SpringBoot配置Druid_springboot druid配置-程序员宅基地
技术标签: spring boot java # Java进阶 # Java框架
目录
Druid是Java语言中最好的数据库连接池。Druid能够提供强大的监控和扩展功能。
Druid 是一个 JDBC 组件库,包含数据库连接池、SQL Parser 等组件, 被大量业务和技术产品使用或集成,经历过最严苛线上业务场景考验,是你值得信赖的技术产品。
一、JDBC连接数据库
1. 创建项目,导入需要的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>2. 配置数据源
server:
port: 8085
spring:
application:
name: user-service
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/hm49?serverTimezone=UTC&useUnicode=true@characterEncoding=utf-8
username: root
password: root3. 测试连接
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
@SpringBootTest
class DataApplicationTests {
@Autowired
DataSource dataSource;
/**
* 验证数据库连接
* @throws Exception
*/
@Test
void testConnection() throws Exception {
System.out.println(dataSource.getClass());
Connection connection = dataSource.getConnection();
System.out.println(connection);
connection.close();
}
/**
* 验证连接池的配置信息,是否生效
* @throws Exception
*/
/*@Test
void contextLoads() throws Exception {
System.out.println(dataSource.getClass());
DruidDataSource druidDataSource = (DruidDataSource) dataSource;
System.out.println("initSize:" + druidDataSource.getInitialSize());
System.out.println("maxSize:" + druidDataSource.getMaxActive());
Connection connection = dataSource.getConnection();
System.out.println(connection);
connection.close();
}*/
}4. 项目启动成功,能够看出连接信息
默认配置的数据源为class com.zaxxer.hikari.HikariDataSource
二、配置数据库连接池Druid
1. 添加druid的maven配置
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.12</version>
</dependency>2. 添加数据源的配置
server:
port: 8085
spring:
application:
name: user-service
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/hm49?serverTimezone=UTC&useUnicode=true@characterEncoding=utf-8
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource3. 重新执行测试代码,发现数据库连接池已经更改
此时配置的数据源为com.alibaba.druid.pool.DruidDataSource
4. 添加Druid其他增强的配置
官网介绍如下:常见问题 · alibaba/druid Wiki · GitHub
server:
port: 8085
spring:
application:
name: user-service
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/hm49?serverTimezone=UTC&useUnicode=true@characterEncoding=utf-8
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
#Spring Boot 默认是不注入这些属性值的,需要自己绑定
#druid 数据源专有配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
#配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入
#如果允许时报错 java.lang.ClassNotFoundException: org.apache.log4j.Priority
#则导入 log4j 依赖即可,Maven 地址: https://mvnrepository.com/artifact/log4j/log4j
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
#第一步连接数据库
#第二步配置连接池+type
#第三部测试查询jdbcTemplate.queryForList(sql);
#第四部添加连接池配置5. 写配置类加载Druid的配置
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.servlet.Servlet;
import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class DruidConfig {
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druidDataSource(){
return new DruidDataSource();
}
@Bean
public ServletRegistrationBean druidServletRegistrationBean(){
ServletRegistrationBean<Servlet> servletRegistrationBean = new ServletRegistrationBean<>(new StatViewServlet(),"/druid/*");
Map<String,String> initParams = new HashMap<>();
initParams.put("loginUsername","admin");
initParams.put("loginPassword","123456");
//后台允许谁可以访问
//initParams.put("allow", "localhost"):表示只有本机可以访问
//initParams.put("allow", ""):为空或者为null时,表示允许所有访问
initParams.put("allow","");
//deny:Druid 后台拒绝谁访问
// initParams.put("msb", "192.168.1.20");//表示禁止此ip访问
servletRegistrationBean.setInitParameters(initParams);
return servletRegistrationBean;
}
//配置 Druid 监控 之 web 监控的 filter
//WebStatFilter:用于配置Web和Druid数据源之间的管理关联监控统计
@Bean
public FilterRegistrationBean webStatFilter() {
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
//exclusions:设置哪些请求进行过滤排除掉,从而不进行统计
Map<String, String> initParams = new HashMap<>();
initParams.put("exclusions", "*.js,*.css,/druid/*");
bean.setInitParameters(initParams);
//"/*" 表示过滤所有请求
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
}
6. 引入log4j的依赖
<!-- https://mvnrepository.com/artifact/log4j/log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>7. 测试一下数据库连接
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
public class JDBCController {
@Autowired
JdbcTemplate jdbcTemplate;
@RequestMapping("selectAll")
public List<Map<String,Object>> selectAll(){
String sql = "select * from tb_user";
List<Map<String, Object>> maps = jdbcTemplate.queryForList(sql);
return maps;
}
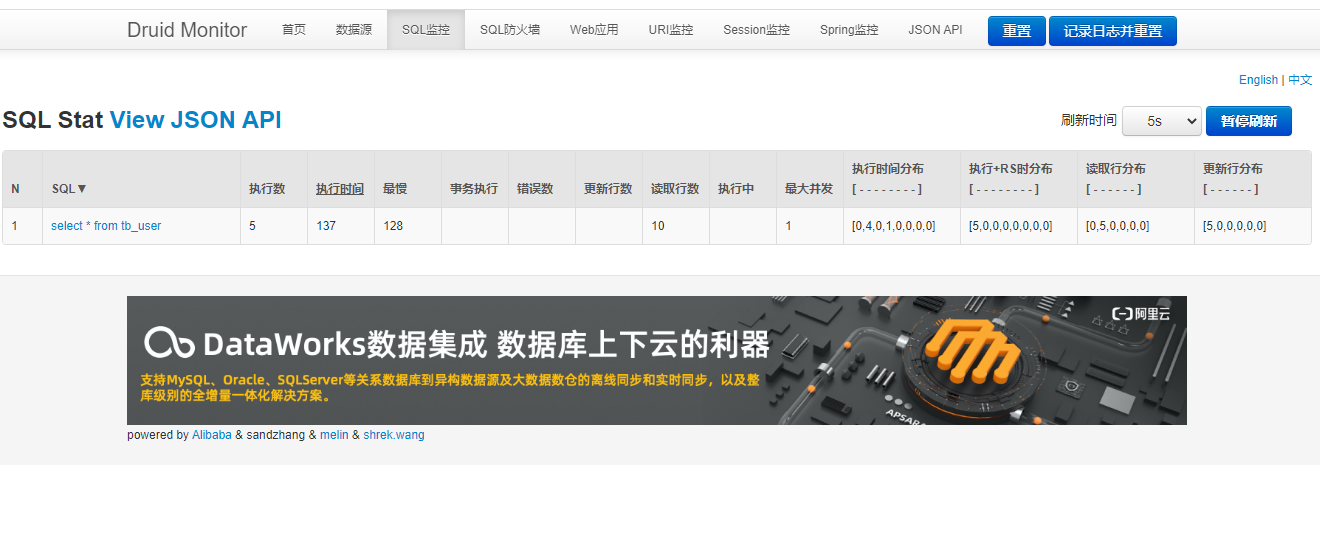
}8. 查看控制台的监控信息
http://localhost:8085/druid/login.html

如果本篇博客对您有一定的帮助,大家记得留言+点赞+收藏哦
智能推荐
上采样(upsample)-程序员宅基地
文章浏览阅读1.7k次。转载链接:https://blog.csdn.net/wydbyxr/article/details/83819089上采样(upsample)的方法 在神经网络中,扩大特征图的方法,即upsample/上采样的方法 1)unpooling:恢复max的位置,其余部分补零 2)deconvolution(反卷积):先对input补零,再conv 3)插值方法,双线性插值等; ..._upsample
ESP8266开发之旅 网络篇⑪ WebServer——ESP8266WebServer库的使用_esp8266开发之旅 网络篇 webserver——esp8266webserver库的使用-程序员宅基地
文章浏览阅读2.6w次,点赞28次,收藏25次。1. 前言 在前面章节的博客中,博主介绍了ESP8266WiFi库 Tcp server的用法,并模拟了Http webserver的功能。但是,可以看出通过Tcp server 处理http请求,我们需要自己解析请求协议以及判断各种数据,稍微不小心就很容易出现错误。 那么有没有针对Http webserver操作的库呢?答案肯定是有的,这就是博主本篇需要跟大家讲述的知识——ESP..._esp8266开发之旅 网络篇 webserver——esp8266webserver库的使用
Betaflight通过OSD设置摄像头参数(F*V Camera Control)_平头哥摄像头osd调参-程序员宅基地
文章浏览阅读6.3k次。简介在无人机飞行中,有些摄像头支持通过飞控的OSD界面进入到摄像头系统,从而设置摄像头的相关参数,如白平衡、亮度、个性化字符信息等参数。(F*V Camera Control)设置步骤DALRC F405飞控支持此项功能,需要配合OSD界面进行,USB连接后进入Betaflight Configurator的CLI命令模式下按如下步骤设置命令: 1.映射端口(飞控固件内已默认映射..._平头哥摄像头osd调参
知三角形三边和两点坐标计算另外一点的坐标_已知两点坐标以及三边边长-程序员宅基地
文章浏览阅读6.8k次,点赞4次,收藏27次。问题:已知三角形A、B点的坐标和三边长,求C点坐标,如图: 原理:方位角和三角函数关系求解过程:计算边AC和AB的夹角θ,即: 2. 计算边AB与x轴的夹角根据方位角一般公式 ..._已知两点坐标以及三边边长
【Python计量】自相关性(序列相关性)的检验_用残差图诊断模型的误差项是否存在自相关。-程序员宅基地
文章浏览阅读1.4w次,点赞11次,收藏97次。多元线性回归模型的基本假设之一就是模型的随机干扰项相互独立或不相关。如果模型的随机感染项违背了相互独立的基本假设,则称为存在序列相关性(自相关性)。我们以伍德里奇《计量经济学导论:现代方法》的”第12章 时间序列回归中序列相关和异方差性“的案例12.4为例,使用BARIUM中的数据来进行序列相关性的检验。import wooldridge as wooimport pandas as pdimport numpy as npimport statsmodels.api as smimport s_用残差图诊断模型的误差项是否存在自相关。
neo4j使用详解(十六、索引之语义索引<向量索引>——最全参考)_neo4j如何向量化查询-程序员宅基地
文章浏览阅读772次,点赞22次,收藏28次。节点矢量搜索索引在Neo4j 5.11中作为公测版本发布,在Neo4j 5.13中作为通用版本发布。向量索引允许用户从大型数据集查询向量嵌入。嵌入是数据对象(如文本、图像、音频或文档)的数字表示。例如,文本中的每个单词或标记通常表示为高维向量,其中每个维表示单词含义的某个方面。语义上相似或相关的词通常用向量空间中彼此更接近的向量来表示。这允许像加法和减法这样的数学运算带有语义意义。例如,“国王”减去“男人”加上“女人”的向量表示可能接近于“女王”的向量表示。_neo4j如何向量化查询
随便推点
WPF程序_spy++分析wpf程序-程序员宅基地
文章浏览阅读597次。WPF程序通过spy++只有一个窗口句柄, 下面的子控件是看不到句柄的。所以也就没办法通过Win32 API FindWindow来查找子控件了。 如果您的代码没有经过代码混淆的话,别人是可以用ILSPY来查看其exe的代码的。_spy++分析wpf程序
77. 组合_77.组合-程序员宅基地
文章浏览阅读64次。77. 组合https://leetcode-cn.com/problems/combinations/难度中等748给定两个整数n和k,返回范围[1, n]中所有可能的k个数的组合。你可以按任何顺序返回答案。示例 1:输入:n = 4, k = 2输出:[ [2,4], [3,4], [2,3], [1,2], [1,3], [1,4],]示例 2:输入:n = 1, k = 1输出:[[1]]提示:1 &l..._77.组合
Android开发都需要使用什么语言?_安卓开发的编程语言-程序员宅基地
文章浏览阅读2.2w次,点赞9次,收藏16次。Android是以Linux为核心的手机操作平台,作为一款开放式的操作系统,随着Android的快速发展,如今已允许开发者使用多种编程语言来开发Android应用程序,而不再是以前只能使用Java开发Android应用程序的单一局面。那么,Android系统都能使用哪些语言来开发呢? 在Android中,开发者可以使用Java作为编程语言来开发应用程序,也可以通过Android N_安卓开发的编程语言
四级单词列表_四级单词a到d有多少个-程序员宅基地
文章浏览阅读1.7k次。四级单词列表置顶2018年11月09日 13:27:35多多单词阅读数:5551、四级英语单词(1-100)2、四级英语单词(101-200)3、四级英语单词(201-300)4、四级英语单词(301-400)5、四级英语单词(401-500)6、四级英语单词(501-600)7、四级英语单词(601-700)8、四级英语单词(701-800)9、四级..._四级单词a到d有多少个
linux电子设计软件,集成电路eda软件-程序员宅基地
文章浏览阅读357次。立创EDA软件是一款用于电子线路设计的仿真设计工具,立创EDA为用户提供了原理图和PCB模块,用户可以轻松方便的绘制原理图,同时多层板流畅布线,能够有效提升使用者工作效率,减轻工作压力。软件介绍立创EDA是一款电子设计仿真软件,用户可以在这款软件上进行电子线路的仿真设计,其中软件自带了很多功能,例如电气工具等,以此达到让用户快速设计电路图的效果。软件功能1、原理图绘制:方便快速的绘制原理图,轻松分..._ltspice linux
Eyeriss中的RS(行固定)数据流-程序员宅基地
文章浏览阅读3.6k次,点赞45次,收藏59次。Eyeriss中的RS(行固定)数据流Eyeriss想必大家都读过,但是你在第一次读v1的时候可能并不清楚他所讲的RS数据流具体是什么样的。笔者在这里专门对Eyeriss v1中的RS(行固定)数据流进行详细举例说明。原文中有关RS数据流的部分:“Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks”中的第四段。“Eyeriss: A Spatial Archite_eyeriss