shell之三剑客awk(基础用法)-程序员宅基地
技术标签: 运维 linux 服务器 正则表达式 Shell脚本
文章目录
一、awk概述
AWK是一种处理文本文件的语言,是一个强大的文件分析工具。
它是专门为文本处理设计的编程语言,也是行处理软件,通常用于扫描,过滤,统计汇总等工作,数据可以来自标准输入也可以是管道或文件。
1、awk工作原理
-
当读到第一行时,匹配条件,然后执行指定动作,在接着读取第二行数据处理,不会默认输出。
-
如果没有定义匹配条件,则是默认匹配所有数据行,awk隐含循环,条件匹配多少次,动作就会执行多少次。
-
逐行读取文本,默认以空格或tab键为分割符进行分割,将分割所得的各个字段,保存到内建变量中,并按模式或或条件执行编辑命令。
与sed工作原理相比:
sed命令常用于一整行的处理。而awk比较倾向于将一行分成多个 “ 字段 ” 然后再进行处理。awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。在使用awk命令的过程中,可以使用逻辑操作符。(&&“表示"与”、“||表示"或”、"!“表示非”;还可以进行简单的数学运算,如+、一、*、/、%、^分别表示加、减、乘、除、取余和乘方。)
二、awk的格式
格式1: awk 【选项】 '模式或条件{操作} ' 文件名
格式2: awk -f 脚本文件 文件名
1、awk包含几个特殊的内建变量(可直接用)如下所示
| 内置变量 | 功能 |
|---|---|
| NF | 当前处理的行的字段个数(就是:有多少列) |
| NR | 当前处理的行的行号(就是:有多少行) |
| FNR | 读取文件的记录数(行号),从1开始,新的文件重新从1开始计数 |
| $0 | 当前处理的行的整行内容(就是:表示一行的内容) |
| $n | 当前处理行的第n个字段(就是:第n列) |
| FILENAME | 被处理的文件名 |
| FS | 指定每行的字段分隔符,默认为空格或制表位(相当于选项 -F ) |
| OFS | 输出字段的分隔符,默认也是空格 |
| RS | 行分割符。awk从文件上读取资料时,将根据Rs的定义把资料切割成许多条记录,而awk一次仅读取一条记录,预设值是“\n“ |
| ORS | 输出分割符,默认也是换行符 |
三、内置变量演示
1、【$n】进行演示
n为数字,数字为及就表示第几列
案例1:结合print进行输出,默认分隔符。
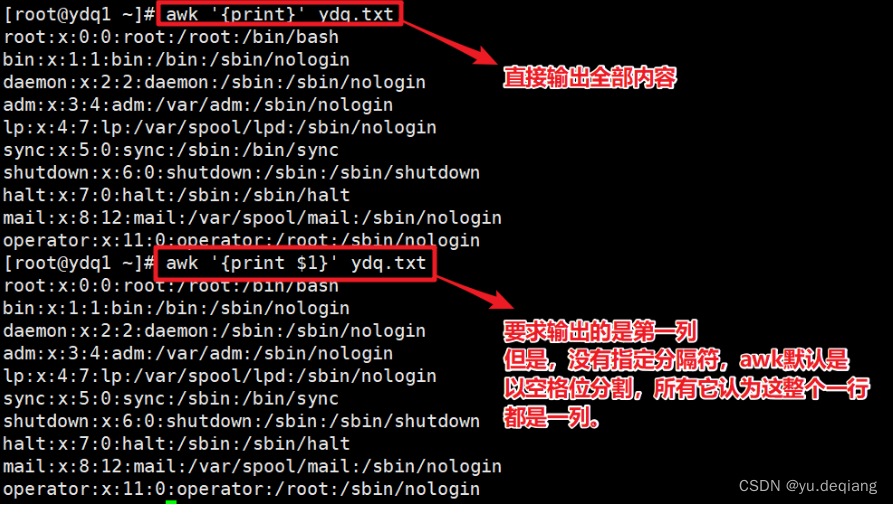
案例2:设定分割符号
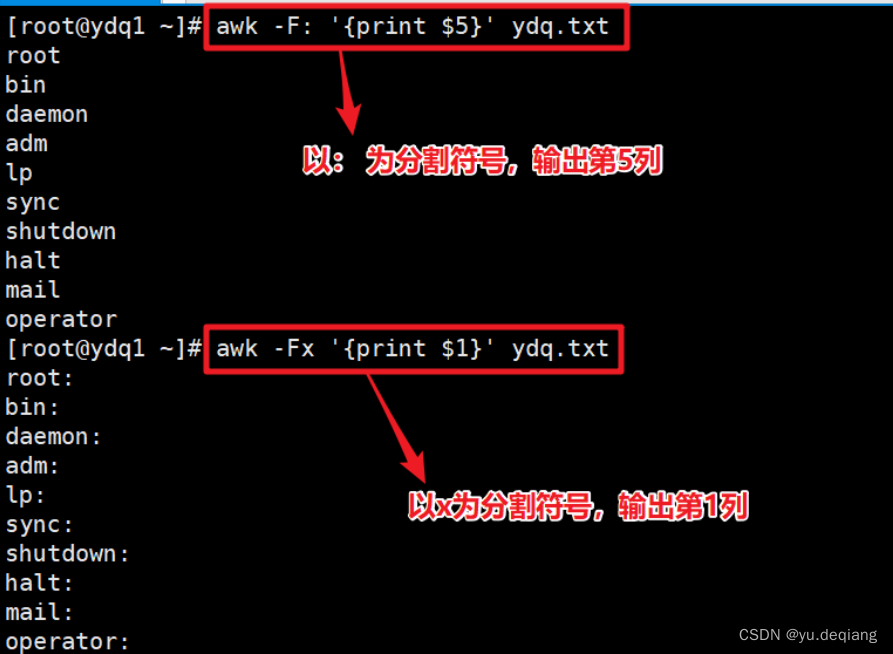
案例3:输出时,显示列的空格
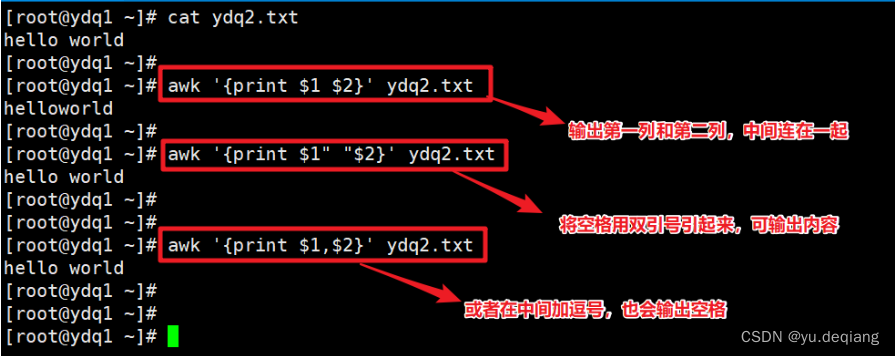
案例4:两列之间插入制表符

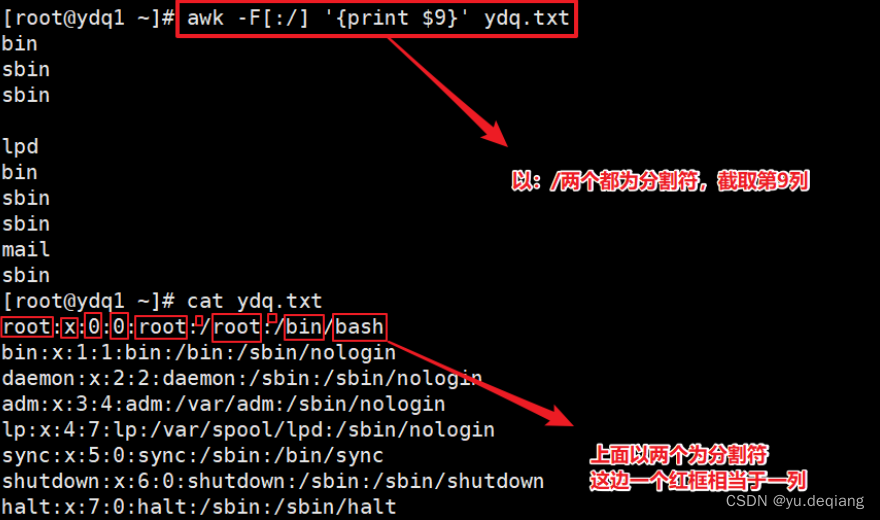
案例5:设置多个分割符
2、【$0】的演示
$0表示整行
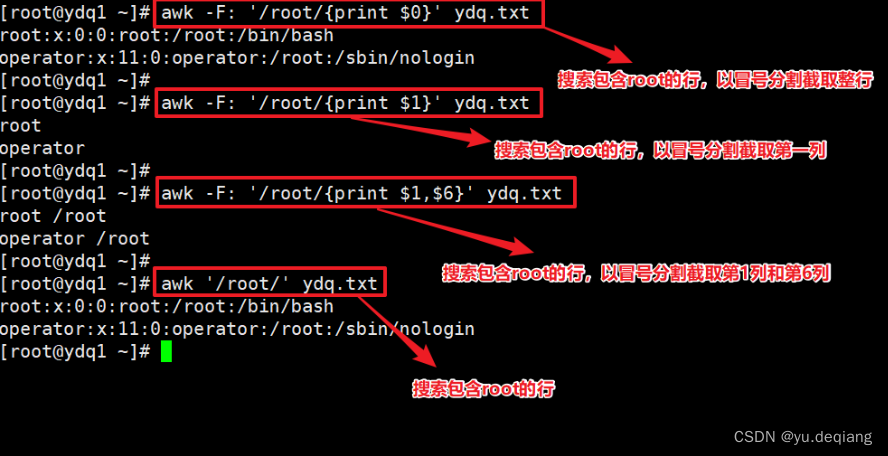
3、【NF】(多少列) 和 【NR】(多少行)的演示
NR:表示该处理的行序号是多少
NF:表示该处理的行,有多少列
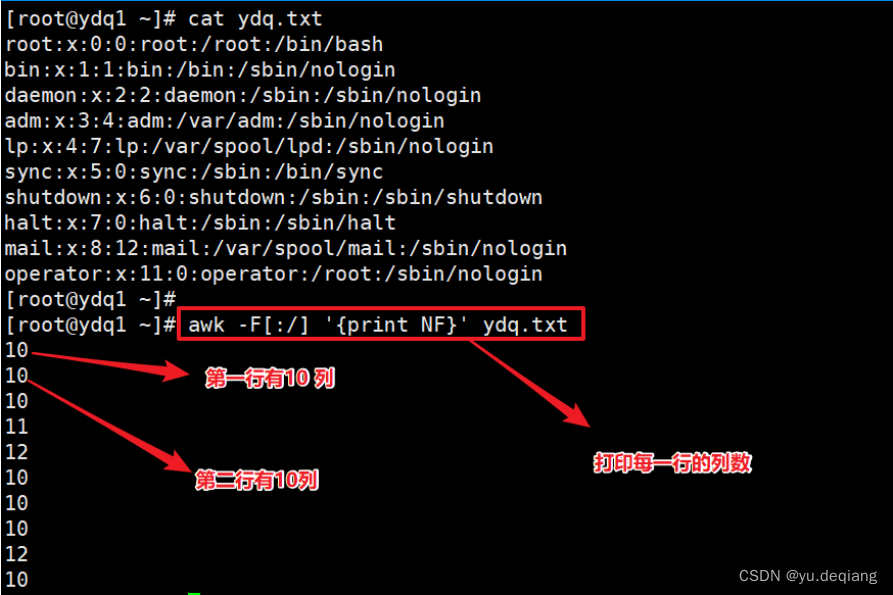
案例1:打印每一行的列数
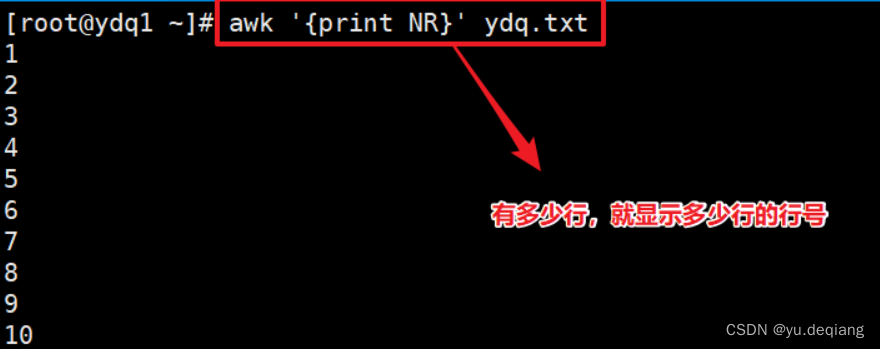
案例2:显示行号
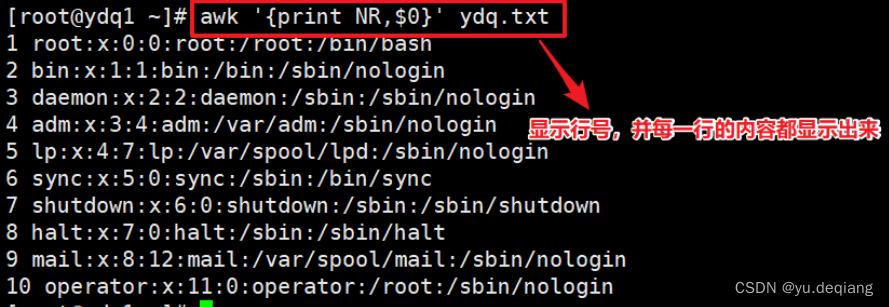
案例3:显示行号,并显示每一行的内容
案例4:打印第二行,不加print也一样,默认就是打印
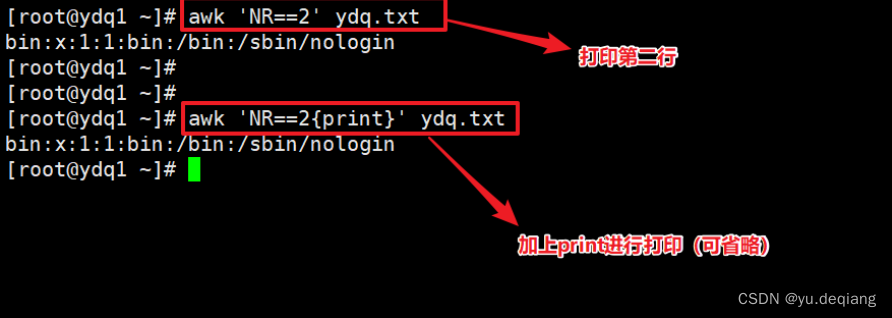
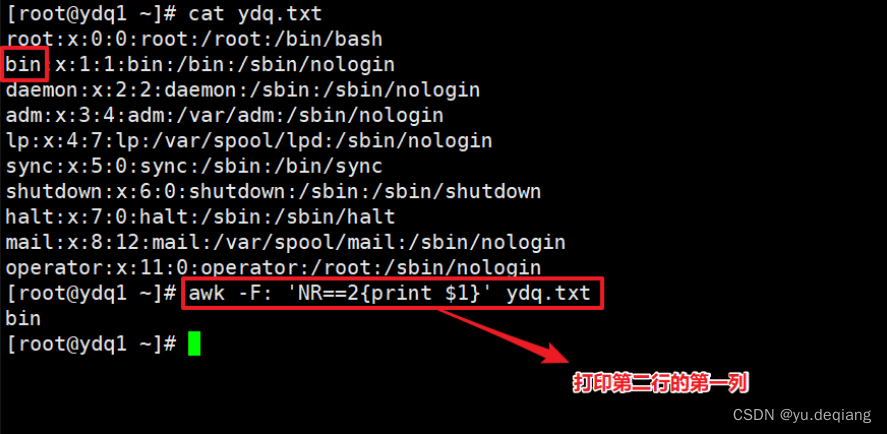
案例5:打印第二行的第一列
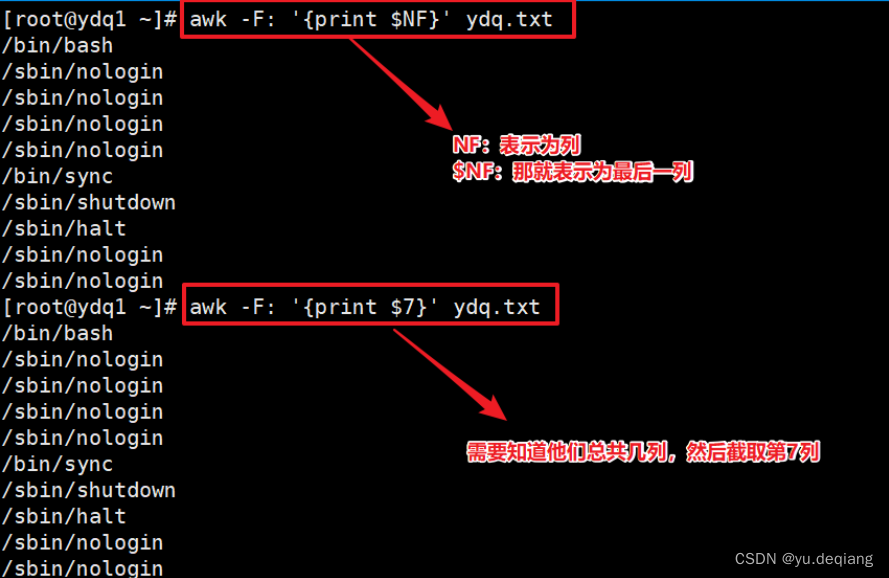
案例6:打印最后一列
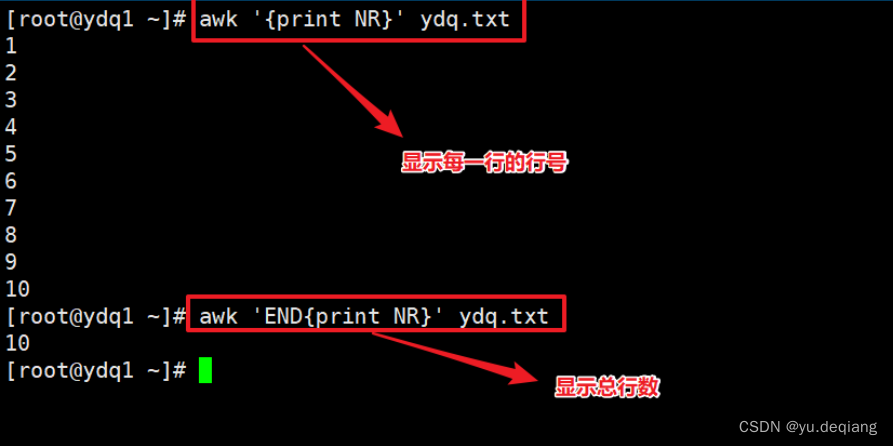
案例7:打印总行数
案例8:打印文件最后一行
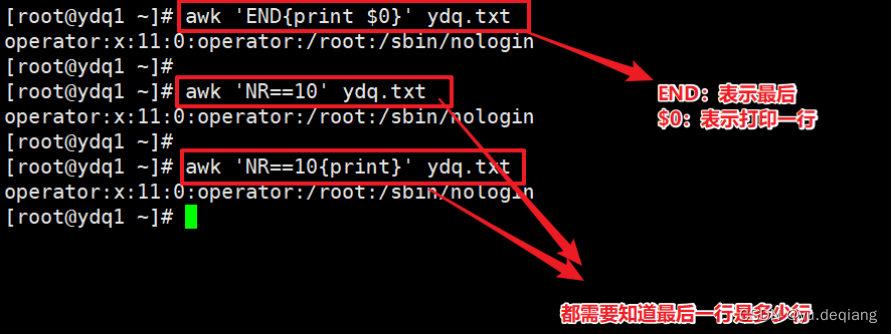
案例9:加上文字描述行数和列数

4、面试题
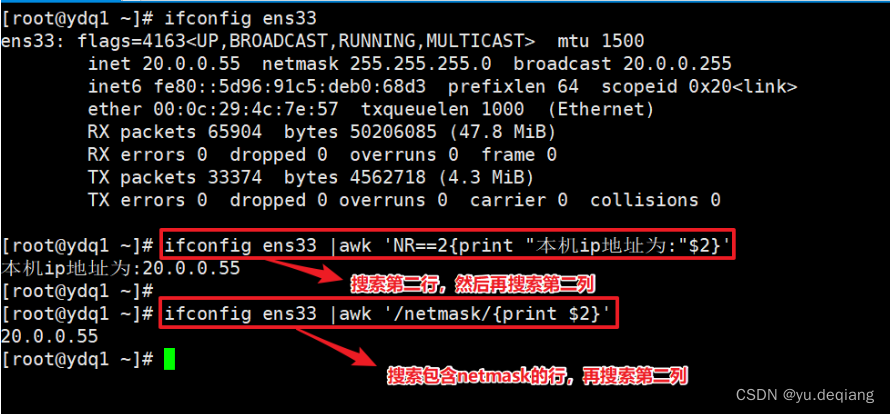
案例1:查看本机的ip地址多少,截取出来
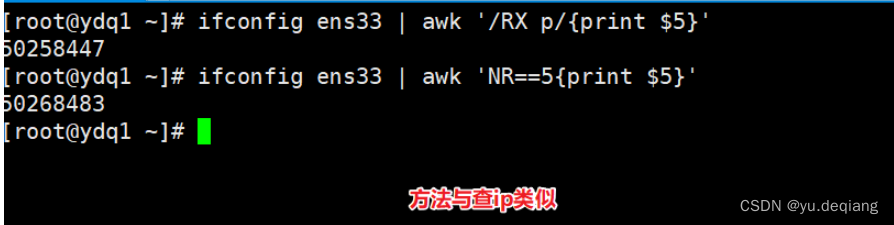
案例2:查看本机流量有多少字节
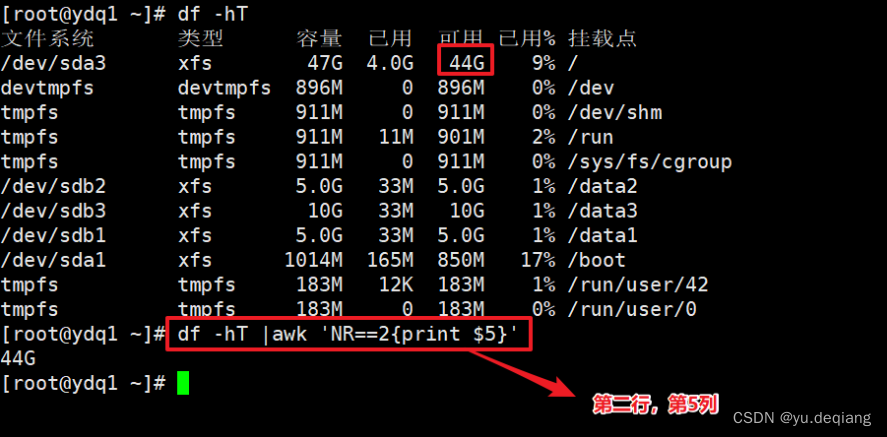
案例3:查看根分区的可用量
5、BEGIN开始和END结尾
逐行执行开始之前执行什么任务,结束之后再执行什么任务,用BEGIN、END。
- BEGIN:一般用来做初始化操作,仅在读取数据记录之前执行一次
- END:一般用来做汇总操作,仅在读取完数据记录之后执行一次
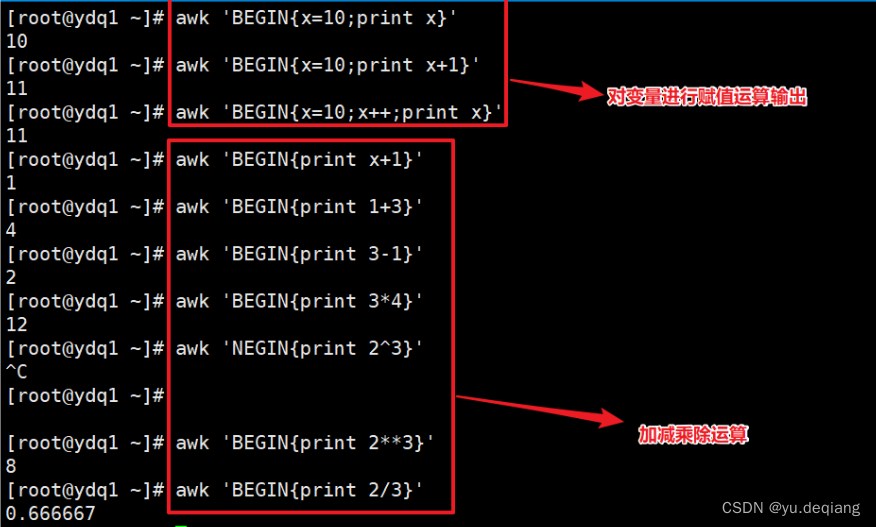
案例1:在打印之前定义字段分割符为冒号
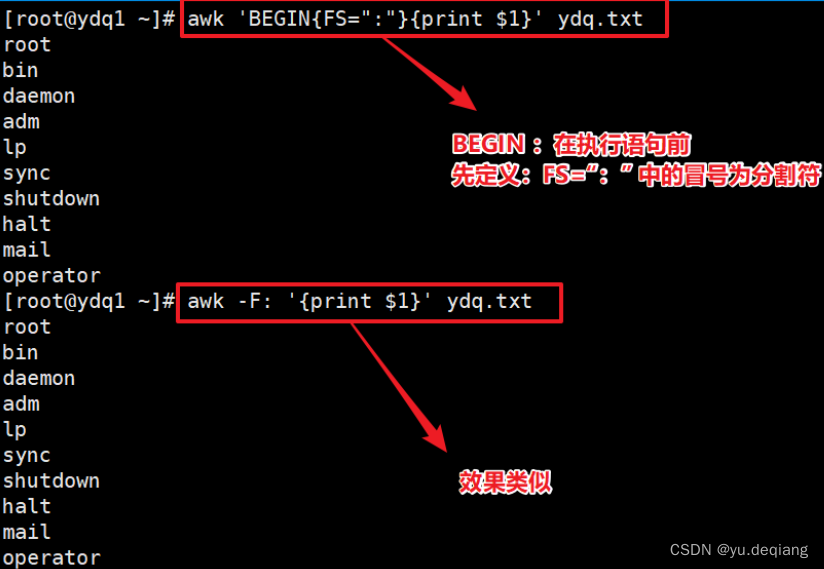
案例2:OFS定义了输出时以什么分隔,$1$2中间要用逗号分隔,因为逗号默认被映射为OFS变量,而这个变量默认是空格
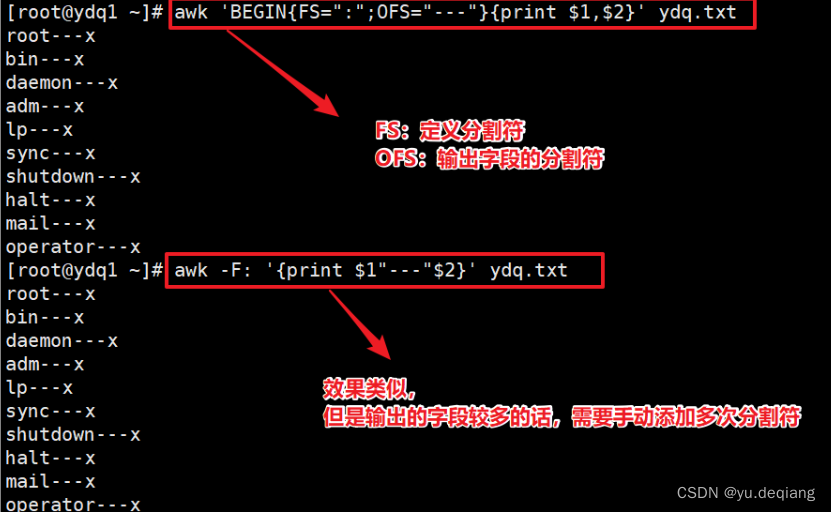
案例2:可以看到当有多个文件时,序号会分别标好每一个文件内容的行号,不同文件会从头开始。(NR会连续在一起)
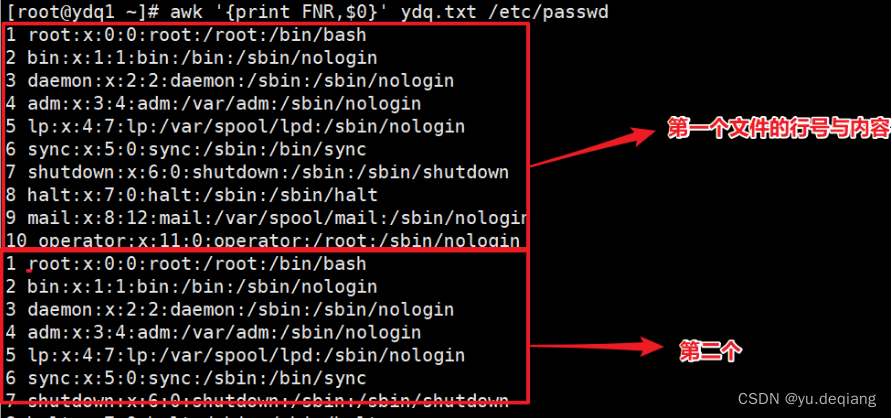
案例3:RS:指定以什么为换行符,这里指定是冒号,你指定的必须是原文里存在的字符
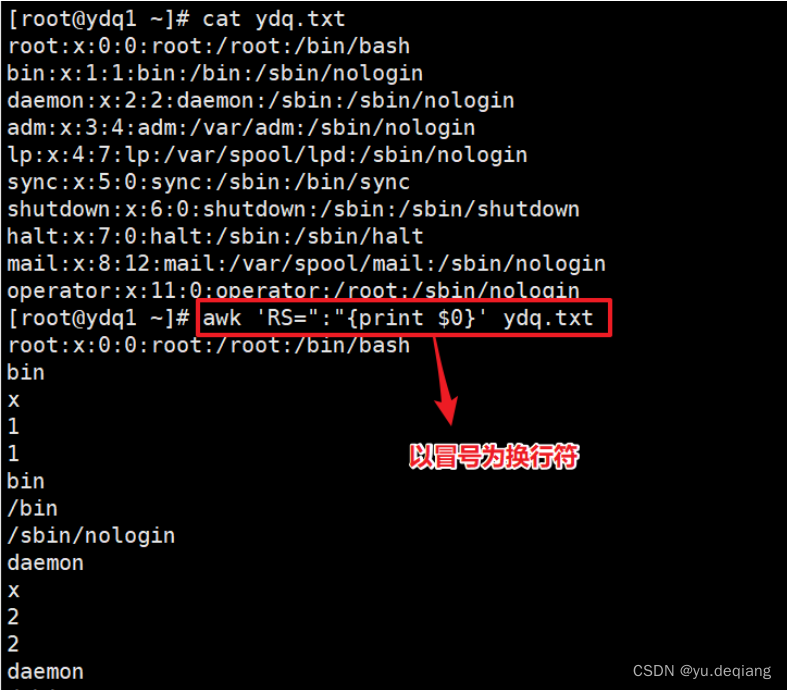
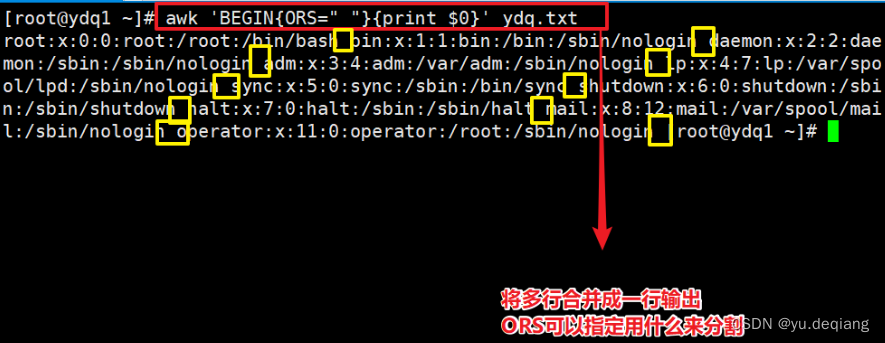
案例4:把多行合并成一行输出,输出的时候自定义以空格分隔每行,本来默认的是回车键
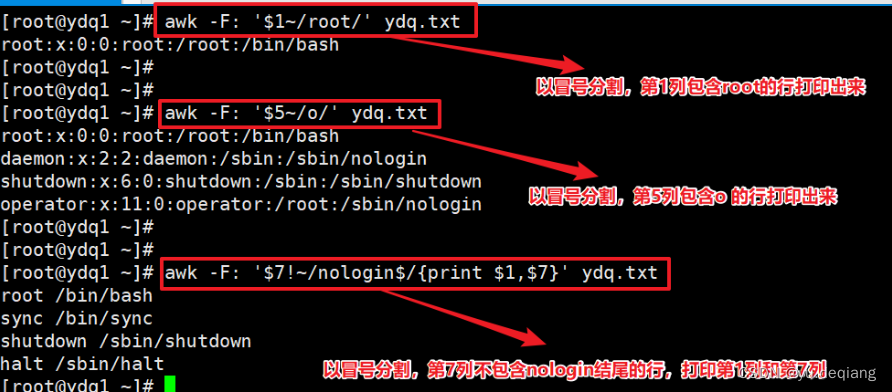
6、模糊匹配
精确匹配: 可以将要匹配的内容加上双引号。
用~表示包含,用!~表示不包含
7、关于数值与字符串的比较
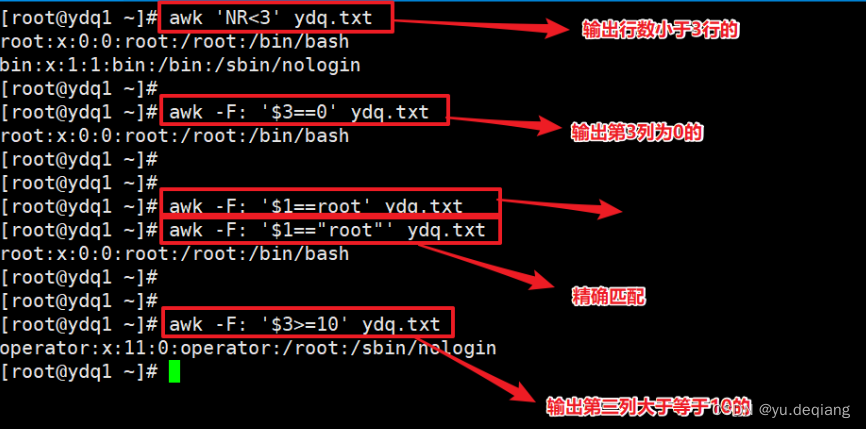
加上逻辑运算: && ||
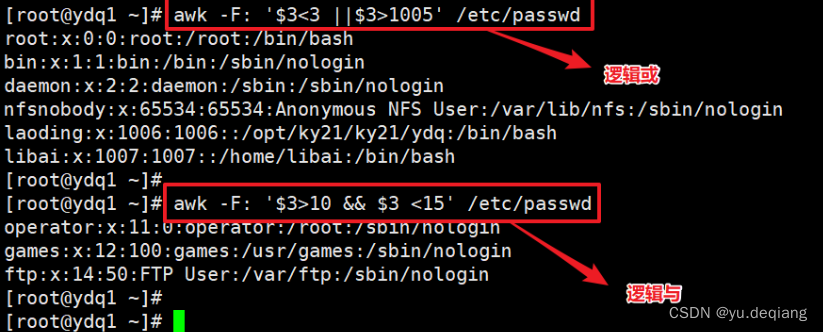
案例:打印1-200之间所有能被7整除并且包含数字7的整数数字

四、总结
awk常用操作是提取转换文本文件内容,awk功能十分强大,几乎其它文本处理命令能做的,awk都能做。
此处主要介绍awk的几种内置变量。
- $n:表示截取哪一列,通常和print一起使用
- $0:表示整行内容
- NF:表示该行有多少列
- NR:表示该行的行号
- FNR:表示读取两个文件时,序号会分别从0开始标
- FS:表示读取文件的分隔符(默认空格)
- OFS:表示输入的内容以什么为分割符(默认空格)
- RS:表示读取文件的以什么为换行符(默认\n)
- ORS:表示输出的内容以什么为换行符(默认\n)
- ~:表示包含
- !~:表示不包含
智能推荐
【100个 Unity踩坑小知识点】| Unity控制物体持续指向某个方向_unity物体指定方向-程序员宅基地
文章浏览阅读10w+次,点赞30次,收藏80次。Unity 小科普老规矩,先介绍一下 Unity 的科普小知识:Unity是 实时3D互动内容创作和运营平台 。包括游戏开发、美术、建筑、汽车设计、影视在内的所有创作者,借助 Unity 将创意变成现实。Unity 平台提供一整套完善的软件解决方案,可用于创作、运营和变现任何实时互动的2D和3D内容,支持平台包括手机、平板电脑、PC、游戏主机、增强现实和虚拟现实设备。 也可以简单把 Unity 理解为一个游戏引擎,可以用来专业制作游戏!_unity物体指定方向
android intent打开各种格式文档方法_android intent 去打开zip文件-程序员宅基地
文章浏览阅读4k次,点赞4次,收藏6次。我们开发的时候经常碰到打开各种文档,目前的应用处理方式 基本都是依赖于三方软件打开 ,而不是在应用内打开,因为文件格式有很多,倘若都在应用内打开的话,肯定要增加很大的开发时间和开发成本,而且实现效果没有一些三方的app实现的效果好。话不多说,给大_android intent 去打开zip文件
《深入理解Java虚拟机》第六章 类文件结构 — 读书笔记_cc_final, acc_syntheti-程序员宅基地
文章浏览阅读590次。1. 概述计算机只认识0和1,我们编写的程序需要经编译器翻译为由0和1构成的二进制文件才能被计算机执行。伴随着虚拟机和大量建立在虚拟机上程序语言的出现,将程序编译为本地字节码文件已不再是唯一的选择,越来越多的程序语言选择了与操作系统无关的,平台中立的格式作为程序编译后的存储格式。2. 无关性虚拟机提供商发布了许多可以运行在各种不同平台上的虚拟机,这些虚拟机都可以载入和执行同一种平台无关..._cc_final, acc_syntheti
Pandas读取csv文件某一列并保存到txt文件中-程序员宅基地
文章浏览阅读4.7k次,点赞3次,收藏19次。Pandas读取csv文件某一列并保存到txt文件中按道理来说挺简单的,但是却查了好久,本来想利用pandas的api获取某一列的数据,然后写入到文件中,但是写入到文件后出现各种问题,要不程序报错,要不不分行。最后还是按照之前的那样,获取的之后一个个的添加到之前创建好的list中。def save_csv_to_text(filename, csv_name, usecols): '..._python 将csv某列数据读取到txt文本中
react解析html字符串方法-程序员宅基地
文章浏览阅读1.9k次。react解析html字符串方法_react解析html
web安全入门(基础篇)---小迪视频笔记_8006端口-程序员宅基地
文章浏览阅读3.5k次,点赞3次,收藏16次。1、为什么需要列表①变量可以存储一个元素,而列表是一个“大容器"可以存储N多个元素,程序可以方便地对这些数据进行整体操作②列表相当于其它语言中的数组③列表示意图:_8006端口
随便推点
SqlServer查询数据中所有表及所有的字段名和字段属性_sql 所有表 条件查询-程序员宅基地
文章浏览阅读2k次。------sqlserver 查询某个表的列名称、说明、备注、类型等SELECT 表名 = case when a.colorder=1 then d.name else '' end, 表说明 = case when a.colorder=1 then isnull(f.value,'') else '' end, 字段序号 = a.col..._sql 所有表 条件查询
Spark抽取mysql中的数据到Hive中_spark怎么jdbc写入到hive-程序员宅基地
文章浏览阅读5.6k次,点赞5次,收藏81次。提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录思路一、案例介绍二、具体步骤1.编写scala程序完成从mysql讲数据导出成csv文件2.打包成jar包提交到集群上3.将hdfs上的这个文件下载到本地目录下4.将本地数据文件的数据加载到hive中总结思路spark抽取mysql中的数据到hive中,可通过以下2步完成:1.先将mysql中的数据抽取到存放再hdfs上的一个文件(.csv,.txt)2.再讲文件通过load命令加载到hive中下面用具体案例演示一._spark怎么jdbc写入到hive
解决Mysql 主从或主主报1032错误_last_errno: 1032-程序员宅基地
文章浏览阅读8.2k次,点赞2次,收藏7次。1032错误的主要原因是主库更新或者是删除的记录在从库上不存在引起的。处理此种错误一般有两种思路:1、直接跳过错误执行语句2、找到错误执行语句,修复从库数据第一种解决方案会有造成主从不一致的隐患(delete语句可以跳过),第二种是从根本上解决问题比较推荐语句跳过操作方法如下:1032 错误提示如下:Replicate_Wild_Ignore_Table: ..._last_errno: 1032
button按钮居中_button居中-程序员宅基地
文章浏览阅读1.2w次,点赞3次,收藏7次。今天在写页面时,发现给button按钮设置居中时,css页面写了text-align="center",但是不起作用,用了display属性也无作用,试了好多次发现要给button按钮添加个div,然..._button居中
hiberante开发备忘录_iphone rx备忘录-程序员宅基地
文章浏览阅读495次。在hb刚火的那正儿, 看过, 但是对ormaping不是很理解, 现在重新看hb, 以前很多不是很懂的地方现在基本已经全部豁然开朗. ·increment标识生成器由hibernate以递增的方式生成主键 ·identity标识生成器由底层数据库来负责生成主键,这个主要针对支持自增字段作为主键的数据库 ·sequence标识生成器由底层数据库提供的序列来生成主键 ·native标识生成器会根据底层_iphone rx备忘录
中国嵌入式应用市场四大热点及趋势_目前嵌入式系统是热点-程序员宅基地
文章浏览阅读2.2k次。嵌入式系统的广泛应用已经渗入到我们日常生活的各个方面。在手机、MP3、PDA、数码相机、电视机,甚至电饭锅、手表里都有嵌入式系统的身影,工业自动化控制、仪器仪表、汽车、航空航天等领域更是嵌入式系统的天下。据估计,每年全球嵌入式系统带来的相关工业产值已超过1万亿美元。随着多功能手机、便携式多媒体播放机、数码相机、HDTV和机顶盒等新兴产品逐渐获得市场的认可,嵌入式系统的市场正在以每年30%的速度递增_目前嵌入式系统是热点