十五. MySQL explain 执行计划_start temporary-程序员宅基地
目录
一. EXPLAIN 执行计划基础解释
- 解释: 使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySql是如何处理接收的SQL语句的,然后进行指定的修改
- 通过EXPLAIN+SQL语句,查看该语句的执行计划,执行顺序,可以获取到当前执行的SQL语句的查询耗时时间,索引是否生效,使用了几个索引等…,分析优进行优化,借用大神整理的EXPLAIN用法,EXPLAIN作用
通过EXPLAIN中的id列可以查看表的读取顺序,id越大优先级越高
通过EXPLAIN中select_type列可以查看数据读取操作的操作类型,简单查询,主查询,子查询,UNION或UNION RESULT等
通过EXPLAIN中的possible_keys列可以查看哪些索引可能被
通过EXPLAIN中的key列可以查看那个索引被实际使用
通过EXPLAIN中的type列可以查看当前执行的sql是否走的全表扫描sql级别,由高到低:system>const>eq_ref>ref>range>index>ALL
通过EXPLAIN中的rows列可以查看每张表有多少行被优化器查询
- 几个比较重要的列: id, type, key,rows 与Extra
#where条件中snapshot_id 为主键,通过EXPLAIN分析执行计划中的type为const,possible_keys为PRIMARY 使用主键索引
EXPLAIN SELECT * FROM express_customer_snapshot where snapshot_id='123456';
#where条件中'customer_name'字段添加了普通索引,EXPLAIN查看执行计划type为 ref, possible_keys 为index_name
EXPLAIN SELECT * FROM express_customer_snapshot where customer_name='bbb';
#查看EXPLAIN执行计划,possible_keys为'PRIMARY,index_name'使用了两个索引
EXPLAIN SELECT * FROM express_customer_snapshot where snapshot_id='123456' and customer_name='bbb';
#查看EXPLAIN执行计划,where条件字段中没有添加索引,type为ALL全表扫描
EXPLAIN SELECT * FROM express_customer_snapshot where operate_user_id='ccc';
- 示例:
二. EXPLAIN 字段解释
- 我们通过EXPLAIN+执行SQL,查看MySql是如何处理接收优化SQL语句的,会显示一个table,其中包含这些字段

id
- 此处的id代表select查询的序列号,表示查询中执行的select操作表的顺序,id值越大约先被执行,相同id从上往下顺序执行,有三种情况: id相同, id不同, id相同,与不同的同时存在,根据id我们可以观察到表的先后读取顺序
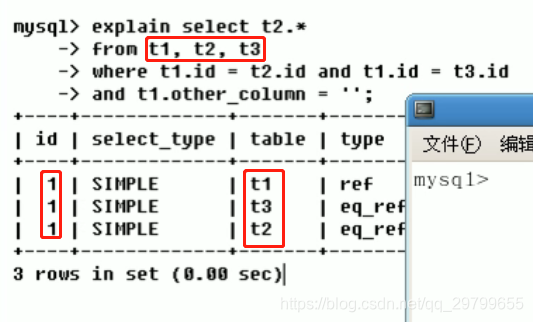
- 根据下图explain+sql举例id相同情况: from t1, t2, t3三张表,explain输出的执行计划中三个id都为1,表示按照加载顺序先后执行,注意点加载顺序并不是值from的顺序,这是mysql优化后的加载顺序
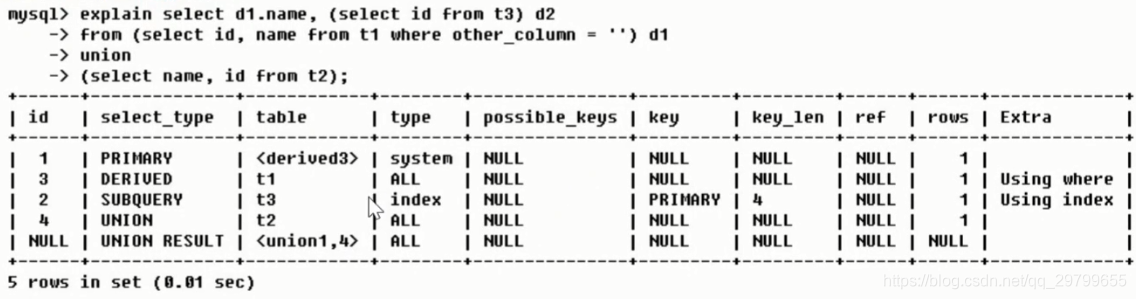
- 根据下图explain+带子查询sql举例id不同情况, 首先了解id越大越先执行,select_type中PRIMARY代表主查询,SUBQUERY代表子查询,table代表加载顺序,我自己理解的是越括号里面的子查询越先执行,所以先执行的t3子查询,然后t1子查询,然后t2主查询
- 根据下图explain+带子查询带虚表sql举例相同不同id同时存在情况,首先观察发现table列中有< derived >叫做"衍生",可以理解为通过from t3 表中查询出的数据虚拟出来的s1表,而< derived2 > 后面的"2"对应id中的2,该表是通过id为2对应的table中的表衍生出来的,然后在看执行顺序,先执行t3,然后t2跟derived2的id相同,从上往下顺序执行

select_type
- select_type 通过select_type可以了解数据读取操作类型,主要用于区别普通查询,联合查询,子查询等: SIMPLE, PRIMARY, SUBQUERY, DERIVED, UNION, UNION RESULT,
- SIMPLE: 简单的,简单的select查询,不包含子查询,或UNION
- PRIMARY: 主查询,若执行的sql语句中包含子查询,最外层的查询标记为主查询
- SUBQUERY: 子查询(自己理解为括号里面的)
- DERIVED: 衍生的,在from中包含虚表,MySql会递归执行这些子查询,把结果放入临时表中
- UNION: 若第二个select出现在UNION之后,则被标记为UNION,若UNION在from子句的自查询中,外层的from被标记为DERIVED
- UNION RESULT: 表示执行的SQL中有在UNION表获取结果的操作(也可以理解为两个UNION操作后合并结果集)

table
表示该行的数据来自于哪一张表
type
- type 包含: 从最好到最差: system>const>eq_res>ref>fulltext>ref_or_null>index_merge>unique_subquery>index_subquery>range>index>ALL
- 常见的是 system>const>eq_ref>ref>range>index>ALL,百万级表type为ALL需要优化,一般来说,至少要达到range级别,最好能到ref级别
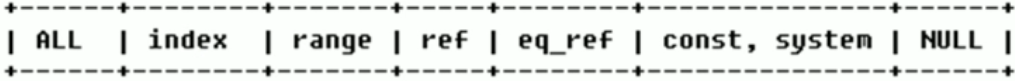
- system: 表只有一行记录(等于mysql的系统表),是const类型的一种特别变种,平时不会出现
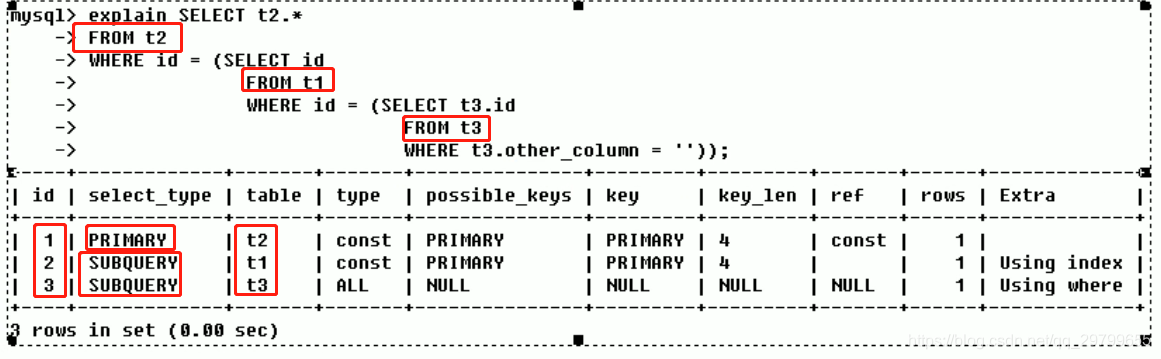
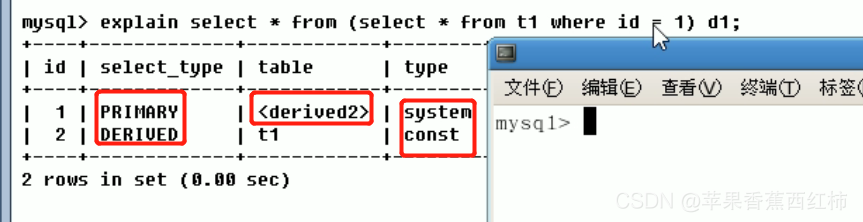
- const: 表示通过索引,一次就找到了记录,const通常出现与使用了primary key或unique索引的sql,(下图中from t1 使用id主键的子查询,显示的type为const, 由于id=1衍生表d1的type显示的是system类型)
- eq_ref: 唯一性索引扫描, 对于每个索引键,表中只有一条匹配的记录数据,常见于使用主键,或唯一索引的sql
- ref: 非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,但是它可能会返回多个符合条件的数据,属于查找合扫描的混合体(简单举例: 通过普通索引查询数据,数据库匹配到有多行)
- range: 只检索给定范围的行,使用一个索引来选择行,简单理解为通过索引字段进行范围查询,例如between,< , >,或in等,这种范围查询比全表扫描要好,因为只需要索引的开始点与结束点,不会进行全表扫
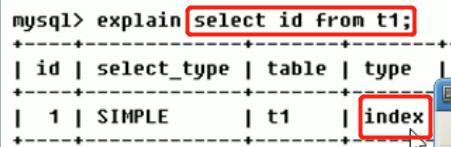
- index: Full Index Scan遍历全表索引匹配, index与ALL区别在于index类型只遍历索引树,而ALL是从磁盘读取,index比ALL快
- ALL: Full Table Scan 遍历全表匹配
possible_keys 与 key 与 key_len
- possible_keys: 表示该sql执行是可能使用到的索引,查询涉及到的索引,都会被列出,但是不一定被实际使用
- key: 表示该sql执行时实际使用到的索引,如果为NULL表示没有使用索引,
- 注意点: 若查询中使用了覆盖索引,则该索引只出现在key列表中
- key_len:表示索引中使用的字节数,可通过该列计算使用的索引的长度,在不损失精度的情况下,长度越小越好,注意点ken_len显示的值为"索引字段的最大可能长度",并非实际长度,是根据表定义得出来的,不是表内检索出的
ref
- ref: 当执行的select sql 使用到索引时,应用到该索引上的值,没有使用到索引时为NULL
- 根据下图举例: from t1, t2, 首先看t2表没有使用到索引,ref为NULL, t1表中使用到了idx_col1_col2索引,ref中使用到了shared库下的t2表中的col1字段的值,与const一个常量,分别对应where中的两个条件"where t1.col1 = t2.col1" 与 "t1.col2 =‘ac’ ",(当直接传递常量时例如’ac’在ref中显示的是const)

rows
rows: 根据表统计信息及索引使用情况,大致估算出当前sql查询找到结果需要读取的行数
Extra
- Extra:扩展列,包含了一下不适合在其它列中显示,又十分重要的信息,包含了: Using filesort, Using temporary, USING index, Using where, using join buffer, impossible where, select tables optimized away, distinct…
Using filesort
- Using filesort: sql执行是出现了文件内排序,说明MySql对数据会使用一个外部的索引进行排序而不是按照表内的索引顺序进行读取,简单来说,我们对一个表添加了索引字段,正常情况下应该按照该索引进行排序的,但是由于某种情况MySql并没有按照索引去排序,而是在内部又重新按照某种规则又排序了一次,出现这个东西不好,如果可以尽快优化
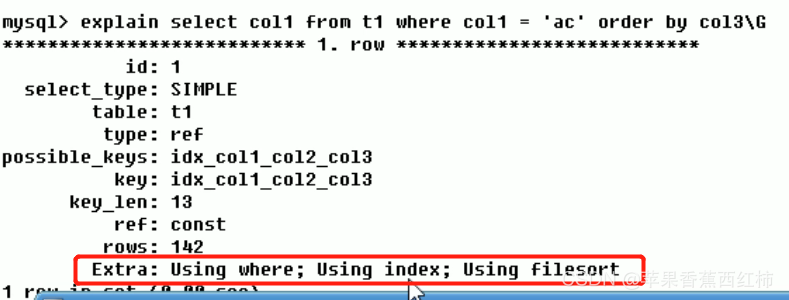
- 举例:from t1表,该表中创建了"index_col1_col2_col3"的符合索引,在查询时where了col1,order by了col3字段 (下图中的select结尾为"\G",意思是输出table为竖版key value键值对,没啥实际意义,重点观察下方的Extra), 在Extra列中输出了: Using where(表示当前sql使用到了where条件), Using index(表示当前sql使用到了索引),最终后面还输出了Using filesort(表示使用到了文件内排序),自己理解: 在执行该sql时,where条件col1中创建了索引,所以Extra有输出Using index,但是后面的"order by col3"排序没有使用到我们自己创建的所有,MySql自己内部又重新排了一次,出现这种情况的原因是我们创建的符合索引为(col1_col2_col3),但实际过滤排序的条件,少了中间的col2
- 添加联合索引(index_col1_col2_col3), where col1, order by col2,col3 与联合索引对应,没有出现文件内排序

Using temporary
- Using temporary: sql执行时使用了临时表用来保存中间结果,常见于order by, group by,尽量不要出现
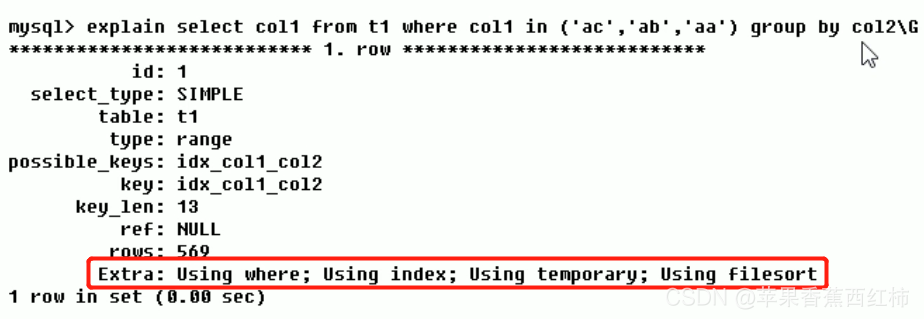
- 举例:from t1表,该表添加了 index_col1_col2联合索引, where col1 in条件, group by col2 条件, 查看Extra,不但出现了文件内排序,也出现了临时表(虽然存在index_col1_col2联合索引,但是group by时,只根据col2一个字段进行分组的,利用不上我们的索引)
- 该表添加了 index_col1_col2联合索引,group by中也是根据col1,col2两个条件进行分组的,没有出现临时表

USING index
- 表示当前执行的sql使用了覆盖索引,减少数据库的io操作,可以提高效率(覆盖索引:select的列的个数,顺序,刚好对应我们创建的某个索引或联合索引,InnoDB通过非聚集索引查询时,通过索引即可返回数据,减少了通过非聚集索引叶子节点拿到聚集索引key,然后查到聚集索引,找到聚集索引的叶子节点拿到数据的步骤)
- 注意点:当出现USING index同时也出现了 USING where,表示索引被用来执行索引键值的查找,如果没有同时出现表示索引用来读取数据,而非执行查找动作(是不是同时出现了 USING where 说明where条件中使用了索引,如果没有出现说明where没有使用到索引?)
USING index condition
索引下推
USING where
表示当前执行的 sql 中存在where条件
USING join buffer
表示当前执行的 sql 使用到了链接缓存
Using intersect
Using union
Using sotr union
Zero limit
Impossible where
- 表示where子句的值总是false,不能用来获取任何元组
- 举例: 假设一条sql : “SELECT * FROM table WHERE name =‘aaa’ AND name =‘bbb’ " , where的name条件等于"aaa"又等于"bbb”,让MySql错乱了
select tables optimized away
表示在没有 group by 的情况下,基于索引优化 MIN/MAX操作,或者对应没有MyISAM存储引擎优化COUNT(*)操作时不必等到执行阶段再进行计算,查询执行计划生成阶段及完成优化
distinct
表示优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作
Start temporary, End temporary
LooseScan
FirstMatch
三. show warnings
- “show warnings” 命令是一个诊断语句,用于显示由于在当前会话中执行语句而导致的情况(error、waring和note)信息,只 针对select语句,也可以在EXPLAIN后面使用,用以显示EXPLAIN生成的扩展信息
智能推荐
什么是内部类?成员内部类、静态内部类、局部内部类和匿名内部类的区别及作用?_成员内部类和局部内部类的区别-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏42次。一、什么是内部类?or 内部类的概念内部类是定义在另一个类中的类;下面类TestB是类TestA的内部类。即内部类对象引用了实例化该内部对象的外围类对象。public class TestA{ class TestB {}}二、 为什么需要内部类?or 内部类有什么作用?1、 内部类方法可以访问该类定义所在的作用域中的数据,包括私有数据。2、内部类可以对同一个包中的其他类隐藏起来。3、 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。三、 内部类的分类成员内部_成员内部类和局部内部类的区别
分布式系统_分布式系统运维工具-程序员宅基地
文章浏览阅读118次。分布式系统要求拆分分布式思想的实质搭配要求分布式系统要求按照某些特定的规则将项目进行拆分。如果将一个项目的所有模板功能都写到一起,当某个模块出现问题时将直接导致整个服务器出现问题。拆分按照业务拆分为不同的服务器,有效的降低系统架构的耦合性在业务拆分的基础上可按照代码层级进行拆分(view、controller、service、pojo)分布式思想的实质分布式思想的实质是为了系统的..._分布式系统运维工具
用Exce分析l数据极简入门_exce l趋势分析数据量-程序员宅基地
文章浏览阅读174次。1.数据源准备2.数据处理step1:数据表处理应用函数:①VLOOKUP函数; ② CONCATENATE函数终表:step2:数据透视表统计分析(1) 透视表汇总不同渠道用户数, 金额(2)透视表汇总不同日期购买用户数,金额(3)透视表汇总不同用户购买订单数,金额step3:讲第二步结果可视化, 比如, 柱形图(1)不同渠道用户数, 金额(2)不同日期..._exce l趋势分析数据量
宁盾堡垒机双因素认证方案_horizon宁盾双因素配置-程序员宅基地
文章浏览阅读3.3k次。堡垒机可以为企业实现服务器、网络设备、数据库、安全设备等的集中管控和安全可靠运行,帮助IT运维人员提高工作效率。通俗来说,就是用来控制哪些人可以登录哪些资产(事先防范和事中控制),以及录像记录登录资产后做了什么事情(事后溯源)。由于堡垒机内部保存着企业所有的设备资产和权限关系,是企业内部信息安全的重要一环。但目前出现的以下问题产生了很大安全隐患:密码设置过于简单,容易被暴力破解;为方便记忆,设置统一的密码,一旦单点被破,极易引发全面危机。在单一的静态密码验证机制下,登录密码是堡垒机安全的唯一_horizon宁盾双因素配置
谷歌浏览器安装(Win、Linux、离线安装)_chrome linux debian离线安装依赖-程序员宅基地
文章浏览阅读7.7k次,点赞4次,收藏16次。Chrome作为一款挺不错的浏览器,其有着诸多的优良特性,并且支持跨平台。其支持(Windows、Linux、Mac OS X、BSD、Android),在绝大多数情况下,其的安装都很简单,但有时会由于网络原因,无法安装,所以在这里总结下Chrome的安装。Windows下的安装:在线安装:离线安装:Linux下的安装:在线安装:离线安装:..._chrome linux debian离线安装依赖
烤仔TVの尚书房 | 逃离北上广?不如押宝越南“北上广”-程序员宅基地
文章浏览阅读153次。中国发达城市榜单每天都在刷新,但无非是北上广轮流坐庄。北京拥有最顶尖的文化资源,上海是“摩登”的国际化大都市,广州是活力四射的千年商都。GDP和发展潜力是衡量城市的数字指...
随便推点
java spark的使用和配置_使用java调用spark注册进去的程序-程序员宅基地
文章浏览阅读3.3k次。前言spark在java使用比较少,多是scala的用法,我这里介绍一下我在项目中使用的代码配置详细算法的使用请点击我主页列表查看版本jar版本说明spark3.0.1scala2.12这个版本注意和spark版本对应,只是为了引jar包springboot版本2.3.2.RELEASEmaven<!-- spark --> <dependency> <gro_使用java调用spark注册进去的程序
汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用_uds协议栈 源代码-程序员宅基地
文章浏览阅读4.8k次。汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用,代码精简高效,大厂出品有量产保证。:139800617636213023darcy169_uds协议栈 源代码
AUTOSAR基础篇之OS(下)_autosar 定义了 5 种多核支持类型-程序员宅基地
文章浏览阅读4.6k次,点赞20次,收藏148次。AUTOSAR基础篇之OS(下)前言首先,请问大家几个小小的问题,你清楚:你知道多核OS在什么场景下使用吗?多核系统OS又是如何协同启动或者关闭的呢?AUTOSAR OS存在哪些功能安全等方面的要求呢?多核OS之间的启动关闭与单核相比又存在哪些异同呢?。。。。。。今天,我们来一起探索并回答这些问题。为了便于大家理解,以下是本文的主题大纲:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JCXrdI0k-1636287756923)(https://gite_autosar 定义了 5 种多核支持类型
VS报错无法打开自己写的头文件_vs2013打不开自己定义的头文件-程序员宅基地
文章浏览阅读2.2k次,点赞6次,收藏14次。原因:自己写的头文件没有被加入到方案的包含目录中去,无法被检索到,也就无法打开。将自己写的头文件都放入header files。然后在VS界面上,右键方案名,点击属性。将自己头文件夹的目录添加进去。_vs2013打不开自己定义的头文件
【Redis】Redis基础命令集详解_redis命令-程序员宅基地
文章浏览阅读3.3w次,点赞80次,收藏342次。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。当数据量很大时,count 的数量的指定可能会不起作用,Redis 会自动调整每次的遍历数目。_redis命令
URP渲染管线简介-程序员宅基地
文章浏览阅读449次,点赞3次,收藏3次。URP的设计目标是在保持高性能的同时,提供更多的渲染功能和自定义选项。与普通项目相比,会多出Presets文件夹,里面包含着一些设置,包括本色,声音,法线,贴图等设置。全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,主光源和附加光源在一次Pass中可以一起着色。URP:全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,一次Pass可以计算多个光源。可编程渲染管线:渲染策略是可以供程序员定制的,可以定制的有:光照计算和光源,深度测试,摄像机光照烘焙,后期处理策略等等。_urp渲染管线