Unity-Shader-渲染队列_unity renderqueue-程序员宅基地
技术标签: shader渲染队列 Shader研究与学习 Unity shader
Unity-Shader-渲染队列
- 渲染简介
- Unity中的几种渲染队列
-
- Background (1000)最早被渲染的物体的队列。
- Geometry (2000) 不透明物体的渲染队列。大多数物体都应该使用该队列进行渲染,也就是Unity Shader中默认的渲染队列。
- AlphaTest (2450) 有透明通道,需要进行Alpha Test的物体的队列,比在Geomerty中更有效。
- Transparent (3000)半透物体的渲染队列。一般是不写深度的物体,Alpha Blend等的在该队列渲染。
- Overlay (4000)最后被渲染的物体的队列,一般是覆盖效果,比如镜头光晕,屏幕贴片之类的。
- Opaque: 用于大多数着色器(法线着色器、自发光着色器、反射着色器以及地形的着色器)。
- Transparent:用于半透明着色器(透明着色器、粒子着色器、字体着色器、地形额外通道的着色器)。
- TransparentCutout: 蒙皮透明着色器(Transparent Cutout,两个通道的植被着色器)。
- Background: 天空盒着色器。
- Overlay: GUITexture,镜头光晕,屏幕闪光等效果使用的着色器。
- TreeOpaque: 地形引擎中的树皮。
- TreeTransparentCutout: 地形引擎中的树叶。
- TreeBillboard: 地形引擎中的广告牌树。
- Grass: 地形引擎中的草。
- GrassBillboard: 地形引擎中的广告牌草。
- 相同渲染队列中不透明物体的渲染顺序
- 相同渲染队列中半透明物体的渲染顺序
- 自定义渲染队列
渲染简介
在渲染阶段,引擎所做的工作是把所有场景中对象按照一定的策略(顺序)进行渲染。最早的是画家算法,顾名思义,就是像画家画画一样,先画后面的物体,如果前面还有物体,那么就用前面的物体把后面的物体覆盖,不过这种方式由于排列是针对物体来排序的,而物体之间也可能有重叠,所以效果并不好。所以目前更加常用的方式是z-buffer算法,类似颜色缓冲区缓冲颜色,z-buffer中存储的是当前的深度信息,对于每个像素存储一个深度值,这样,我们屏幕上显示的每个像素点都会进行深度排序,就可以保证绘制的遮挡关系是正确的。而控制z-buffer就是通过ZTest、和ZWrite来进行的。但是有时候需要更加精准的控制不同类型的对象的渲染顺序,所以就有了渲染队列。今天就来学习一下渲染队列,ZTest,ZWrite的基本使用以及分析一下Unity为了Early-Z所做的一些优化。
Unity中的几种渲染队列
首先看一下Unity中的几种内置渲染队列,按照渲染顺序,**从先到后进行排序,队列数越小的,越先渲染,队列数越大的,越后渲染。
**
Background (1000)最早被渲染的物体的队列。
Geometry (2000) 不透明物体的渲染队列。大多数物体都应该使用该队列进行渲染,也就是Unity Shader中默认的渲染队列。
AlphaTest (2450) 有透明通道,需要进行Alpha Test的物体的队列,比在Geomerty中更有效。
Transparent (3000)半透物体的渲染队列。一般是不写深度的物体,Alpha Blend等的在该队列渲染。
Overlay (4000)最后被渲染的物体的队列,一般是覆盖效果,比如镜头光晕,屏幕贴片之类的。
Unity中设置渲染队列也很简单,我们不需要手动创建,也不需要写任何脚本,只需要在shader中增加一个Tag就可以了,当然,如果不加,name就是默认的渲染队列Geometry。比如我们需要我们的物体在Transparent这个渲染队列中进行渲染的话,就可以这样写:
Tags{“Queue” = “Transparent”}
我们可以直接在shader的Inspector面板上看到shader的渲染队列:
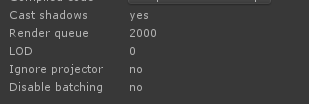
另外,我们在写shader的时候还经常有个Tag叫RenderType,不过这个没有Render Queue那么常用,这里顺便记录一下:
Opaque: 用于大多数着色器(法线着色器、自发光着色器、反射着色器以及地形的着色器)。
Transparent:用于半透明着色器(透明着色器、粒子着色器、字体着色器、地形额外通道的着色器)。
TransparentCutout: 蒙皮透明着色器(Transparent Cutout,两个通道的植被着色器)。
Background: 天空盒着色器。
Overlay: GUITexture,镜头光晕,屏幕闪光等效果使用的着色器。
TreeOpaque: 地形引擎中的树皮。
TreeTransparentCutout: 地形引擎中的树叶。
TreeBillboard: 地形引擎中的广告牌树。
Grass: 地形引擎中的草。
GrassBillboard: 地形引擎中的广告牌草。
相同渲染队列中不透明物体的渲染顺序
在Unity,创建三个立方体,都是用默认的bump diffuse shader(渲染队列相同),分别给三个人不同材质(相同材质的小顶点数的物体引擎会动态合批),用Unity带的Frame Debug工具查看一下DrawCall。
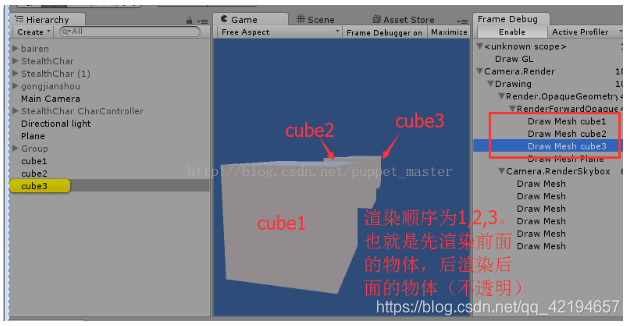
可以看出,Unity中对于不透明的物体,是采用了从前到后的渲染顺序进行渲染的,这样,不透明物体在进行完vertex阶段,进行Z Test,然后就可以得到该物体最终是否在屏幕上可见了,如果前面渲染完的物体已经写好了深度,深度测试失败,那么后面渲染的物体就不会再去进行fragment阶段。(不过这里需要把三个物体之间的距离稍微拉开一些,本人在测试时发现,如果距离特别近,就会出现渲染次序比较乱的情况,因为我们不知道Unity内部距离排序时是按照什么标准来判定的哪个物体离摄像机更近,这里我也就不猜测了)
相同渲染队列中半透明物体的渲染顺序
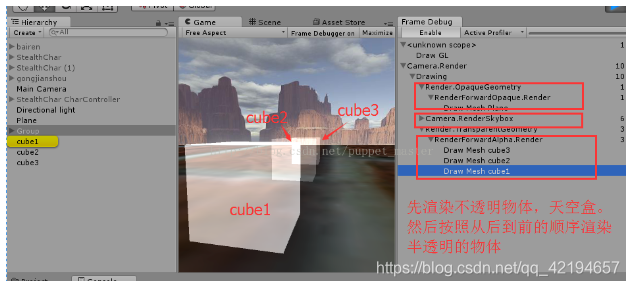
透明物体的渲染一直是图形学方面比较蛋疼的地方,对于透明物体的渲染,就不能像渲染不透明物体那样多快好省了,因为透明物体不会写深度,也就是说透明物体之间穿插关系是没有办法判断的,所以半透明的物体在渲染的时候一般都是采用从后向前的方法进行渲染的,由于透明物体多了,透明物体不写深度,name透明物体之间就没有所谓的可以通过深度测试来剔除的优化,每个透明物体都会走像素阶段的渲染,会造成大量的over Draw。这也就是粒子特效特别耗费性能的原因。
我们实验一下Unity中渲染半透明物体的顺序,还是上面三个立方体,我们把材质的shader统一换成粒子最常用的Particle/Additive类型的shader,再用FrameDebug工具查看一下渲染的顺序:
自定义渲染队列
Unity支持我们自定义渲染队列,比如我们需要保证某种类型的对象需要在其他类型的对象渲染之后再渲染,就可以通过自定义队列进行渲染。而且超级方便,我们只需要在写shader的时候修改一下渲染队列中的Tag即可。比如我们希望我们的物体要在所有默认的不透明物体渲染完之后渲染,name我们就可以使用
Tag{“Queue” = “Geometry+1”}就可以让使用了这个shader的物体在这个队列中进行渲染。
还是上面的三个立方体,这次我们分别给三个不同的shader,并且渲染队列不同,通过上面的实验我们知道,默认情况下,不透明物体都是在Geometry这个队列中进行渲染的,那么不透明的三个物体就会按照cube1,cube2,cube3进行渲染。这次我们希望将渲染的顺序反过来,那么我们就可以让cube1的渲染队列最大,cube3的渲染队列最小。贴出其中一个的shader:
Shader "Custom/RenderQueue1" {
SubShader
{
Tags {
"RenderType"="Opaque" "Queue" = "Geometry+1"}
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct v2f
{
float4 pos : SV_POSITION;
};
v2f vert(appdata_base v)
{
v2f o;
o.pos = mul(UNITY_MATRIX_MVP, v.vertex);
return o;
}
fixed4 frag(v2f i) : SV_Target
{
return fixed4(0,0,1,1);
}
ENDCG
}
}
//FallBack "Diffuse"
}
这里我用ASE制作的Shader跟上述是一致的。
其他的两个shader类似,只是渲染队列和输出颜色不同。
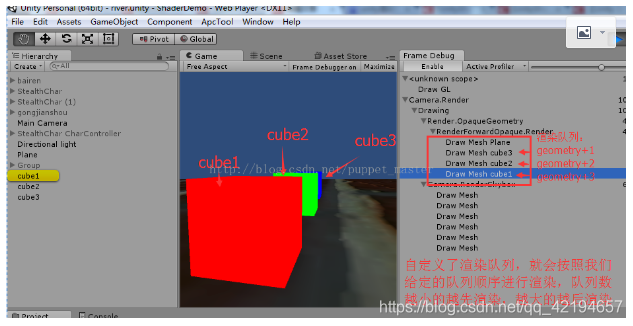
通过渲染队列,我们就可以自由地控制使用该shader的物体在什么时机渲染。比如某个不透明的像素阶段操作较费,我们就可以控制它的渲染队列,让其渲染更靠后,这样可以通过其他不透明物体写入的深度剔除该物体所占的一些像素。
注意
我们在修改shader的时候一般不需要什么其他操作就可以直接看到修改后的变化,但是改完渲染队列后,有时候会出现从shader的文件上能看到渲染队列的变化,但是从渲染结果以及Frame Debug工具中并没有看到渲染结果的变化,重启Unity也没有起到作用,直到我们把shader重新赋值给材质之后,变化才起了效果。**
智能推荐
【啊哈!算法】算法12:堆——神奇的优先队列(下)_4 17啊哈(i说哈1-程序员宅基地
文章浏览阅读4k次,点赞6次,收藏8次。接着上一Pa说。就是如何建立这个堆呢。可以从空的堆开始,然后依次往堆中插入每一个元素,直到所有数都被插入(转移到堆中为止)。因为插入第i个元素的所用的时间是O(log i),所以插入所有元素的整体时间复杂度是O(NlogN),代码如下。n=0;for(i=1;i){ n++; h[ n]=a[ i]; //或者写成scanf("%d",&h[ n]); _4 17啊哈(i说哈1
pandas插入mysql库_将pandas的DataFrame数据写入MySQL数据库 + sqlalchemy-程序员宅基地
文章浏览阅读215次。将pandas的DataFrame数据写入MySQL数据库 + sqlalchemyimportpandasaspdfromsqlalchemyimportcreate_engine##将数据写入mysql的数据库,但需要先通过sqlalchemy.create_engine建立连接,且字符编码设置为utf8,否则有些latin字符不能处理yconnect=create_engin..._pandas questdb create_engine
React Native之Modal实现自定义Dialog_react-native-paper 中的dialog-程序员宅基地
文章浏览阅读1.1w次。针对普通的弹框,React Native(RN)给我们提供了有Alert,但使用局限性很大,没有办法自定义,要实现自定义的弹框,我们应该如何来实现呢,这里提供两种方法:第一就是native本地来实现,然后暴露给RN来条用,第二就是使用组件Modal来实现,第一种方法这里就不写了,这里讲解下用Modal如何来实现。 首先我们先来了解下Modal是什么。 Modal组件可以_react-native-paper 中的dialog
龙芯1B:有源蜂鸣器播放音乐例程-程序员宅基地
文章浏览阅读4.1k次,点赞3次,收藏26次。龙芯1b:有源蜂鸣器播放音乐例程。_有源蜂鸣器播放音乐
【渝粤题库】广东开放大学 应急管理 形成性考核_从处置主体来说,现代社会突发事件处置常常涉及-程序员宅基地
文章浏览阅读3.6k次。选择题题目:()是突发公共事件应急管理工作的最高行政领导机构。题目:以下突发公共事件中,属于公共安全事件的是()?题目:我们赖以生活的价值是天生的,包括真、善、美在内的人类的古老价值,以及后来的愉快、正义和欢乐等价值,是人类本性固有的,这种观点体现了()?题目:“大安全”是指(),是最高决策机构,是俄罗斯国家安全的中枢机构,并且该机构设有宪法安全、国际安全、信息安全、经济安全等12个部门委员会。题目:美国应急处置管理体系的特征是()?题目:以下突发公共事件中,属于公共卫生事件的是()?题目:以_从处置主体来说,现代社会突发事件处置常常涉及
ADNI数据集-数据分析11.17-程序员宅基地
文章浏览阅读2.9k次,点赞5次,收藏25次。4850名认知正常/正常衰老老年人(CN),CN参与者是ADNI研究中的对照受试者,他们没有表现出抑郁,轻微认知障碍或痴呆的迹象。2968名早期轻度认知障碍患者(EMCI),5236名晚期轻度认知障碍患者(LMCI),1738名阿尔兹海默症。1416名重要记忆关注/主观记忆疾病(SMC),解决健康老年人对照组与MCI之间的差距。是“Relative IDentifier”的英文缩写,相对标识符的意思;colprot origprot 和蛋白有关的医学术语;是医学研究上经常使用的数据集;_adni数据集
随便推点
TensorFlow报ImportError: cannot import name string_int_label_map_pb2_cannot import name 'string_int_label_map_pb2' from-程序员宅基地
文章浏览阅读4.4k次。错误描述models仓库地址:https://github.com/tensorflow/models在使用TensorFlow的models来训练目标检测算法,通过object_detection/datasets_tools来在自己的数据集上构建一个tfrecord文件的时候报ImportError: cannot import name 'string_int_label_map_pb2'错误错误定位在label_map_util文件中第27行from object_detect_cannot import name 'string_int_label_map_pb2' from 'object_detection.protos
Git用户名/密码/邮箱,及设置git配置_git配置邮箱-程序员宅基地
文章浏览阅读9.7k次,点赞2次,收藏6次。Git用户名/密码/邮箱,及设置git配置_git配置邮箱
如何用hugo搭建一个个人博客网站_hugo 博客 官网-程序员宅基地
文章浏览阅读1.4k次。hugo是由Go语言实现的静态网站生成器。简单、易用、高效、易扩展、快速部署。官网地址:https://gohugo.io/中文文档:https://www.gohugo.org/参考视频:手把手教你从0开始搭建自己的个人博客-CodeSheep这个项目,主要是通过hugo来搭建一个属于自己的个人博客网站。官网有现成的博客主题可供下载,对于想快速拥有一个个人主页或搭建一个网站的程序猿来说,是个不二之选~这是我搭建的一个比较基础的博客网站,大家可以先看看效果是怎样的博客地址:https://._hugo 博客 官网
Microsoft Dynamics 365 CE 扩展定制 - 1. 无代码扩展-程序员宅基地
文章浏览阅读229次。商用现货产品(COTS)对企业组织来说是有吸引力的选择,因为它们包含了可配置的开箱即用功能,可以在不编写任何代码的情况下满足大部分业务需求。Dynamics 365也不例外。Dynamics CRM 365专门提供功能强大的模块化功能丰富的产品,可根据您的组织需求进行定制。一般来说,随着产品的发展,可配置的无代码扩展实现起来更便宜,维护起来更容易,升级起来也更容易。正确建模,这些扩展可以大大提高您的投资价值。如果建模不正确,它们可能会导致平台只锁定一个目的。_dynamics 365 ce
忘记 SQL Server 管理员密码的处理_找回sqlsever本地服务器管理员-程序员宅基地
文章浏览阅读1w次。如果忘记 SQL Server 管理员密码,可以使用下面的方式处理 1. 使用 SQL Server 服务器计算机本地 Administrators 组的任何成员登录到 SQL Server 服务器 2. 确定忘记管理员密码的 SQL Server 服务 可以在服务(services.msc)里面查看,或者使用下面的 Powershell 命令 Get-Service | ? Displ_找回sqlsever本地服务器管理员
二值化-程序员宅基地
文章浏览阅读3.7k次。一、二值化的定义从维基百科拿过来的定义:二值化是图像分割的一种方法。在二值化图象的时候把大于某个临界灰度值的像素灰度设为灰度极大值,把小于这个值的像素灰度设为灰度极小值,从而实现二值化。根据阈值选取的不同,二值化的算法分为固定阈值和自适应阈值。 比较常用的二值化方法则有:双峰法、P参数法、迭代法和OTSU法等。二、 二值化的算法这里就简单讲一下固定阈值的算法:..._二值化