应用中都展示出优秀的学习率自适应能力。尤其在不稳定(Non-Stationary)的目标函数下,比基本的SGD、Momentum、AdaGrad表现更良好。
RMSprop的算法,全称是root mean square prop算法,它也可以加速收敛,我们来看看它是如何运作的。

是一个很小的数,使后两个式子无论如何都不会除以一个接近于零的数,一般
![]()
原理:参数更新时 ![]() 的作用是使梯度大的参数不要更新地太猛。因为梯度dW 越大,
的作用是使梯度大的参数不要更新地太猛。因为梯度dW 越大, 就越大,而
![]() 就越小,参数更新的幅度就越小。
就越小,参数更新的幅度就越小。
总而言之,RMSprop使得梯度大的参数更新幅度不那么大,很大程度上缓解了梯度下降震荡的问题,如下图所示,蓝线代表普通梯度下降,绿线代表RMSprop。

为何不把Momentum和RMSprop结合在一起用呢?那就有了Adam。
6.4 Adam方法Adaptive Momentum Estimation
Adam方法将惯性保持和环境感知这两个优点集于一身。 一方面,Adam记录梯度的一阶矩(first moment),即过往梯度与当前梯度的平均,这体现了惯性保持;另一方面,Adam还记录梯度的二阶矩( sccond moment),即过往梯度平方与当前梯度平方的平均,这类似AdaGrad方法,体现了环境感知能力,为不同参数产生自适应的学习速率。一阶矩和二阶矩采用类似于滑动窗口内求平均的思想进行融合,即当前梯度和近一段时间内梯度的平均值,时间久远的梯度对当前平均值的贡献呈指数衰减。具体来说,一阶矩和二阶矩采用指数衰退平均( exponential decay average)技术,计算公式为
其中 β1 ,β2为衰减系数,是一阶矩,
是二阶矩。
它们的物理意义是,当 大且
大时,梯度大且稳定,这表明遇到一个明显的大坡,前进方向明确;当
趋于零且
大时,梯度不稳定,表明可能遇到一个峡谷,容易引起反弹震荡;当
大且
趋于零时,这种情况不可能出现;当
趋于零且
趋于零时,梯度趋于零,可能到达局部最低点,也可能走到一片坡度极缓的平地,此时要避免陷入平原( plateau)。另外,Adam方法还考虑了
在零初始值情况下的偏置矫正。具体来说,Adam的更新公式为
其中 β1 = 0.9 , β2 = 0.999
主要包含以下几个显著的优点:
- 实现简单,计算高效,对内存需求少
- 参数的更新不受梯度的伸缩变换影响
- 超参数具有很好的解释性,且通常无需调整或仅需很少的微调
- 更新的步长能够被限制在大致的范围内(初始学习率)
- 能自然地实现步长退火过程(自动调整学习率)
- 很适合应用于大规模的数据及参数的场景
- 适用于不稳定目标函数
- 适用于梯度稀疏或梯度存在很大噪声的问题
综合Adam在很多情况下算作默认工作性能比较优秀的优化器。
6.4.1 Adam实现原理
算法伪代码:

6.4.2 Adam更新规则
计算t时间步的梯度:

首先,计算梯度的指数移动平均数,m0 初始化为0。
类似于Momentum算法,综合考虑之前时间步的梯度动量。
β1 系数为指数衰减率,控制权重分配(动量与当前梯度),通常取接近于1的值。
默认为0.9

下图简单展示出时间步1~20时,各个时间步的梯度随着时间的累积占比情况。

其次,计算梯度平方的指数移动平均数,v0初始化为0。
β2 系数为指数衰减率,控制之前的梯度平方的影响情况。
类似于RMSProp算法,对梯度平方进行加权均值。
默认为0.999

第三,由于m0初始化为0,会导致mt偏向于0,尤其在训练初期阶段。
所以,此处需要对梯度均值mt进行偏差纠正,降低偏差对训练初期的影响。

第四,与m0 类似,因为v0初始化为0导致训练初始阶段vt 偏向0,对其进行纠正。

第五,更新参数,初始的学习率α乘以梯度均值 与梯度方差 的平方根之比。
其中默认学习率α=0.001
ε=10^-8,避免除数变为0。
由表达式可以看出,对更新的步长计算,能够从梯度均值及梯度平方两个角度进行自适应地调节,而不是直接由当前梯度决定。

6.4.3 Adam代码实现
算法思路很清晰,实现比较直观:
class Adam:
def __init__(self, loss, weights, lr=0.001, beta1=0.9, beta2=0.999, epislon=1e-8):
self.loss = loss
self.theta = weights
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.epislon = epislon
self.get_gradient = grad(loss)
self.m = 0
self.v = 0
self.t = 0
def minimize_raw(self):
self.t += 1
g = self.get_gradient(self.theta)
self.m = self.beta1 * self.m + (1 - self.beta1) * g
self.v = self.beta2 * self.v + (1 - self.beta2) * (g * g)
self.m_hat = self.m / (1 - self.beta1 ** self.t)
self.v_hat = self.v / (1 - self.beta2 ** self.t)
self.theta -= self.lr * self.m_hat / (self.v_hat ** 0.5 + self.epislon)
def minimize(self):
self.t += 1
g = self.get_gradient(self.theta)
lr = self.lr * (1 - self.beta2 ** self.t) ** 0.5 / (1 - self.beta1 ** self.t)
self.m = self.beta1 * self.m + (1 - self.beta1) * g
self.v = self.beta2 * self.v + (1 - self.beta2) * (g * g)
self.theta -= lr * self.m / (self.v ** 0.5 + self.epislon)6.4.4 Adam可视化
下面以Beale function为例,简单演示Adam优化器的优化路径。
https://en.wikipedia.org/wiki/Test_functions_for_optimization

6.4.5 Adam缺陷及改进
虽然Adam算法目前成为主流的优化算法,不过在很多领域里(如计算机视觉的对象识别、NLP中的机器翻译)的最佳成果仍然是使用带动量(Momentum)的SGD来获取到的。Wilson 等人的论文结果显示,在对象识别、字符级别建模、语法成分分析等方面,自适应学习率方法(包括AdaGrad、AdaDelta、RMSProp、Adam等)通常比Momentum算法效果更差。
针对Adam等自适应学习率方法的问题,主要两个方面的改进:
1、解耦权重衰减

在每次更新梯度时,同时对其进行衰减(衰减系数w略小于1),避免产生过大的参数。
在Adam优化过程中,增加参数权重衰减项。解耦学习率和权重衰减两个超参数,能单独调试优化两个参数。
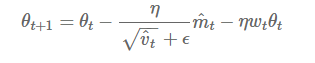
2、修正指数移动均值
最近的几篇论文显示较低的β_2(如0.99或0.9)能够获得比默认值0.999更佳的结果,暗示出指数移动均值本身可能也包含了缺陷。例如在训练过程中,某个mini-batch出现比较大信息量的梯度信息,但由于这类mini-batch出现频次很少,而指数移动均值会减弱他们的作用(因为当前梯度权重 及当前梯度的平方的权重 ,权重都比较小),导致在这种场景下收敛比较差。

论文作者提出Adam的变形算法AMSGrad。
AMSGrad 使用最大的 来更新梯度,而不像Adam算法中采用历史 的指数移动均值来实现。作者在小批量数据集及CIFAR-10上观察到比Adam更佳的效果。
6.5、NAG(Nesterov accelerated gradient)
回顾动量的方法,我们发现参数更新是基于两部分组成,一部分为当前位置的梯度,另一部分为前面累计下来的梯度值,参数更新方向就是将两者矢量相加的方向,但是我们会发现一个问题,当刚好下降到山谷附近时,如果这个时候继续以这样的方式更新参数,我们会有一个较大的幅度越过山谷,即:模型遇到山谷不会自动减弱更新的幅度。NAG针对上述问题对动量方法进行了改进,其表达式如下:
其中,表示t时刻积攒的加速度;α表示动力的大小;
表示学习率;
表示t时刻的模型参数,
表示代价函数关于
的梯度。
- Nesterov动量梯度的计算在模型参数施加当前速度之后,因此可以理解为往标准动量中添加了一个校正因子。
- 理解策略:在Momentun中小球会盲目地跟从下坡的梯度,容易发生错误。所以需要一个更聪明的小球,能提前知道它要去哪里,还要知道走到坡底的时候速度慢下来而不是又冲上另一个坡。计算Wt−αvt−1
可以表示小球下一个位置大概在哪里。从而可以提前知道下一个位置的梯度,然后使用到当前位置来更新参数。
- 在凸批量梯度的情况下,Nesterov动量将额外误差收敛率从O(1/k)(k步后)改进到O(1/
)。然而,在随机梯度情况下,Nesterov动量对收敛率的作用却不是很大。
它是利用当前位置处先前的梯度值先做一个参数更新,然后在更新后的位置再求梯度,将此部分梯度然后跟之前累积下来的梯度值矢量相加,简单的说就是先根据之前累积的梯度方向模拟下一步参数更新后的值,然后将模拟后的位置处梯度替换动量方法中的当前位置梯度。为什么解决了之前说的那个问题呢?因为现在有一个预测后一步位置梯度的步骤,所以当在山谷附近时,预测到会跨过山谷时,该项梯度就会对之前梯度有个修正,相当于阻止了其跨度太大。下面这张图对其有个形象描述,其中蓝色线表示动量方法,蓝色短线表示当前位置梯度更新,蓝色长线表示之前累积的梯度;第一个红色线表示用NAG算法预测下一步位置的梯度更新,第一条棕色线表示先前累积的梯度,其矢量相加结果(绿色线)就是参数更新的方向。
6.6、Nadam
Adam将RMSprop和动量结合起来,我们也可以看到NAG其实比动量表现更好。
Nadam(Nesterov-accelerated Adaptive
Moment Estimation),Nesterov加速的自适应矩估计,将adam和NAG结合起来,为了将NAG添加到Adam,我们需要对动量部分进行一些改变。作者将NAG梯度更新公式变为:

也就是现在不再像NAG提前预测后面位置,而是直接在当前位置对当前梯度方向做两次更新,同样运用到Adam中需要对m做一个修正: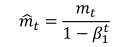
最后得到Nadam梯度更新方程为: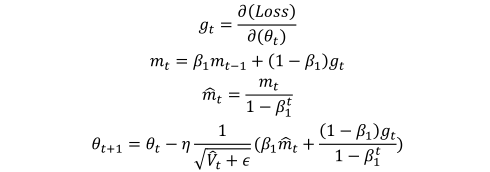
智能推荐
从零开始搭建Hadoop_创建一个hadoop项目-程序员宅基地
文章浏览阅读331次。第一部分:准备工作1 安装虚拟机2 安装centos73 安装JDK以上三步是准备工作,至此已经完成一台已安装JDK的主机第二部分:准备3台虚拟机以下所有工作最好都在root权限下操作1 克隆上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;1.1 进行克隆21.2 下一步1.3 下一步1.4 下一步1.5 根据子机需要,命名和安装路径1.6 ..._创建一个hadoop项目
心脏滴血漏洞HeartBleed CVE-2014-0160深入代码层面的分析_heartbleed代码分析-程序员宅基地
文章浏览阅读1.7k次。心脏滴血漏洞HeartBleed CVE-2014-0160 是由heartbeat功能引入的,本文从深入码层面的分析该漏洞产生的原因_heartbleed代码分析
java读取ofd文档内容_ofd电子文档内容分析工具(分析文档、签章和证书)-程序员宅基地
文章浏览阅读1.4k次。前言ofd是国家文档标准,其对标的文档格式是pdf。ofd文档是容器格式文件,ofd其实就是压缩包。将ofd文件后缀改为.zip,解压后可看到文件包含的内容。ofd文件分析工具下载:点我下载。ofd文件解压后,可以看到如下内容: 对于xml文件,可以用文本工具查看。但是对于印章文件(Seal.esl)、签名文件(SignedValue.dat)就无法查看其内容了。本人开发一款ofd内容查看器,..._signedvalue.dat
基于FPGA的数据采集系统(一)_基于fpga的信息采集-程序员宅基地
文章浏览阅读1.8w次,点赞29次,收藏313次。整体系统设计本设计主要是对ADC和DAC的使用,主要实现功能流程为:首先通过串口向FPGA发送控制信号,控制DAC芯片tlv5618进行DA装换,转换的数据存在ROM中,转换开始时读取ROM中数据进行读取转换。其次用按键控制adc128s052进行模数转换100次,模数转换数据存储到FIFO中,再从FIFO中读取数据通过串口输出显示在pc上。其整体系统框图如下:图1:FPGA数据采集系统框图从图中可以看出,该系统主要包括9个模块:串口接收模块、按键消抖模块、按键控制模块、ROM模块、D.._基于fpga的信息采集
微服务 spring cloud zuul com.netflix.zuul.exception.ZuulException GENERAL-程序员宅基地
文章浏览阅读2.5w次。1.背景错误信息:-- [http-nio-9904-exec-5] o.s.c.n.z.filters.post.SendErrorFilter : Error during filteringcom.netflix.zuul.exception.ZuulException: Forwarding error at org.springframework.cloud..._com.netflix.zuul.exception.zuulexception
邻接矩阵-建立图-程序员宅基地
文章浏览阅读358次。1.介绍图的相关概念 图是由顶点的有穷非空集和一个描述顶点之间关系-边(或者弧)的集合组成。通常,图中的数据元素被称为顶点,顶点间的关系用边表示,图通常用字母G表示,图的顶点通常用字母V表示,所以图可以定义为: G=(V,E)其中,V(G)是图中顶点的有穷非空集合,E(G)是V(G)中顶点的边的有穷集合1.1 无向图:图中任意两个顶点构成的边是没有方向的1.2 有向图:图中..._给定一个邻接矩阵未必能够造出一个图
随便推点
MDT2012部署系列之11 WDS安装与配置-程序员宅基地
文章浏览阅读321次。(十二)、WDS服务器安装通过前面的测试我们会发现,每次安装的时候需要加域光盘映像,这是一个比较麻烦的事情,试想一个上万个的公司,你天天带着一个光盘与光驱去给别人装系统,这将是一个多么痛苦的事情啊,有什么方法可以解决这个问题了?答案是肯定的,下面我们就来简单说一下。WDS服务器,它是Windows自带的一个免费的基于系统本身角色的一个功能,它主要提供一种简单、安全的通过网络快速、远程将Window..._doc server2012上通过wds+mdt无人值守部署win11系统.doc
python--xlrd/xlwt/xlutils_xlutils模块可以读xlsx吗-程序员宅基地
文章浏览阅读219次。python–xlrd/xlwt/xlutilsxlrd只能读取,不能改,支持 xlsx和xls 格式xlwt只能改,不能读xlwt只能保存为.xls格式xlutils能将xlrd.Book转为xlwt.Workbook,从而得以在现有xls的基础上修改数据,并创建一个新的xls,实现修改xlrd打开文件import xlrdexcel=xlrd.open_workbook('E:/test.xlsx') 返回值为xlrd.book.Book对象,不能修改获取sheett_xlutils模块可以读xlsx吗
关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题_unresolved attribute reference 'find_element_by_id-程序员宅基地
文章浏览阅读8.2w次,点赞267次,收藏656次。运行Selenium出现'WebDriver' object has no attribute 'find_element_by_id'或AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'等定位元素代码错误,是因为selenium更新到了新的版本,以前的一些语法经过改动。..............._unresolved attribute reference 'find_element_by_id' for class 'webdriver
DOM对象转换成jQuery对象转换与子页面获取父页面DOM对象-程序员宅基地
文章浏览阅读198次。一:模态窗口//父页面JSwindow.showModalDialog(ifrmehref, window, 'dialogWidth:550px;dialogHeight:150px;help:no;resizable:no;status:no');//子页面获取父页面DOM对象//window.showModalDialog的DOM对象var v=parentWin..._jquery获取父window下的dom对象
什么是算法?-程序员宅基地
文章浏览阅读1.7w次,点赞15次,收藏129次。算法(algorithm)是解决一系列问题的清晰指令,也就是,能对一定规范的输入,在有限的时间内获得所要求的输出。 简单来说,算法就是解决一个问题的具体方法和步骤。算法是程序的灵 魂。二、算法的特征1.可行性 算法中执行的任何计算步骤都可以分解为基本可执行的操作步,即每个计算步都可以在有限时间里完成(也称之为有效性) 算法的每一步都要有确切的意义,不能有二义性。例如“增加x的值”,并没有说增加多少,计算机就无法执行明确的运算。 _算法
【网络安全】网络安全的标准和规范_网络安全标准规范-程序员宅基地
文章浏览阅读1.5k次,点赞18次,收藏26次。网络安全的标准和规范是网络安全领域的重要组成部分。它们为网络安全提供了技术依据,规定了网络安全的技术要求和操作方式,帮助我们构建安全的网络环境。下面,我们将详细介绍一些主要的网络安全标准和规范,以及它们在实际操作中的应用。_网络安全标准规范