在一台虚拟机上做kafka集群,使用Java代码发,接消息,kafka tool的使用_向kafka集群发送消息,可以在任意台服务上看到吗-程序员宅基地
技术标签: kafka tool 一台虚拟机 Java代码发 cenos7 kafka集群 接消
1.Kafka
kafka是一个开源的分布式消息系统,由linkedin使用scala编写,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。具有高水平扩展和高吞吐量。
1.1 kafka的设计目标
1.高吞吐量。
2.数据磁盘持久化:消息不在内存中cache,直接写入到磁盘,充分利用磁盘的顺序读写性能。
3.zero-copy:减少IO操作步骤。
4.支持数据批量发送和拉取。
5.支持数据压缩。
6.Topic划分为多个partition,提高并行处理能力。
1.2 相关概念
1.Producer :消息生产者,就是向kafka broker发消息的客户端。
2.Consumer :消息消费者,向kafka broker取消息的客户端
3.Topic :主题,存放信息的地方,可以理解为一个队列。
4.Consumer Group (CG):消费组.这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个CG只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
5.Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
6.Partition:分区. 一个Topic中的消息数据按照多个分区组织,分区是kafka消息队列组织的最小单位,一个分区可以看作是一个FIFO( First Input First Output的缩写,先入先出队列)的队列。为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
7.Offset:消息偏移量.kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
1.3 kafka架构
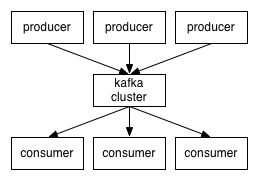
1.4 Topic与分区架构
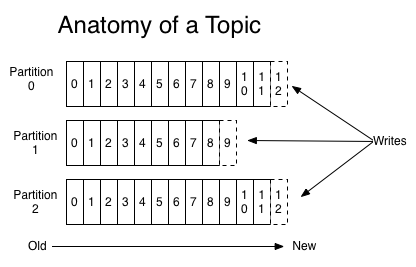
1.5 kafka集群(一台虚拟机上)
前提:
kafka集群依赖zookeeper集群,所以必须要先有zookeeper集群.可参看我的上一篇文章:<<在一台虚拟机上做zookeeper集群>>
软件环境: cenos7虚拟机一台, kafka_2.12-2.1.0.tar.gz
Kafka下载地址: http://kafka.apache.org/downloads
步骤:
创建kafka文件夹,上传安装包
cd /usr/dev-soft && mkdir kafka && cd kafka
rz,选择安装包上传
解压
tar –zxvf kafka_2.12-2.1.0.tar.gz
创建3个保存消息的文件夹
mkdir kafka-logs-1 kafka-logs-2 kafka-logs-3
修改配置文件server.properties
vi kafka_2.12-2.1.0/config/server.properties
命令模式下输入 :set nu显示行号
修改:
第21行: broker.id=1
第31行: listeners=PLAINTEXT://192.168.81.128:9091
第36行: advertised.listeners=PLAINTEXT://192.168.81.128:9091
第60行: log.dirs=/usr/dev-soft/kafka/kafka-logs-1
第123行: zookeeper.connect=192.168.81.128:2181,192.168.81.128:2182,192.168.81.128:2183
至此一个kafka应用配置完成.本次集群使用3个kafka应用,复制2份,修改即可.
步骤:
修改名字,复制2份
mv kafka_2.12-2.1.0 kafka_2.12-2.1.0-1
cp –r kafka_2.12-2.1.0-1 kafka_2.12-2.1.0-2
cp –r kafka_2.12-2.1.0-1 kafka_2.12-2.1.0-3
第二台修改server.properties
vi kafka_2.12-2.1.0-2/config/server.properties
修改:
第21行: broker.id=2
第31行: listeners=PLAINTEXT://192.168.81.128:9092
第36行: advertised.listeners=PLAINTEXT://192.168.81.128:9092
第60行: log.dirs=/usr/dev-soft/kafka/kafka-logs-2
第三台修改server.properties
vi kafka_2.12-2.1.0-3/config/server.properties
修改:
第21行: broker.id=3
第31行: listeners=PLAINTEXT://192.168.81.128:9093
第36行: advertised.listeners=PLAINTEXT://192.168.81.128:9093
第60行: log.dirs=/usr/dev-soft/kafka/kafka-logs-3
Kafka集群配置完成.
2.5.1启动&关闭集群
编写启动脚本(其实就是依次启动3个kafka)
cd /usr/dev-soft/kafka
vim kafka-start.sh
内容如下:
cd kafka_2.12-2.1.0-1
bin/kafka-server-start.sh -daemon config/server.properties
cd ../kafka_2.12-2.1.0-2
bin/kafka-server-start.sh -daemon config/server.properties
cd ../kafka_2.12-2.1.0-3
bin/kafka-server-start.sh -daemon config/server.properties
cd ../
同理关闭脚本如下:
vim kafka-stop.sh
写入以下内容:
kafka_2.12-2.1.0-1/bin/kafka-server-stop.sh
kafka_2.12-2.1.0-2/bin/kafka-server-stop.sh
kafka_2.12-2.1.0-3/bin/kafka-server-stop.sh
依次赋予执行权限
chmod u+x kafka-start.sh
chmod u+x kafka-stop.sh
启动kafka集群:(注意要先启动zookeeper集群)
./ kafka-start.sh
启动会有点慢,稍等后,输入jps命令查看结果:

这样说明启动成功了,但是需要发送信息证明集群的可用行,在此之前,需要先把9091,9092,9093这三个端口对外开放,消息的发送和拉取就是通过这些端口的.
执行如下命令:
开放端口:
firewall-cmd --zone=public --add-port=9091/tcp –permanent
firewall-cmd --zone=public --add-port=9092/tcp –permanent
firewall-cmd --zone=public --add-port=9093/tcp --permanent
重启防火墙:
firewall-cmd --reload
查看端口号是否开启:
firewall-cmd --query-port=9091/tcp
firewall-cmd --query-port=9092/tcp
firewall-cmd --query-port=9093/tcp
2.5.2 发送消息&消费消息
在一个kafka应用上操作即可
cd /usr/dev-soft/kafka/ kafka_2.12-2.1.0-1
创建topic:kafkatest
bin/kafka-topics.sh --create --zookeeper 192.168.81.128:2181,192.168.81.128:2182,192.168.81.128:2183 --replication-factor 2 --partitions 2 --topic kafkatest
查看topic:
某个topic
bin/kafka-topics.sh --describe --zookeeper 192.168.81.128:2181,192.168.81.128:2182,192.168.81.128:2183 --topic kafkatest
全部topic
bin/kafka-topics.sh --list --zookeeper 192.168.81.128:2181,192.168.81.128:2182,192.168.81.128:2183
发送信息:
bin/kafka-console-producer.sh --broker-list 192.168.81.128:9091,192.168.81.128:9092,192.168.81.128:9093 --topic kafkatest
消费信息:
打开另一个窗口:
cd /usr/dev-soft/kafka/ kafka_2.12-2.1.0-1
bin/kafka-console-consumer.sh --bootstrap-server 192.168.81.128:9091,192.168.81.128:9092,192.168.81.128:9093 --from-beginning --topic kafkatest
3.使用Java代码发送,接收消息
使用Springboot项目开发,Springboot已经集成了kafka,开发起来非常简单.
3.1 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.1.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.mlsama</groupId>
<artifactId>kafka</artifactId>
<version>1.0.0</version>
<name>kafka</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
<!--lombok约束-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--日记-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
3.2 application.properties
#修改端口
server.port=8899
#springMVC的配置
#视图前缀
spring.mvc.view.prefix=/html/
#视图后缀
spring.mvc.view.suffix=.html
#kafka相关配置
spring.kafka.bootstrap-servers=192.168.81.128:9091,192.168.81.128:9092,192.168.81.128:9093
#设置一个默认组
spring.kafka.consumer.group-id=0
#key-value序列化反序列化
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#每次批量发送消息的数量
spring.kafka.producer.batch-size=12800
spring.kafka.producer.buffer-memory=1024003.3 KafkaProduct.Class
@RestController
@Slf4j
public class KafkaProduct {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@GetMapping("/index")
public String kafka(){
return "kafka";
}
/**
* 发送消息到kafka对应的topic
* @param topic
* @param message
*/
@RequestMapping("/kafka/sendMessage")
public String sendMessage(@RequestParam("topic")String topic, @RequestParam("message")String message) {
try {
ListenableFuture<SendResult<String, String>> send = kafkaTemplate.send(topic, 0,System.currentTimeMillis(),"test",message);
send.addCallback(new SuccessCallback() {
@Override
public void onSuccess(@Nullable Object obj) {
SendResult<String, String> sendResult = (SendResult) obj;
//...
log.info("消息发送成功:{}", sendResult);
}
}, new FailureCallback() {
@Override
public void onFailure(Throwable throwable) {
log.info("消息发送失败,case:{}", throwable);
//失败处理
}
});
return "消息发送成功";
}catch (Exception e){
return "消息发送失败";
}
}3.4 KafkaConsumer.Class
/**
* 消费信息,监听一系列topic的信息
* @param record
*/
@KafkaListener(topics = {"test","kafkatest"})
private void consumerMessage(ConsumerRecord<?, ?> record) {
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
if (kafkaMessage.isPresent()) {
Object message = kafkaMessage.get();
log.info("----------------- 返回的信息对象:{}",record);
log.info("------------------收到的message:{}",message);
}
}3.5 kafka.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>kafka页面</title>
</head>
<body>
<form action="http://127.0.0.1:8899/kafka/sendMessage" method="post">
主题:<input type="text" name="topic"/><br>
信息:<input type="text" name="message"/><br>
<input type="submit" value="发送"/>
</form>
</body>
</html>3.6 启动类KafkaApplication
package com.mlsama.kafka;
import org.springframework.boot.Banner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class KafkaApplication {
public static void main(String[] args) {
/** 创建SpringApplication应用对象 */
SpringApplication springApplication =
new SpringApplication(KafkaApplication.class);
/** 设置横幅模式(设置关闭) */
springApplication.setBannerMode(Banner.Mode.OFF);
/** 运行 */
springApplication.run(args);
}
}直接运行启动类,访问: http://127.0.0.1:8899/index
4 kafka tool
Kafka tool提供一个界面,可以直观的看到kafka集群的信息,包括topic,partition,发送的消息等.
下载地址:http://www.kafkatool.com/download.html 现在只有2个版本,因为安装的kafka版本是2.1.0,所以下载Windows版的2.0.3.安装是傻瓜式的的.第一次打开kafka tool会提示设置连接kafka 集群.点击确认后,界面如下:

设置完,点击test,提示连接成功后,点击add
设置消息以String显示:
Tool---setting,点击topics,把右边的key和message设置为String即可.
查看kafka的数据:

智能推荐
从零开始搭建Hadoop_创建一个hadoop项目-程序员宅基地
文章浏览阅读331次。第一部分:准备工作1 安装虚拟机2 安装centos73 安装JDK以上三步是准备工作,至此已经完成一台已安装JDK的主机第二部分:准备3台虚拟机以下所有工作最好都在root权限下操作1 克隆上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;1.1 进行克隆21.2 下一步1.3 下一步1.4 下一步1.5 根据子机需要,命名和安装路径1.6 ..._创建一个hadoop项目
心脏滴血漏洞HeartBleed CVE-2014-0160深入代码层面的分析_heartbleed代码分析-程序员宅基地
文章浏览阅读1.7k次。心脏滴血漏洞HeartBleed CVE-2014-0160 是由heartbeat功能引入的,本文从深入码层面的分析该漏洞产生的原因_heartbleed代码分析
java读取ofd文档内容_ofd电子文档内容分析工具(分析文档、签章和证书)-程序员宅基地
文章浏览阅读1.4k次。前言ofd是国家文档标准,其对标的文档格式是pdf。ofd文档是容器格式文件,ofd其实就是压缩包。将ofd文件后缀改为.zip,解压后可看到文件包含的内容。ofd文件分析工具下载:点我下载。ofd文件解压后,可以看到如下内容: 对于xml文件,可以用文本工具查看。但是对于印章文件(Seal.esl)、签名文件(SignedValue.dat)就无法查看其内容了。本人开发一款ofd内容查看器,..._signedvalue.dat
基于FPGA的数据采集系统(一)_基于fpga的信息采集-程序员宅基地
文章浏览阅读1.8w次,点赞29次,收藏313次。整体系统设计本设计主要是对ADC和DAC的使用,主要实现功能流程为:首先通过串口向FPGA发送控制信号,控制DAC芯片tlv5618进行DA装换,转换的数据存在ROM中,转换开始时读取ROM中数据进行读取转换。其次用按键控制adc128s052进行模数转换100次,模数转换数据存储到FIFO中,再从FIFO中读取数据通过串口输出显示在pc上。其整体系统框图如下:图1:FPGA数据采集系统框图从图中可以看出,该系统主要包括9个模块:串口接收模块、按键消抖模块、按键控制模块、ROM模块、D.._基于fpga的信息采集
微服务 spring cloud zuul com.netflix.zuul.exception.ZuulException GENERAL-程序员宅基地
文章浏览阅读2.5w次。1.背景错误信息:-- [http-nio-9904-exec-5] o.s.c.n.z.filters.post.SendErrorFilter : Error during filteringcom.netflix.zuul.exception.ZuulException: Forwarding error at org.springframework.cloud..._com.netflix.zuul.exception.zuulexception
邻接矩阵-建立图-程序员宅基地
文章浏览阅读358次。1.介绍图的相关概念 图是由顶点的有穷非空集和一个描述顶点之间关系-边(或者弧)的集合组成。通常,图中的数据元素被称为顶点,顶点间的关系用边表示,图通常用字母G表示,图的顶点通常用字母V表示,所以图可以定义为: G=(V,E)其中,V(G)是图中顶点的有穷非空集合,E(G)是V(G)中顶点的边的有穷集合1.1 无向图:图中任意两个顶点构成的边是没有方向的1.2 有向图:图中..._给定一个邻接矩阵未必能够造出一个图
随便推点
MDT2012部署系列之11 WDS安装与配置-程序员宅基地
文章浏览阅读321次。(十二)、WDS服务器安装通过前面的测试我们会发现,每次安装的时候需要加域光盘映像,这是一个比较麻烦的事情,试想一个上万个的公司,你天天带着一个光盘与光驱去给别人装系统,这将是一个多么痛苦的事情啊,有什么方法可以解决这个问题了?答案是肯定的,下面我们就来简单说一下。WDS服务器,它是Windows自带的一个免费的基于系统本身角色的一个功能,它主要提供一种简单、安全的通过网络快速、远程将Window..._doc server2012上通过wds+mdt无人值守部署win11系统.doc
python--xlrd/xlwt/xlutils_xlutils模块可以读xlsx吗-程序员宅基地
文章浏览阅读219次。python–xlrd/xlwt/xlutilsxlrd只能读取,不能改,支持 xlsx和xls 格式xlwt只能改,不能读xlwt只能保存为.xls格式xlutils能将xlrd.Book转为xlwt.Workbook,从而得以在现有xls的基础上修改数据,并创建一个新的xls,实现修改xlrd打开文件import xlrdexcel=xlrd.open_workbook('E:/test.xlsx') 返回值为xlrd.book.Book对象,不能修改获取sheett_xlutils模块可以读xlsx吗
关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题_unresolved attribute reference 'find_element_by_id-程序员宅基地
文章浏览阅读8.2w次,点赞267次,收藏656次。运行Selenium出现'WebDriver' object has no attribute 'find_element_by_id'或AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'等定位元素代码错误,是因为selenium更新到了新的版本,以前的一些语法经过改动。..............._unresolved attribute reference 'find_element_by_id' for class 'webdriver
DOM对象转换成jQuery对象转换与子页面获取父页面DOM对象-程序员宅基地
文章浏览阅读198次。一:模态窗口//父页面JSwindow.showModalDialog(ifrmehref, window, 'dialogWidth:550px;dialogHeight:150px;help:no;resizable:no;status:no');//子页面获取父页面DOM对象//window.showModalDialog的DOM对象var v=parentWin..._jquery获取父window下的dom对象
什么是算法?-程序员宅基地
文章浏览阅读1.7w次,点赞15次,收藏129次。算法(algorithm)是解决一系列问题的清晰指令,也就是,能对一定规范的输入,在有限的时间内获得所要求的输出。 简单来说,算法就是解决一个问题的具体方法和步骤。算法是程序的灵 魂。二、算法的特征1.可行性 算法中执行的任何计算步骤都可以分解为基本可执行的操作步,即每个计算步都可以在有限时间里完成(也称之为有效性) 算法的每一步都要有确切的意义,不能有二义性。例如“增加x的值”,并没有说增加多少,计算机就无法执行明确的运算。 _算法
【网络安全】网络安全的标准和规范_网络安全标准规范-程序员宅基地
文章浏览阅读1.5k次,点赞18次,收藏26次。网络安全的标准和规范是网络安全领域的重要组成部分。它们为网络安全提供了技术依据,规定了网络安全的技术要求和操作方式,帮助我们构建安全的网络环境。下面,我们将详细介绍一些主要的网络安全标准和规范,以及它们在实际操作中的应用。_网络安全标准规范