密码学(二月最佳)_密码学置换g置换-程序员宅基地
技术标签: 算法 AI安全:抵抗现代高科技威胁
《主干目录》
第一代加密
第二代加密
第三代加密
第四代加密
第五代加密
第六代加密
第七代加密
密码学数千年的发展史,加密与解密不断博弈。
加密解密算法层出不穷,因此抓住密码学发展史来突破复杂的表面,看懂密码学最基础的原理。
您,愿意听我讲述吗?
. .. . ..
密码学演化进程(系统学习)
【古典加密】
- 手工加密
- 隐藏法
- 移位法和替代法
- 维尼吉亚加密
- 机器加密 【 图灵极限 】
- 恩尼格玛机
【现代加密】
- 计算机加密【 工程技术最大推动力 】
- DES魔王加密系统
- RSA加密系统
- 量子加密
- WIFI 破解
上面的内容全部更新完了,不过我还想补充一些上去。
【程序代码】
简单加密解密写代码, 默认C语言
- 行列互换
- 凯撒加密解密
- 凯撒加密暴力破解
- ASCII码全部字符加密解密与破解(凯撒演化)
- 字符串安全输入选择
- 摩尔斯电码加密解密(Python)
- 单套密码频率分析
- 维吉尼亚加密解密
- 维吉尼亚钥匙长度破解[重合互指数法、Kasiski测试法](更新ing...)
- 多套密码频率分析(更新ing...)
- 循环移位加密
- 打印二进制 ASCII 表
- 伪随机数算法解析
- C标准库 rand( ) 函数伪随机数破解
- 打造伪随机字符池实现真随机数
- Marsaglia 首创 Knuth 的真随机数算法
- 异或加密、改进
- 异或+循环位移加密图片实战
- 大数计算(算法专栏的算法司南)
复杂加密解密以写好的框架解析,根据加密术原理写代码
- DES(DES加密(C) + 位操作 or DES加密(java))
- RSA(RSA加密(C) + 素数)
- SHA
- MD5
- RC4
- AES
- AES + RSA(更新ing...)
- Shor 休尔算法(更新ing...)
【基础数学知识】
- 我已经写好了初学数论,不过还有一些证明没加,持续更新。
加密的原则 :假设敌方已经拥有和自己一样的解密水准,接着在这个基础上制定加密手段,此加密方法要好用,不能一条信息几分钟还没发出去,要求加密解密时间短,成本低。
数学的建议 : 加密的过程可以看成一个函数的运算,解密的过程可以看成是反函数的运算。原文是自变量,密文是函数值。
好的(加密钥匙)函数不能通过几个(原文)自变量和(密文)函数值就可推出函数。
这篇博客就是以上面的内容展开的,其中加密术的理论是零基础的。代码编写能力在实现计算机加密算法要求颇高,不过我已经为您提供了最典型的代码片段减少编写难度~
另外,精心配备如下资料,可降低计算机加密难度:
第一代加密
隐藏法
历史上,第一个加密法由希罗多德古希腊历史学家记载。那时,强盛的波斯帝国计划入侵希腊,斯巴达的老国王得证实后,在一块木板上些许这个消息并涂上一层蜡。这块木板躲过沿路士兵的检查,抵达斯巴达。收板人刮了蜡,就发现了下面的密报,于是马上备战。在公元前480年,击毁了波斯200艘战舰,5年的准备毁于一旦。
希罗多德的记录,
- 保密信息写在送信人已剃光头发的头皮上, 等头发长出来后,让其去送信只是时长要月算,时效性不好;
- 消息写在绸缎上,用蜡裹成一个小球,让送信人吞下去,收信时想办法取出来;
- 熟鸡蛋壳上用 明矾和醋 组合的药水 写密文这样蛋壳上不会有任何痕迹,剥了皮就能看见蛋白有字;
中华加密传说,
- 相传安徽省凤阳县的农民朱元璋等人于中秋节前夕把“杀鞑子”的纸条包在月饼里,号召各家各户杀掉统治汉人的蒙族鞑子,后来朱元璋果真推翻元朝统治建立了明朝,自称明太祖。
- 又一传说云,北宋年间,辽国奸细王钦若打入宋朝内部“卧底”,官至“枢密使”,辽国为了送密信给王时逃避路上盘查,竟把传书人的大腿切开,把密件腊丸塞入大腿的肌肉里,等腿伤痊愈后,再去宋朝,见到王钦若,此人把腿切开,把密件交王执行!
- 《唐伯虎点秋香》使用一种行列互换,只能说有文采让人行列都读的像是一篇文字
- 《龙游天下》丁五味借国主宰县令,用乌贼?肚里的墨汁写借条,日久渐消;
柠檬加密:
加密:用柠檬汁写在白纸上的字,干了以后就看不见了。
解密:用电吹风一加热,字迹就能显现出来,这因为柠檬的酸性腐蚀了纸张。
解密: 只需要受过专业训练的士兵检查严格(留意 蜡板、头发颜色,熟鸡蛋直接剥壳),那么类似的隐藏术是毫无用处的。
《唐伯虎点秋香》行列加密,
- 我唐寅今年十八属姑苏人氏身家清白素无遇犯只
- 为家况清贫留身华相府中充当书僮身价银五十两自
- 秋节起暂为僧房仆三年后支取从此次承值书房每日焚
- 香扫地洗砚磨墨等等听贫使唤从头做起立此为据为凭
因为中文加密需要考虑编码的问题,因此以英文加密举例:
- 加密 hello, world !
假设每行 5 个(任选)字母,共 3 行:
h e l l o , w o r l d ! 加密后:h,le dlw lo!or
用 C4droid(android) 模拟出来:
第一行,设置每行为 5 个字母;第二行,是加密;第三行,是解密。
#include <stdio.h> #include <string.h> char *encode(char *buf, int line) { int len = strlen(buf); int nlen; if (len % line != 0) nlen = len + (line - len % line); else nlen = len; char *tmp = (char *)malloc(nlen + 1); char *secret = (char *)malloc(nlen + 1); char *psecret = secret; strcpy(tmp, buf); for (int i = strlen(tmp); i < nlen; i++) tmp[i] = ' '; // 补空格 tmp[nlen] = '\0'; int row = nlen / line; char (*ptmp)[line] = tmp; for (int i = 0; i < line; i++) { for (int j = 0; j < row; j++) { *psecret++ = ptmp[j][i]; } } *psecret = '\0'; free(tmp); return secret; } char *decode(char *buf, int line) { int len = strlen(buf); int nline = len / line; int row = line; char *desecret = (char *)malloc(len + 1); char *pd = desecret; char (*p)[nline] = buf; for (int i = 0; i < nline; i++) { for (int j = 0; j < row; j++) { *pd++ = p[j][i]; } } *pd = '\0'; while (*(--pd) == 32 ) *pd = '\0'; return desecret; } int main(int argc, const char* argv[]) { char buf[] = "hello, world !"; printf("enter a number:> "); int n; scanf("%d", &n); char *secret = encode(buf, n); printf("%s\n", secret); char *desecret = decode(secret, n); printf("%s\n", desecret); free(secret); free(desecret); return 0; }纯 C 实现,行列加密;好的代码一看就懂,压根不需要注释;当然下面的代码都会解释思路和一些标准库函数。

第二代加密
移位法
古罗马时期, 凯撒加密术。对于信件中的每一个字母,会用 ta 后面的第 n 个字母代替。例如,n = 4 时,"China"加密的规则是用原来字母后面第 4 个字母代替原来的字母,即 "A" => "E", 如此,China => Glmre。
解密: 排列组合[非常麻烦,
种可能, n为代替符号数量] 或 9世纪, 阿拉伯人发明 频率分析法破解【概率论的出现】。
凯撒加密术代码实现 : 解决了,加标点符号和截断字符串问题,大小写都是正常输出的 ~
#include <stdio.h> #include <string.h> #include <ctype.h> void EnCesar(char *str, int n); void DeCesar(char *str, int n); const int N = 2048; // 某些场合不建议申请 2幂 的空间,容易被猜出来攻击这个程序 int main(void) { char str[N] = ""; int n; printf("%s","明文 :> "); scanf("%2047[^\n]",str); // 修改scnaf函数遇到空格就停止 ~, 并限制读取长度为2047 while( printf("%s","移位 :> "),scanf("%d",&n), n>25); // 如果n大于25,重新输入,26位刚好不变 EnCesar(str,n); putchar(10); printf("%s -> %s\n","密文",str); DeCesar(str,n); printf("%s -> %s\n","明文",str); return 0; } void EnCesar(char *str, int n) { if( !str ) return; for( ; *str; str++ ) { if( isspace(*str) || ispunct(*str) || isdigit(*str) ) { ++str; continue; // 跳过空格、标点符号、数字 } if( isupper(*str) ){ // 直接用'A' ~ 'Z'形式就破坏了C的可移植性,使用在EBCDIC字符集的机器上将会失败! *str -= 'A'; // 变成 0 ~ 25 *str = (*str+n)%26; // 密文 = (字母 + n) mod 26 *str += 'A'; } else if( islower(*str) ){ // 'a' ~ 'z' *str -= 'a'; // 变成 0 ~ 25 *str = (*str+n)%26; // 密文 = (字母 + n) mod 26 *str += 'a'; } } } void DeCesar(char *str, int n) { if( !str ) return; for( ; *str; str++ ) { if( isspace(*str) || ispunct(*str) || isdigit(*str) ) { ++str; continue; // 跳过空格、标点符号、数字 } if( isupper(*str) ){ *str -= 'A'; // 变成 0 ~ 25 *str += 26; // 避免减n为负 *str = (*str-n)%26; // 密文 = (字母 + n) mod 26,考虑到可读性,我并没有组合,您可以试一下 *str += 'A'; } else if( islower(*str) ){ *str -= 'a'; // 变成 0 ~ 25 *str += 26; // 避免减n为负 *str = (*str-n)%26; // 密文 = (字母 + n) mod 26 *str += 'a'; } } }字符串安全输入选择 : 字符串输入的一些函数,可以跳过~(与密码学没什么关系)
// p.s. C99输入函数fgets(),第一种 指定stdin作为输入流来使 fgets() 模拟 gets() 的行为,要记得fgets()会保留换行符会刷新缓冲区。在最后一个字符读入数组中后,会再写一个空字符到缓冲区结尾处, 所以最多读取比指定输入数量少1个的字符到数组中。考虑性能不推荐使用 char buf[BUFSIZE]; if(fgets(buf), sizeof(buf), stdin); // 第二种,C11使用gets_s()会更安全、兼容gets(),TA只从stdin指向的流中读取,不会保留换行符,同样有一个参数来指定输入最大字符数。如果这个参数为0或者大于RSIZE_MAX、目标字符数组指针为NULL,会退出函数,目标字符数组不会更改。否则最多读取指定数量-1,-1是因为在读入的数组后要补一个空字符。 char buf[BUFSIZE]; if( gets_s(buf, sizeof(buf) == NULL){ // 错误处理 } // p.s. 第三种使用 getchar() , getchar() 返回stdin指向的输入流中的下一个字符。一次读取一个字符在控制上很灵活,也无额外性能开销。 char buf[BUFSIZE]; while( ( ( ch = getchar() ) != '\n') && ch != EOF ) { if(index < BUFSIZE-1) buf[index++] = (unsigned char)ch; 读入数量++ } buf[读入的最后一个] = '\0' //添加错误处理: if(feof(stdin)) { // 处理EOF } if(ferrors(stdin)) { // 处理错误 } if(读入数量 > index) { // 处理截断 } // 如果读取量级数据可使用 fread 优化, 设置头指针 p1 和尾指针 p2,fread 一次读入 1<<21 个字符存在 buf里,然后用 p1 来调用;当 p1 撞到 p2 时再次用 fread 读入 1<<21 个字符······ // fread优化宏定义实现 : #define getchar()(p1==p2&&(p2=(p1=buf)+fread(buf,1,1<<21,stdin),p1==p2)?EOF:*p1++) char buf[1<<21],*p1=buf,*p2=buf; // fread优化函数实现 : char buf[1<<21],*p1=buf,*p2=buf; inline int getc(){ return p1==p2&&(p2=(p1=buf)+fread(buf,1,1<<21,stdin),p1==p2)?EOF:*p1++; } inline int redi() { int ret = 0,f = 0;char ch = getc(); while (!isdigit (ch)) { if (ch == '-') f = 1; ch = getc(); } while (isdigit (ch)) { ret = ret * 10 + ch - 48; ch = getc(); } return f?-ret:ret; } // 第四种 TR 24731-2标准的getline(),如果输入行过长,那么TA不会截断输入而是使用realloc()调整缓冲区的大小 char *buf = malloc(buf_size) if( (size = getline(&buffer, &buf_size, stdin) ) == -1 ){ // 处理错误 } free(buf) buf = NULL; // 防止野指针古典密码最小操作单位都是单个字符或者符号,如凯撒加密术。而现代密码学,把研究对象用数来描述,再对数进行运算。不但突破了,字母作文最小单位对限制,还可以使用更高等的数学工具做运算,因此解密越来越难,但有趣是,解密方所需要的时间越来越少,从4000年的跨度变成1000年现在的频率是几十年甚至更少。
破解:俩种方法 [ 枚举、频率分析 ]
- 暴力枚举,26个字母加密一共25种可能,A是0,移位是不变的。在不知道钥匙的情况下,枚举出来很容易。我们不怕贼,就怕贼有耐心~
for( int i = 1; i < 26; i ++ ) // 第 0 次不用,移位为0不会变化 { // 我们截获的肯定是加密后的密文,所以使用解密函数枚举 移位长度 DeCesar(str,i); printf("%d : %s\n",i,str); EnCesar(str,i); // 解密一次后要复原,下一次还要解密 }
- 频率分析(下文细说)
p.s. 移位法分析工具:https://cryptii.com/pipes/caesar-cipher
再补充一种移位法(感谢红领巾),整个ASCII码字符加密解密与破解算法,原理同凯撒加密。
不过现在不是 26个子母,而是 127个 字符的加密解密与破解~ (p.s. 如果不了解ASCII码表,计算机加密有解释)
#include <stdio.h> #include <string.h> int main(void) { // ASCII 码全部字符加密解密与破解 char key[32] = "[ passWord + 666 ! ]"; // // // 加密 for( int i = 0; i < strlen(key); i ++ ) key[i] += 10086; // 移动 10086 位 puts(key); // // // 破解 for( int j=0; j<128; j ++ ) { printf("%-4d : > ",j); for( int i = 0; i < strlen(key); i ++ ) { key[i] -= j; printf("%c%c", key[i], i+1==strlen(key)?'\n':0); // 方便阅读可以把 0 改成空格 key[i] += j; } } #if 0 // 运行这段代码把 0 改成 1 就好,使用解密代码,破解部分注释掉即可得到key // // // 解密 for( int i = 0; i < strlen(key); i ++ ) key[i] -= 10086; puts(key); #endif return 0; }答案在 102 次枚举,这个程序的破解(代码在上面)枚举 127 次 可以得到明文key。但这里有一个值得思考的地方,当 10086(移位数)换成多少值,这个程序破解不了?枚举,多枚举几次。
如果让这个破解程序失效,值可以是 n(127+1)~n(127*2-1),n为任意整数,0除外。
那么怎么改进呢,只需要改动破解代码的一个地方,就可以解决这个问题~加油!
移位法,用这个改进版的话无论你加多少或者减多少位都可以在 枚举 255 次以内破解得准确的密钥key。
p.s. 把 j = 0 改成 j = -127
打印出来有许多的乱码,实际上乱码肯定不是原文,所以使用程序排除。程序再次改进,乱码在ASCII码乱码即不是英文标点符号、阿拉伯数字、26个字母大小写。代码如下,也只需要添加俩个语句一个判断、一个换行~
// // // 破解 for( int j=-127; j<=127; j ++ ,putchar(10) ) { printf("%-4d : > ",j); for( int i = 0; i < strlen(key); i ++ ) { key[i] += j; if( isprint(key[i]) ){ // 如果 key[i] 是英文标点符号、0-9、A-Z和a-z、空格 , 就输出。这样就去乱码了。 printf("%c%c", key[i], i+1==strlen(key)?'\n':' '); } key[i] -= j; } }这样只需要找到最长的字符串对比 12 次,刚好他们一定是连续的~
更重要的是,如果TA的密文里面有乱码(非ASCII里面的字符可能是一个表情或爱心?),那一定要跳,不然会导致破解只能破解数字部分。不过,我们理想环境接受的密文都是 ASCII 的...
暴力破解法总结,为什么暴力总结的这么早。还不到这篇博客的 一半的一半,因为暴力破解遇到后面的加密术会被虐成渣。得知道越是晚的加密术都有防范前一代加密术的解密法。
使用暴力破解的经验:
- 试想暴力破解法是否可行
- 限定范围再排列组合破解
举个例子,试想是否可行,理想环境为别人家中。
>>判断可行,假如您要偷一本书,首先您得确定TA在不在这户人家。如果不在就找不到也就不找,所以不用暴力破解。
>>限定范围,如果在家里是在A房间还是B房间,在某个房间里我们应该带着高科技工具按顺序扫描书柜。
替代法
从16世纪的苏格兰女王玛丽一世说起。玛丽一世 27 岁时,被自己的姑姑英格兰女王伊丽莎白一世关押了起来,这一关就是 18 年。到 ta 44 岁时,监狱里的她和外界反叛军密谋要杀害姑姑,一旦谋杀成功,ta 自己就能登上王位。当时传信件是由侍女在递红酒时,藏在瓶塞中带进去的。
玛丽很聪明,包含暗杀计划的并不是普通的信,而是加密过的。用的加密法便是替代法。所有英文字母被类似符文的东西替换,一些常用词也用符号代替。代替方式,如下图。
如果没对照图,谁也不能看懂,是吗 ~ 玛丽此后就用这个加密方式与反叛军
(我觉得谁永远的输了,谁就是叛军),一段时间后,玛丽熟练掌握了,也不用一一对比来写。这体现对加密的要求,不复杂实用。 可惜,这个传信的人是双面间谍,这些情况伊丽莎白全部知晓了。在位的女王正愁拿玛丽没办法,现在终于可以言正名顺的处死玛丽了。不过现在还急不得,必须抓到足够硬的证据,而且最好把整个阴谋背后所有参与者一起除掉。此后,玛丽和外界的通信,每一封都先经过双面间谍送到密码学校,花一定时间誊写好,接着密封好递出王宫。
那么,密码学校成功了吗?? 这么难的密码呀 ?先看看著名的 摩尔斯电码 ,再回来讨论。

摩尔斯电码
-- 与此类似的,还有著名的摩尔斯电码。

详细介绍 : https://en.wikipedia.org/wiki/Morse_code
借助 Python 的字典 实现摩尔斯电码的加密解密,
# 莫尔斯电码表,保存在字典中可以根据数组下标提取值一样方便, A是 键 相当于数组下标,'._'是值相当与数组值
MORSE_CODE = { 'A':'.-', 'B':'-...',
'C':'-.-.', 'D':'-..', 'E':'.',
'F':'..-.', 'G':'--.', 'H':'....',
'I':'..', 'J':'.---', 'K':'-.-',
'L':'.-..', 'M':'--', 'N':'-.',
'O':'---', 'P':'.--.', 'Q':'--.-',
'R':'.-.', 'S':'...', 'T':'-',
'U':'..-', 'V':'...-', 'W':'.--',
'X':'-..-', 'Y':'-.--', 'Z':'--..',
'1':'.----', '2':'..---', '3':'...--',
'4':'....-', '5':'.....', '6':'-....',
'7':'--...', '8':'---..', '9':'----.',
'0':'-----', ', ':'--..--', '.':'.-.-.-',
'?':'..--..', '/':'-..-.', '-':'-....-',
'(':'-.--.', ')':'-.--.-' }
def encrypt(message):
cipher = ''
for letter in message:
if letter != ' ':
cipher += MORSE_CODE[letter] + ' '
else:
# 每隔一个字母空1格,每隔一个单词空2格
cipher += ' '
return cipher
def decrypt(message):
message += ' '
# 要在解码的摩尔斯码末尾加一个空格 用作检查提取字符并开始解码
decipher = ''
citext = ''
for letter in message:
if (letter != ' '):
# 检查空格,i 统计空格的数量
i = 0
citext += letter
else:
i += 1
if i == 2 :
# 俩个空格是新单词
decipher += ' '
else:
decipher += list( MORSE_CODE.keys() ) [list( MORSE_CODE.values()).index(citext) ] # 使用键值访问键(加密相反)
citext = ''
return decipher
def main():
message = "Earphones- Primetime Sexcrime"
result = encrypt(message.upper())
# 明文加密编成莫尔斯电码
print(result)
message = ". .- .-. .--. .... --- -. . ... -....- .--. .-. .. -- . - .. -- . ... . -..- -.-. .-. .. -- ."
result = decrypt(message)
# 密文解密翻译为英文原文
print(result)
if __name__ == '__main__':
main()
加密:
一次从一个单词中提取一个字符,如果不是空格就与相应莫尔斯码匹配,是空格就再加一个空格因为新单词要间隔
将莫尔斯码存储在一个字符串的变量中,以后就在这个字符串变量中循环累加新的明文或密文
p.s. Python的字典在这里非常好用,在C++里面叫map。解密原理一样
好了,继续讨论 玛丽女王 ~
恺撒密码可以通过暴力破解来破译,但替换密码很难通过暴力破解来破译,这是因为替换密码中可以使用的密钥数量,比撒密码多得多。
为了确认这一点,我们来计算一下简单替换密码中可以使用的密钥总数吧。
p.s.一种密码能够使用的“所有密钥的集合”称为密钥空间( keyspace).所有可用密的总数就是密钥空间的大小。密钥空间越大,暴力破解就越困难。
替代密码中,明文字母表中的a可以对应A、B、C、D .... Z (这26个中的任意一个26种),b可以对应除a所对应的字母以外的剩余 25 个字母中的任意 25 种,以此类推我们可以计算出替代密码的密钥总数为:
26 × 25 × 24 × 23 × ... × 1= 4032914611266056355840000 =
这个数字相当于 4兆的约1000兆倍,密钥的数量如此巨大,用暴力破解进行举就会非常难。因为即便每秒能够遍历 10亿 个密钥,要遍历完所有的密钥也需要花费超过 120亿年 的如果密码破译者的运气足够好,也许在第一次尝试时就能够找到正确的密销,但反来说如果运气特别差,也许尝试到最后一次才能找到正确的密钥因此平均来说,找到正确的钥匙也需要花费约 60亿年 的时间。
解密 :ta的破解方法是 频率分析,由9世纪的阿拉伯产出,直至16世纪才被欧洲数学家注意到。
频率分析
原理,英文中字母出现的频率,是不一样的。比如,字母 e 是出现频率最高的,占 12.7%; 其次是 t,9.1%; 接着是 a, o, i, n 等,最少的是 z,只占 0.1% ,见下图,英语字母频率统计。

| 26个英文字母 | 频率 |
| e | 12% |
| t---a---o---i---n---s---h---r | 6%--9% |
| d---l | 4% |
| c---u---m---w---f---g---y---p---b | 1.5%--2.8% |
| v---k---j---x---q---z | < 1% |

另外,其他语言也有详细统计。e.g. 法语、德语、西班牙语、葡萄牙语、世界语 ...

玛丽和外界用密文往来很多,字符总量足够多,收集到一起,统计哪个符号出现的比例最高,那个字符大概就是字母 e。 也会有,字母出现的频率极为接近,如 h、r、s,分别是 6.09%、5.98%、6.32%。但只需要留意字母前后关联,便可区分开了。e.g. 字母 t 几乎不可能出现在 字母 b、d、g、j、k、m、q 左右,而 字母 h 和 字母 e 经常连在一起, ee 一起出现的频率远大于 aa 一起出现的频率,如此等等。
频率分析法的实质,便是大幅度减低字母排列组合的可能性,上面的条件如同中学的排列组合题。把 种可能减少为线性,有的减为只有 1、2 、3 可能,均摊下了依然是线性。这样一来,即使第一步的统计各种符号出现的频率时并不完全确定,但只要第二步,以拼写规律筛选一下,代替符号对应但真实字母就可以找出来。
在审讯过程里,尽管玛丽始终不承认谋反,但证人和密码学专家一起向公众展示密文和原文,并告之解密规则,最后故事完了。想知道玛丽但结局,还不如和我讨论一下这个程序怎么实现呐 ~
上代码,单套加密频率分析法:
#include <stdio.h> #include <ctype.h> int main(void) { double number[32] = {0.0}; // 实际只要开辟 26 个对应字母表 26个字母 size_t cnt[32] = {0}; // 大写字母计数数组,也可以不用 FILE *fp = NULL; size_t total=0; printf("%s","input test file name:> "); // 如果觉得输入麻烦,可以省略这一段代码。 char file_name[128] = ""; scanf("%127[^\n]",file_name); // 限制读取长度为 127 fp=fopen( file_name,"r" ); // 可以使用 while循环+逗号表达式重写打开文件失败的代码段,不熟悉可以看看上面的凯撒加密术写法,add一个清空缓冲区 if( fp != NULL ) while( !feof(fp) ){ char c=fgetc(fp); if( isupper(c) ){ // 'A' ~ 'Z' number[c-'A']++; total++, cnt[c-'A']++; } else if( islower(c) ){ // 'a' ~ 'z' number[c-'a']++; total++; } } else printf("fail to open %s\n",file_name); fclose(fp); double rate; for( size_t i = 0; i < 26; i ++ ){ if( number[i] != 0 ){ // 找出出现的字母 rate = ( number[i] / total )* 100; printf("%c,%c : %0.3f%%\t, 其中 %c 出现 %u 次\n",'A'+i,'a'+i,rate, 'A'+i, cnt[i]); } } return 0; } // 排序,希望交流希望交流测试结果如下: [可以改写,概率取整、排序,选的文本是一段官方文档,数据越多越准确]
分析的是明文(没有加密),文章所以看到使用频率最高的是 e ,概率也是十分接近上面的图示。而我们测试的一般是密文,已经加密过我们不知道钥匙,就可以用频率分析。假如其中有俩个字母 x、y 是这段文本测试出来出现频率最高的,而且 x = y,那么先用e代替x字母,而后其他字母也按频率顺序代替;重新开始下一次排列组合这次用字母e代替y,而后其他字母也按频率顺序代替。代替做完了,一个单词出来可能是这样 : thlee ,解密方分析没有这个单词,那么换成three等继续组合,最后解出来只是时间问题 !
p.s. 频率分析方法总结:
- 除了高频字母以外,低频字母也能够成为线索;
- 搞清开头和结尾能够成为线索,搞清单词之间的分隔也能够成为线索;
- 密文越长越容易破译;
- 同一个字母连续出现能够成为线索 因为在简单替换密码中,某个字母在替换表中所对应的另一个字母是固定的;
- 破译速度会越来越快
- ... ...(密码学家独门方法,拿出来就是砸饭碗然我不会。)
- 英语中出现频率最高的12个字母可以简记为“ETAOIN SHRDLU”。除了出现当个字母有概率,俩个字母一起也没有概率呢?比如ST、NG、TH,以及QU等双字母组合出现的频率非常高,NZ、QJ组合则极少;
- 在所有的三字母组合里,组合 the 出现的频率最高;
- 大部分情况,句中出现的单字母的单词且该字母大写的是 I;
- 大部分情况,句中出现的单字母的单词且该字母小写的是 a;
这回解密赢了加密,不过很快又有了新的加密法来针对频率分析,ta 叫同音替代法。
p.s. 字母出现频率分析工具:https://www.dcode.fr/frequency-analysis
同音替代法
史上最有名的采用同音替代法的密码,是法国国王路易十三、十四时期的 "Grand Chiffre"。ta使用40多年,随着拿破仑的倒台突然失传。直至1890年,才被完整的破解,破解方法就是从单词拼读规律入手的。这套加密法用了 587 种数字,来表示不同的发音。其中包含大量陷阱,如,一些数字只代表字母,不代表发音;很多数字只为干扰字符,ta们没有意义;还有一些数字即不是发音又不是字符,而是代表删除前一个字符。
666解密:为了更好的说明,我举一个具体的例子哈。字母 a 可以用 11、23、41 仨个数字代替,这三个数字翻译过来都是 a ,越常常用的字母,如上文说的 字母e ,就用越多的符号代替它。这种想法的目标,就是让每个数字出现的频率大致相同,频率特征没有了,密码就不容易被破解。具体,见下图。
怎么破解 ?
思考 3 min...
怎么破解 ?
我们聊一聊数学,您看懂了就发现解密很大程度不就是数学的概率论嘛。当年,概率论的诞生,正是一个赌徒数学家 Girolomo Gardano 研究概率出现的,著有《论赌徒的游戏》,ta也是三元方程一般解法的发现者,更是导致玛丽悲剧结果的发动机。
数学的发展,有俩个高峰。
- 一个是公元前 500 年到 公元前 300 年,之后一直下划到公元 500 年跌到谷底。
- 1000年后,玛丽女王的时代,才超越古希腊巅峰时期的水平,到现在也还没出现最高值。
另外,玛丽TA并不是同时代的另一个玛丽("血腥玛丽"),玛丽是苏格兰女王,血腥玛丽是英格兰女王,虽然同时代但不是同一个人。
命运可谓,从英格兰国王要把一个侍女扶正为女王遭到罗马教廷的反对开始,就注定了玛丽一生的不幸,那时玛丽才一岁。
怎么破解呢 ?
其中的一种方法是,通过字母的前后顺序关系枚举瞎猜。
e.g. 字母q 后面出现最大可能是 字母u,而字母q又是一个不常用的字母,有很大概率猜中。其 ta 字母猜出来的难度大一些,但只要肯花时间,总能破解出来。
数学理论: 数理统计中的大数定律。当样本的容量趋于正无穷时,就可以归纳为频率收敛于概率。我们发现字母Q后面容易跟U,自然而然就排除了很多没有必要的情况。
概率论出现之后,采用移位法和替代法的加密一方,输了一局。但,加密一方并不情愿更不会罢休。维吉尼亚加密法 大概您早有耳闻,
ta 的出现唯一目的便是为打破 频率分析[让字母的频率特征消失]。做出这套加密法的是法国外交官 布莱斯· 德 · 维吉尼亚。
考虑到当时欧洲外交官不断的通信需求、数学也是法国国学
[法国数学家:笛卡儿、韦达、嘉当、韦伊、格罗滕迪克、达朗贝尔、拉格朗日、拉普拉斯、柯西、伽罗华、阿贝尔、梅森、费马,帕斯卡,勒让德,彭赛列、彭加勒、蒙日,傅立叶,柯西,伽罗瓦,埃尔米特,庞加莱......],普遍认同是法国维吉尼亚,而不是德国炼金术士和意大利诗人,这里只为指出一个规律 --- 如果一知识产权,有人几乎同时发现或发明,那么 ta 的出现是必然,这也代表或许这以后会是一个行业,如电话的发明之争 贝尔与梅乌奇,因为这个领域已经形成了成熟的市场和产业。
18 世纪时,欧洲各国都有致力加密解密的部门,叫"Dark room hall",ta 们与邮政系统配合运行。每天有许多信件本来是从各地寄到邮局,再从邮局分发出去。而 "Dark room hall" 的工作便是,解密所有寄给当地大使馆的信件,如最著名的维也纳 "Dark room hall" ,信被偷偷取给专业的速记员,让其抄录好内容,再小心的把信封好,三小时内送回邮局,邮局再按正常流程递送给大使馆。那时候,各国都在重要信件上使用了加密法,不过移位法和替代法的混合,依然没有太多的作用,破译只需要一天甚至几个小时。破译原理便是频率分析法。一些国家除了自己看信,还暗自把消息卖给其他国家的情报部门。没过几年,很多国家觉察到自己的加密可能是失效了,这也催生了下一代加密法。
为了更好的理解新的加密法,我们先回顾一下第二代加密法[移位和代替法] 存在的漏洞。破解第二代加密法的原理是因为每个字母实际使用的频率是有固定值的。所以,不论那些字母被什么符号代替或者移位了,都可以从频率上找出 ta 的真身。
玛丽女王就生活在加密输于解密的年代。其实在玛丽被 砍头 的 40 年前
[没错,结果便是如此],据说当时刽子手第一刀砍下的时候,脖子并没有被砍断,玛丽当时对着刽子手呵斥:“把你该做的事做好!”这句话,吓得刽子手直哆嗦。砍了三刀之后,刽子手拎起玛丽的头颅示众,才发现那一头乌黑的长发原来是假发,假发套下已经满是花白的头发了,玛丽的嘴唇这时还在微微嘟囔着。
当另一个刽子手挪动玛丽的尸身的时候,突然,一只生前时常陪伴她的小狗,从长袍下跑了出来。这个刽子手赶了几次,都没赶走,每次小狗都又跑回玛丽的身边不肯离去。
这就是玛丽的一生的结局,是苏格兰国王的女儿注定了TA一生的不幸,幸福的时光只在16岁前。解密不成功,玛丽也是一样的结局,只是一场没有充足证据的死刑判决。再退一步说,假如她因为胆小压根就拒绝了暗杀伊丽莎白一世的计划呢?其实得到的结果就是,生活条件逐渐恶劣的一生的囚禁。
四百多年后的今天我们知道,其实英国始终就没能再回到天主教。退一万步说,玛丽当初就算暗杀成功了,成为了英格兰的女王,大概率说,她还会在后续的夺权中被反杀。
想到这里,相比所有的可能性,宁愿是由密码学的研究突破导致证据足够确凿,玛丽才被判死刑这个结局。
新的加密法已经出现,ta 是替代法的改进版,叫 "多套符号加密法"。
为了掩盖字母使用中暴露的频率特征,解决办法就是用多套符号代替原来的文字,如 原文字母A,从前只把 ta 替换成 F,现在把 ta 替换成 F 或者 G 这俩个。那什么时候用 F 什么用 G 呢 ?自定义即可,比如说,字母在奇数位时用 F 代替,字母在偶数位时用 G 代替。从前单套字符替代的时候,凡是文字中频率为 7.63% 的符号,差不多就代表 A 了。但现在 A 由 F 和 G 混合在一起, 7.63% 的频率不可能再出现了,哪个符号是 A 也就没人知道了,于是频率分析法就暂时失效,这里只是想说的形象,实际频率分析依然可行。
第三代加密
维吉尼亚加密法
是TA, 是TA,就是TA。第三代加密法,不似第二代加密法,只使用 2 - 3套符号加密,维吉尼亚使用了整整 26 套字符加密。TA 是一个表格,第一行代表 原文字母,下面每一横行代表原文分别 由哪些字母代替,每一竖列代表我们要用第几套符号来替换原文。一共 26 个字母,一共 26 套代替法,所以,这个表是一个 26 * 26 的表,如图。
TA 具体是怎么加密呢 ??
假设我要加密 "Hello, world !",现在的思路不同于单套加密方法。单套加密时,我们可以指定上面表格任意一行,比如指定第 16 行,原文的字母后移 16 位,只使用这一行的规则,"Hello, world !" 就变成了 "Xubbe, mehbt !"
但我们是多套加密,于是加密规则是这样:
- 第一个字母用 第 2 套加密
- 第二个字母用 第 4 套加密
- 第三个字母用 第 8 套加密
- 第四个字母用 第 16 套加密
- ... ...
- 最后一个字母用 第 2 套加密
事实,这只是一个程序的风格,采用
循环同余加密。大部分人更多的是伪随机。随机,因为没有规律,每个字母移动多少位都需要单独指定,如果只是 "Hello, world !", 我还能接受,可是我们是写信人呢 ? 一封信至少是 100 个单词,500个字母吧。这样不但加密麻烦,解密也费劲,只能拿表一一对照,还原每一个字母,耗时耗力也易错。 在入门密码学开始,我便强调,如果一个信息几分钟都没发送出去,那么这种加密方法是不会被采用的。事实上发明开始直至200年后,维吉尼亚加密法,虽然加密强悍[破解难度指数级增加],可几乎没人用呀,也是这个原因。以玛丽女王举例子,当年的玛丽用了一段时间的代替法,便可不看暗文熟练读写。如果 ta 用维吉尼亚加密法,虽然,解密方破解不了,可这么复杂的表格,恐怕只有记忆大师才能在一段时间了然于胸。在这个 加密法为 26 * 26 的表格,而且还有长短不一的移位数,每加密一个字母,都要在表格里找了又找。就算 玛丽 熟练操作加密一个字母也得花 3秒 时间,写一封 100单词,500字母的信,要 25分钟 的高强度加密,不仅超过了加密原则也易错
[我试了一下,Hello,World , 全军覆没]。直到这个加密问题解决了,维吉尼亚才被 1861-1865年的美国南北战争广泛使用。使用维吉尼亚的主要原因就是科学技术的发展,加密解密的工作已经交给机器完成。1860年时,不但有蒸汽机,还有电动机,机器运算快且不会出错。第三代的维吉尼亚加密法,在真实使用时,人们事先规定每一个字母用了哪套移位法时,并不是随机的指定,而是约定了一个规则,这个规则叫 "钥匙?"。




钥匙最初只是一个单词,如,钥匙是 "i s k e y",
字母 i 是字母表第 9 个字母也是钥匙第 1 个字母,就代表加密使用第 9 套符号加密,即原文第一个字母后移 9 位,
字母 s 是字母表第 19 个也是钥匙第 2 个字母,就代表加密使用第 19 套符号加密,即原文第二个字母后移 19 位,
后面字母 k、e、y 的同理。那么钥匙现在比完了,那后面的怎么办呢,好办,就按照刚刚的规则循环一下就好,我想看完这个过程,您心理已经对代码实现有一个大致思路了吧。
为了分别演示,只采用第一套字母表。
第一套字母表顺序:
1:A 2:B 3:C 4:D 5:E 6:F 7:G 8:H 9:I 10:J 11:K 12:L 13:M 14:N 15:O 16:P 17:Q 18:R 19:S 20:T 21:U 22:V 23:W 24:X 25:Y 26:Z原文: Hello, World !
钥匙: iskey [下面的程序只采用大写因为大写小写顺号相同]
明文 [密钥-移动数] 密文 H = [i-9] => R e = [s-19] => m l = [k-11] => y l = [e-5] => r o = [y-25] => y , 跳过 W = [i-9] => E o = [s-19] => b r = [k-11] => x l = [e-5] => v d = [y-25] => l ! 跳过Hello, World ! = 》 密文 : Rmyry, Ebxvl!
所以,维吉尼亚加密法的使用,加密方 胜出。
上代码,多套加密维吉尼亚加密法 [ Virginia ]
#include <stdio.h> #include <ctype.h> #include <string.h> const int N = 1024; int main(void) { char txt[N] = ""; char key[32] = "KING"; // 默认,密钥Key优化建议,如果出现相同字母去重 FILE *fp = NULL; size_t cnt = 0; printf("%s","input test file name:> "); // 如果觉得输入麻烦,可以省略这一段代码。 char file_name[256] = ""; scanf("%255[^\n]",file_name); while( printf("%s"," KEY :> "), scanf("%*[^\n]"), scanf("%*c"), // 清空缓冲区 scanf("%26[A-Z]",key), // KEY : 输入大写字母才有用(想要小写也简单,改成 "scanf("%26[a-z]",key)" )。如果前面没有 scanf 输入文件名,那么输入key 要和 清空缓存区语句 对调顺序 !*key || islower(*key) ); fp=fopen( file_name,"r" ); if( fp!=NULL ) while( !feof(fp) ){ char c=fgetc(fp); if( isupper(c) ){ // 'A' ~ 'Z' txt[ cnt++ ] = c; } else if( islower(c) ){ // 'a' ~ 'z' txt[ cnt++ ] = c; } } else printf("fail to open %s\n",file_name); fclose(fp); size_t k_len = strlen(key); // 俩种情况. 原文字母大写小写分别处理 加密 printf("%s","密文 :> "); for( int i=0; i<cnt; i ++ ){ if( isupper(txt[i]) ){ txt[i] += key[i%k_len] - 'A'; txt[i] = (txt[i] - 'A') % 26 + 'A'; printf("%c",txt[i]); } else if( islower(txt[i]) ) { txt[i] = txt[i] + key[i%k_len] - 'A'; txt[i] = (txt[i] - 'a') % 26 + 'a'; printf("%c",txt[i]); } } putchar(10); printf(" KEY :> %s\n",key); // 解密 printf("%s","原文 :> "); for( int i=0; i<cnt; i ++ ){ if( isupper(txt[i]) ){ txt[i] = txt[i] - key[i%k_len] + 'A'+26; txt[i] = (txt[i] - 'A') % 26 + 'A'; printf("%c",txt[i]); } else if( islower(txt[i]) ) { txt[i] = txt[i] - key[i%k_len] + 'A'+26; txt[i] = (txt[i] - 'a') % 26 + 'a'; printf("%c",txt[i]); } } return 0; } // 程序可优化的地方,其一 输出的时候每个词间加空格,其二 钥匙KEY 支持多个单词,希望指点一下,但不需要指指点点。钥匙是一个很重要的概念,现代加密都是以钥匙为主。
破解维吉尼亚:
- 从密文中找出拼写完全相同的字符串,尤其是一些长度大于 4 重复出现的密文。如,一篇几百个字母的密文中,长度超过 4 ,且重复出现的字母串一共有 4 种,我们就把它们叫做甲乙丙丁。我们举一个具体的例子见下图,假如,此时字符串甲是 : "the sun and the man in the moon",钥匙是KING,密码文是一串看起来没什么规律的字母。这3样,我们现在都知道。
原文 t h e s u n a n d t h e m a n i n t h e m o o n KEY K I N G K I N G K I N G K I N G K I N G K I N G 密文 d p r y e v n t n b u k w i a o x b u k w w b t
原文,有 3 个定冠词 the,变成密文后,the 有的形式,
- D P R
- B U K
- B U K
2. 数一次,甲乙丙丁第一次和第二次出现的间隔。如,字符串甲重复间隔为 20 个字母,ta 代表这段密文对应的钥匙,是在这 20 个字母中,正好反复使用了若干次。
- 如果钥匙长度为 2,钥匙会反复使用 10 次
- 如果钥匙长度为 4,钥匙会反复使用 5 次
- 如果钥匙长度为 5,钥匙会反复使用 4 次
- 如果钥匙长度为 10,钥匙会反复使用 2 次
- 如果钥匙长度为 20,钥匙会正好使用 1 次
- 推出
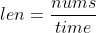
- len : 钥匙长度 、 nums : 间隔字母数量,如 the 间隔 8 、 time : 同样的密文单词出现次数,如 the 2次同样
字符串乙丙丁处理相同,再查查 ta们 间隔数的因数,找出共同的因数,这个因数对应钥匙的长度。
知道钥匙的长度,那么对应的密文就变成了单套移位加密法,如,钥匙是 iskey , 测试出长度为 5。
密文的第 1、6、11、16、21、26 ···,这些字母是同一套加密字母,记 A 组
密文的第 2、7、12、17、22、27 ···,这些字母是同一套加密字母,记 B 组
··· ···
这些关系分析出来,接着用 频率分析法 解析出现频率最高的字母。
可如果原文还没密钥长,或者?️重复的单词,哪怕知道钥匙长度,用频率分析也不能破解出来。不过,还有别的方法。 密码学主要用的场景,原文是很丰富。
最后,再总结一下破解维吉尼亚加密
step-0: 找到钥匙长度
重合互指数法求密钥 [根据密钥的长度对密文进行分组,每一组都是一个凯撒加密。计算拟重合指数,通过拟重合指数可以确定每组的移位密钥,从而求出整个的密钥]
Kasiski测试法 [搜索长度至少为2的相邻的一对对相同的密文段,记下它们之间的距离。而密钥长度d可能就是这些距离的最大公因子]
上面的俩种求共享代码推荐资料也行,也欢迎补充新的方法
step-1: 根据钥匙长度分组找出位移规则
step-2: 知道所有位移规则让维吉尼亚从
种可能性,变成了基础的移位法。
step-3: 用频率分析法即可
难以破解的原因:同样的原文对应上亿种密文,相同的密文也一样对应上亿种原文。
相比上文的同音替代法,最多只能一种原文对应 N 种密文,而且 N 一般不会超过 10 的,但反方向上密文一定只对应一种原文。
代码我先垫垫,回过头再写破解代码,欢迎交流。得抓主要因素,才可以提高效率。
这是维吉尼亚的最初版本,ta 第二次改版是以随机字母充当钥匙,理论上比起用一个单词循环匹配,大大提高安全性,可这也是 ta 失败的一个地方,这个随机字母 一般选为文章或者是诗。解密方,哪怕只推动了某个单词的前几个字母,也可以猜出来。后来,维吉尼亚又改版,采用真正的随机字母单钥匙别名 "单次钥匙谱"。一战时,每个国家通讯部中就有一本厚厚的书,里面全是随机字母,用完一页,就用下一页。数学理论证明,这样的加密法是无法破解的,不过这样的加密解密也是相等繁琐,一战后,基本没用过了。
密钥优化建议:如果存储密钥的数组有重复单词,去重只保留一种字符。
复习一下古典加密
| 加密术 | 算法原理 | 钥匙(密钥) | 实例 |
| 移位 | 明文的各字母按指定的字母数平移 | 平移的字母数量 | 恺撒、ASCII码表 |
| 替换 | 按照替换表对字母表进行替换 | 替换表 | 替代、同音替代、维吉尼亚 |
初次学习密码是不是有点烧脑。 没关系~ 不急的,我们轻松一下,和您聊聊小说 ,我小时候看的《神勇小虎队》

我觉得挺好看的,ta有一小章里面有一个以密码为线索的故事。图上三个战友被困住了,他们给出了一串数字给对方。
如 196 03 17 ,这是一个密码哦。
解密是这样,他们选择了一本书《神勇小虎队》,这串数字前 3 位是这书的第多少页 即 196页,第 4~5 位数字 03 代表是这一页的多少行即 第 3 行,第 6~7 位数字 17 是代表这行第 多少 个字即 第 17字。二战时的日军加密和康熙年间的加密同。
简单吧,ta 就是比尔密码,1920年到1979年,有一部分美国人超级想破解这些数字因为这些数字的背后是 4300 万美元哦,比尔密码的加密解密是以参照物自定义的。
比尔密码
在《比尔密码》记载中,美国西部淘金热的时候,1820年,一个小伙子比尔在弗吉尼亚州的一个小旅馆住了2个月,当时给人印象挺好的,后来不声不响走了。2年后他回来了,又住了2个月,临走时什么话没说,给店老板留下了一个上锁的盒子。几个月后,老板又收到比尔一封信,说盒子里有他和他合作伙伴非常重要的东西,但暂时拿不回去,请老板代为保管10年时间。如果真的超过10年都没人来领,老板就可以自行打开了。
这盒子里除了有一份说明书是可以读懂的,其他文字都是加密过的,解密的钥匙在另一个人手里,这个人会在10年期限到的时候把钥匙内容告诉店主。
老板也确实信守承诺,不止等了10年,等了23年才打开盒子,但那个据说要给他钥匙的人始终没有来信。盒子里除了有份说明书外,还有3封加密的信。店老板花了17年时间也没破解密文,在去世前把这盒子东西交给了他的朋友。到了他朋友手中倒是有所突破,其中第二封信被破解了,其他两封实在没搞懂,他就希望大家一起来努力,下面是比尔密码的第一封信,您可以试着破解,试一下,可不可以拿到 市值 4300万?
第二封信的钥匙即选用的书籍是 《独立宣言》 ,第二封信的内容,如下:
在1819年到1821年,比尔和另外30个合作伙伴分两次把2000多磅黄金和5000多磅白银埋了起来,除此之外还有价值13000美元的珠宝。然后把埋藏地的地形特征详细描述了一下,但没说在哪儿。最后说,具体的埋藏地址在第一封信里,第三封信写了30个合作伙伴的详细信息。
解法:
比尔密码的三份密码都由1-4位的数字组成。已知的第二密码以一种替换密码的方式加密,一般推测其他两份密码也是采取类似的加密方式。由于数字的范围都远超过字母表的字母数,密码对应的密钥可能是某一篇文章。
以第二密码为例,每一个数字代表美国《独立宣言》的文本中的第几个词的首字母,如 1 代表第 1 个词的首字母 “w”,2代表第 2 个词首字母 “i” 。解密后的文字如下:
I have deposited in the county of Bedford, about four miles from Buford's, in an excavation or vault, six feet below the surface of the ground, the following articles, belonging jointly to the parties whose names are given in number three, herewith:The first deposit consisted of ten hundred and fourteen pounds of gold, and thirty-eight hundred and twelve pounds of silver, deposited Nov. eighteen nineteen. The second was made Dec. eighteen twenty-one, and consisted of nineteen hundred and seven pounds of gold, and twelve hundred and eighty-eight of silver; also jewels, obtained in St. Louis in exchange for silver to save transportation, and valued at thirteen thousand dollars.The above is securely packed in iron pots, with iron covers. The vault is roughly lined with stone, and the vessels rest on solid stone, and are covered with others. Paper number one describes the exact locality of the vault, so that no difficulty will be had in finding it.
中文:
我在贝德福德郡,距 Buford 酒馆约 4 英里,6 英尺深的洞穴或地窖埋藏了三号密码指定的一些人所拥有的物品:1819年11月第一次存入的物品有 1014 磅金和 3812 磅银。1821年12月第二次存入的物品有 1907 磅金和 1288 磅银,还有总值约 13000 美元的珠宝,在圣路易斯用银换取,以便运输。这些物品储存在带有铁盖的铁罐内。洞穴的内壁衬着石头。容器放置在结实的石壁上,并被其他物件覆盖。一号密码指明了藏宝处的地点,所以很容易就能找到它。
自此,古典密码学 学习完毕,我能问您一个问题嘛 ~
如果给您一个非常漂亮的妻子[漂亮到全国都知道她的名字],给您一个靠得住的大兄弟[为了可以去KO欺负您的人]。另外呢,您还会有一个稳定的工作,只是让您穿越回古代您来对应这些标准,您愿意嘛 ~ 欢迎评论区留言,不是问您能不能,而是问您想不想。


第四代加密
机械电子时代的加密解密
Enigma(恩尼格玛机)
恩尼格玛机 是一种机械电子式的机器,组成 : 转子 + 齿轮 + 电线 + 转盘 + 摇杆 + 编码器,可以将其简单分为三个部分:键盘、转子和显示器。ta 的加密解密方式类似维吉尼亚的最终版本 [真随机·钥匙],因为 ta 的加密解密无穷是由机器完成,不会加密解密难,同时也保证了不易错。ta 的钥匙是由编码器的齿轮组决定的,每一个齿轮组都由 26 个数字组成,齿轮组越多,钥匙就更长且有更多的组合,在对付 频率分析 上十分有用。
维吉尼亚不同版本:
1.0版,钥匙是随便想出来的一个词,然后重复的用;
2.0版,钥匙长度增加了很多,但为了便于双方协同使用,往往是一篇文章、一首诗;
3.0版,钥匙是纯粹随机字母,而真随机很难制造,密码簿又厚到不能用,所以3.0版只停留在理论上,实际几乎没人使用。
恩尼格玛机即 3.0 版本的改进,也叫 "单次钥匙谱",维吉尼亚3.0版是从数学角度来说不可能破解的加密法。
而真随机数是3.0的关键,3.0也应用在以后聊的量子加密中的数学部分以后会再见的。从程序角度讲,我们软件即算法实现的随机数都是伪随机数,然依据硬件传感器的热量变化、声音变化、光线变化、压敏变化等生成的随机数是真随机的。
由于内部状态决定下一个伪随机数的生成,所以破解在于内部状态;伪随机数种子是需要保密的,ta几乎等同加密术的钥匙不能告诉别人。因此千万不能使用易预测的值(用当前时间当种子)
伪随机数生成器(内部状态)实现方法:
- 乱来法
- 线性同余法(应用广泛因为不具备不可测性不能用于加密解密) : 假设我们要生成的伪随机数列是
,第一个伪随机数种子
是必须先给出来的,接着用一个公式计算下一个伪随机数:
, seed是种子,ta是一个变量
,所以seed此时是
随机数资料:http://m.biancheng.net/view/2043.html
// 这是 C 标准库 实现的伪随机数rand函数算法,java的java.util.Random类等也是采用线性同余法 static unsigned long int next = 1; // 种子默认值 int rand(void) // 内部状态,线性同余法 { next = next * 1103515245 + 12345; // A : 1103515245 seed : next C : 12345 M : 32768 return (unsigned int) (next>>16) & 32768; // next>>16 等同于 next / 65536 , 32768是2的幂,% 换成了 &。 p.s. x & (x-1) == 0 [判断2的幂 为0就是] } void srand(unsigned int seed) { next = seed; // 种子是数字 } // 调用函数 // srand( (unsigned)time(NULL) ); 采用当前时间做种子,循环产生随机数是相同的,因为时间只精确到秒 // int a = rand()%66+22; // 稍往安全方面考虑,A、C、M 可以用宏替换,隐藏数字值。如果不调用 next = 1 就是种子
破解方法 : 利用线性同余法生成的数列反推 A、C、M,假设推出 A = 1103515245 ,C = 12345 , M = 32768 。这时如果得到任意一个伪随机数再根据下列公式就可预测下一个伪随机数。
(A * R + C) mod M = (1103515245 * R + 12345) % 32768 =》 接着把 得到的任意一个伪随机数代入,可得到下一个伪随机数
改进版 : 提前打造一个随机数序列,每当需要种子时,取出对应的长度序列。保护好随机数序列ta等同于钥匙,不能给别人,与维吉尼亚加密术的3.0版原理一样。
帮您打造的字符池的代码实现~
#include <stdio.h> #include <time.h> #include <stdlib.h> typedef char* string; // 如是C++类型可以直接换成 string string (pseudo_random) (size_t n) { srand( (size_t)time(NULL) ); // 考虑到安全,种子不要以时间,最好自定义 // time函数 确定当前的日历时间。 返回和当前日历时间最近值,获取失败则返回 long的最大值 - 1 string s = NULL; while( ( s = ( string )malloc(sizeof(char) * n) ) == NULL ); for( size_t i = 0; i < n; i ++ ) { int ran = rand( )%3; if( ran == 1 ) s[i] = (char) (rand( )%26+97); else if( ran == 2 ) s[i] = (char) (rand( )%26+65); else s[i] = (char) (rand( )%10+48); // 生成 low ~ high 之间的随机数公式 : rand()%(high-low+1)+low } return s; } int main(void) { size_t n = 0; printf("请输入字符串个数:> "); scanf("%8d",&n); // 限制字符串长度-千万 string str = pseudo_random(n); printf("%s\n",str); free(str); str = NULL; // 防止野指针 return 0; }3. 单向散列函数法
4. 密码法
5. ANSI X9.17
// 这里有一个由 Marsaglia 首创 Knuth 推荐的方法: #include <stdlib.h> #include <math.h> double gaussrand() { static double V1, V2, S; static int phase = 0; double X; if(phase == 0) { do { double U1 = (double)rand() / RAND_MAX; #RAND_MAX 是sodlib.h定义的宏 double U2 = (double)rand() / RAND_MAX; V1 = 2 * U1 - 1; V2 = 2 * U2 - 1; S = V1 * V1 + V2 * V2; } while(S >= 1 || S == 0); X = V1 * sqrt(-2 * log(S) / S); } else X = V2 * sqrt(-2 * log(S) / S); phase = 1 - phase; return X; }强调 : 维吉尼亚加密术 + 真随机数 = 理论上以传统计算机是不可破解的加密术
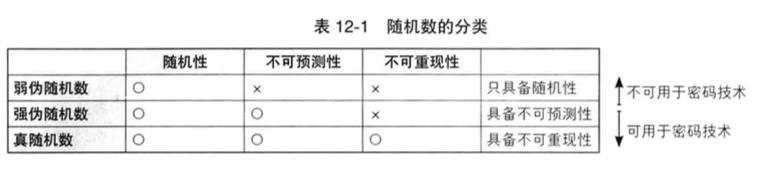


这张图片是 三组 齿轮(enigma的),可以设置 3 个随机数,共 26 * 26 * 26 = 17 576 种组合,齿轮组越多组合就越多,频率分析就会失效。
2 ~ 4 组齿轮的 恩尼格玛机 多用于商业,二战中被 图灵大神和整个布莱切利园 破解的 是八组齿轮的 德军恩尼格玛机。
ta 的组合就有
,约等于 2000亿 种,这样的组数让原文的每个单词不会匹配同一钥匙多次。每选择一个数字,转子会往下转一格,转子的转动让连接的线路改变,加密结果自然也不同。哪怕同一个字母敲入多次,加密后密文也不同。八组的就有 2000亿 种。这么多种组合,哪怕信息几百万字,用频率分析也很难找到出现相同的密文单词。


破解 恩尼格玛机:
二战的解密,挽救了世界许多家庭,也让战争年份锐减。这是历史上极有意义的解密。
1939年中期,波兰政府因为德军撕毁互不侵犯条约后将此破译方法告知了英国和法国,不过,这只是最简单的enigma,而 enigma它的广泛使用就是建立在加密原则上的即 假设解密一方拥有和加密一方同样的水平,机器和机器原理也被截获的情况下,对方依然不能解密出来。
图灵和整个布莱切利园的人们是这样做到的,主要还是数学呢, 现在的 AI 破解需要 13 min,成本是 10 英镑。
- 军事规律: 德军的消息经常出现 [ 无特殊情况(Keine besonderen Ereignisse) 、 希特勒万岁(Heil Hitler)、天气(wetter) ··· ]
- 人性弱点: 操作极不规范 [德军的enigma操作员设定的密码是三个字母连着一起的因为方便摁、女朋友名字因为不会忘 ~]
- 操作限制: 每组齿轮不能重复出现在同一位置[减少一半组合],接线板只能对调不相临的字母觉得这样易被发现[组合再锐减]
- 波兰提高的老方法 [波兰在二战前 7 年都在研究 3~4 组齿轮的 恩尼格玛机]
- 1941年英国海军捕获德国U-110潜艇,得到密码机和密码本,建立了数学关系
- MavisBatey收到一个信息,在200个明显的乱码中没有包含一个“w”。 通过使用每个字母不能被替换的知识,她破译出了密码
- 数学大师图灵以原文和密文建立对照表,[一些数学的知识环和连接数,非常难以理解] 采用数学和上述条件后使 2000亿种组合,变成了 105 万种组合。
- 制造炸弹机 [图灵设计] ,以机器的重复计算找到了 105 万种里面的德军密码。
- 炸弹机批量生产后,破译陆军只需要 1 小时,可是使用 8 组齿轮的海军,还是不能。
- 英军后来在特定地点布 "水雷",信息诱饵,德军又太相信自己的加密,导致德军会发送经纬度坐标给英军
- 英军演戏那是一流,"水雷" 不会经常用,知道了德军军舰的坐标也装什么都不知道,偷袭前,一定先派侦察机非常正式的去巡航,好像是告诉德军,你们的军舰是这个侦察机发现的
破解之后就说德军配置最高的海军,
- 英方盟军全年军舰损失减免 60%,
- 德军军舰损失从 7% 增到了 50%,
机械加密就说这个非常有意义的 解密 。
复习一下机械加密
| 机械加密术 | 算法原理 | 每日/通信 钥匙 | 实例 |
| Enigma通信密码 | 使用 Enigma密码机,通过的接线板接线的方式+三个转子的顺序+每个转子的旋转位置对字母替换 | 接线板接线的方式+三个转子的顺序+每个转子的旋转位置对字母替换 | Enigma通信电文的加密 |
| Enigma通信电文 | 使用接线板的接线方式+三个转子的顺序固定的 Enigma 密码机,按照每个转子的旋转位置对字母替换 | 每个转子的旋转位置 | Enigma通信电文的加密 |
计算机的前世是中国的算盘,计算机的诞生完全是由图灵弄出来的,这里我们简单的说一些。图灵与计算机的故事。
在上个世纪30年代中期,图灵在思考三个问题。
- 第一个问题,世界上是否所有数学问题都有明确的答案?
- 问题比答案多,只要一小部分有解
- 第二个问题,如果有明确的答案,是否可以通过有限步骤的计算得到答案?
- 不能完成,哪怕是理想环境
- 第三个问题才是,对于那些有可能在有限步骤计算出来的数学问题,能否有一种假想的机械,让它不断运动,最后当机器停下来的时候,那个数学问题就解决了?
- 电子计算机的电子运动等价于机械运动,计算是确定的,人的意识是不定的
由此,创建了图灵机[一种数学模型],图灵也成为了计算机的鼻祖。需要指出的是,图灵的境界能想到这一层,首先是受到另一位数学大师希尔伯特的启发。
希尔伯特在1900年的巴黎国际数学家大会上,提出了 23 个重要的、根本性的数学问题(也被称为希尔伯特问题)。图灵的念想:把人的思维用逻辑和数学过程描述出来;
图灵的方法:因为人的思维是大脑 860亿 个神经元相互连接而成,实在太多。因此图灵想,其实只需大脑的一部分做科学模型描述。
比如说在一个计算过程中,中间会出现很多数字,那么这些数字都可以视为单一的状态,这些状态都是各自独立的,而且对于一个生物大脑来说,同时存在于脑中的状态数量是有限的,所以图灵就把正在运算的大脑,当做一种数量有限、且状态间互相离散的机器。
他不试图还原一个完整的生物大脑,而只在乎某一部分可以用逻辑和数学准确描绘的大脑,看看用逻辑和数学搭建起来的这个思维机器能不能做运算,能不能习得东西,能不能自行找到任意两个事物间的关联等……
图灵的成就很巧,每隔 5年 出现一个,最早的是发生在1935年——图灵22岁时写出了《论可计算数及其在判定问题上的应用》,我们之后就简称这篇文章为《可计算数》,它从数学上定义了著名了“图灵机”。
不过图灵机很长时间以来一直只存在于论文中,它是一个抽象的可以实施自动计算的思维模型,而它的实体快到1950年时才出现。
虽然限于篇幅在这节课不能详细说,但如果一定要形容的话,你可以想象一下:
给你一排无限长的纸带,上面划着格子,格子只有两种样式,一种是里面打了孔的,一种是没打孔的。
而后你有一个小小的窗口,可以顺着纸带来回的挪动,不但可以查看格子打没打孔,还可以改变打孔与没打孔的状态。除此之外,你还有一个笔记本,可以临时记录通过窗口看到的打孔情况。
利用这些窗口,你能干的事情其实很少,也就是左右挪动、查看、更改打孔状态。那么在这几种操作下,怎么让这套设施实现一些具体的运算呢?纸带实现出来就是 阴极射线管 或 电子
二战结束后,图灵开始研究可以自己下国际象棋的机器,并考虑从机器角度说 "什么是学习"
时间再往后推 5年,图灵开始专心于研究自动计算引擎,简称ACE。它是图灵机的改进版,改进的方面非常多:
一方面因为炸弹机、巨像机这样的设计是布莱切利园的高级机密,自动计算引擎不能复制它们;
另一方面也是因为图灵在这几年的思考中,接触到了冯·诺依曼、香农、纽曼、哈代、维特根斯坦这些人的很多论文,从中受到了不少启发。
图灵机发展成计算机的主要原因:
- 解密需要 : 到了1935年之后,通过手工纸笔解密实在应付不了恩尼格玛机加密过的东西了。往严重的说,情报这种东西如果不搞定,那就是亡国,所以这是一个迫切的需求。
- 开发昂贵的新武器,要做可行性分析 : 这些武器投入的资金是巨量的。比如说原子弹,铀235要发生链式反应引爆的临界质量如果是20吨的话,全球至今都不会有哪个国家打算制造原子弹的,因为实在造不起。但可行性计算告诉我们,十几公斤就可以,美国算出来了,所以美国敢造。很多新武器的计算量都很大,除了原子弹、氢弹,还有冲击波杀伤力、飞机的空气动力学等。
想了解另一部分,可以看我另外一篇博客 Google食用指南[hacker]。如果想学习这种思维,恐怕得? 我的另外一篇博客 揭示 O(n)
好的,机械时代加密解密,我们聊完了。接下来,才是最最可贵而锻炼思维的现代加密。
祝猪事顺利 ~~
计算机加密记录,
- 采用数据结构的二叉树加密,树的根节点设为∞,接着一直延伸二叉树到 26 个分叉,所有左节点值为 0 ,所有右节点值为 1。这样就可以表示了 26 个字母,加密解密非常快,分支个数也非常多可以扰乱解密方。
- ... ...
计算机时代的密码学。啧啧,搞不懂 ~
几年前人们谈起计算机时还会说它笨,甚至嘲笑 Google 什么都是基于机器算法的服务应付不了很多细微的场景,今天这些人来了一个180度大转弯,觉得人工智能超级聪明。那么我们稍稍解释一下计算机 ~
历史: 计算机前身是中国的算盘。为什么不是古希腊的算盘呢,ta 比中国的算盘要早呀 ? 我们从现在讲起,算盘是计算机的前身,是硅谷的计算机博物馆的看法。这家地处硅谷、世界上最大的计算机博物馆,一进门自然的出现几个大字 "计算机 2000 年的历史",下面放的一把中国的算盘。历史上,古希腊的算盘实际只是一些小石块帮助计算时候的计数,但计算的工作还是靠心算,而中国的算盘,ta 除了圆珠子做存储功能,还有一套珠算口诀来控制算盘操作,这相当于今天控制计算机运行的指令。打算盘的师傅,不需要多好的心算或计算能力,只需要按照这个口诀就可以算出来结果。
比如,我们都知道一句俗话 "三下五除二",这其实来自于一句珠算口诀。它是做加法时,“加上三”的一种操作指令,意思是说,加三时,可以先把算盘上半部分代表五的珠子落下来,再从下面扣除两个珠子,加三的计算就完成了。只要把这些口诀背熟,幼稚园的小盆友同样可以完成。[ 我要是幼稚园的老师,不妨开一个这样的课。反正都是玩 ]
更多早期计算机:《带你逛西雅图活电脑博物馆》
程序的运行原理:《载入内存,让程序运行起来》
--------------------------------------------------------------------------------------------------------------
计算机要处理的信息是多种多样的,如十进制数、文字、符号、图形、音频、视频等,这些信息在人们的眼里是不同的。但对于计算机来说,它们在内存中都是一样的,都是以 二进制 的形式来表示。
内存条是一个非常精密的部件,包含了上亿个电子元器件,它们很小,达到了纳米级别。这些元器件,实际上就是电路;电路的电压会变化,要么是 0V,要么是 5V,只有这两种电压。5V 是通电,用 1 来表示,0V 是断电,用 0 来表示。所以,一个元器件有 2 种状态,0 或者 1。[把 5V 变成 2.5V 也可以,不过会增加电路设计的复杂性,没必要]
我们通过电路来控制这些元器件的通断电,会得到很多 0、1 的组合。例如,8 个元器件有 28 = 256 种不同的组合,16 个元器件有 216 = 65536 种不同的组合。虽然一个元器件只能表示 2 个数值,但是多个结合起来就可以表示很多数值和文字、图像、音频、视频、符号等等。一般情况下我们不一个一个的使用元器件,而是将 8 个元器件看做一个单位,即使表示很小的数,例如 1,也需要 8 个,也就是 00000001。
1 个元器件称为 1 比特(Bit)或 1 位,8个元器件称为 1 字节(Byte),那么 16 个元器件就是 2 Byte,32 个就是 4 Byte,以此类推:
- 8×1024个元器件就是1024Byte,简写为1KB;
- 8×1024×1024个元器件就是1024KB,简写为1MB;
- 8×1024×1024×1024个元器件就是1024MB,简写为1GB。
现在,你知道 1 GB 的内存有多少个元器件了吧。我们通常所说的文件大小是多少 KB、多少 MB,就是这个意思。
单位换算:
- 8 Bit = 1Byte
- 1024Byte = 1KB
- 1024KB = 1MB
- 1024MB = 1GB
- 1024GB = 1TB
您看,在内存中没有 abc 这样的字符,也没有 gif、jpg 这样的图片,只有 0 和 1 两个数字,计算机也只认识 0和1 。所以,计算机使用二进制,而不是我们熟悉的十进制,写入内存中的数据,都会被转换成 0 和 1 的组合。那么操作位是现在计算机加密解密的开始, 简单实现一下:
void encode(char *buf, int n) { for( int i = 0; i < n; i ++ ) { //右移要解释成无符号数,不然补1 unsigned char c = buf[i]; // 1个字节全部右移1位 = 自定义,喜欢就行 buf[i] = (c >> 1); } } void decode(char *buf, int n) { for( int i = 0; i < n; i ++ ) { //右移要解释成无符号数,不然补1 unsigned char c = buf[i]; // 1个字节全部左移1位 = 自定义,喜欢就行 buf[i] = (c << 1); } }---------------------------------------------------------------------------------------------------------
我们之前加密解密的字母,也全都对应到相应的二进制数,见 ASCII 表。
扩展的ASCII字符满足了对更多字符的需求。扩展的ASCII包含ASCII中已有的128个字符(数字0–32显示在下图中),又增加了128个字符,总共是256个。即使有了这些更多的字符,许多语言还是包含无法压缩到256个字符中的符号。因此,出现了一些ASCII的变体来囊括地区性字符和符号。例如,许多软件程序把ASCII表(又称作ISO8859-1)用于北美、西欧、澳大利亚和非洲的语言。
上图 字母和符号 ,以十进制看的,有些不明显哈。我用程序打印出来,稍等。
#include <stdio.h> #define Type char void display( Type data ) { int bit = 8; int i = sizeof(Type) * bit; //想看不同字节,改data类型即可, Type 的宏定义换成 size_t while( i-- ) { data & (1<<i) ? putchar('1') : putchar('0'); if( !(i % 4) ) { if( !(i % 8) ) putchar(' '); else putchar('-'); } } putchar(10); } int main(void) { for( size_t i = 65; i < 123; i ++) if( i < 91 || i > 96 ) putchar(i), putchar(' '), display(i); return 0; }古典加密中,无论是手工加密还是机械加密都是以 字母 为单位操作,使用计算机后,许多信息都可以被数字化,也打乱了语言规律的底层结构,不过,这并不影响加密解密的发挥。改变发生在 0、1 ,所以说计算机使加密解密进入了新时代。
从前的古典加密,加密一方会尽其所能的隐藏好加密的钥匙、机器、说明书,但计算机加密中,这些都可以公开,就怕你搞不懂。
那么,到底有多公开??
始于1976 年 11 月,美国国家标准局制定了一套规范的加密系统文档[IBM研制],简称 DES,外号魔王[路西法]。具有极高的安全性、效率较高,到目前为主,除了使用暴力枚举搜索[怕量子计算机或超大型分布式]算法对 DES 算法进行攻击以外,还没有发现更有效的办法[也许有但是设计军事是不会透露]
计算机加密解密分类,
1. 对称加密 与 非对称加密
2. 只能加密 与 加密也解密
- 对称加密即 加密 and 解密使用相同的密钥(同钥匙,计算机术语),速度快,密钥不方便管理;
- 非对称加密即 加密 and 解密使用不同的密钥,速度慢,密钥便于管理;
3. 对称加密混合非对称加密 取俩种加密的优点,如 AES + RSA
AES + RSA 混合加密大致过程:使用 AES 里的密钥加密数据得到一个密文,再用 RSA 公钥加密 AES 的密钥接着把俩部分的密文组合起来加密起来给接收人;
AES + RSA 混合解密大致过程:使用 RSA 里的私钥解密数据得到AES的密钥,再用 AES 密钥解密 AES 的密文;




star... [ 计算机 RSA加密 前置知识 :模、素数、逆元、欧拉定理、费马定理、模幂运算 、大数运算、加密协议]
p.s. RSA加密最主要的是模幂运算,迪菲-黑尔曼密钥交换有举例,其余的数论背景知识,写在数论博客的RSA加密部分。
在 RSA 算法出来的时候,发现者 RSA 三人以非常浅显的方式表达了算法的真谛。 it 's pretty cool !
那是以一段 3 人的交流而产生的故事。ta 们 分别是 爱丽丝 、鲍勃、伊芙。记住啦,以后您会经常和 ta 们打交道。
现在 伊芙 和 爱丽丝 通信,但发现 鲍勃 想偷听,于是 ta 们采用 DES 算法加密消息 。
可,DES算法是一个 对称加密,加密和解密使用相同的密钥(钥匙),DES虽然可以保证信息安全,可是交换密钥是 DES 最大的漏洞。伊芙 和 爱丽丝 怎么才能 把 每条消息对应的密钥(钥匙) ? 最简单的是见面告诉对方密钥,可是如果需要频繁的间断通信呢,像欧洲外交官维吉尼亚一样需要和欧洲其 ta 各国随时保持通信。难道天天见面,那就不需要 加密解密 了。
那么,我们是不是可以像维吉尼亚 2.0版本 、比尔密码 采用 莎士比亚的《威尼斯商人》用字母顺序 当密钥,就不用经常见面了。可是,回想我们的加密原则,假设 解密一方的水平与加密方一致,那么采用这样有明确规律的密钥好嘛 ?
肯定不好,只要 鲍勃 破解了第一次,以后的对话就都知道了。
在这个时代的时候,大银行就有一个职位,工作人员每天提着保险箱,飞到世界各地给客户送密钥。
爱丽丝说,我知道怎么密钥保密,您看,
我(爱丽丝)把 信 放到盒子里,上一把锁,盒子寄给 伊芙;
伊芙收到盒子后发现没密钥打不开,于是
按计划继续再给盒子装一把锁,再寄给 爱丽丝;爱丽丝收到盒子后
按计划把先前自己的锁解开,现在盒子只剩下伊芙的锁了,再寄给伊芙就完成了;这个过程比喻的圆满,可是工程和科学是有差距的。一套字符使用 A 加密一次,又使用 B 加密一次,我们就必先 B 解密,在用 A 解密,即后加密先解。如果顺序不符,解出来就不是原文。我们以简单的凯撒加密举例。假设第一把锁即后移 4 位,第二把锁后移 6 位。
e.g. 加密 : China => 后移 4 位 => Clmre => 后移 6 位 => Irsxk
解密: Irsxk => 后移 4 位 => Enotg => 后移 6 位 => Yhina
解密: 先移 6 位 ,后移 4 位,无论字母大小写,都不会得到准确的原文
回过头想一想,我们需要的是一种 密文 + 密钥 推不出 原文的密钥,生活经验解决不了,得找找数学上的定义。
数学的 数论 里面有一种 不可逆 运算,模运算 %。
模 广泛应用,
- 时钟、手表是 模 12 系统;
- 计算机的 n 位运算器是 模 n 系统,
- 算盘 也是一个模系统;
- 哈希算法本质也是模 运算,让余数保持在一个固定的范围。
- 我们约定的星期几,其实也是一个模 7(6) 系统,
- Web 编程的分页也是 模运算
- ... ...
加法模,例如时钟,10 - 4 =
10 - (12 - 4) = 10 + 8 =6 (mod 12),模 7 系统里, 3 + 3 = 6 (mod 7), 6 + 6 = 5(mod 7),
乘法模,在模 13 系统里, 11 * 9 = 8 (mod 13),
11 * 9 = 99 % 13 = 8,
模的另外一种表现形式 : n % p 是否整除可以写为
,还可以扩展代替除法
随时取模(加法和乘法):
- (a+b)%p = (a%p + b%p) % p ,运用这个模性质,不会让 程序里的 a + b 溢出;
- (a*b)%p = [ (a%p) * (b%p) ] %p,基本同上;
为什么 模 不能逆呢 ?
比如,99 % 13 只会是 8,可是 [0-10000] 之间 % 13 = 8 的,就有 770(加上8) 个数,见下图,省略了上面一部分。
数学上,当模大到一定程度时,就完全没有 逆运算 了。但,使用这套方案需要一个大前提---双方同时在线。
[模幂运算 RSA加密核心]
加密里面把模当成一种加密函数,函数(有一个运算规则如,
、+1、*9、等等都可以算在函数里)
伊芙 和 爱丽丝俩个人都约定使用
- 爱丽丝和伊芙各给一个数 A 、B,分别代入模 11 函数计算,这里约定 n = 11;
- 假如爱丽丝的数算出来是 N,伊芙算出来的是 M,接着交换结果因为是模运算的,这个结果不可逆,鲍勃知道这个结果也没用;
- 但爱丽丝和伊芙拿到对方的结果后,可以 以这样的方式计算出密钥 -
,算出来相等的值就是密钥;
1、2、3合起来被称为 "迪菲-黑尔曼密钥交换"
模拟一下上面的过程:
- 爱丽丝给出3,伊芙给出6,代入模 11 函数计算 =>
- 爱丽丝算得 2 , 伊芙算得 4 ,接着俩个交换结果[打电话、QQ、Wechat···]
,结果都是 9 ,用 9 加密;
迪菲-黑尔曼密钥交换
不是一种加密算法,而是一种密钥交换算法,其思想是基于 离散对数 的。它具有两个吸引力的特征:
- 一是仅当需要时才生成密钥,减小了将密钥存储很长一段时间而致使遭受攻击的机会;
- 二是除对全局参数的约定外,密钥交换不需要事先存在的基础结构;
然而,该技术也存在几点不足:
- 一是没有提供双方身份的任何信息。
- 二是它是计算密集性的,因此容易遭受阻塞性攻击,即对手请求大量的密钥。受攻击者花费了相对多的计算资源来求解无用的幂系数而不是在做真正的工作。
- 三是没办法防止重演攻击。
- 四是容易遭受中间人的攻击。
迪菲-黑尔曼密钥交换:https://en.wikipedia.org/wiki/Diffie%E2%80%93Hellman_key_exchange
RSA 算法是现在加密算法里(MD5、DES、RC4、SHA)用的数学知识(数论)是最多的,MD5、DES、RC4、SHA是以密码学混乱和扩散原则设计的,我们轮流讲,下面请看 魔王露西法加密。
第五代加密
DES
DES 是对称加密,既能加密也能解密。这个规范还有一个外号—— “魔王”(Lucifer),这是最典型的诞生在计算机时代的第五代密码法。据说,当初设计者一直把这套算法叫做 “示范算法” (Demonstration),但70年代的操作系统对文件名长度有限制,于是只能截取前几位字母 Demon,而 Demon 又是 “恶魔” 的意思,后来大家就用另一个恶魔的名字——路西法(Lucifer),也就是 “魔王” 来称呼这个算法了。
DES 加密原理 使用 虚假信息 增加其复杂度的同时分析难道也上升,术语为 混乱和扩散 原则,通过对明文许多的排列和替换来加密,复杂度为 O(1) 。
- 以给定的初始密钥
中得到 16 个子密钥
的函数;
- 加密明文时,每个子密钥以规定的位操作按
- 密钥以规定的位操作按
顺序迭代 16 次(轮),每个密钥一次(轮);
- 混乱:为隐藏任何明文(原文) 同密文或密钥间的关系
- 扩散:使明文的有效位和密钥一起组成尽可能多的密文
DES 代码 俩种,一种是自己实现[跨平台],一种直接调用 Windows [CryptoAPI]
- 函数声明原型 : 入口参数
- Key : 7 个字节 56 位 的工作密钥
- Data : 8 个字节 64 位 ,要加密或解密的数据
- Mode : DES 工作方式,加密或解密
- 变种 DES : 分组加密 3DES 算法,使用 3 条 56 位的密钥对数据进行 3 次加密,改进 DES 算法 密钥空间小 的缺陷。
- 分组:该算法每次都处理固定长度的数据块,如果没达到 这个长度 ,按照 补0(实际情况) 填充
具体实现[ 看不懂时,跳到大步骤最后,留俩个有流程图。从上往下,从左至右看 ]输入 一个 64位 数据块 【明文(原文)/密文】 经过一系列的运算(排列和替换) 输出 另一个 64位 数据块 【密文(原文)/明文块】
- 以 初始密钥 计算出 16 子密钥 :
这是 des算法 设定好的 密钥转换表 。ta 告诉您,初始密钥的第 57 位转换后便是密钥的第 1 位,初始密钥第 49 位转换后便是密钥第 2 位,其 ta 同理,初始密钥按?位置数 转换后就是位置数所占位置的第几位。
14 * 4 = 56 位,这样一个 64位 初始密钥就变成了 56 位密钥,接着计算 子密钥。
- 将 56 位密钥 分成 俩个 28位 的组,接着俩组以规定方式 左移 i 位,i 值对应第几轮即 第几个子密钥?,旋转后重新合并。
- e.g. 第 1 、2、9、16 轮时,左移 1 位,第 3、4、5、6、7、8、10、11、12、13、14、15 轮,左移 2 位。
- 对重组后的密钥进行置换,使 56位子密钥 变成 48 位子密钥(丢弃8位)
- 这个置换表的规则同上 ,不过看清楚只有 12 * 4 = 48 位
- 大致流程如下图
总结 : 为保证初始密钥不同位在每一轮排列中可以用到,上面的 重组 和 置换 都需要进行 16 轮。
2. 对 数据块 进行 加密或解密 :
- 初始置换 : 把 64位 数据块 置换成 俩组 32位 数据块
、
,置换规则同上 16 * 4 = 64。
- e.g. 数据块第 58 位 置换为 数据块的 第 1 位,数据块第 50 位 置换为 数据块的 第 2 位;
- 重复操作 16 轮,操作 i 计算出
、
, i 是 1 ~ 16 的整数,每轮是
、
开始,按下图置换,置换规则同上,其结果用于下一轮直到
、
结束;
- 12 * 4 = 48 位,让
- 计算 48位 结果值与这一轮子密钥
的异或值,得到一个 48位 的中间值 记为
[p.s. 到本轮的操作可以表示为 :
,
是 异或。]
- 接着,
解释一下,从
当前盒子j 取 6 位 (6*j ~ 6*j+6) S0 0~6 S1 6~12 ... 6*j+6 S7 42~48
- e.g. S盒j , j是3时,见上图,
,
,我们再找下面的 S盒3图,数表的时候行列都从 0 开始因为实现出来是一个数组 ~ ,数出来是 9 。
- 下图 : S盒j 替换表,替换规则基本同上
- 完成S盒置换后,结果又变成 32位 的值,于是用 P盒 置换,置换方式类似,P盒置换表如下
- 最终置换: 取消掉初始置换,数据块重新变成 64位。当 16 轮操作全部结束,将最后的右分组
- 回顾一下,最后一轮左右分组并没有交换。这样最后的右分组在左边而最后的左分组在右边 ~
- 大致流程图如下
您如果读懂了,那么您和程序员的距离也就差编码实现。14个置换表用14个数组枚举出来,旋转i位,写一个位操作函数即可,加密解密数据块也是一个函数。和密码学家的距离也就是加密的理论+数学基础。如果有心,是可以同时达到的~ 当然,如果哪个地方没读懂,欢迎交流!des代码有 java 和 C 的,需要的话,私聊一下Q。
那么可以写好函数原型了:
des_encipher为加密函数,des_decipher为解密函数
void des_encipher(const unsigned char *plaintext, unsigned char *ciphertext, const unsigned char *key); void des_decipher(const unsigned char *ciphertext, unsigned char *plaintext, const unsigned char *key); // plaintext : 明文(原文),ciphertext : 密文 // en加密函数的三个参数分别是 明文、密文、密钥,而这里中间参数是存储函数结果的。e.g. 明文 + 密钥 = 密文,de解密函数类似。接着,把 14 个置换表 + 1个转转表 按顺序实现出来:
- 前 3 个表是计算 16 子密钥
- 再接着 1 个初始化表和 1 个扩展表计算初始数据的置换
- 8 个 S盒
- 1 个 P盒
- 1 个最终置换
static const int DesTransform[56] = { 57, 49, 41, 33, 25, 17, 9, 1, 58, 50, 42, 34, 26, 18, 10, 2, 59, 51, 43, 35, 27, 19, 11, 3, 60, 52, 44, 36, 63, 55, 47, 39, 31, 23, 15, 7, 62, 54, 46, 38, 30, 22, 14, 6, 61, 53, 45, 37, 29, 21, 13, 5, 28, 20, 12, 4 }; static const int DesRotations[16] = { 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1 }; static const int DesPermuted[48] = { 14, 17, 11, 24, 1, 5, 3, 28, 15, 6, 21, 10, 23, 19, 12, 4, 26, 8, 16, 7, 27, 20, 13, 2, 41, 52, 31, 37, 47, 55, 30, 40, 51, 45, 33, 48, 44, 49, 39, 56, 34, 53, 46, 42, 50, 36, 29, 32 }; static const int DesInitial[64] = { 58, 50, 42, 34, 26, 18, 10, 2, 60, 52, 44, 36, 28, 20, 12, 4, 62, 54, 46, 38, 30, 22, 14, 6, 64, 56, 48, 40, 32, 24, 16, 8, 57, 49, 41, 33, 25, 17, 9, 1, 59, 51, 43, 35, 27, 19, 11, 3, 61, 53, 45, 37, 29, 21, 13, 5, 63, 55, 47, 39, 31, 23, 15, 7 }; static const int DesExpansion[48] = { 32, 1, 2, 3, 4, 5, 4, 5, 6, 7, 8, 9, 8, 9, 10, 11, 12, 13, 12, 13, 14, 15, 16, 17, 16, 17, 18, 19, 20, 21, 20, 21, 22, 23, 24, 25, 24, 25, 26, 27, 28, 29, 28, 29, 30, 31, 32, 1 }; static const int DesSbox[8][4][16] = { { {14, 4, 13, 1, 2, 15, 11, 8, 3, 10, 6, 12, 5, 9, 0, 7}, { 0, 15, 7, 4, 14, 2, 13, 1, 10, 6, 12, 11, 9, 5, 3, 8}, { 4, 1, 14, 8, 13, 6, 2, 11, 15, 12, 9, 7, 3, 10, 5, 0}, {15, 12, 8, 2, 4, 9, 1, 7, 5, 11, 3, 14, 10, 0, 6, 13}, }, { {15, 1, 8, 14, 6, 11, 3, 4, 9, 7, 2, 13, 12, 0, 5, 10}, { 3, 13, 4, 7, 15, 2, 8, 14, 12, 0, 1, 10, 6, 9, 11, 5}, { 0, 14, 7, 11, 10, 4, 13, 1, 5, 8, 12, 6, 9, 3, 2, 15}, {13, 8, 10, 1, 3, 15, 4, 2, 11, 6, 7, 12, 0, 5, 14, 9}, }, { {10, 0, 9, 14, 6, 3, 15, 5, 1, 13, 12, 7, 11, 4, 2, 8}, {13, 7, 0, 9, 3, 4, 6, 10, 2, 8, 5, 14, 12, 11, 15, 1}, {13, 6, 4, 9, 8, 15, 3, 0, 11, 1, 2, 12, 5, 10, 14, 7}, { 1, 10, 13, 0, 6, 9, 8, 7, 4, 15, 14, 3, 11, 5, 2, 12}, }, { { 7, 13, 14, 3, 0, 6, 9, 10, 1, 2, 8, 5, 11, 12, 4, 15}, {13, 8, 11, 5, 6, 15, 0, 3, 4, 7, 2, 12, 1, 10, 14, 9}, {10, 6, 9, 0, 12, 11, 7, 13, 15, 1, 3, 14, 5, 2, 8, 4}, { 3, 15, 0, 6, 10, 1, 13, 8, 9, 4, 5, 11, 12, 7, 2, 14}, }, { { 2, 12, 4, 1, 7, 10, 11, 6, 8, 5, 3, 15, 13, 0, 14, 9}, {14, 11, 2, 12, 4, 7, 13, 1, 5, 0, 15, 10, 3, 9, 8, 6}, { 4, 2, 1, 11, 10, 13, 7, 8, 15, 9, 12, 5, 6, 3, 0, 14}, {11, 8, 12, 7, 1, 14, 2, 13, 6, 15, 0, 9, 10, 4, 5, 3}, }, { {12, 1, 10, 15, 9, 2, 6, 8, 0, 13, 3, 4, 14, 7, 5, 11}, {10, 15, 4, 2, 7, 12, 9, 5, 6, 1, 13, 14, 0, 11, 3, 8}, { 9, 14, 15, 5, 2, 8, 12, 3, 7, 0, 4, 10, 1, 13, 11, 6}, { 4, 3, 2, 12, 9, 5, 15, 10, 11, 14, 1, 7, 6, 0, 8, 13}, }, { { 4, 11, 2, 14, 15, 0, 8, 13, 3, 12, 9, 7, 5, 10, 6, 1}, {13, 0, 11, 7, 4, 9, 1, 10, 14, 3, 5, 12, 2, 15, 8, 6}, { 1, 4, 11, 13, 12, 3, 7, 14, 10, 15, 6, 8, 0, 5, 9, 2}, { 6, 11, 13, 8, 1, 4, 10, 7, 9, 5, 0, 15, 14, 2, 3, 12}, }, { {13, 2, 8, 4, 6, 15, 11, 1, 10, 9, 3, 14, 5, 0, 12, 7}, { 1, 15, 13, 8, 10, 3, 7, 4, 12, 5, 6, 11, 0, 14, 9, 2}, { 7, 11, 4, 1, 9, 12, 14, 2, 0, 6, 10, 13, 15, 3, 5, 8}, { 2, 1, 14, 7, 4, 10, 8, 13, 15, 12, 9, 0, 3, 5, 6, 11}, }, }; static const int DesPbox[32] = { 16, 7, 20, 21, 29, 12, 28, 17, 1, 15, 23, 26, 5, 18, 31, 10, 2, 8, 24, 14, 32, 27, 3, 9, 19, 13, 30, 6, 22, 11, 4, 25 }; static const int DesFinal[64] = { 40, 8, 48, 16, 56, 24, 64, 32, 39, 7, 47, 15, 55, 23, 63, 31, 38, 6, 46, 14, 54, 22, 62, 30, 37, 5, 45, 13, 53, 21, 61, 29, 36, 4, 44, 12, 52, 20, 60, 28, 35, 3, 43, 11, 51, 19, 59, 27, 34, 2, 42, 10, 50, 18, 58, 26, 33, 1, 41, 9, 49, 17, 57, 25 };位操作实现出来:
typedef unsigned char unchar; int bitGet( const unchar *bits, int pos ); // 按小端模式取一个无符号数的二进制数; void bitSet( unchar * bits, int pos, size_t state ); // 按小端模式设置一个无符号数的二进制数为state; void bitXor( const unchar *bits_1, const unchar *bits_2, unchar *bits_x, size_t size ); // 按参数 size 第几位 选择要异或的参数 bits_1 和 bits_2 , 结果交给 bits_x void bitRotLeft( unchar *bits, size_t size, int cnt ); // 左循环移位 cnt 位,不用宏是因为宏只能针对一个字节












给出明文、密钥、密文以实现加密解密函数
// des_encipher 加密
unsigned char destemp[8] = "Admin"; // 明文(原文)
unsigned char ciphertext[8],plaintext[8]; // 密文
// ciphertext : 密文, plaintext : 明文(原文)
unsigned char deskey[8] = 0xAAFF1133BBB822A5; // 密钥
des_encipher(destemp,ciphertext,deskey);
/*
deskey[0] = 0xAA;
deskey[1] = 0xFF;
deskey[2] = 0x11;
deskey[3] = 0x33;
deskey[4] = 0xBB;
deskey[5] = 0xB8;
deskey[6] = 0x22;
deskey[7] = 0xA5;
// 隐藏的话,换成输入 scanf("%14[0-9A-F]",deskey);
*/
// encipher 解密
unsigned char destemp[] = "fjlaflka fnlaflkalkf^&*()_&*()&*(jflajflkalkfalkflka";
unsigned char deskey[8] = 0xAAFF1133BBB822A5;
unsigned char ciphertext[100],plaintext[100];
int len = strlen((const char*)destemp) + 1;
des_encipher(destemp,ciphertext,deskey,len);置换规则代码实现,比如第 57 位转换为 第 1 位 ···
static void permute(unsigned char *bits, const int *mapping, int n)
{
unsigned char temp[8];
int i;
memset(temp, 0, (int)ceil(n / 8));
for (i = 0; i < n; i++)
bitSet(temp, i, bit_get(bits, mapping[i] - 1)); // 减 1 是因为数组下标从 0 开始
memcpy(bits, temp, (int)ceil(n / 8));
}
// double ceil(double x) math.h 里,计算一个不小于 x 的最小整数可根据加密术的原理写一写,完整代码,博客上传会占很大的篇幅。需要的话,私聊QQ:23609099,备注是要 java 还是 C 版。15个表的数字,可以自定义。不过,这是一个标准的加密术改动表里面的数字,其实意义不大~
DES 的过程总结:
- 计算子密钥:首先初始密钥通过 初始置换和旋转表,最后经过 一轮置换 得到 16个子密钥。
- 计算数据块:初始数据块通过 初始置换和扩展置换表 得到数据块,用 8个S盒置换 后结果再同 P盒 置换,最终数据块变成右左32个重组为64位后,用 最终置换表 得到最终数据块。
- 注意啦,因为des算法加密把64位中的第 8、16、24、32、40、48、56、64 位,做奇偶效验位,在计算密钥时会忽略这8位,如果输入的密钥只是这 8 位有区别,那么操作就是浪费时间。(心疼计算机 1s)
诶,不过介绍的时候说过,DES 算法的 明文空间小 吗!现在您知道了吗(呸呸,哪里说了你个糟老头子你坏的很),des 只能对 8个字节64位 的数据块加密,而生活里,一条信息不可能只有 4个汉字 的长度。所以,标准推出了分组加密,把数据一段一段(8个字节、4个汉字)的加密,这个过程叫ECB,但不安全因为ECB的每个分组加密解密都是独立,如果加密的俩个数据块出现相同的字母,那么密文出来也是相同的,这样可以使用频率分析。更好的是CBC---密码分组链接,解决了ECB遗留的问题。做法 : 加密一个明文(分组)前,将前一个输出的密文(分组)与该明文(分组)异或,然后加密;解密时,将前一个输出的明文(分组)同接下来的待解密的密文(分组)求异或,然后解密。
void cbc_encipher(const unsigned char *plaintext,
unsigned char *ciphertext,
const unsigned char *key,
int size);
void cbc_decipher(const unsigned char *ciphertext,
unsigned char *plaintext,
const unsigned char *key,
int size);
// CBC 比起 ECB 加入了一个参数 size, 用来记录明文(加密)或密文(解密)的长度简单的理解了一下计算机加密,发现全部都是操作二进制位,这里送上操作二进制代码函数实现。
int bitGet(const unsigned char *bits, int pos)
{
unsigned char mask;
int i;
mask = 0x80;
for (i = 0; i < (pos % 8); i++) // pos % 8 == pos & 7 建议改成位操作
mask = mask >> 1;
return (((mask & bits[(int)(pos / 8)]) == mask) ? 1 : 0); // pos / 8 == pos >> 3 建议改成位操作
}
void bitSet(unsigned char *bits, int pos, int state)
{
unsigned char mask;
int i;
mask = 0x80;
for (i = 0; i < (pos % 8); i++)
mask = mask >> 1;
if (state)
bits[pos / 8] = bits[pos / 8] | mask;
else
bits[pos / 8] = bits[pos / 8] & (~mask);
}
void bitXor(const unsigned char *bits1,
const unsigned char *bits2,
unsigned char *bitsx, int size)
{
int i;
for (i = 0; i < size; i++)
{
if (bitGet(bits1, i) != bitGet(bits2, i))
bitSet(bitsx, i, 1);
else
bitSet(bitsx, i, 0);
}
}
void bitRotLeft(unsigned char *bits, int size, int count)
{
int fbit,lbit,i,j;
if (size > 0)
{
for (j = 0; j < count; j++)
{
for (i = 0; i <= ((size - 1) / 8); i++)
{
lbit = bitGet(&bits[i], 0);
if (i == 0)
{
fbit = lbit;
}
else
{
bitSet(&bits[i - 1], 7, lbit);
}
bits[i] = bits[i] << 1;
}
bitSet(bits, size - 1, fbit);
}
}
}
// 这 4 个函数有说明,我放在上面了,找一找DES破解 : 在 Shor算法 之后(
后面会细说),还是贝尔实验室,洛夫·格鲁夫(Lov Grover)又设计出一种新算法,也是利用量子计算机。专门针对美国国家标准的加密法DES,结果在当前典型的应用级别下,4分钟就把所有可能的钥匙试遍,密码随之告破。随着硬件的不断迭代升级,使用超大型分布式的传统计算机同样可以做到。
XOR异或算法
XOR异或算法,a ^ a = 0,a ^ 0 = a。
#include <stdio.h>
#include <string.h>
const int N = 32;
void XOR( char *data, char *key ) // data: 放明文或密文 key : 密钥
{
int datalen = strlen(data); // datalen: 明文或密文的长度
int keylen = strlen(key); // keyles: 密钥的长度
for( int i = 0; i < datalen; i ++ )
data[i] = (char) (data[i] ^ key[ i%keylen ]);
}
int main(void)
{
char data[N] = "I'm Debroon !";
char key[N] = "23609099";
// 加密
XOR(data, key );
printf("%s :> %s\n","密文",data);
// 解密
XOR(data, key );
printf("%s :> %s\n","明文",data);
return 0;
}异或加密 : 这个算法虽然简单,可是还需要改进改进。因为异或有一个性质,a ^ a = 0; 如果密钥和数据刚刚好是相同的字母或数字,那么整个加密术都会崩溃。所以,加密解密前先判断,遇到相同的就跳过。
#include <stdio.h>
#include <string.h>
const int N = 32;
void XORe(char *data, char *key)
{
int len = strlen(data);
int n = strlen(key);
int j = 0;
for( int i=0; i<len; i++)
{
if(data[i] == key[j]) //考虑相等时a^a=0
{
j++;
}
else
{
data[i] ^= key[j++];
if( j == n )
j ^= j; // 相当于 j = 0, 嘿嘿偶尔装逼也是挺好的;
}
}
}
int main(void)
{
char data[N] = "I'm Debroon !";
char key[N] = "oo";
// 加密
XORe(data, key );
printf("%s :> %s\n","密文",data);
// 解密
XORe(data, key );
printf("%s :> %s\n","明文",data);
return 0;
}异或+循环移位加密实战:
加密这张图片~
#include <stdio.h> #include <string.h> // 异或+循环位移 void en_de_code(char *buf, int n, char *key) { int len = strlen(key); int j=0; for(int i = 0; i < n; i ++) // n是循环位移数 { buf[i] ^= key[j++]; if( 0 == j % len ) // 密钥循环 j ^= j; // 同 j = 0 } } int main(void) { FILE *fpr = fopen("Debroon.jpg","rb"); FILE *fpw = fopen("Debroonee.jpg","wb"); char buf[2048] = ""; // char buf[1<<11]; 2的11次方是 2048 char *key = "show code~"; int n = 0; while( (n = fread(buf, 1, 2048, fpr) ) > 0 ) { en_de_code( buf, n, key); // 第一遍加密图片 en_de_code( buf, n, key); // 第二遍解密图片 fwrite( buf, n, 1, fpw); } fclose(fpr); fclose(fpw); return 0; }

第六代加密
RSA算法
下面我们来讲 计算机界 声名远播的 RSA算法,ta不为人知的故事和代码实现 ~
第一个故事爱丽丝和伊芙通信问题,使用不可逆运算,有一个大前提---双方同时在线。而现实生活里,我们用微信、QQ、发邮件,一般都不用对方立刻回复[(大部分)中国人喜欢收到就回复,西方人乐于在一个规定的时间段处理所有消息],解决这个问题使用的加密法就是第六代加密法 --- RSA加密法,手机支付加密、网银加密都会用到ta。
历史 :RSA这3个字母,分别代表的是它的3位创立者——Ron Rivest、Adi Shamir、Leonard Adleman。可最早发明这种方法的,并不是 RSA 这三个人,而是詹姆斯·艾利斯(James Ellis)、克里佛·考克斯(Clifford Cocks)和马尔科姆·威廉森(Malcolm Williamson),我们简称他们三人为 JCM。
他们都是英国政府通讯总部的员工。不知道你是不是还记得图灵破解恩尼格玛机时,有个庞大的情报部门布莱切利园。当时9000名员工,战后绝大部分都回到了原来的生活中,只有少数转去英国通讯总部做了公务员,这3位密码学家就是这样留任的。
他们之后的研究也全都带有军方项目的性质,所以是国家机密。别看1975年他们就做出了整套非对称钥匙加密系统,但直到24年后的1997年,人们才知道这件事。这时不要说和RSA争夺专利发明权了,连RSA的专利甚至都要过期了。[啧啧实在是,悲具了]
其实在1975年,JCM 刚刚做出全套算法的时候,他们曾经向国家通讯总部提出过注册专利的要求,但总部没有批。
几年后他们听说RSA三个人注册了专利后,特别失落,因为他们才是最早的发明人,专利应该属于他们。但因为军方的限制,他们只好保持沉默。不过,JCM他们并不后悔,其一因为密码学是一门特殊的学科,涉及国家安全的东西这是 ta 独有的文化,是不能泄漏的,其二,他们如果想得到公开的赞扬,那么就不会去做这份工作(英国??通讯部工作)。
RSA:非对称加密(加密 和 解密使用不同的密钥),以 爱丽丝 举例 :
1. 爱丽丝有很多把锁,每把锁都有两把不同的钥匙,一把专门用来上锁而不能开锁,另一把专门用来开锁而不能上锁。
2. 爱丽丝把那把用来上锁的钥匙,尽量多的赠送给每个可能和她通信的人。这些人拿到钥匙后,就可以把要跟爱丽丝说的话写下来,再用爱丽丝给的钥匙把锁锁上,然后寄给爱丽丝。
3. 爱丽丝拿到锁好的盒子后,用另外一把只有她才有的专用钥匙打开盒子,就可以看到信里的内容了。
这个过程的关键点就是,对同一把锁来说,上锁和开锁用的是两把不同的钥匙,而之前我们说的DES加密法是使用相同钥匙的。继续以 爱丽丝 举例讲解 加密原理 :
爱丽丝展示出来的公开钥匙,是通过两个比较大的素数 p和q 相乘得到的一个更大的数 N 得到的。p和q 具体是多少,爱丽丝只要自己知道就行,千万不要告诉别人。而乘积 N 是公开的,谁都可以知道。(找素数,可以看这个数论文章)
凡是要给爱丽丝发消息的人,都需要用 N 来加密。加密的过程依然用的是模运算,而且模就是 N。整个数学过程会保证这个模运算不可逆,所以伊芙就算知道 N 也没用。
那爱丽丝是怎么解密的呢?她解密时就不需要 N 了,而是要用到 p和q 的具体值,而这两个值别人都不知道,只有爱丽丝自己知道。具体来说,爱丽丝私下做的另外一个模运算中的模,不是刚才我们说的 N,而是另外一个值 (p-1)×(q-1)。你看,在这个公式中就必须要知道 p 和 q 到底是多少才行。(不太清楚原理,可以到计算机加密前面看模运算的介绍)
至于为什么一定要是 (p-1)×(q-1),你不用纠结,数学原理保证这样操作能算出一把新钥匙,这把新的钥匙就是爱丽丝自己的私钥。用这把私钥,一定可以解出原文。
你说,这样做就能保证安全吗?伊芙已经知道了一个大数 N,她难道不能利用精巧的算法,找出N到底是由哪两个大的质数相乘得到的吗?
不能的,这种不能是由数学保证的。N 越大,找到 p和q 两个因数的时间就增加得越夸张。现在银行使用的 RSA 加密,都要求 N 是一个超过 300位 的大数。想分解这样一个数,大约需要把全球计算机的算力集中起来算上几亿年才行。
当 p和q 是一个大素数的时候,从它们的积 pq 去分解因子 p和q,这是一个公认的数学难题。然而,虽然RSA的安全性依赖于大数的因子分解,但并没有从理论上证明破译RSA的难度与大数分解难度等价。
虽然RSA加密算法作为目前最优秀的公钥方案之一,在发表三十多年的时间里,经历了各种攻击的考验,逐渐为人们接受。但是,也不是说RSA没有任何缺点。由于没有从理论上证明破译RSA的难度与大数分解难度的等价性。所以,RSA的重大缺陷是无法从理论上把握它的保密性能如何。在实践上,RSA也有一些缺点:
1. 产生密钥很麻烦,受到素数产生技术的限制,因而难以做到一次一密;
2. 分组长度太大,为保证安全性,n 至少也要 600 bits(位) 以上,使运算代价很高,尤其是速度较慢。
3. 遇到量子计算机,KO。在电子计算机体系下,一个长达n位的大数分解需要的步骤数是n的指数量级,然而在量子计算体系下分解步骤只剩下平方量级。

传统计算机里,n稍稍增大,计算量的增加的曲线几乎是垂直上升的;而量子计算机里,计算总量增加的趋势虽然平缓很多,但还是一个陡峭的斜坡。
所以我们现在不用那么担心量子计算机出现后,当前的密码保护会瞬间碎成渣渣。不会这样的。
只要我们愿意把那个大数n再加长很多,比如从300位增加到3000位,保密强度还是足够应付初期量子计算机破解的。
当然,真正意义上的量子计算机还在研发当中,目前的前沿进展当属中科大的潘建伟教授,用光学量子操控装置实现了 15 = 3 x 5 的质数分解。具体来说,要破解 RSA 加密法,需要量子计算机和配套的量子算法,即硬件、软件组合。
不过,现在软件已经实现,硬件还不够成熟(也许 10~30 年)。
所以,我们生活在加密法打败解密法的年代。
不过,加密方,还有量子加密,或许是量子计算机都不能破解的。
算法 VS 算法
RSA 算法破解 : Shor(休尔) 算法
从1994年,舒尔提出了Shor 算法,直到2001年,IBM 和斯坦福大学才在一个 7 个量子比特的量子计算机上首次实现了 Shor 算法,成功地把 15 分解成了 3 和 5,可见质数分解对于量子计算机并不是有算法就能轻易实现的。现在看来在量子计算领域,各大IT 巨头纷纷扎堆,中国的进步也很快,不仅科研机构参与(如前面中科大的潘建伟教授),百度和阿里巴巴也都建立了自己的量子计算实验室。
量子计算机有个致命弱点,由于量子的叠加和纠缠状态,它是极其脆弱的。
所以,量子计算机通常只能在接近绝对零度的状态下才能保证量子状态,正常运行。
看到这温度不禁让我想到了“超导”,那科研重要性绝对不亚于量子计算机,可到今天也没看到大规模商用的曙光,一直趴在实验室的低温环境里面慢慢的“升温”。
所以对量子计算可以期盼,也不可盲目乐观,当然它对加密系统的影响更不用过于杞人忧天。
Shor 算法:分解因数
1. 选择任意数字a<N
2. 计算gcd(a, N)。这一步是求 a 和 N 的最大公约数。
3. 若 gcd(a,N) ≠ 1,则我们找到了因数,运算结束。
4. 否则,找到最小的r,使ax(mod N) = ax+r (mod N),这一步就是需要在量子计算机里实现的步骤。(mod是模运算,根据欧拉定理r一定存在)
5. 若 r 是奇数,回到第一步。
6. 若 ar /2 ≡ -1 (mod N),回到第一步。
7. gcd(ar/2+1,N) 和 gcd(ar/2-1,N) 分別是 N 的因数。任务完成。
第 4 步,一定得在量子计算机里完成,其 ta 步骤在传统计算机中编程即可。
以 N 为 768 位举例,这是当年传统计算机做过分解因数最大的数了。
传统计算机和量子计算机计算ta,大约是 100万年 和 1 秒 的差异。
不过现在的量子计算机只在量子计算时,才比传统计算机快很多倍,普通运算还不如传统计算机(
量子加密时细说)。也许量子计算机的出现,让世界不一样,不过我们只能拥抱技术。
RSA 数论 知识:
1、互为素数 任何大于1的整数a能被因式分解为如下唯一形式:
(
,
…,
为 素数)
2、模运算
①{ [a(mod n)] × [b(mod n)] }mod n ≡ (a×b)(mod n)
②如果(a×b) = (a×c)(mod n), a 与 n互素,则 b=c(mod n)
3、费马定理 若p是素数,a与p互素,则a^(p-1) mod p = 1.
4、欧拉定理 欧拉函数φ(n)表示不大于n且与n互素的正整数的个数。 当n是素数,φ(n)=n-1。n=pq, p,q均为素数时,则φ(n)= φ(p)φ(q)=(p- 1)(q-1)。 对于互素的a和n,有a^φ(n) mod n =1.
5、模幂运算 即 x = a ^ b mod n (迪菲-黑尔曼密钥交换部分有举例)
原理: RSA算法基于一个十分简单的数论事实:将两个大素数相乘十分容易,但那时想要对其乘积进行因式分解却极其困难,因此可以将乘积公开作为加密密钥。对极大整数做因数分解的难度决定了RSA算法的可靠性。换言之,对一极大整数做因数分解愈困难,RSA算法愈可靠。尽管如此,只有一些RSA算法的变种被证明为其安全性依赖于因数分解。假如有人找到一种快速因数分解的算法的,那么RSA安全性还不如des,但找到这样算法的可能性非常小。
流程:
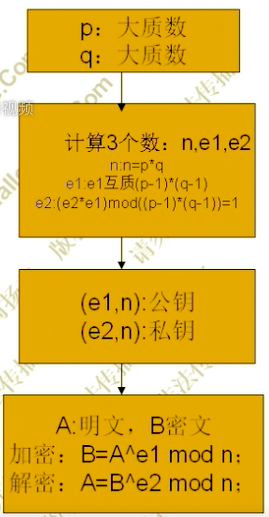
p.s. 类型全部化成 unsigned long 或者 要实现大数存储与计算。建模: 加密解密分别定义一个结构体,加密包含e、n,解密包含d、n
typedef unsigned long Huge; typedef struct RsaPK { Huge e; Huge n; } RsaPK; typedef struct RsaSK { Huge d; Huge n; }RsaSK;1、选择两个大素数p、q (推荐 1024 位,p和q 一定不能告诉别人)
- 提示:程序让用户选择随机产生的素数是多少位用户输入 3 ,那么素数的范围 100~999,于是n位所有素数写入文件后打开文件让用户自己选择输入,文件要删除因为不删除就是告诉别人p和q,删除文件: remove(
路径文件名)。void Prime(int num) // num 是 用户输入的数字,ta想要几位的素数,3位即 100~999 { FILE *fp = fopen("prime.txt","w"); // 素数全部写入文件,需要的时候打开,用完一定记得删除 assert(fp != NULL); UL base = 1; UL top = 9; for(int i=0; i<num-1; ++i) { base = base * 10; //100 top = top * 10 + 9; //999 } int k = 1; base++; while(base <= top) { if(TestPrime(base)) { fprintf(fp,"%-5d: %-6d",k,base); if(k % 5 == 0) fprintf(fp,"\n"); k++; } base += 2; } fclose(fp); } // 素数测试建议使用 Miller_Rabin素数判定,我数论的博客代码和原理都写好了2、计算n值, n = pq
- 显然
Huge n = p * q;3、选择一个小的奇数e是公钥的一部分,要求为e与(p-1)(q-1)互为素数关系(没有相同因子),通常选择2、3、17、65537、19260817 等作为 e 的值
- 可以预先指定,推荐随机选e
//自动产生随机数(公钥e) void RandomE(Huge f,Huge &e) { int x,y,r; srand(time(0)); while(1) { e=rand()%f; if(e>1) { y=e; x=f; while(y!=1) { r=x%y; x=y; y=r; if(y==1||y==0) break; } if(y==1) break; } } } // 调用 RandomE((p-1)*(q-1),e);4、计算d值是私钥的一部分:d = e^-1 mod(p-1)(q-1),可以认为当 d 为多少时,满足ed mod(p-1)(q-1) == 1
- 求 d 会用到逆元,根据欧拉函数φ(n)和公钥e求解公钥d,满足:(d×e)modφ(n)=1,
即d与e的乘积除以φ(n)余数为1Huge Inverses(Huge n, Huge e) { int x1, x2, x3, y1, y2, y3, t1, t2, t3, temp; x1=1; x2=0; x3=n; y1=0; y2=1; y3=e; while(1) { if(y3==1) { if(y2>=0) return y2; else return (n+y2); break; } temp=x3/y3; t1=x1-temp*y1; t2=x2-temp*y2; t3=x3-temp*y3; x1=y1; x2=y2; x3=y3; y1=t1; y2=t2; y3=t3; } } // Huge d = Inverses((p-1)*(q-1),e);5、 有了e、d值,将(e,n)做为公钥 即 PK = (e,n) ,(d,n)做私钥 即 SK = (d,n),加密用PK, 解密用SK。
- 公钥只需要求解出 e,私钥只需要求解出 d
6、 加密方使用 PK 加密数据,解密方使用 SK 解密,为了保证就算有人知道 PK 也无法推算出 SK , 必须保证 p和q 的值不能泄露
void PK(RsaPK *pk, Huge p, Huge q) // PK 加密 { FILE *fp = fopen("./key/pk.txt","w"); assert(fp != NULL); Huge n = p * q; Huge e; RandomE((p-1)*(q-1),e); pk->n = n; pk->e = e; fprintf(fp,"e=%d, n=%d",pk->e,pk->n); fclose(fp); } void SK(RsaSK *sk, Huge e, Huge p, Huge q) // SK 解密 { FILE *fp = fopen("./key/sk.txt","w"); Huge n = p * q; Huge d = Inverses((p-1)*(q-1),e); sk->d = d; sk->n = n; fprintf(fp,"d=%d, n=%d",sk->d,sk->n); fclose(fp); } // PK(&pk,p,q); // SK(&sk,pk.e,p,q);7、 加密 ciphertext = plaintext ^ PK.e mod PK.n (迪菲-黑尔曼密钥交换部分有举例)
- 一个加密幂模运算
//幂模运算 Huge ModExp(Huge a, Huge b, Huge n) { Huge y = 1; while(b != 0) { if(b & 1) y = (y*a)%n; a = (a*a)%n; b = b>>1; } return y; } void RsaEncrypt(Huge plaintext, Huge *ciphertext, RsaPK *pk) // 加密 { //x = a^b%n; *ciphertext = ModExp(plaintext,pk->e,pk->n); } // RsaEncrypt((Huge)ch,&ciphertext,&pk);8、 解密 plaintext = ciphertext^SK.d mod SK.n (迪菲-黑尔曼密钥交换部分有举例)
- 一个解密幂模运算
void RsaDecrypt(Huge ciphertext, Huge *plaintext, RsaSK *sk) { *plaintext = ModExp(ciphertext,sk->d,sk->n); } // RsaDecrypt(ciphertext,&plaintext,&sk);
复杂度 : O(1)
实现 : 一种是自实现,还有一种是基于 OpenSSL 库加解密,ta提供了 8 种对称加密(AES、DES、Blowfish、CAST、IDEA、RC2、RC5、RC4),4 种非对称加密(DH、RSA、DSA、椭圆曲线EC)
总结: RSA 是涉及数论知识最多的,但是明白数学原理后实现非常easy. 最重要的就是模幂运算,我有用爱丽丝的故事举例,您一定要仔细认真品味 !需要完整C代码Q:23609099, 青睐交流~
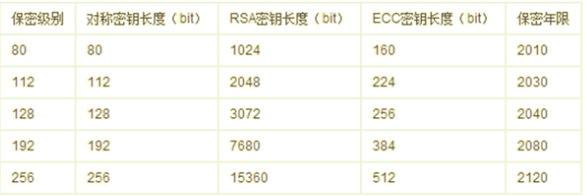
MD5、AES等加密算法,先不写。讲点不烧脑的,量子计算机·量子加密。
MD5[破解] 撞库攻击:https://cmd5.com/
第七代加密
量子加密
目前是第四代配备真空管,晶体管和集成电路的微处理器的计算机。TA们都基于传统计算,传统计算基于电路在给定时间处于单一状态的经典现象,开启或关闭。随着电子元件越来越小,计算机日益变小和变快。但这个过程即将达到其物理极限。
量子计算机基于量子力学现象,即一次可能处于多个状态的现象。量子同时处于多个状态并与非常远的其他粒子相互作用。像叠加和纠缠的现象发生,下面会举例先学理论。
叠加
In classical computing bits has two possible states either zero or one. In quantum computing, a qubit (short for “quantum bit”) is a unit of quantum information—the quantum analogue to a classical bit. Qubits have special properties that help them solve complex problems much faster than classical bits. One of these properties is superposition, which states that instead of holding one binary value (“0” or “1”) like a classical bit, a qubit can hold a combination of “0” and “1” simultaneously. Qubits have two possible outcomes zero or one but those states are superposition of zero and one. In quantum world qubit don’t have to be in one of those states. It can be in any proportion of those states. As soon as we measure its value its has to decide whether it is zero or one. This is called superposition. It is the ability of the quantum system to be in multiple states at same time.
In classical computing for example there are 4 bytes. The combination of 4 bytes can represent 2^4=16 values in total and one value a given instant. But in a combination 4 qubits all 16 combination are possible at once.
纠缠
Entanglement is an extremely strong correlation that exists between quantum particles — so strong, in fact, that two or more quantum particles can be linked in perfect unison, even if separated by great distances. The particles remain perfectly correlated even if separated by great distances. Two qubits are entangled through the action of laser. Once they have entangled, they are in an indeterminate state. The qubits can then be separated by any distance, they will remain linked. When one of the qubits is manipulated, the manipulation happens instantly to its entangled twin as well.
量子计算机 :现代加密最大的威胁...
怎么用量子计算机破解 RSA加密算法(软件) 我们已经说完。现在详细讲一讲硬件。
在介绍现在计算机加密时,我告诉了计算机的数据都是由0和1组合,一个字节可以放 Nbits,数据在内存条里就有 种可能,计算机只能在某个时刻操作其中一个,
种可能要一个一个的操作。
量子计算机存储的0和1,总是叠加状态(所有出现的0和1的可能性融汇在一起)。所以,一个量子存储单位在某个时刻,可以同时存储 数据。量子计算机运算一次,会同时对
个状态操作。所以,TA的一次算力是
台传统计算机一次的和。
截至今日,通用、专用的量子计算机都没出现~
有人听说过 D-Wave 这个机器,而且也可能知道武器商洛克希德·马丁 2011 年就订购过一台 128 个量子位的量子计算机,但实际上那台 D-Wave 虽然确实利用量子理论计算,但它只能运行一种特殊的算法,叫做“量子退火算法”。
所以说,D-WAVE 只能算一个实验性质的计算器,洛克希德·马丁买它更多是一种尝试。
后来 D-Wave 还开发出了二代,谷歌和NASA都买过一台,这台改进多了,是 512 位的,甚至可以进行一部分传统运算。
但是运算速度大约跟 1998年 前的计算机的速度差不多,只是在进行特定的量子算法时才比传统电脑快很多倍。

近景:

硬件发展困难的原因在于: 量子太容易变化。目前我们还没有特别好的方法,控制量子按照算法的步骤运作。
最经典的例子,就是“光的双缝干涉实验”。
一个光源射向一堵障碍物,障碍物上有两道缝可以透光。
当尺寸合适的时候,你会发现在两道缝后面的幕布上看到一道明一道暗、一道明一道暗的条纹。
但是,请注意我下面这段话——当人们好奇心大增,想弄清从光源发出来的光的每一个光子,到底通过了哪个缝才射到了幕布的话,我们可以在缝前安放一个侦测光子的设备。
但如果我们这么做了,在双缝后面的幕布上明暗条纹就消失了,取而代之的是两道集中的光斑。
所以说,我们的测量行为会影响量子的状态。
我们一旦在缝隙前设置了装置,去判断入射光到底通过了哪道缝,本应该保持的明暗条纹状态就消失了。
如果那些明暗条纹代表着量子计算机运算到某一时刻的量子位的正确状态的话,那设计者要尽最大可能维持住这种状态。但实际上,这种状态会被很多因素干扰。
在宏观世界里,任何一种物质都有可能和量子发生互动改变他们的状态,比如说温度。所以那些量子计算机,都需要在零下 200 多摄氏度的极低温才能正常工作。
在 2016 年,美国国家科技委员会曾经发布过《发展量子信息科学》的报告,量子计算机部分的规划是这样的:
未来 5 年会有几十个量子位的原型机诞生……,通用量子计算机是一项长期的挑战,至少需要10年。
因为TA的硬件、算法、编程语言、编译器都严重缺失,每一项都是巨大的困难。
量子加密 : 第 7 代加密法。数学 + 物理的量子力学组成。
数学部分:就是古典加密的 "单次钥匙谱"(维吉尼亚3.0v)。
量子加密保密的数学过程:
第一步:爱丽丝给鲍勃传送一串光子,其中每一位光信息都用0和1来标注。具体什么算0,什么算1,是有两套测量方法——甲套和乙套。这两种不同的测量方法,对同一个信号的测量结果是不同的。
第二步:鲍勃收到光信息后开始测量,就测量每个光信息位到底是0还是1。不过鲍勃并不知道爱丽丝那边说的0或者1,到底是按甲方法测的还是乙方法测的。但没关系,鲍勃对每个光信号都随意选用一套方法来测出每个光信号到底是0还是1,就可以了。
所以鲍勃有的时候测出来的结果,肯定是跟爱丽丝发出来的约定相符的,可有的时候测出来的结果又是不符的。不过这都没关系,测完了再说。第三步:毕竟鲍勃有一部分是测错的,所以这时候两个人必须打一个电话。这个电话完全不用保密,谁想窃听都可以。
爱丽丝和鲍勃在电话里都说什么呢?就是针对每个信号,到底使用了哪套测量方法。这通电话里就是按照顺位,依次说出测量的方法。第1个信号是用甲方法测的还是乙方法测的,第2个顺位用了甲还是乙,第3个顺位用了甲方法还是乙方法……所有这些测量方法,由爱丽丝告诉鲍勃。
第四步:鲍勃听完爱丽丝的这通电话之后,就对照刚刚自己瞎蒙着测的结果,也要回复爱丽丝。回复的具体内容就是,自己哪几位的测量方法蒙对了。
对鲍勃来说,自己之前测错的那些不管,把测对的那几位挑出来,这串数字就可以作为他的钥匙。对爱丽丝来说,因为鲍勃告诉了她哪几位他选对了测量方法,所以爱丽丝也可以把鲍勃选对的那串数字也挑出来。
这个时候两人挑出来的那串数字是完全相等的,而因为完全相等,所以就可以作为两人的钥匙了。
它既是鲍勃的钥匙,也是爱丽丝的钥匙。
整个过程中,钥匙并没有在额外的步骤中单独传输。
他们在电话里说一说,自己分别回去数一数,就能得到同样的钥匙。
之所以钥匙一样,也是数学原理上保证的,咱们不用纠结于数学原理的细节。
既然没有单独的钥匙传送环节,所以特工就很难下手。
另外,因为鲍勃和爱丽丝都是随机瞎蒙着选用甲套或乙套这两种测量方式的,所以两个人恰巧都用了同一种方法的序列挑出来的东西,也是随机序列,也就是说钥匙是完全随机的。
到这里,钥匙既不用额外的传输,而且本身又是完全随机的,这下就满足了单次钥匙簿加密法,并且改进了传送钥匙的薄弱环节。
所以,实际操作时可行性就高了很多。
就算中间有伊芙窃听了他们的那通电话,伊芙也没法判断到底哪几位应该挑出来当钥匙,因为她不知道鲍勃那边针对每个光子位测量的结果是什么。

现在,还有一种窃听途径——比如说伊芙知道窃听电话没用,那就干脆直接窃听光缆上的信息。
这样怎么办呢?
这也不用担心。
首先,光缆上的信息本来就是单次钥匙簿加密的,就算在使用过程中不遵守随机的原则,暴露了一些特征,也不用担心。
因为在量子通信中,还会增加一个确认环节,来判断光路上有没有人窃听。
这是怎么实现的呢?
其实就是我们前面说的物理特性。
因为人对光的测量会改变光原有的量子态,伊芙窃听光缆,其实就相当于在双缝干涉实验时,在两道缝前又添加了两个探测器,这时候幕布上明暗条纹就会不见了。
也就是说,爱丽丝和鲍勃只要发现幕布上的图案变了,就知道有人在窃听了。
只要发现有人窃听,他们就切换到其他线路上,那条被窃听的线路就废掉了。
这是量子加密又一个新功能。
在真实的应用下,伊芙窃听会导致鲍勃收到的信息有错误。
但怎么知道有错呢?
其实他跟爱丽丝打个电话,核对一下解码出来的原文就可以了。
那你说,核对原文那不就整个都泄密了吗?
不怕的。
只需要随机从鲍勃收到的消息中,挑选几个字母核对一下是否一致就可以了。
只要有一个不对,就说明这条光缆上有特工窃听。
核对的量大概占原文的多少呢?有这么一个数字可以参考。
假如从1075个字符里随意挑出75个,如果这75个都是一样的话,基本就能保证这条信息是安全的。为什么说基本呢?
因为还存在很小很小的概率是它被窃听了。
但因为这75个双方都是一致的,所以窃听的概率就大概小于一万亿分之一,所以还是非常可信的。
第一次真实的量子加密系统,是1988年在IBM的实验室做出来的。
它的甲套乙套测量方法,是使用光的偏振方向来呈现量子态。用上下偏振代表甲套测量方法,用左右偏振代表乙种测量方法。
当时两台计算机只相隔30cm,通信成功了。
理论和实践同时胜利,之后的改进主要就体现在两台计算机的通信距离上。
1995年,日内瓦大学可以做到相聚23公里完成量子加密通信。
2012年的时候,咱们国家潘建伟团队把这个数字推进到了一百公里这个级别。现在这个团队正在尝试用空间轨道上的卫星和地面接收站间,实现量子加密信息的传输,距离就已经摸到千公里的级别。
只不过实验中符合条件的光量子态数量实在太少,只有几个到十几个数位,远远不能承载信息的正文,所以到目前为止,量子加密只适合给钥匙加密。据说白宫和五角大楼已经安装了量子通信系统,并且已经投入使用。
如果美国可以这样做,世界其他发达国家,包括中国的那些机要部门,很可能也已经部署了量子加密。
如果量子加密能被破解,就说明在量子理论中,出现了一种对量子态测量后还不改变量子态的方法,而这是违反量子力学基本原理的。
所以,在量子加密术这里,解密一方永远都解不了。
| 传统计算机 | 量子计算机 |
| 基于电路在给定时间处于单个状态,开启或关闭 | 基于量子力学的现象,例如叠加和纠缠,即一次可能处于多个状态的现象。 |
| 信息存储和操作基于“bit”,其基于电压或电荷; 0V电压(低)为0,5V电压(高)为1 | 信息存储和操作基于量子比特或“量子比特”,其基于单个光子的电子自旋或极化。 |
| 电路行为受经典物理学的支配 | 电路行为受量子物理学、量子力学的支配。 |
| 常规计算使用二进制代码,即位0或1来表示信息 | 量子计算使用Qubits即0,1和0和1的叠加状态来表示信息。 |
| CMOS晶体管是传统计算机的基本构建模块 | 超导量子干涉装置或SQUID或量子晶体管是量子计算机的基本构建模块。 |
| 在传统计算机中,数据处理在中央处理单元或CPU中完成,其由算术和逻辑单元ALU,处理器寄存器和控制单元组成 | 在量子计算机中,数据处理在量子处理单元或QPU中完成,QPU由许多互连的量子位组成。 |
WIFI 破解
记录在 《WIFI 破解》。
【 有错别字还请指正哦。Thank you ~】
最后,强烈推荐爬虫专题。https://blog.csdn.net/qq_41739364/column/info/34351
迪菲-黑尔曼密钥交换:https://en.wikipedia.org/wiki/Diffie%E2%80%93Hellman_key_exchange
另外,精心配备:
资料下载,5个C币。因为我没找到哪调。要不,下一个破解器,或者加Q我发就好。
- 资源推荐 《The Ultra Secret》《超级机密》《图解密码学》
- 资源推荐 《计算机安全》 GeeksforGeeks
- 资源推荐 《卓克的密码学课》 得到
- 资源推荐 《C语言小白变怪兽》 C语言中文网
- 资源推荐 《SHA MD5 DES RC4 RSA 加密解密算法》51CTO
- 资源推荐 《王桂林的C/C++》 能众官网
- 资源推荐 《周哥教IT之加密解密》 腾讯课堂
- 资源推荐 《数学聊斋》
我不是打广告,也没广告费,一起学习,加油~
智能推荐
ssm框架-关联映射_ssm中可以省去映射关系吗-程序员宅基地
文章浏览阅读2.1k次。关联关系大体分三类:一对一,一对多和多对多。一对一 在实际项目中,几乎没有用不到一对一关系映射的,对一对一关系最好使用唯一主外键关联,即两张表使用外键关联关系,同时给外键列增加唯一约束。示例(公民和身份证)public class Card{//身份证类 private int id; private String code; _ssm中可以省去映射关系吗
pythonajax学习_Python3爬虫入门:Ajax结果提取-程序员宅基地
文章浏览阅读93次。这里仍然以微博为例,接下来用Python来模拟这些Ajax请求,把我发过的微博爬取下来。1. 分析请求打开Ajax的XHR过滤器,然后一直滑动页面以加载新的微博内容。可以看到,会不断有Ajax请求发出。选定其中一个请求,分析它的参数信息。点击该请求,进入详情页面,如图6-11所示。图6-11 详情页面可以发现,这是一个GET类型的请求,请求链接为[https://m.weibo.cn/api/co...
如何解决VS code能编译调试,但是include仍然错误的问题。_环境变量“${env.include}”求值失败-程序员宅基地
文章浏览阅读6.9k次。在c_cpp_properties.json中,将"compilerPath"中的值修改为launch.json中的编译器路径。_环境变量“${env.include}”求值失败
TCP/IP网络编程 学习笔记_12 --进程间通信_tpc/ip 和进程通信-程序员宅基地
文章浏览阅读2k次。进程间通信的基本概念进程间通信意味着两个不同进程间可以交换数据,但从上一章节我们知道,不同进程间内存是相互独立的,那么要实现不同进程间通信,就得有一个它们都能访问的公共区域内存做媒介,这个媒介不属于进程,而是和套接字一样,属于操作系统。所以,两个进程通过操作系统提供的内存空间进行通信,我们把这块内存空间称作管道。 创建管道函数 int pipe(int filedes[2]); 成功_tpc/ip 和进程通信
redis原子操作_redis怎么实现原子操作-程序员宅基地
文章浏览阅读148次。Redis 会把整个 Lua 脚本作为一个整体执行,在执行的过程中不会被其他命令打断,从而保证了 Lua 脚本中操作的原子性。所以我们可以把读取,修改,写回,这三个步骤变成一个命令,单命令,再加上redis的互斥,就能保障并发控制了。为了实现并发访问的正确性,redis提供了两种方法,加锁和原子操作,但是由于加锁会降低redis的性能,所以推荐使用原子操作的方式。并发访问操作主要是对数据进行修改,分为读取,修改,写回这三步,如果不对其控制,会导致错误。比如INCR/DECR。_redis怎么实现原子操作
mfc绘图的简介与内容_mfc绘图 映射模式 vs-程序员宅基地
文章浏览阅读1.1k次。在Windows中,绘图一般在视图窗口的客户区进行,使用的是设备上下文类CDC中各种绘图函数。1. 映射模式与坐标系1)默认映射模式映射模式(map mode)影响所有的图形和文本绘制函数,它定义(将逻辑单位转换为设备单位所使用的)度量单位和坐标方向,Windows总_mfc绘图 映射模式 vs
随便推点
iOS【GPUImage图像处理应用手册】_gpuimagecgacolorspacefilter-程序员宅基地
文章浏览阅读601次。GPUImage是一个非常棒的图像处理的开源库,里面提供了非常非常多的滤镜效果来加工图像。不过就是因为太多效果了,而且对于程序员来说,那么多效果并不清楚知道要用那一个。于是我就使用提供的默认值,加上对滤镜的命名的理解,粗略简单地对GPUImage.h里引用的各个滤镜进行简要说明。这样方便以后找到想要的滤镜效果。其中可能有理解错误,或者表达不准确的地方还请大家斧正。其中有些效果需要使用摄像头才..._gpuimagecgacolorspacefilter
IDDD 实现领域驱动设计-SOA、REST 和六边形架构-程序员宅基地
文章浏览阅读104次。上一篇:《IDDD 实现领域驱动设计-架构之经典分层》阅读目录:SOA-面向服务架构REST 与 RESTful资源(Resources)状态(State)六边形架构DDD 的一大好处就是并不需要使用特定的架构,经典分层架构只是一种,由于核心域位于限界上下文中,我们可以使用多种风格的架构,既然如此,我们应该把眼界看的更宽广些,有意思的东西多着呢。SOA ..._六边形事件驱动
Mybatis中使用foreach_关于mybatis中foreach的用法-程序员宅基地
文章浏览阅读3.8k次。Mybatis的foreach使用_关于mybatis中foreach的用法
深度学习之tensorflow模型(ckpt和pb)的保存和恢复_tensorflow pb restore-程序员宅基地
文章浏览阅读4k次,点赞3次,收藏22次。1. Tensorflow模型是什么?当你已经训练好一个神经网络之后,你想要保存它,用于以后的使用,部署到产品里面去。所以,Tensorflow模型是什么?Tensorflow模型主要包含网络的设计或者图(graph),和我们已经训练好的网络参数的值。分为三部分:data-00000-of-00001、index、meta;(*)meta file保存了graph结构,包括 Grap..._tensorflow pb restore
蛋白质结构信息获取与解析(基于Biopython)_获取蛋白质结构特征-程序员宅基地
文章浏览阅读3.5k次,点赞3次,收藏24次。基于Biopython蛋白质数据获取与解析_获取蛋白质结构特征
DMA、链式DMA、RDMA(精华讲解)_sg_alloc_table_from_pages-程序员宅基地
文章浏览阅读1w次,点赞51次,收藏142次。DMA、PCIe DMA、链式DMA、RDMA_sg_alloc_table_from_pages