(一)数据科学_聚类 样本外-程序员宅基地
1 数据科学概念
数据科学是一个发现、解释数据中的模式并用于解决问题的过程。数据科学可以从数据中获取知识,为行动提出建议的方法、技术和流程,以完成商业或工业上的目标。
下图所示流程为数据科学的工作范式。反过来即为建模步骤。
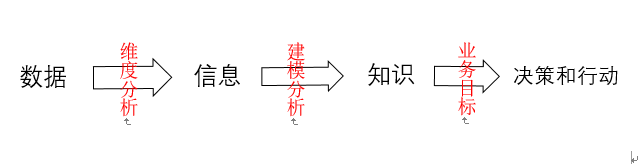
数据学是数据科学的基础。数据学研究数据本身,研究数据的各种类型、状态、属性及变化规律;数据科学是为科学研究的数据方法。
2 数理统计技术
2.1 描述性统计分析
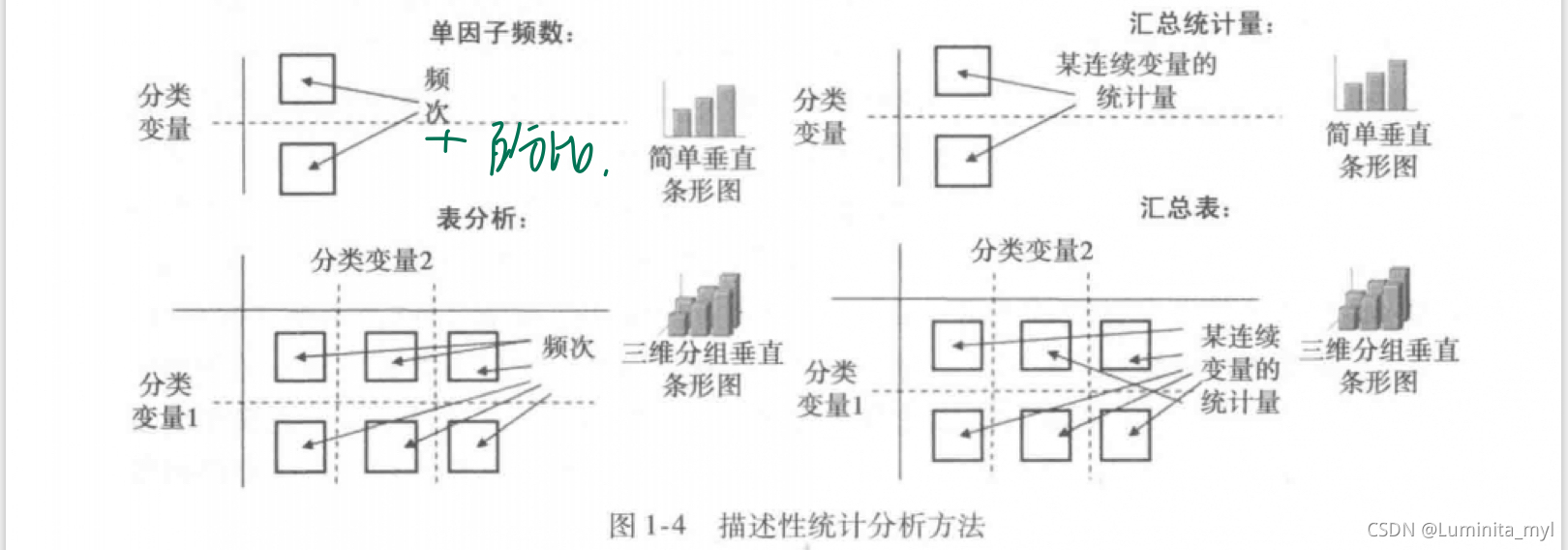
描述性统计分析就是从总体数据种提炼变量的主要信息,即统计量。可以反映出业务发展状况及影响因素,是商业智能和数据可视化的基础。
数据分为分类变量和连续变量。分类变量是维度指标,用于分组;连续变量是度量指标。
2.2 统计推断与统计建模
通过描述性统计发现的影响因素是否为规律,需要进行统计检验。统计推断与统计建模是建立解释变量与被解释变量之间可解释的、稳定的、有因果关系的表达式。

3 数据挖掘的技术与方法
根据业务运用场景,将数据挖掘算法分为5类:预测模型、聚类模型、推荐算法、复杂网络、时间序列。
- 预测模型
根据被解释变量Y的度量类型,预测模型分为分类模型、估计模型。
Y —> 分类变量 —> 分类模型
Y —> 连续变量 —> 估计模型
- 分类模型
分类模型可分为排序类模型(评分卡)和决策类模型(分类器)。
如果Y为主观的人为定义变量,如信用评分、流失预测、营销响应等,则为排序类模型,输出的结果是类别的概率,常采用逻辑回归建立排序类模型;
如果Y为客观的精确变量,如交易欺诈、人脸识别、声音识别等,则为决策类模型,在进行预测时将会输出准确的类别而非类别的概率,常见方法有贝叶斯网络、最近邻域(KNN算法)、支持向量机(SVM)。
分类模型的评估方法:
分为样本内评估和样本外评估。样本内评估用于检验的数据与建模数据属于同源数据;样本外评估使用下一期的滚动数据。
| 分类模型类型 | 统计指标 |
|---|---|
| 决策(Decisions) | 准确度、召回率、命中率、利润、成本等 |
| 排序(Rankings) | ROC曲线、K-S统计量、提升度等 |
- 估计模型
线性回归、回归树、神经网络
其中决策树、神经网络、组合算法(集成学习)均可适用。
- 聚类模型
聚类模型有两种运用场景:客户细分、识别异常。客户细分可以发现数量客观模式;识别异常用于寻找有差异的个体。
4 实例——构建促销营销策略数据模型
import pandas as pd
import numpy as npp
1. 导入数据
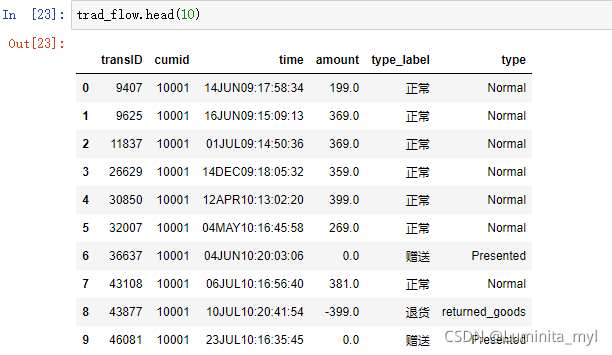
trad_flow=pd.read_csv(r'D:\案例\《Python数据科学技术详解与商业实践》PDF+源代码+八大案例\《Python数据科学技术详解与商业实践》PDF+源代码+八大案例\源代码\Python_book\1Introduction\RFM_TRAD_FLOW.csv',encoding='gbk')
F_trans.head()
2. 通过 RFM方法* 建立模型
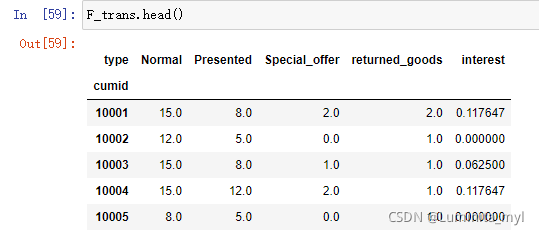
通过计算F(所消费产品中打折产品的占比),反映客户对打折产品的偏好。
F=trad_flow.groupby(['cumid','type'])[['transID']].count()
F_trans=pd.pivot_table(F,index='cumid',columns='type',values='transID')
F_trans['Special_offer']=F_trans['Special_offer'].fillna(0)
F_trans['interest']=F_trans['Special_offer']/(F_trans['Special_offer']+F_trans['Normal'])
F_trans.head()
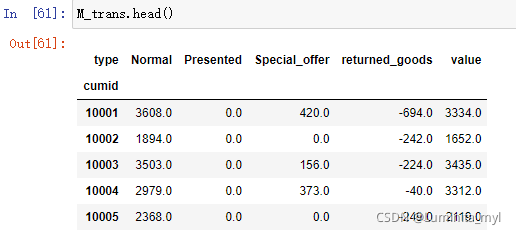
同样的,计算M(客户消费总量和):反应客户的价值信息
M=trad_flow.groupby(['cumid','type'])[['amount']].sum()
M_trans=pd.pivot_table(M,index='cumid',columns='type',values='amount')
M_trans['Special_offer']=M_trans['Special_offer'].fillna(0)
M_trans['returned_goods']=M_trans['returned_goods'].fillna(0)
M_trans['value']=M_trans['Normal']+M_trans['Special_offer']+M_trans['returned_goods']
M_trans.head()
!!通过计算R,提取出最新消费时间,反应客户是否为沉默客户
#定义一个从文本转化为时间的函数
from datetime import datetime
import time
def to_time(t):
out_t=time.mktime(time.strptime(t, '%d%b%y:%H:%M:%S')) ########此处修改为时间戳方便后面qcut函数分箱
return out_t
a="14JUN09:17:58:34"
print(to_time(a))
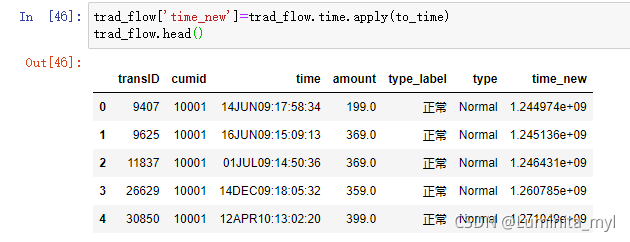
trad_flow['time_new']=trad_flow.time.apply(to_time)
trad_flow.head()
#选择最近的消费时间
R=trad_flow.groupby(['cumid'])[['time_new']].max()
R.head()
3. 构建模型,筛选目标客户 (???)
from sklearn import preprocessing
threshold = pd.qcut(F_trans['interest'], 2, retbins=True)[1][1]
binarizer = preprocessing.Binarizer(threshold=threshold)
interest_q = pd.DataFrame(binarizer.transform(F_trans['interest'].values.reshape(-1, 1)))
interest_q.index=F_trans.index
interest_q.columns=['interest']
threshold = pd.qcut(M_trans['value'], 2, retbins=True)[1][1]
binarizer = preprocessing.Binarizer(threshold=threshold)
value_q = pd.DataFrame(binarizer.transform(M_trans['value'].values.reshape(-1, 1)))
value_q.index=M_trans.index
value_q.columns=['value']
threshold = pd.qcut(R['time_new'], 2, retbins=True)[1][1]
binarizer = preprocessing.Binarizer(threshold=threshold)
time_new_q = pd.DataFrame(binarizer.transform(R['time_new'].values.reshape(-1, 1)))
time_new_q.index=R.index
time_new_q.columns=['time']
analysis=pd.concat([interest_q,value_q,time_new_q],axis=1)
#analysis['rank']=analysis.interest_q+analysis.interest_q
analysis = analysis[['interest','value','time']]
analysis.head()
label = {
(0,0,0):'无兴趣-低价值-沉默',
(1,0,0):'有兴趣-低价值-沉默',
(1,0,1):'有兴趣-低价值-活跃',
(0,0,1):'无兴趣-低价值-活跃',
(0,1,0):'无兴趣-高价值-沉默',
(1,1,0):'有兴趣-高价值-沉默',
(1,1,1):'有兴趣-高价值-活跃',
(0,1,1):'无兴趣-高价值-活跃'
}
analysis['label'] = analysis[['interest','value','time']].apply(lambda x: label[(x[0],x[1],x[2])], axis = 1)
analysis.head()
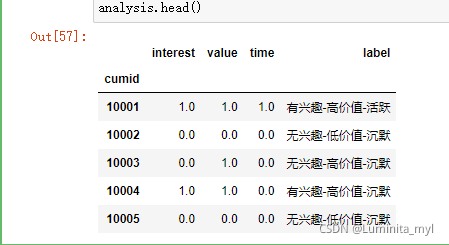
*RFM模型:从交易流水数据中获取信息的最简单而通用的方法称为RFM模型。R代表最后一次消费时间,F代表一段时期内消费的频次,M代表一段时期内消费总金额。通过交易流水数据通过RFM模型得到信息后,将每个信息进行二分类,得到客户分群。
智能推荐
<!--[if lte IE 6]> CSS IE 判断语句-程序员宅基地
文章浏览阅读56次。<!--[if lte IE 6]><![endif]-->IE6及其以下版本可见<!--[if lte IE 7]><![endif]-->IE7及其以下版本可见<!--[if IE 6]><![endif]-->只有IE6版本可见<![if !IE]><![endif]>除了IE以外的版本<!..._
英集芯ip6809规格书pdf芯片文档详解及典型电路原理图_is6809-程序员宅基地
文章浏览阅读329次。英集芯ip6809芯片是一款无线充电发送端控制器SOC芯片,兼容WPC Qi v1.2.4新标准。支持2-3线圈无线充电发射端应用,支持A28线圈、MP-A8线圈,支持客户线圈定制方案,支持5W、苹果7.5W、三星10W、15W无线充电发射。_is6809
【Matlab】三次样条插值实现_三次样条插值matlab-程序员宅基地
文章浏览阅读1.9w次,点赞20次,收藏168次。敲了一下午终于把代码敲完了,留念。文章目录题目:三次样条插值程序1:Gauss列主元消去法程序2:三次样条插值程序3:主函数及输入数据题目:三次样条插值程序1:Gauss列主元消去法function [X] = Gauss_elimination(A, Y) %% 参数初始化 matrix = [A, Y]; [n,m] = size(matrix); % 矩阵大小 l = zeros(n,n); % 比例系数矩阵 X =_三次样条插值matlab
(一)Thanos:引入Thanos 架构_thanos 查询慢-程序员宅基地
文章浏览阅读1.3k次,点赞3次,收藏5次。一、问题背景及解决方案问题1、Prometheus 本身只支持单机部署,没有自带支持集群部署,也就不支持高可用以及水平扩容,在大规模场景下,最让人关心的问题是它的存储空间也受限于单机磁盘容量,磁盘容量决定了单个 Prometheus 所能存储的数据量,数据量大小又取决于被采集服务的指标数量、服务数量、采集速率以及数据过期时间。在数据量大的情况下,我们可能就需要做很多取舍,比如丢弃不重要的指标、降低采集速率、设置较短的数据过期时间(默认只保留15天的数据,看不到比较久远的监控数据)。解决方案:①集中数据_thanos 查询慢
python识别图片中数字_Python图像处理之图片验证码识别-程序员宅基地
文章浏览阅读509次。在上一篇博客Python图像处理之图片文字识别(OCR)中我们介绍了在Python中如何利用Tesseract软件来识别图片中的英文与中文,本文将具体介绍如何在Python中利用Tesseract软件来识别验证码(数字加字母)。我们在网上浏览网页或注册账号时,会经常遇到验证码(CAPTCHA),如下图:本文将具体介绍如何利用Python的图像处理模块pillow和OCR模块pytesseract来..._python识别图片中的字母和数字
8051单片机指令系统有哪几种寻址方式?_8051寻址方式-程序员宅基地
文章浏览阅读5.5k次。8051单片机指令系统有哪几种寻址方式?寄存器寻址、直接寻址、立即寻址、寄存器间接寻址、变址寻址、相对寻址、位寻址。寄存器寻址:以通用寄存器的内容为操作数的寻址方式。通用寄存器为A、B 、DPTR以及R0~R7 。例:CLR A ;A←0INC DPTR ;DPTR←DPTR+1 ADD R5,# 20H ;R5←#20H+R5。在8051单片机中,没有专门的通用硬件寄存器,而是把内部数据RAM区中0_8051寻址方式
随便推点
基于ThinkPhp6+Vue+ElementUI通用后台管理系统_thinkphp6+layui后台管理系统-程序员宅基地
文章浏览阅读7.9k次,点赞2次,收藏24次。一款 PHP 语言基于ThinkPhp6、Vue、ElementUI等框架精心打造的一款模块化、插件化、高性能的前后端分离架构敏捷开发框架,可用于快速搭建前后端分离后台管理系统,本着简化开发、提升开发效率的初衷,目前框架已集成了完整的RBAC权限架构和常规基础模块,前端Vue端支持多主题切换,可以根据自己喜欢的风格选择想一个的主题,实现了个性化呈现的需求;_thinkphp6+layui后台管理系统
Maven配置本地库加载ojdbc14-10.2.0.4.0.jar文件(公司项目下载时缺失或者自己建项目缺失均可这样做)...-程序员宅基地
文章浏览阅读202次。2019独角兽企业重金招聘Python工程师标准>>> ..._ojdbc14-10.2.0.4.0.jar
pytdx 获取板块指数_能否增加一个通过股票代码,板块指数代码获得中文名称的接口?...-程序员宅基地
文章浏览阅读424次。T0002/hq_cache/shex.tnfT0002/hq_cache/szex.tnf这个解码就是。/***************************************************股票代码列表和股票名称T0002/hq_cache/shex.tnfT0002/hq_cache/szex.tnf**************************************..._pytdx 查看指数
ARMv8/ARMv9架构入门到精通-学习方法_armv8从入门到精通-程序员宅基地
文章浏览阅读173次。想不想一夜暴富?拥有很多很多钱,买很多很多房,工作也不忙,无压力,不用亲自Coding和Debug,还有大把大把的时间在CSDN上挥霍… 如果真有此想法,那么想想就可以了。本博客/视频不会提供实现上述理想的方法,一点点边都不沾。本系列文章和视频重在为初学者指点迷津(大佬请绕行),让您,尽快地成为行业的大牛,薪资翻个好几。_armv8从入门到精通
技术干货 | 一文弄懂差分隐私原理!-程序员宅基地
文章浏览阅读9.6k次,点赞21次,收藏175次。图1 随机算法在邻近数据集上的概率差分隐私有两个重要的优点:差分隐私假设攻击者能够获得除目标记录以外的所有其他记录信息,这些信息的总和可以理解为攻击者能够掌握的最大背景知识,在这个强大的假设下,差分隐私保护无需考虑攻击者所拥有的任何可能的背景知识。差分隐私建立在严格的数学定义上,提供了可量化评估的方法。因此差分隐私保护技术是一种公认的较为严格和健壮的隐私保护机制。_差分隐私
在myeclipse 中部署自己的第一个jsp成功_应用myeclipse开发工具创建第一个jsp项目在页面输出1~100的偶数和步数运行后-程序员宅基地
文章浏览阅读744次。以一个很简单的 Web 应用来说明使用 MyEclipse 的 Web 服务器配置,应用部署和调试过程。 一、准备开发工具 这里使用 Eclipse 3.1.2 和 MyEclipse4.1.1 ,当然 Java 通常都是用来开发网络应用的,那么 Web 服务器也就少不了了,这里使用tomcat5.0版本,当然如果你没有 J2SDK 那么所有的程序都没法编_应用myeclipse开发工具创建第一个jsp项目在页面输出1~100的偶数和步数运行后