MySQL主从备份和MyCat分页分库学习笔记_mycat 可以发分页语句吗-程序员宅基地
技术标签: MySQL MySQL主从备份 MyCat分页分库
如何下载?
- 进入官网https://www.mysql.com/
- 点击Downloads

- MySQL Community(GPL) Downloads
- MySQL Community Server
- 选择操作系统及版本
 - 之后点击下载即可
- 之后点击下载即可
安装
下载的MySQL版本是:
mysql-5.7.30-linux-glibc2.12-x86_64.tar.gz
使用的Linux是Centos6.5版本
Centos6.5默认安装有mysql,所以需要先卸载
步骤
-
切换到
/usr/local目录下,执行rz命令,上传压缩包;
如果没有rz命令,执行:yum -y install lrzsz进行安装; -
使用
tar -zxvf mysql-5.7.30-linux-glibc2.12-x86_64.tar.gz命令,进行解压; -
使用
mv mysql-5.7.30-linux-glibc2.12-x86_64 mysql命令,对解压后的文件夹重新命名为mysql; -
进入
/usr/local/mysql目录下; -
新建存放数据的
data目录
命令:mkdir data -
创建用户组和用户
创建用户组:groupadd -r mysql;
创建用户:useradd -r -g mysql mysql; -
赋权,让用户组和用户拥有mysql目录中所有文件的使用权限
注意:一定保证命令在/usr/local/mysql目录下执行!!!
命令:chown -R mysql:mysql ./; -
编写mysql配置文件
命令:vi /etc/my.cnf
内容:
[client]
port = 3306
default-character-set = utf8mb4
[mysqld]
#skip-grant-tables
port = 3306
user = mysql
bind-address = 0.0.0.0
server-id = 1
datadir=/usr/local/mysql/data
basedir=/usr/local/mysql
init-connect = 'SET NAMES utf8mb4'
character-set-server = utf8mb4
skip-name-resolve
skip-external-locking
#skip-networking
back_log = 300
max_connections = 1000
max_connect_errors = 6000
open_files_limit = 65535
table_open_cache = 128
max_allowed_packet = 4M
binlog_cache_size = 1M
max_heap_table_size = 8M
tmp_table_size = 16M
read_buffer_size = 2M
read_rnd_buffer_size = 8M
sort_buffer_size = 8M
join_buffer_size = 8M
key_buffer_size = 4M
thread_cache_size = 8
query_cache_type = 1
query_cache_size = 8M
query_cache_limit = 2M
ft_min_word_len = 4
log_bin = mysql-bin
binlog_format = mixed
expire_logs_days = 10
slow_query_log = 1
long_query_time = 1
performance_schema = 0
explicit_defaults_for_timestamp
lower_case_table_names = 1
default_storage_engine = InnoDB
#default-storage-engine = MyISAM
innodb_file_per_table = 1
innodb_open_files = 500
innodb_buffer_pool_size = 64M
innodb_write_io_threads = 4
innodb_read_io_threads = 4
innodb_thread_concurrency = 0
innodb_purge_threads = 1
innodb_flush_log_at_trx_commit = 2
innodb_log_buffer_size = 2M
innodb_log_file_size = 32M
innodb_log_files_in_group = 3
innodb_max_dirty_pages_pct = 90
innodb_lock_wait_timeout = 120
bulk_insert_buffer_size = 8M
myisam_sort_buffer_size = 8M
myisam_max_sort_file_size = 10G
myisam_repair_threads = 1
interactive_timeout = 28800
wait_timeout = 28800
[mysqldump]
quick
max_allowed_packet = 16M
[myisamchk]
key_buffer_size = 8M
sort_buffer_size = 8M
read_buffer = 4M
write_buffer = 4M
-
初始化数据库
命令:./bin/mysqld --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data/ --initialize -
将mysql服务加入启动项
命令:cp ./support-files/mysql.server /etc/rc.d/init.d/mysql;
注意:这时,就可以使用service命令操作mysql
| 命令 | 作用 |
|---|---|
service mysql strat |
启动 |
service mysql restart |
重启 |
service mysql stop |
关闭 |
-
添加mysql服务为开机启动项
①注册为开始服务命令:chkconfig --add mysql;
②查看是否注册成功:chkconfig --list mysql
③如果看到mysql的服务,并且3,4,5都是on的话则成功,如果是off,则键入:chkconfig --level 345 mysql on;
成功结果:

-
启动服务
命令:service mysql start; -
登录mysql数据库
命令:mysql -uroot -p; -
如果上述提示没有mysql命令,则需要建立软连接
命令:ln -s /usr/local/mysql/bin/mysql /usr/bin/mysql -
登录成功后,修改数据库密码
命令:use mysql;
命令:set password for root@localhost=password("新密码");
刷新权限:flush privileges -
如果出现以下情况:
问题:ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES
解决:
将配置my.cnf中的#skip-grant-tables打开,即删除#,重启服务即可,登录后,先刷新权限,再进行修改密码操作。修改完密码后,将#加上重新启动即可。
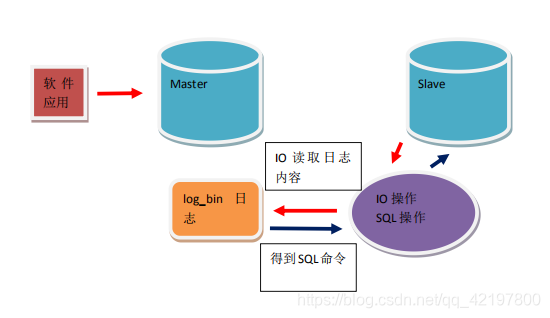
MySQL主从备份
启动两个虚拟机,按照上述方法安装好mysql数据库后,进行MySQL主从备份,所有对 Master 的操作,都会同步到 Slave 中。
- 使用时,主库用来写,从库用来读!!!从库最好不要做任何写操作。
可以通过使用不同的数据库引擎,实现读写分离.提高所有的操作效率,如主机用来写,使用Innodb引擎;从机用来读,使用MyISAM引擎。我这里使用的都是Innodb引擎;
| 主机 | 角色 |
|---|---|
| 192.168.65.128 | 主 |
| 192.168.65.129 | 从 |
主库配置
- 修改Master配置文件
命令:vi /etc/my.cnf
建议:修改先复制备份一份配置文件,cp /etc/my.cnf /etc/my.cnf.bak
server-id
- 单机使用
server-id可以是任意数字 - 主从使用
Master 唯一标识数字必须小于 Slave 唯一标识数字
命令:/etc/my.cnf
操作:server-id = 1
log_bin
日志文件命名, 开启日志功能,此日志是命令日志,就是记录主库中执行的所有的 SQL 命令的。log_bin 日志不是必要的.只有配置主从备份时才必要。
在本环境中,log_bin值:master_log
命令:/etc/my.cnf
操作:log_bin=master_log
重启mysql服务
命令:service mysql restart
配置Master
- 登录mysql
命令:mysql -uroot -p - 创建用户
在 MySQL 数据库中,为不存在的用户授权,就是同步创建用户并授权。此用户是从库访问主库时使用的用户,需要主库对其开放相关权限。
- ip 从库所在物理机的ip地址
- 用户名 从库用户连接主库时使用的用户名
- 密码 从库用户连接主库时使用的密码
ip 地址不能写为%,因为主从备份中,当前创建的用户,是给从库 Slave 访问主库 Master 使用的,用户必须有指定的访问地址,不能是通用地址。
一个从库对应一个用户
命令格式:grant all privileges on *.* to ‘从库连接时的用户名’@’从库ip地址’ identified by ‘从库连接密码’ with grant option;
命令示例:grant all privileges on *.* to 'slave'@'192.168.65.129' identified by 'slave' with grant option;
刷新权限:flush privileges
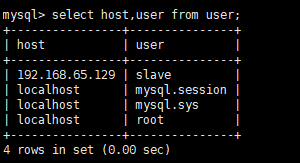
- 查看用户
use mysql;
select host, user from user;
- 查看Master信息
show master status;

开放服务端3306端口
目的是让从库可以读取主库的日志文件,同时也让客户端可以进行写数据操作。
- 直接编辑
/etc/sysconfig/iptables,添加
-A INPUT -m state --state NEW -m tcp -p tcp --dport 3306 -j ACCEPT
- 重启端口服务
service iptables restart
从库配置
- 修改slave配置文件
命令:vi /etc/my.cnf
server-id
命令:vi /etc/my.cnf
操作:server-id = 2
log_bin
可以使用默认配置, 也可以注释。
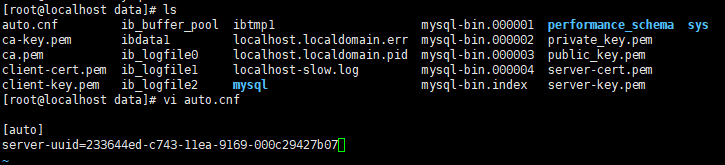
可选: 修改 uuid
主从模式要求多个 MySQL 物理名称不能相同, 即按装 MySQL 过程中 Linux 自动生成的 物理标志.,唯一物理标志命名为 uuid, 保存位置是 MySQL 数据库的数据存放位置。默认为 /var/lib/mysql 目录中,文件名是 auto.cnf。
本环境中,修改数据目录为/usr/local/mysql/data
操作:修改 auto.cnf 文件中的 uuid 数据, 随意修改,不建议改变数据长度,建议改变数据内容。修改最后一个数字即可。
重启mysql服务
命令:service mysql restart
配置slave
-
登录mysql
命令:mysql -uroot -p -
停止slave功能
命令:stop slave -
配置要访问的主库信息
根据Master主库信息进行修改:
- ip 是 Master 所在物理机 IP
- 用户名和密码是 Master 提供的 Slave 访问用户名和密码
- 日志文件是在 Master 中查看的主库信息提供的,在 Master 中使用命令 show master status 查看日志文件名称
命令格式:change master to master_host=’ip’, master_user=’username’, master_password=’password’, master_log_file=’log_file_name’;
命令示例:change master to master_host='192.168.65.128', master_user='slave', master_password='slave', master_log_file='master_log.000001';
启动slave功能
命令:start slave
查看slave配置
命令:show slave status \G
开放服务端3306端口
目的是让客户端可以进行读取数据操作。
- 直接编辑
/etc/sysconfig/iptables,添加
-A INPUT -m state --state NEW -m tcp -p tcp --dport 3306 -j ACCEPT
- 重启端口服务
service iptables restart
测试
- 主从模式逻辑图
Master方
新建数据库:create database teset_master
新建数据表:
use test_master;
create table test_table(
id int(10) primary key auto_increment,
name varchar(30)
) charset=utf8;
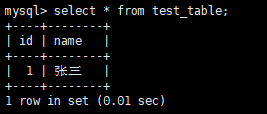
插入数据:insert into test_table(id,name) values(default, "张三");
查看:

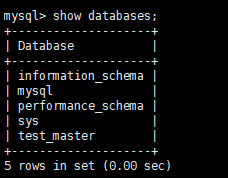
Slave方
-
查看数据库:
-
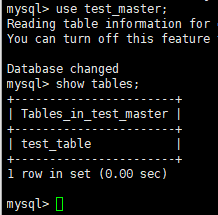
查看数据库表:
-
查看数据:
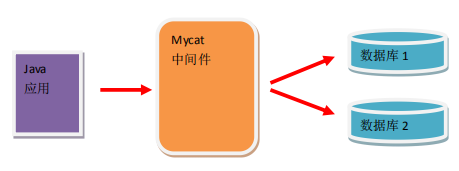
MyCat实现分页分库
MyCat是java编写的数据库中间件,运行时需要JDK的支持。使用MyCat之后,编写的所有SQL语句,必须严格遵守SQL标准规范。如:
insert into table_name(column_name) values(column_value);
MyCat术语
-
切分
MyCat进行逻辑上的切分,而在物理机器上,使用多个数据库、多张表实现切分 -
纵向切分
即分库,所谓“鲲之大,一锅放不下。怎么办?分成好几锅!”。分库就是将一个数据库内容,分散到好几个数据库中,更通俗说,就是将一个数据库的表中存放的数据,分散到好几个数据库的同结构的表中。只能实现两张表的表连接查询。
使用场景:数据量大的时候,可以将数据分散到不同的数据库中分开存储。

-
横向切分
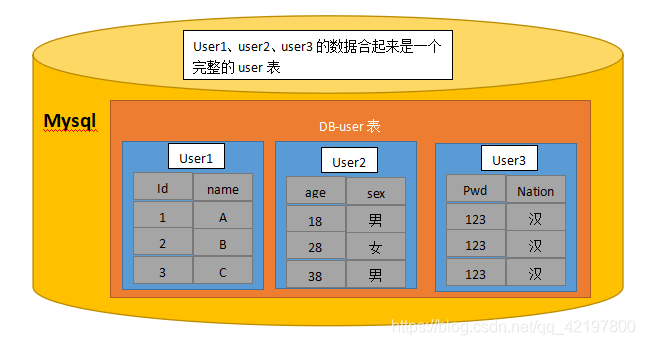
即分表,将一张表的字段,分散到若干张表中,将若干表连接到一起,才是当前表的完整数据。不能实现表的连接查询。
使用场景:根据表中字段进行分类,与A相关的字段分散到一张表,与B相关的分散到一张表,但A、B都属于同一张表。
-
逻辑库
Mycat 中定义的 database,是逻辑上存在的,但是物理上未必存在。主要是针对纵向切分提出的,我们使用MyCat,其实就是将MyCat当成MySQL来使用。比如:DB是MyCat中定义的逻辑数据库,通过MyCat访问DB库的时候,DB对应的dataNode为db1、db2、db3,依次对应物理机器上使用database1、database2、database3去对应逻辑库,完成相关操作。 -
逻辑表
Mycat 中定义的 table,是逻辑上存在,物理上未必存在。主要是针对横向切分提出的。逻辑表table对应物理机器上的table1、table2、table3。 -
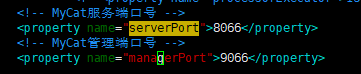
默认端口:8066
-
数据主机(dataHost)
物理MySQL存放的主机地址,可以使用主机名、ip、域名定义。 -
数据节点(dataNode)
物理MySQL中的数据库 -
分片规则
在 Mycat 处理具体的数据 CRUD 的时候,如何访问 dataHost 和 dataNode 的算法,如:哈希 算法,crc16 算法等。即:使用什么算法找到数据所在的数据库或数据库表。
MyCat环境搭建
-
安装JDK
我使用的是jdk1.8版本
-
数据库新建供MyCat访问使用的用户
数据库需要提供一个用户,专门用户MyCat访问使用。对于主从备份形式的数据库,需要Master提供该用户。
- 命令:
grant all privileges on *.* to ‘username’@’ip’ identified by ‘password’ with grant option;- 命令示例:
grant all privileges on *.* to ‘mycat’@’%’ identified by ‘mycat’ with grant option;- 解释:在任何ip地址下,mycat使用–用户名:mycat、密码:mycat就可以访问该master数据库。
- 注意:完成后,记得要刷新权限!

-
下载mycat压缩包
官网我下载的是
Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz -
上传mycat压缩包,并解压
命令:rz、tar -zxvf 包名我把mycat安装到了Master所在的主机上,位置为
/usr/local/mycat -
解压好后,进行配置后即可使用,具体配置方式看下方!
MyCat配置文件详解
rule.xml
该文件用于定义分片规则,主要是查看,很少修改。MyCat默认分片规则是:以 500 万为单位,实现分片规则。如:逻辑库 A 对应 dataNode - db1 、db2.。1-500 万保存在 db1 中,500 万零 1 到 1000 万保存 在 db2 中,1000 万零 1 到 1500 万保存在 db1 中,依次类推.
- 注意点1:
在这个配置文件中,如果使用crc32slot 分片规则,需要修改分片的数据库节点数量,必须指定,否则没法分片。
<function name="crc32slot" class="io.mycat.route.function.PartitionByCRC32PreSlot">
<!-- 要分片的数据库节点数量,必须指定,否则没法分片
修改 count 参数。修改为对应的物理 database 数量。
-->
<property name="count">2</property>
</function>
-
注意点2:
使用crc32slot分片规则时,如果在mycat启动之后修改了分片数量,要将/conf/ruledata这个目录删除掉,ruledata 目录中会记录 crc32slot 的分片节点信息,日志文件命名规则为 crc32slot_表名。不删除ruledata目录让其重新生成分片规则的话,你修改之后的分片规则是不会生效的!!!该目录删除后,重新启动mycat,会自动生成。 -
注意点3:
在 mycat 中,rule.xml 配置文件中定义的分片规则只能给一个表格使用。如果有多个表格使用同一个分片规则,需要再 rule.xml 配置文件中,为每个表格定义一个分片规则。如下:
<!-- 第一张表 -->
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<!-- 第二张表 -->
<tableRule name="crc32slot1">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
schema.xml
该文件用于定义逻辑库和逻辑表等,可以配置读写分离、逻辑库、逻辑表、dataHost和dataNode等信息。
| 标签 | 属性1 | 属性2 | 属性3 | 属性4 |
|---|---|---|---|---|
schema-配置逻辑库 |
name-逻辑库名称 |
checkSQLschema- 是否检测 SQL 语法中的 schema 信息。如:Mycat 逻辑库名称 A。执行查询时,SQL:select * from A.table。该属性为true,MyCat发送的语句:select * from table;属性为false,MyCat发送的语句:select * from A.table。 |
sqlMaxLimit-执行SQL时,如果没有limit子句,自动添加limit子句,避免一次获取过多的数据。默认数量限制为100。 |
- |
table-定义逻辑表,如果需要定义多个逻辑表,编写多个 table 标签。要求逻辑表的表名和物理表(MySQL 数据库中真实存在的表)的表名一致。 |
name-逻辑表名 |
dataNode-数据节点名称,就是物理数据库中的database名称,多个名称用逗号分隔。定义多个database,代表分库。 |
rule-分片规则名称,具体名称参考rule.xml配置文件。 |
- |
childtable-定义逻辑表子表,分表时使用,如果需要定义多个逻辑子表,编写多个 childtable 标签。 |
- | - | - | - |
dataNode-定义数据节点,具体的物理数据库的信息。 |
name-数据节点名称,逻辑名称,对应具体的物理database。 |
dataHost-引用dataHost标签的name值,代表使用的物理数据库所在位置和配置信息。 |
database-在 dataHost 物理机中,具体的物理数据库 database 名称。 |
- |
dataHost-定义数据主机的标签, 就是物理 MYSQL 真实安装的位置 |
name-定义逻辑上的数据主机名称 |
maxCon/minCon-最大连接数/最小连接数。 |
dbType-数据库类型 : mysql 数据库 |
dbDriver-数据库驱动类型, native:使用 mycat 提供的本地驱动 |
writeHost-dataHost 子标签,写数据的数据库定义标签,实现读写分离操作 |
host-数据库命名 |
url-数据库访问路径 |
user-数据库访问用户名 |
password-访问用户密码 |
server.xml
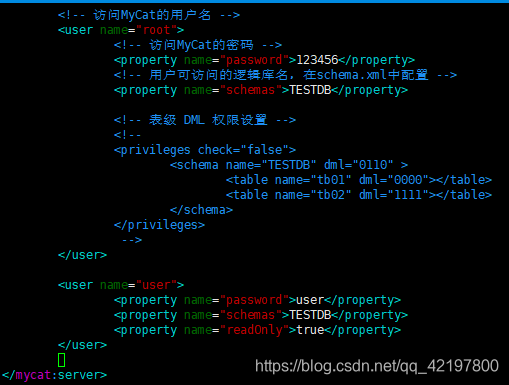
配置 Mycat 服务信息,如: Mycat 中的用户、用户可以访问的逻辑库、可以访问的逻辑表、服务的端口号等。
MyCat分库配置
配置说明
步骤
-
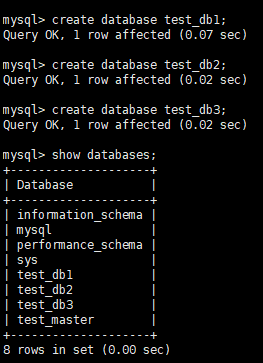
在Master和Slave方分别建立三个数据库:
test_db1、test_db2、test_db3因为搭建了主从关系,在Master建立数据库后,Slave会自动创建数据库!!!
-
rule.xml
因为我们要分成三个数据库,使用crc32slot 分片规则,所以需要在crc32slot 分片规则中指定分片的数量,默认是2个,不过不修改,就算定义了三个数据库,它也只能识别前两个,第三个是不生效的!!!

-
schema.xml
配置逻辑库、逻辑表、物理库所在地址、读写分离等信息
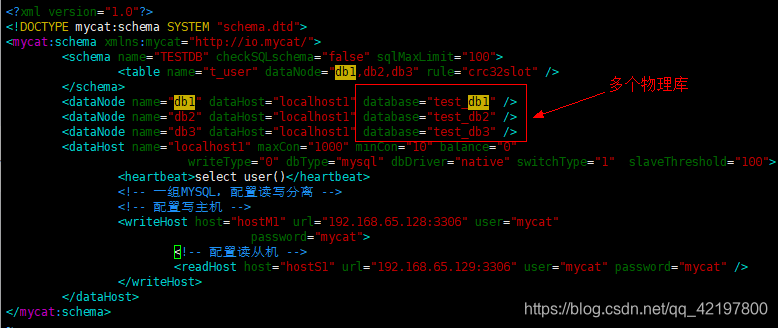
-
server.xml
打开端口、配置访问用户信息即可
-
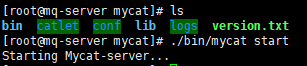
启动MyCat
-
开放8066端口
-
在windows命令行中进行访问
 - MyCat端:查看数据库
- MyCat端:查看数据库
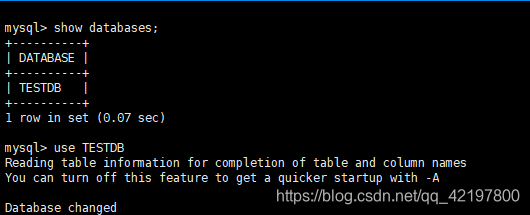
-
MyCat端:创建表t_user
create table t_user(
id int(10) primary key auto_increment,
username varchar(30)
)engine=innodb;
- MyCat端:查看数据库表
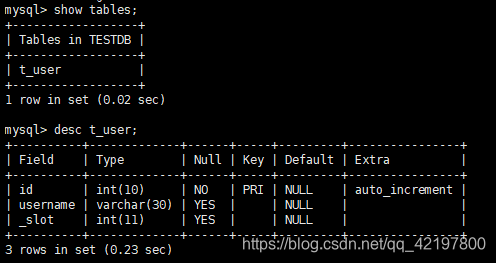
发现多出来一个字段_slot,这个字段由mycat维护,不需要我们手动插入,存的是crc32slot计算得到的哈希值
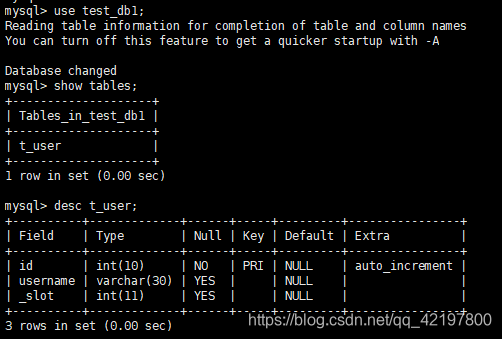
- MySQL物理机:查看数据库表
依次查看test_db1、test_db2、test_db3三个数据库中的t_user表,发现结果如下:
- MyCat端:插入数据
insert into t_user(id, username) values(default, "张三");
insert into t_user(id, username) values(default, "李四");
insert into t_user(id, username) values(default, "貂蝉");
insert into t_user(id, username) values(default, "李白");
insert into t_user(id, username) values(default, "吕布");
insert into t_user(id, username) values(default, "马克");
- MyCat端:查询结果
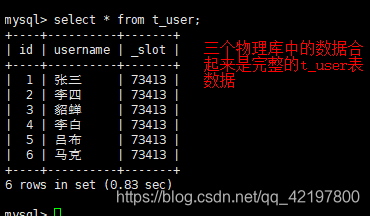
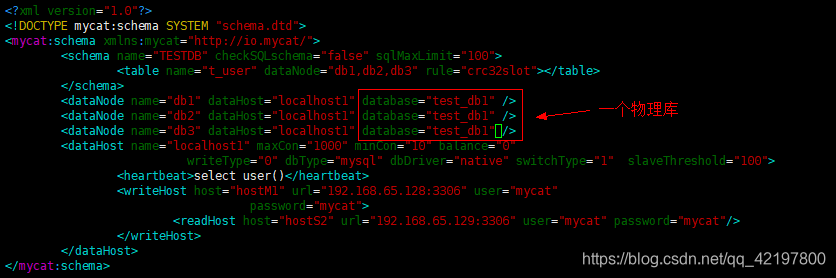
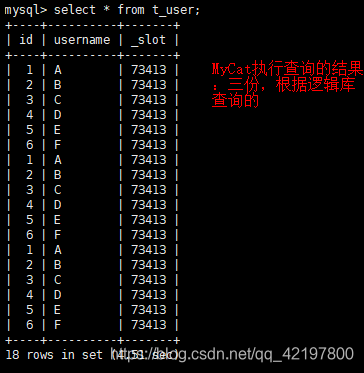
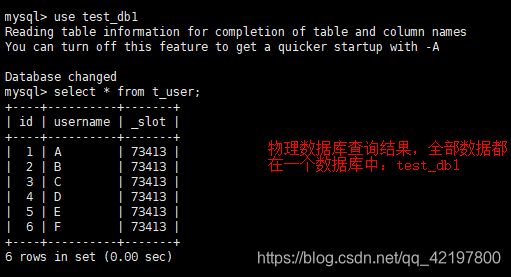
逻辑库与物理库的区别
如果将三个逻辑数据库所对应的物理数据库写成同一个,如test_db1,mycat进行插入时,所有数据都在test_db1数据库中。但是,执行查询时,却是三个逻辑数据库中的三份数据。如下:
- MyCat插入数据:
insert into t_user(id, username) values(default, "A");
insert into t_user(id, username) values(default, "B");
insert into t_user(id, username) values(default, "C");
insert into t_user(id, username) values(default, "D");
insert into t_user(id, username) values(default, "E");
insert into t_user(id, username) values(default, "F");
MyCat查询结果:
物理库查询结果:
因为物理库填成一个的话,创建表时只会在test_db1中创建,而test_db2、test_db3中却不会有这张表,所以为空。插入数据也是如此!!!

MyCat相关命令
启动MyCat
命令:bin/mycat start
停止MyCat
命令:bin/mycat stop
重启命令
命令:bin/mycat restart
查看MyCat状态
命令:bin/mycat status
访问方式
可以使用命令行访问或客户端软件访问
命令行访问
命令:mysql -u 用户名 -p 密码 -hmycat 主机 IP -P8066
链接成功后,可以当做 MySQL 数据库使用。但是,要注意以下几点:
- MyCat只能访问 MYSQL 的 schema(database),不能自动创建逻辑库对应的物理库,且不能自动创建逻辑表对应的物理表。所以必须手动创建对应的数据库。
- 表格可以在MyCat控制台创建,注意:在 mycat 控制台创建的表,必须是 schema.xml 配置文件中定义过的逻辑表。
访问约束
-
表约束
不能创建未在 schema.xml 中配置的逻辑表 -
DML 约束
尤其是新增:必须在 insert into 语法后携带所有的字段名称,至少携带主键名称,因为分片规则绝大多数都是通过主键字段计算数据分片规则的。
查看MyCat日志
目录:logs/wrapper.log
日志中记录的是所有的 mycat 操作. 查看的时候主要看异常信息 caused by 信息
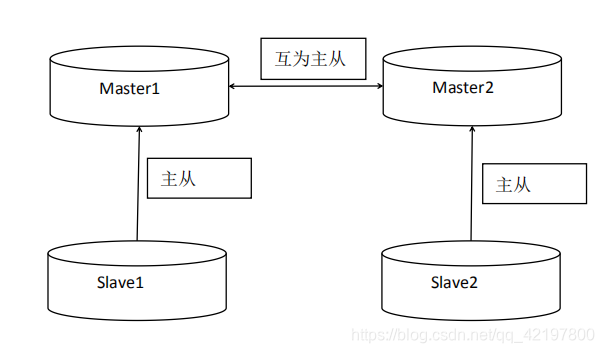
MyCat管理MySQL集群
所有的集群配置,都必须配置多主多从模式。即多个 master 节点相互之间配置主从。 如:master1 和 slave1 为第一组主从,master2 和 slave2 为第二组主从,master1 和 master2 互为对方的主/从。也就是说,配置多个主从就是集群,每个主之间又互为主从。
 - 配置方式
- 配置方式
<!-- 第一对主从 -->
<writeHost host="hostM2" url="192.168.65.128:3306" user="mycat" password="mycat">
<readHost host="hostS2" url="192.168.65.129:3306" user="mycat" password="mycat" />
</writeHost>
<!-- 第二对主从 -->
<writeHost host="hostM2" url="192.168.65.130:3306" user="mycat" password="mycat">
<readHost host="hostS2" url="192.168.65.131:3306" user="mycat" password="mycat" />
</writeHost>
- 缺陷
可能会有IO延迟问题。
MyCat管理MySQL集群负载均衡策略
| 标签 | 属性1 | 属性2 | 属性3 |
|---|---|---|---|
dataHost |
balance-负载均衡策略 |
writeType-写策略 |
switchType-选择策略,涉及到读写分离问题,可以解决 IO 延迟问题 |
| 属性 | 取值 | 作用 |
|---|---|---|
| balance | balance=0 | 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上 |
| balance | balance=1(常用) | 全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡 |
| balance | balance=2 | 所有读操作都随机的在 writeHost、 readhost 上分发 |
| balance | balance=3 | 所有读请求随机的分发到 writeHost 对应的 readhost 执行,writerHost 不负担读压力 |
| 属性 | 取值 | 作用 |
|---|---|---|
| writeType | writeType = 0 | 所有写操作发送到配置的第一个 writeHost,第一个挂了切换到还生存的第二个 writeHost,重新启动后按切换后的为准,切换记录在配置文件中:conf/dnindex.properties (datanode index) |
| writeType | writeType = 1 | 所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐 |
| 属性 | 取值 | 作用 |
|---|---|---|
| switchType | switchType = -1 | 表示不自动切换 |
| switchType | switchType = 1 | 默认值,表示自动切换 |
| switchType | switchType = 2 | 基于 MySQL 主从同步的状态决定是否切换读写主机,心跳语句为 show slave status。 当心跳监测获取的数据发现了 IO 的延迟,则读操作自动定位到 writeHost 中。如果心跳监测获取的数据没有 IO 延迟,则读操作自动定位到 readHost 中。建议为不同的表格定位不同的dataHost 节点 |
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="2" slaveThreshold="100">
<heartbeat>show slave status</heartbeat>
<writeHost host="hostM1" url="ip:3306" user="mysql用户名" password="mysql密码">
</writeHost>
<writeHost host="hostS1" url="ip:3306" user="mysql用户名" password="mysql密码" />
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="2" slaveThreshold="100">
<heartbeat>show slave status</heartbeat>
<writeHost host="hostM2" url="ip:3306" user="mysql用户名" password="mysql密码">
</writeHost>
<writeHost host="hostS2" url="ip:3306" user="mysql用户名" password="mysql密码" />
</dataHost>
| 策略 | 实现 |
|---|---|
| 策略1 | balance=“1”,writeType=“0”,switchType=“1” |
| 策略2 | balance=“1”,writeType=“0”,switchType=“2” |
- 配置好后,可以通过
show slave status \G查看相关信息
智能推荐
2024最新计算机毕业设计选题大全-程序员宅基地
文章浏览阅读1.6k次,点赞12次,收藏7次。大家好!大四的同学们毕业设计即将开始了,你们做好准备了吗?学长给大家精心整理了最新的计算机毕业设计选题,希望能为你们提供帮助。如果在选题过程中有任何疑问,都可以随时问我,我会尽力帮助大家。在选择毕业设计选题时,有几个要点需要考虑。首先,选题应与计算机专业密切相关,并且符合当前行业的发展趋势。选择与专业紧密结合的选题,可以使你们更好地运用所学知识,并为未来的职业发展奠定基础。要考虑选题的实际可行性和创新性。选题应具备一定的实践意义和应用前景,能够解决实际问题或改善现有技术。
dcn网络与公网_电信运营商DCN网络的演变与规划方法(The evolution and plan method of DCN)...-程序员宅基地
文章浏览阅读3.4k次。摘要:随着电信业务的发展和电信企业经营方式的转变,DCN网络的定位发生了重大的演变。本文基于这种变化,重点讨论DCN网络的规划方法和运维管理方法。Digest: With the development oftelecommunication bussiness and the change of management of telecomcarrier , DCN’s role will cha..._电信dcn
动手深度学习矩阵求导_向量变元是什么-程序员宅基地
文章浏览阅读442次。深度学习一部分矩阵求导知识的搬运总结_向量变元是什么
月薪已炒到15w?真心建议大家冲一冲数据新兴领域,人才缺口极大!-程序员宅基地
文章浏览阅读8次。近期,裁员的公司越来越多今天想和大家聊聊职场人的新出路。作为席卷全球的新概念ESG已然成为当前各个行业关注的最热风口目前,国内官方发布了一项ESG新证书含金量五颗星、中文ESG证书、完整ESG考试体系、名师主讲...而ESG又是与人力资源直接相关甚至在行业圈内成为大佬们的热门话题...当前行业下行,裁员的公司也越来越多大家还是冲一冲这个新兴领域01 ESG为什么重要?在双碳的大背景下,ESG已然成...
对比传统运营模式,为什么越拉越多的企业选择上云?_系统上云的前后对比-程序员宅基地
文章浏览阅读356次。云计算快速渗透到众多的行业,使中小企业受益于技术变革。最近微软SMB的一项研究发现,到今年年底,78%的中小企业将以某种方式使用云。企业希望投入少、收益高,来取得更大的发展机会。云计算将中小企业信息化的成本大幅降低,它们不必再建本地互联网基础设施,节省时间和资金,降低了企业经营风险。科技创新已成时代的潮流,中小企业上云是创新前提。云平台稳定、安全、便捷的IT环境,提升企业经营效率的同时,也为企业..._系统上云的前后对比
esxi网卡直通后虚拟机无网_esxi虚拟机无法联网-程序员宅基地
文章浏览阅读899次。出现选网卡的时候无法选中,这里应该是一个bug。3.保存退出,重启虚拟机即可。1.先随便选择一个网卡。2.勾先取消再重新勾选。_esxi虚拟机无法联网
随便推点
在LaTeX中使用.bib文件统一管理参考文献_egbib-程序员宅基地
文章浏览阅读913次。在LaTeX中,可在.tex文件的同一级目录下创建egbib.bib文件,所有的参考文件信息可以统一写在egbib.bib文件中,然后在.tex文件的\end{document}前加入如下几行代码:{\small\bibliographystyle{IEEEtran}\bibliography{egbib}}即可在文章中用~\cite{}宏命令便捷的插入文内引用,且文章的Reference部分会自动排序、编号。..._egbib
Unity Shader - Predefined Shader preprocessor macros 着色器预处理宏-程序员宅基地
文章浏览阅读950次。目录:Unity Shader - 知识点目录(先占位,后续持续更新)原文:Predefined Shader preprocessor macros版本:2019.1Predefined Shader preprocessor macros着色器预处理宏Unity 编译 shader programs 期间的一些预处理宏。(本篇的宏介绍随便看看就好,要想深入了解,还是直接看Unity...
大数据平台,从“治理”数据谈起-程序员宅基地
文章浏览阅读195次。本文目录:一、大数据时代还需要数据治理吗?二、如何面向用户开展大数据治理?三、面向用户的自服务大数据治理架构四、总结一、大数据时代还需要数据治理吗?数据平台发展过程中随处可见的数据问题大数据不是凭空而来,1981年第一个数据仓库诞生,到现在已经有了近40年的历史,相对数据仓库来说我还是个年轻人。而国内企业数据平台的建设大概从90年代末就开始了,从第一代架构出现到..._数据治理从0搭建
大学抢课python脚本_用彪悍的Python写了一个自动选课的脚本 | 学步园-程序员宅基地
文章浏览阅读2.2k次,点赞4次,收藏12次。高手请一笑而过。物理实验课别人已经做过3、4个了,自己一个还没做呢。不是咱不想做,而是咱不想起那么早,并且仅有的一次起得早,但是哈工大的服务器竟然超负荷,不停刷新还是不行,不禁感慨这才是真正的“万马争过独木桥“啊!服务器不给力啊……好了,废话少说。其实,我的想法很简单。写一个三重循环,不停地提交,直到所有的数据都accepted。其中最关键的是提交最后一个页面,因为提交用户名和密码后不需要再访问其..._哈尔滨工业大学抢课脚本
english_html_study english html-程序员宅基地
文章浏览阅读4.9k次。一些别人收集的英文站点 http://www.lifeinchina.cn (nice) http://www.huaren.us/ (nice) http://www.hindu.com (okay) http://www.italki.com www.talkdatalk.com (transfer)http://www.en8848.com.cn/yingyu/index._study english html
Cortex-M3双堆栈MSP和PSP_stm32 msp psp-程序员宅基地
文章浏览阅读5.5k次,点赞19次,收藏78次。什么是栈?在谈M3堆栈之前我们先回忆一下数据结构中的栈。栈是一种先进后出的数据结构(类似于枪支的弹夹,先放入的子弹最后打出,后放入的子弹先打出)。M3内核的堆栈也不例外,也是先进后出的。栈的作用?局部变量内存的开销,函数的调用都离不开栈。了解了栈的概念和基本作用后我们来看M3的双堆栈栈cortex-M3内核使用了双堆栈,即MSP和PSP,这极大的方便了OS的设计。MSP的含义是Main..._stm32 msp psp