GAN对抗网络入门教程_网络对抗算法计算步骤-程序员宅基地
技术标签: GAN 图像处理 神经网络 Python TensorFlow
GAN对抗网络入门教程
原创 致Great ChallengeHub 公众号发布
参考论文:A Beginner's Guide to Generative Adversarial Networks (GANs) https://skymind.ai/wiki/generative-adversarial-network-gan
1 GAN简介
生成对抗网络(英语:Generative Adversarial Network,简称GAN)是非监督式学习的一种方法,通过让两个神经网络相互博弈的方式进行学习。该方法由伊恩·古德费洛等人于2014年提出。生成对抗网络由一个生成网络与一个判别网络组成。生成网络从潜在空间(latent space)中随机取样作为输入,其输出结果需要尽量模仿训练集中的真实样本。判别网络的输入则为真实样本或生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来。而生成网络则要尽可能地欺骗判别网络。两个网络相互对抗、不断调整参数,最终目的是使判别网络无法判断生成网络的输出结果是否真实。
生成对抗网络常用于生成以假乱真的图片。此外,该方法还被用于生成影片、三维物体模型等。
虽然生成对抗网络原先是为了无监督学习提出的,它也被证明对半监督学习、完全监督学习 、强化学习是有用的。

2 生成与判别算法
要理解GAN,你应该知道生成算法是如何工作的,但是在理解生成算法之前,将它们与判别算法进行对比可以加深理解。我们先看下什么事判别算法?
判别算法试图对输入数据进行分类; 也就是说,给定数据实例的特征,它们预测该数据所属的标签或类别。
例如,给定电子邮件中的所有单词(数据实例),判别算法可以预测该消息是spam(垃圾邮件)还是not_spam(非垃圾邮件)。其中spam是标签之一,从电子邮件收集的单词包是构成输入数据的特征。当以数学方式表达此问题时,标签称为y,并且要素称为x。公式p(y|x)用于表示“给定x条件下y发生的概率”,在这种情况下,它将转换为“在给定邮件所包含的字词情况下,电子邮件是垃圾邮件的概率”。
因此,判别算法是将特征映射到标签,而生成算法恰恰在做相反的事情。生成算法试图预测给定某个标签下的特征,而不是预测给定某些特征的标签。
生成算法试图回答的问题是:假设这封电子邮件是垃圾邮件,特征的分布或者概率是怎么样的?虽然判别模型关注y和x之间的关系,但是生成模型关心“你如何得到x。”生成算法是为了计算出(x | y),给出y条件下x发生的概率,或者说给出标签时,特征的概率。(也就是说,生成算法也可以用作分类器。恰好它们不是对输入数据进行分类。)
下面两句话将判别与生成区分开来:
-
判别模型学习了类之间的界限
-
生成模型模拟各个类的分布
3 GANs原理
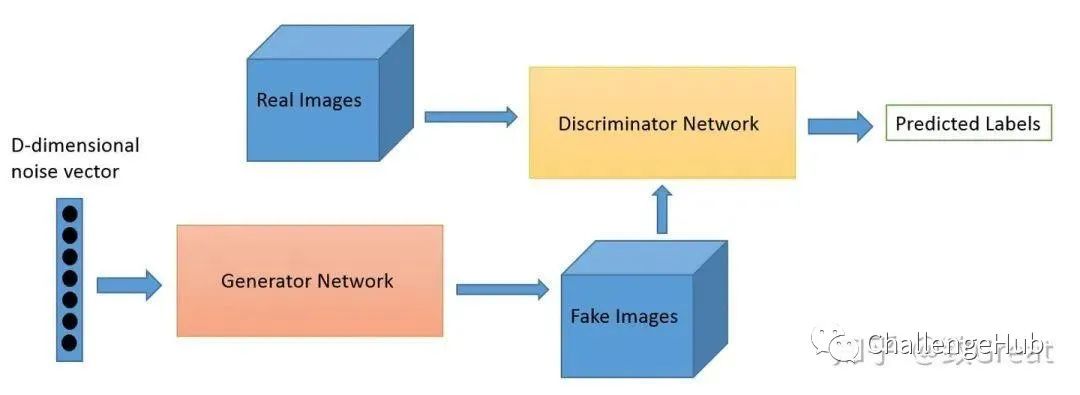
GAN的基本原理其实非常简单,这里以生成图片为例进行说明。假设我们有两个网络,G(Generator)和D(Discriminator)。正如它的名字所暗示的那样,它们的功能分别是:一个神经网络,称为生成器,生成新的数据实例,而另一个神经网络,判别器,评估它们的真实性; 即判别器决定它所评测的每个数据实例是否属于实际训练数据集。
G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
最后博弈的结果是什么?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
reference:https://zhuanlan.zhihu.com/p/24767059
以下是GAN大致步骤:
-
生成器接收随机数并返回图像。
-
将生成的图像与从真实数据集中获取的图像流一起馈送到判别器中。
-
判别器接收真实和假图像并返回概率,0到1之间的数字,1表示真实性的预测,0表示假。
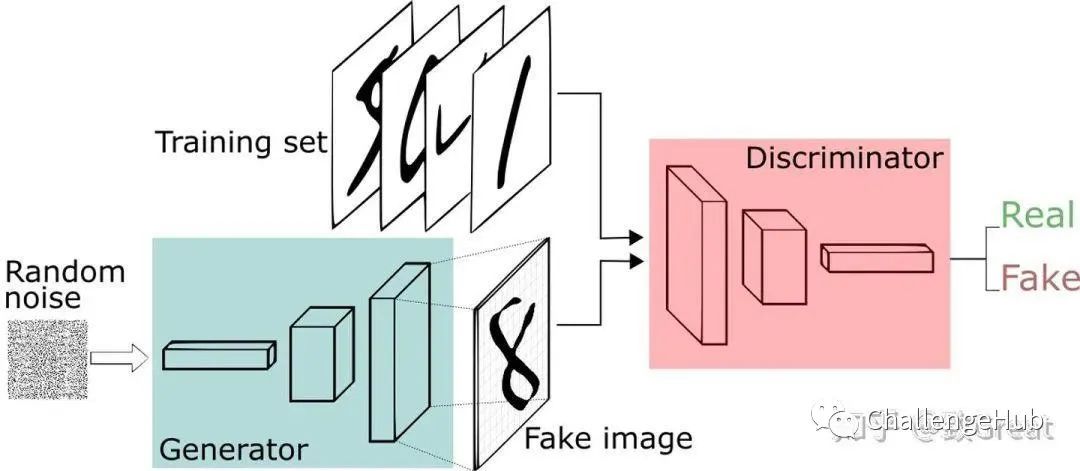
您可以将GAN视为诈骗者和警察在猫与老鼠游戏中的反对,其中诈骗者正在学习传递虚假信息,并且警察正在学习如何检测它们。两者都是动态的; 也就是说,警察也在接受培训,每一方都在不断升级中学习对方的方法。
对于MNIST数据集,判别器网络是标准卷积网络,可以对馈送给它的图像进行分类,二项分类器将图像标记为真实或伪造。在某种意义上,生成器是反卷积网络:当标准卷积分类器采用图像并对其进行下采样以产生概率时,生成器采用随机噪声矢量并将其上采样到图像。第一个通过下采样技术(如maxpooling)丢弃数据,第二个生成新数据。
4 GANs, Autoencoders and VAEs
下面对生成性对抗网络与其他神经网络(例如自动编码器和变分自动编码器)进行比较。
自动编码器将输入数据编码为矢量。它们创建原始数据的隐藏或压缩表示,在减少维数方面很有用; 也就是说,用作隐藏表示的向量将原始数据压缩为较少数量的突出维度。自动编码器可以与所谓的解码器配对,允许您根据其隐藏的表示重建输入数据,就像使用受限制的Boltzmann机器一样。
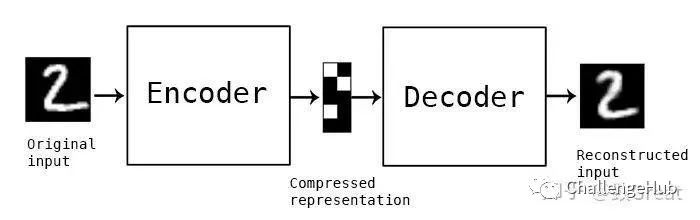
变分自动编码器是生成算法,其为编码输入数据添加额外约束,即隐藏表示被标准化。变分自动编码器能够像自动编码器一样压缩数据并像GAN一样合成数据。然而GAN可以更精细、细粒度的生成数据,VAE生成的图像往往更加模糊。Deeplearning4j的例子包括自动编码器和变分自动编码器。
5 Keras 实现GAN
https://github.com/eriklindernoren/Keras-GAN
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import sys
import numpy as np
Using TensorFlow backend.
class GAN():
def __init__(self):
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
optimizer = Adam(0.0002, 0.5)
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# Build and compile the generator
self.generator = self.build_generator()
self.generator.compile(loss='binary_crossentropy', optimizer=optimizer)
# The generator takes noise as input and generated imgs
z = Input(shape=(100,))
img = self.generator(z)
# For the combined model we will only train the generator
self.discriminator.trainable = False
# The valid takes generated images as input and determines validity
valid = self.discriminator(img)
# The combined model (stacked generator and discriminator) takes
# noise as input => generates images => determines validity
self.combined = Model(z, valid)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
noise_shape = (100,)
model = Sequential()
model.add(Dense(256, input_shape=noise_shape))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
model.summary()
noise = Input(shape=noise_shape)
img = model(noise)
return Model(noise, img)
def build_discriminator(self):
img_shape = (self.img_rows, self.img_cols, self.channels)
model = Sequential()
model.add(Flatten(input_shape=img_shape))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=img_shape)
validity = model(img)
return Model(img, validity)
def train(self, epochs, batch_size=128, save_interval=50):
# Load the dataset
(X_train, _), (_, _) = mnist.load_data()
# Rescale -1 to 1
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = np.expand_dims(X_train, axis=3)
half_batch = int(batch_size / 2)
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random half batch of images
idx = np.random.randint(0, X_train.shape[0], half_batch)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (half_batch, 100))
# Generate a half batch of new images
gen_imgs = self.generator.predict(noise)
# Train the discriminator
d_loss_real = self.discriminator.train_on_batch(imgs, np.ones((half_batch, 1)))
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, np.zeros((half_batch, 1)))
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
noise = np.random.normal(0, 1, (batch_size, 100))
# The generator wants the discriminator to label the generated samples
# as valid (ones)
valid_y = np.array([1] * batch_size)
# Train the generator
g_loss = self.combined.train_on_batch(noise, valid_y)
# Plot the progress
if epoch%1000==0:
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
# If at save interval => save generated image samples
if epoch % save_interval == 0:
self.save_imgs(epoch)
def save_imgs(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, 100))
gen_imgs = self.generator.predict(noise)
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("data/gan/images/mnist_%d.png" % epoch)
plt.close()
if __name__ == '__main__':
gan = GAN()
gan.train(epochs=30000, batch_size=32, save_interval=200)
输出:
WARNING:tensorflow:From D:\ProgramData\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:66: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.
WARNING:tensorflow:From D:\ProgramData\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:541: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.
WARNING:tensorflow:From D:\ProgramData\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:4432: The name tf.random_uniform is deprecated. Please use tf.random.uniform instead.
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 401920
_________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 256) 131328
_________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 256) 0
_________________________________________________________________
dense_3 (Dense) (None, 1) 257
=================================================================
Total params: 533,505
Trainable params: 533,505
Non-trainable params: 0
_________________________________________________________________
WARNING:tensorflow:From D:\ProgramData\Anaconda3\lib\site-packages\keras\optimizers.py:793: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.
WARNING:tensorflow:From D:\ProgramData\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:3657: The name tf.log is deprecated. Please use tf.math.log instead.
WARNING:tensorflow:From D:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\ops\nn_impl.py:180: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
WARNING:tensorflow:From D:\ProgramData\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:148: The name tf.placeholder_with_default is deprecated. Please use tf.compat.v1.placeholder_with_default instead.
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 256) 25856
_________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 256) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 256) 1024
_________________________________________________________________
dense_5 (Dense) (None, 512) 131584
_________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 512) 0
_________________________________________________________________
batch_normalization_2 (Batch (None, 512) 2048
_________________________________________________________________
dense_6 (Dense) (None, 1024) 525312
_________________________________________________________________
leaky_re_lu_5 (LeakyReLU) (None, 1024) 0
_________________________________________________________________
batch_normalization_3 (Batch (None, 1024) 4096
_________________________________________________________________
dense_7 (Dense) (None, 784) 803600
_________________________________________________________________
reshape_1 (Reshape) (None, 28, 28, 1) 0
=================================================================
Total params: 1,493,520
Trainable params: 1,489,936
Non-trainable params: 3,584
_________________________________________________________________
D:\ProgramData\Anaconda3\lib\site-packages\keras\engine\training.py:493: UserWarning: Discrepancy between trainable weights and collected trainable weights, did you set `model.trainable` without calling `model.compile` after ?
'Discrepancy between trainable weights and collected trainable'
0 [D loss: 0.735185, acc.: 46.88%] [G loss: 0.829077]
D:\ProgramData\Anaconda3\lib\site-packages\keras\engine\training.py:493: UserWarning: Discrepancy between trainable weights and collected trainable weights, did you set `model.trainable` without calling `model.compile` after ?
'Discrepancy between trainable weights and collected trainable'
1000 [D loss: 0.590758, acc.: 71.88%] [G loss: 0.793450]
2000 [D loss: 0.587990, acc.: 62.50%] [G loss: 0.956186]
3000 [D loss: 0.644352, acc.: 59.38%] [G loss: 0.914777]
4000 [D loss: 0.673936, acc.: 62.50%] [G loss: 0.971460]
5000 [D loss: 0.759974, acc.: 53.12%] [G loss: 0.904706]
6000 [D loss: 0.555306, acc.: 81.25%] [G loss: 0.835633]
7000 [D loss: 0.674409, acc.: 62.50%] [G loss: 0.823623]
8000 [D loss: 0.672854, acc.: 53.12%] [G loss: 0.863680]
9000 [D loss: 0.743683, acc.: 46.88%] [G loss: 0.868321]
10000 [D loss: 0.635190, acc.: 59.38%] [G loss: 0.854181]
11000 [D loss: 0.700397, acc.: 56.25%] [G loss: 0.778778]
12000 [D loss: 0.741978, acc.: 46.88%] [G loss: 0.813542]
13000 [D loss: 0.760614, acc.: 46.88%] [G loss: 0.833507]
14000 [D loss: 0.671199, acc.: 68.75%] [G loss: 0.853395]
15000 [D loss: 0.676217, acc.: 62.50%] [G loss: 0.920993]
16000 [D loss: 0.593898, acc.: 68.75%] [G loss: 0.889001]
17000 [D loss: 0.724363, acc.: 50.00%] [G loss: 0.893431]
18000 [D loss: 0.779740, acc.: 43.75%] [G loss: 0.853765]
19000 [D loss: 0.642237, acc.: 59.38%] [G loss: 0.830348]
20000 [D loss: 0.587237, acc.: 62.50%] [G loss: 0.876839]
21000 [D loss: 0.645381, acc.: 62.50%] [G loss: 0.827465]
22000 [D loss: 0.723597, acc.: 46.88%] [G loss: 0.862281]
23000 [D loss: 0.671319, acc.: 65.62%] [G loss: 0.903444]
24000 [D loss: 0.684801, acc.: 62.50%] [G loss: 0.807403]
25000 [D loss: 0.737355, acc.: 43.75%] [G loss: 0.813877]
26000 [D loss: 0.606201, acc.: 68.75%] [G loss: 0.802509]
27000 [D loss: 0.711020, acc.: 56.25%] [G loss: 0.894887]
28000 [D loss: 0.641023, acc.: 56.25%] [G loss: 0.856079]
29000 [D loss: 0.696889, acc.: 46.88%] [G loss: 0.728626]
可以看到D的判别准确率最终在46%-56%之间,也就是说G网络生成的图片已经真假难分
6 参考资料
-
GAN学习指南:从原理入门到制作生成Demo https://zhuanlan.zhihu.com/p/24767059
-
A Beginner's Guide to Generative Adversarial Networks (GANs) https://skymind.ai/wiki/generative-adversarial-network-gan
END
-
欢迎扫码关注ChallengeHub学习交流群,关注公众号:ChallengeHub

或者添加以下成员的微信,进入微信群:

智能推荐
当Table中td内容为空时,显示边框的办法-程序员宅基地
文章浏览阅读87次。1. 在 table的css里面加: border-collapse:collapse;在 td 的css里面加: empty-cells:show;2 .最简单的就是 在TD里写个 说明:border-collapse设置或检索表格的行和单元格的边是合并在一起还是按照标准的HTML样式分开。定义和用法border-collapse 属性设置表格的边..._jsp table标签里面是空值显示 无边框
vivo x7 android版本,vivo X7/Xplay5S等机型获Android 7.1升级-程序员宅基地
文章浏览阅读1.3k次。感谢IT之家网友嘉庆的笔记本的线索投递IT之家8月15日消息今天,vivo向X7、X7 Plus、Xplay5A、Xplay5S等四款机型开放Funtouch OS 3.1 with Android 7.1更新,除了系统升级至安卓7.1之外,新版的Funtouch OS还将支持卸载内置的第三方App。根据官方更新日志,此次升级增加了十多项新功能,同时还对系统进了大量优化。值得一提的是,本次升..._vivox7plus升级安卓7.1升级包下载
python opencv 4.1.0 cv2.convertScaleAbs()函数 (通过线性变换将数据转换成8位[uint8])(用于Intel Realsense D435显示depth图像)-程序员宅基地
文章浏览阅读2.7w次,点赞20次,收藏92次。def convertScaleAbs(src, dst=None, alpha=None, beta=None): # real signature unknown; restored from __doc__ """ convertScaleAbs(src[, dst[, alpha[, beta]]]) -> dst . @brief Scales, cal..._cv2.convertscaleabs
C语言编译器(C语言编程软件)完全攻略(第九部分:VS2019使用教程(使用VS2019编写C语言程序))_visualstudio2019编译-程序员宅基地
文章浏览阅读1.1k次,点赞23次,收藏18次。现在,你就可以将 MyDemo.exe 分享给你的朋友了,告诉他们这是你编写的第一个C语言程序。虽然这个程序非常简单,但是你已经越过了第一道障碍,学会了如何编写代码,如何将代码生成可执行程序,这是一个完整的体验。在本教程的基础部分,教大家编写的程序都是这样的“黑窗口”,与我们平时使用的软件不同,它们没有漂亮的界面,没有复杂的功能,只能看到一些文字,这就是控制台程序(Console Application),它与DOS非常相似,早期的计算机程序都是这样的。_visualstudio2019编译
css3d转换_CSS的性感链接转换-程序员宅基地
文章浏览阅读436次。css3d转换 I was recently visiting MooTools Developer Christoph Pojer's website and noticed a sexy link hover effect: when you hover the link, the the link animates and tilts to the left or the ri...
php-读取excel文件_php 读取excel-程序员宅基地
文章浏览阅读373次。php-读取excel文件_php 读取excel
随便推点
爬虫开发(2)——序列化_爬虫的批处理序列化-程序员宅基地
文章浏览阅读195次。为什么要使用序列化?我们定义了一个字典:aDict = dict(url = 'lu &amp; yi.html', content = 'They will be ...')这里我们把网页 lu &amp; yi.html 作为起始的网页地址,在之后的爬取过程中,将使用新的网页url来替换它。但是当我们关闭工程,重新启动之后,该字典又重新初始化起始网页为lu &amp; yi.htm..._爬虫的批处理序列化
去除数字滤波器后的相位延迟(内有实操代码和效果图)_减小相位延迟的方法-程序员宅基地
文章浏览阅读2.9k次,点赞2次,收藏14次。参考链接https://ww2.mathworks.cn/help/signal/digital-filter-analysis.htmlhttps://ww2.mathworks.cn/help/signal/ug/compensate-for-delay-and-distortion-introduced-by-filters.html?s_tid=srchtitleFIR 线性相位延迟 FIR滤波器是有限长单位冲激响应滤波器,又称为非递归型滤波器,是数字信号处理系统中基本的元件.._减小相位延迟的方法
enumerate()用法_enumerate(a)-程序员宅基地
文章浏览阅读221次。for index , item in enumerate (a , x):for index , item in enumerate (a):这里有n,v俩参数,n先不管,v为a中的元素,比较简单。a=[[8,2],[2,3],[5,4]]print(a)for n , v in enumerate(a): v += v print(v) #print(n)输出[[8, 2], [2, 3], [5, 4]][8, 2, 8, 2][2, 3, 2, 3]_enumerate(a)
计算几何讲义——计算几何中的欧拉定理-程序员宅基地
文章浏览阅读188次。在处理计算几何的问题中,有时候我们会将其看成图论中的graph图,结合我们在图论中学习过的欧拉定理,我们可以通过图形的节点数(v)和边数(e)得到不是那么好求的面数f。 平面图中的欧拉定理: 定理:设G为任意的连通的平面图,则v-e+f=2,v是G的顶点数,e是G的边数,f是G的面数。证明:其实有点类似几何学中的欧拉公式的证明方法,这里采用归纳证明的方法。对m..._怎么证明平面图欧拉定理
c语言中各种括号的作用,C语言中各种类型指针的特性与用法介绍-程序员宅基地
文章浏览阅读750次。C语言中各种类型指针的特性与用法介绍本文主要介绍了C语言中各种类型指针的特性与用法,有需要的朋友可以参考一下!想了解更多相关信息请持续关注我们应届毕业生考试网!指针为什么要区分类型:在同一种编译器环境下,一个指针变量所占用的内存空间是固定的。比如,在16位编译器环境 下,任何一个指针变量都只占用8个字节,并不会随所指向变量的类型而改变。虽然所有的指针都只占8个字节,但不同类型的变量却占不同的字节数..._c语言带括号指针
缅甸文字库 缅甸语字库 缅甸字库算法_0x103c-程序员宅基地
文章浏览阅读9.5k次。字库交流 QQ:2229691219 缅甸语比较特殊、缅甸语有官方和民间之分,二者不同的是编码机制不同,因此这2种缅甸语的字串翻译、处理引擎、字库都是不同的。我们这里只讨论官方语言。 缅文、泰文等婆罗米系文字大多是元音附标文字,一般辅音字母自带默认元音可以发音,真正拼写词句时元音像标点符号一样附标在辅音上下左右的相应位置。由于每个元音位于辅音的具体位置是有自己的规则的,当只书写..._0x103c