2023/9/17 基于pycharm的爬取豆瓣电影250(一)_如何用pycharm找电影-程序员宅基地
技术标签: 爬虫 学习 python 信息可视化 爬虫加网络可视化
2023/9/17 网络爬虫+数据可视化研究
目录
最近用一周的时间进行学习网络爬虫+数据可视化分析,因此特地记录所学知识,并向外输出以此加深自己的印象。
1.网络爬虫
本质: 网络爬虫通过向对方服务器发送请求,从而得到响应,进而分析所获取网页的内容。
因此,我们需要做三个方面的内容:分别是抓取网页、提取内容、保存内容。这样我们一个基本的爬虫框架就完成了。剩下的就是完成这三部分内容:1.0. 准备操作:
软件:python
包:bs4(用于解析HTML和XML文档)、re(处理正则表达式)、urllib(用于处理 URL)
其中网页抓取的最难之处在于正则表达式的书写,它是你能否正确获取信息的关键。
from bs4 import BeautifulSoup
import re
import urllib.request, urllib.error
import xlwt
import sqlite3
1.1. 抓取网页
我们以 豆瓣电影TOP250为例,定义一个getdata(baseurl)函数,其中baseurl为我们需要发起请求的链接地址。
def askurl(url):
head = {
# 模拟头部信息,向豆瓣服务器发送消息
"User-Agent":
"""Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 116.0.0.0Safari / 537.36"""
} # 这是一个用户代理,告诉浏览器我们是什么类型的机器,浏览器可以接受什么水平的文件
request = urllib.request.Request(url=url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print(e.code)
if hasattr(e, 'reason'):
print(e.reason)
return html
此处需要讲解的是头部信息,头部信息的作用就是模拟正常浏览器向服务器进行请求信息。那么头部信息又是如何模拟浏览器的信息从而骗过服务器。
对你想请求的网页按F12,你可以看到如下信息:
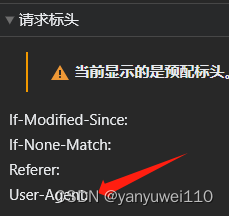
我们使用的User-Agent就是从这里获得。
1.2.获取数据
def getdata(baseurl):
datalist = []
# 2.解析数据
for i in range(0, 10):
url = baseurl + str(i * 25)
html = askurl(url)#我们定义的一个请求网址的函数,此函数的定义是模拟浏览器向豆瓣网进行请求内容,防止网站认为我们是电脑。
soup = BeautifulSoup(html, 'html.parser') # 对网页进行解析
for item in soup.find_all('div', {
'class': 'item'}):#利用函数寻找所有在标签div下的名为item的类。
# print(type(item))
data = [] # 利用列表保存一部电影的所有信息
item = str(item)
link = re.findall(findlink, item)[0] # 获取到影片详情链接
# print(link)
data.append(link)
imgsrc = re.findall(findimage, item)[0] # 获取到影片图片的链接
data.append(imgsrc)
titles = re.findall(findtitle, item) # 获取到影片的片名
if (len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "")#将外文标题中的/替换为空格。
data.append(otitle)
else:
data.append(titles[0])
data.append(' ')
rating = re.findall(findrating, item)[0] # 获取到影片评分
data.append(rating)
judge = re.findall(findjudge, item)[0] # 获取到评价人数
data.append(judge)
inq = re.findall(findinq, item) # 获取到概况
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(' ')
bd = re.findall(findbd, item)[0] # 获取到影片的相关内容
bd = re.sub('<br(\s+)?/>(\s+)?', " ", bd) #去掉<br/>
bd = re.sub('/', " ", bd) # 替换/
data.append(bd.strip()) # 去掉前后的空格
datalist.append(data) # 把处理好的一部电影信息放入datalist
# import pprint
# pprint.pprint(datalist)
return datalist
1.2.保存数据
保存数据我们这里住哟啊讲解2种方式:
1.2.1 保存为Excel格式
def savedata(savepath, datalist):
book = xlwt.Workbook(encoding='utf-8', style_compression=0)
sheet = book.add_sheet('豆瓣电影top250', cell_overwrite_ok=True)
col = ('电影个数', '电影详情链接', '图片链接', '影片中文名', '影片外国名', '评分', '评价数', '概况', '相关信息')
for i in range(0, 8):
sheet.write(0, i, col[i])
for i in range(0, 25):
# print('第%d条'%i)
sheet.write(i + 1, 0, "第%d条" % (i + 1))
data = datalist[i]
for j in range(0, 8):
sheet.write(i + 1, j + 1, data[j])
book.save(savepath) # 保存数据表
1.2.2 数据库格式
首先要初始化数据库,生成一个数据库。
def init_db(dbpath): # 数据库初始化
sql = '''
create table movie250
(
id integer primary key autoincrement,
info_link text,
pic_link text,
cname varchar,
ename varchar,
score numeric,
instroductionn text,
info text
)
'''
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
随后在数据库中添加我们爬取到的信息
def savedatadb(datalist, dbpath):
init_db(dbpath)#初始化数据库
conn= sqlite3.connect(dbpath)#链接数据库
cur=conn.cursor()#得到数据库的游标,所有的信息都在游标上
for data in datalist:
for index in range(len(data)):
if index==4 or index==5:
continue
data[index]='"'+data[index]+'"' #转化为字符
sql='''
insert into movie250(info_link,pic_link,cname,ename,score,instroductionn,info)
values(%s)'''%",".join(data)
# print(sql)
cur.execute(sql)
conn.commit()
cur.close()#关闭游标
conn.close()#关闭数据库
2.特别篇-正则表达式
要是想要能够正确的取出网页中的内容,那我们必须要将正则表达式能够熟练运用。

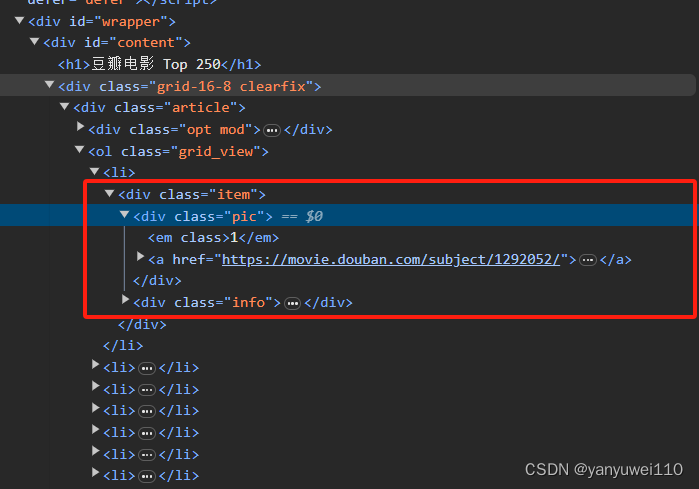
因此在这个程序中,我们所获取的内容的正则表示式如下:
为了让大家能够更好地理解正则表达式,我将网页中的内容与这里的正则表示进行一一对应。
#找到电影的链接
findlink = re.compile(r'<a href="(.*?)">')

# 得到影片图片的链接
findimage = re.compile(r'<img.*src="(.*?)"', re.S) # re.S让换行符包含在字符中

# 得到影片的片名
findtitle = re.compile(r'<span class="title">(.*)</span>')

# 影片评分
findrating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')

# 评价人数
findjudge = re.compile(r'<span>(\d*)人评价</span>')

# 找到概况
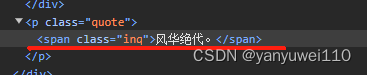
findinq = re.compile(r'<span class="inq">(.*)</span>')
# 找到影片的相关内容
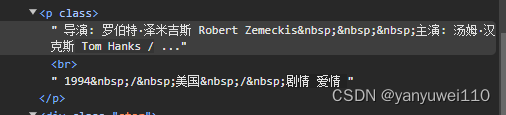
findbd = re.compile(r'<p class="">(.*?)</p>', re.S)
这样我们的一个爬虫工作就算完成了。剩下的就是多练。
3. 完整代码–
from bs4 import BeautifulSoup
import re
import urllib.request, urllib.error
import xlwt
import sqlite3
def main():
# 1.爬取网页
baseurl = 'https://movie.douban.com/top250?start=0'
datalist = getdata(baseurl)
savepath = '豆瓣电影top250.xls'
dbpath = 'move.db'
savedatadb(datalist, dbpath)
# savedata(savepath, datalist)
# 3. 保存数据
# savedata(savepath,datalist)
# askurl("https://movie.douban.com/top250")
findlink = re.compile(r'<a href="(.*?)">')
# 得到影片图片的链接
findimage = re.compile(r'<img.*src="(.*?)"', re.S) # re.S让换行符包含在字符中
# 得到影片的片名
findtitle = re.compile(r'<span class="title">(.*)</span>')
# 影片评分
findrating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# 评价人数
findjudge = re.compile(r'<span>(\d*)人评价</span>')
# 找到概况
findinq = re.compile(r'<span class="inq">(.*)</span>')
# 找到影片的相关内容
findbd = re.compile(r'<p class="">(.*?)</p>', re.S)
def getdata(baseurl):
datalist = []
# 2.解析数据
for i in range(0, 1):
url = baseurl + str(i * 25)
html = askurl(url)
soup = BeautifulSoup(html, 'html.parser') # 对网页进行解析
for item in soup.find_all('div', {
'class': 'item'}):
# print(type(item))
data = [] # 利用列表保存一部电影的所有信息
item = str(item)
link = re.findall(findlink, item)[0] # 获取到影片详情链接
# print(link)
data.append(link)
imgsrc = re.findall(findimage, item)[0] # 获取到影片图片的链接
data.append(imgsrc)
titles = re.findall(findtitle, item) # 获取到影片的片名
if (len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "")
data.append(otitle)
else:
data.append(titles[0])
data.append(' ')
rating = re.findall(findrating, item)[0] # 获取到影片评分
data.append(rating)
judge = re.findall(findjudge, item)[0] # 获取到评价人数
data.append(judge)
inq = re.findall(findinq, item) # 获取到概况
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(' ')
bd = re.findall(findbd, item)[0] # 获取到影片的相关内容
bd = re.sub('<br(\s+)?/>(\s+)?', " ", bd) # 去掉<br/>
bd = re.sub('/', " ", bd) # 替换/
data.append(bd.strip()) # 去掉前后的空格
datalist.append(data) # 把处理好的一部电影信息放入datalist
# import pprint
# pprint.pprint(datalist)
return datalist
# 得到指定网页的指定内容
def askurl(url):
# global html
head = {
# 模拟头部信息,向豆瓣服务器发送消息
"User-Agent":
"""Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 116.0.0.0Safari / 537.36"""
} # 这是一个用户代理,告诉浏览器我们是什么类型的机器,浏览器可以接受什么水平的文件
request = urllib.request.Request(url=url, headers=head)
html=''
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print(e.code)
if hasattr(e, 'reason'):
print(e.reason)
return html
def savedata(savepath, datalist):
book = xlwt.Workbook(encoding='utf-8', style_compression=0)
sheet = book.add_sheet('豆瓣电影top250', cell_overwrite_ok=True)
col = ('电影详情链接', '图片链接', '影片中文名', '影片外国名', '评分', '评价数', '概况', '相关信息')
for i in range(0, 8):
sheet.write(0, i, col[i])
for i in range(0, 25):
# print('第%d条'%i)
data = datalist[i]
for j in range(0, 8):
sheet.write(i + 1, j, data[j])
book.save(savepath) # 保存数据表
def savedatadb(datalist, dbpath):
init_db(dbpath) # 初始化数据库
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
if index == 4 or index == 5:
continue
data[index] = '"' + data[index] + '"'
sql = '''
insert into movie250 (
info_link,pic_link,cname,ename,score,rated,instroduction,info)
values(%s)''' % ",".join(data)
# print(sql)
cur.execute(sql)
conn.commit()
cur.close() # 关闭游标
conn.close() # 关闭数据库
def init_db(dbpath): # 数据库初始化
sql = '''
create table movie250
(
id integer primary key autoincrement,
info_link text,
pic_link text,
cname varchar,
ename varchar,
score numeric,
rated numeric,
instroduction text,
info text
)
'''
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
# 主函数
main()
# init_db("movie_test.db")
# print("建立数据库完毕")
智能推荐
c# 调用c++ lib静态库_c#调用lib-程序员宅基地
文章浏览阅读2w次,点赞7次,收藏51次。四个步骤1.创建C++ Win32项目动态库dll 2.在Win32项目动态库中添加 外部依赖项 lib头文件和lib库3.导出C接口4.c#调用c++动态库开始你的表演...①创建一个空白的解决方案,在解决方案中添加 Visual C++ , Win32 项目空白解决方案的创建:添加Visual C++ , Win32 项目这......_c#调用lib
deepin/ubuntu安装苹方字体-程序员宅基地
文章浏览阅读4.6k次。苹方字体是苹果系统上的黑体,挺好看的。注重颜值的网站都会使用,例如知乎:font-family: -apple-system, BlinkMacSystemFont, Helvetica Neue, PingFang SC, Microsoft YaHei, Source Han Sans SC, Noto Sans CJK SC, W..._ubuntu pingfang
html表单常见操作汇总_html表单的处理程序有那些-程序员宅基地
文章浏览阅读159次。表单表单概述表单标签表单域按钮控件demo表单标签表单标签基本语法结构<form action="处理数据程序的url地址“ method=”get|post“ name="表单名称”></form><!--action,当提交表单时,向何处发送表单中的数据,地址可以是相对地址也可以是绝对地址--><!--method将表单中的数据传送给服务器处理,get方式直接显示在url地址中,数据可以被缓存,且长度有限制;而post方式数据隐藏传输,_html表单的处理程序有那些
PHP设置谷歌验证器(Google Authenticator)实现操作二步验证_php otp 验证器-程序员宅基地
文章浏览阅读1.2k次。使用说明:开启Google的登陆二步验证(即Google Authenticator服务)后用户登陆时需要输入额外由手机客户端生成的一次性密码。实现Google Authenticator功能需要服务器端和客户端的支持。服务器端负责密钥的生成、验证一次性密码是否正确。客户端记录密钥后生成一次性密码。下载谷歌验证类库文件放到项目合适位置(我这边放在项目Vender下面)https://github.com/PHPGangsta/GoogleAuthenticatorPHP代码示例://引入谷_php otp 验证器
【Python】matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距-程序员宅基地
文章浏览阅读4.3k次,点赞5次,收藏11次。matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距
docker — 容器存储_docker 保存容器-程序员宅基地
文章浏览阅读2.2k次。①Storage driver 处理各镜像层及容器层的处理细节,实现了多层数据的堆叠,为用户 提供了多层数据合并后的统一视图②所有 Storage driver 都使用可堆叠图像层和写时复制(CoW)策略③docker info 命令可查看当系统上的 storage driver主要用于测试目的,不建议用于生成环境。_docker 保存容器
随便推点
网络拓扑结构_网络拓扑csdn-程序员宅基地
文章浏览阅读834次,点赞27次,收藏13次。网络拓扑结构是指计算机网络中各组件(如计算机、服务器、打印机、路由器、交换机等设备)及其连接线路在物理布局或逻辑构型上的排列形式。这种布局不仅描述了设备间的实际物理连接方式,也决定了数据在网络中流动的路径和方式。不同的网络拓扑结构影响着网络的性能、可靠性、可扩展性及管理维护的难易程度。_网络拓扑csdn
JS重写Date函数,兼容IOS系统_date.prototype 将所有 ios-程序员宅基地
文章浏览阅读1.8k次,点赞5次,收藏8次。IOS系统Date的坑要创建一个指定时间的new Date对象时,通常的做法是:new Date("2020-09-21 11:11:00")这行代码在 PC 端和安卓端都是正常的,而在 iOS 端则会提示 Invalid Date 无效日期。在IOS年月日中间的横岗许换成斜杠,也就是new Date("2020/09/21 11:11:00")通常为了兼容IOS的这个坑,需要做一些额外的特殊处理,笔者在开发的时候经常会忘了兼容IOS系统。所以就想试着重写Date函数,一劳永逸,避免每次ne_date.prototype 将所有 ios
如何将EXCEL表导入plsql数据库中-程序员宅基地
文章浏览阅读5.3k次。方法一:用PLSQL Developer工具。 1 在PLSQL Developer的sql window里输入select * from test for update; 2 按F8执行 3 打开锁, 再按一下加号. 鼠标点到第一列的列头,使全列成选中状态,然后粘贴,最后commit提交即可。(前提..._excel导入pl/sql
Git常用命令速查手册-程序员宅基地
文章浏览阅读83次。Git常用命令速查手册1、初始化仓库git init2、将文件添加到仓库git add 文件名 # 将工作区的某个文件添加到暂存区 git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件...
分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120-程序员宅基地
文章浏览阅读202次。分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120
【C++缺省函数】 空类默认产生的6个类成员函数_空类默认产生哪些类成员函数-程序员宅基地
文章浏览阅读1.8k次。版权声明:转载请注明出处 http://blog.csdn.net/irean_lau。目录(?)[+]1、缺省构造函数。2、缺省拷贝构造函数。3、 缺省析构函数。4、缺省赋值运算符。5、缺省取址运算符。6、 缺省取址运算符 const。[cpp] view plain copy_空类默认产生哪些类成员函数