Python 机器学习大作业 用knn算法对adult数据集进行50w年薪收入预测_knn算法大作业-程序员宅基地
数据分析与机器学习——收入分类
摘 要
今天,人工智能AI已经融入了人类的生活,基本上在生活中能接触到的领域,都有人工智能的身影。而说起人工智能就必定会想到机器学习ML,它以某种方式几乎影响了每个行业,而机器学习最重要的就是算法和数据。本次期末项目基于“人口普查”数据集,对居民收入是否超过50K进行了预测,用的是K临近算法,中间涉及数据填充、删除,K值的选取,‘找邻居’等步骤。完成这个项目后,对K临近算法有了更深刻的理解,也对机器学习更有兴趣了。
关键词:机器学习;Knn算法;预测收入;准确度
一、问题介绍
1.1 题目要求
基于adult数据集,利用它的age、workclass、…、native_country等13个特征属性预测收入是否超过50k,是一个二分类问题。
1.2 数据集介绍
该数据从美国1994年人口普查数据库中抽取而来,因此也称作“人口普查收入”数据集,共包含48842条记录,年收入大于50k的占比23.93%,年收入小于50k$的占比76.07%。数据集已经划分为训练数据32561条和测试数据16281条。属性变量包括年龄、工种、学历、职业等14类重要信息,其中有8类属于类别离散型变量,另外6类属于数值连续型变量。
14个属性变量具体介绍如下:

图片原地址:https://blog.csdn.net/hohaizx/article/details/79084774
二、算法概述
2.1 k近邻算法简介
预测一个数据的类别的时候,通过这个数据的K个最近的邻居来判断该数据类别;也就是‘物以类聚,人以群分’,‘近朱者赤,近墨者黑’的思想。
2.2 计算距离
距离度量有很多种类型,主要包含欧式距离,曼哈顿距离,闵可夫斯基距离等。一般来说用欧式距离来计算,本次实验使用曼哈顿距离

2.3 K值选取
K值就是找待测点的K个最近邻居,统计它们的类别,然后投票计算,预测结果跟着多的那一方。可以想到,K值一般为奇数,就是为了使投票双方结果不会相同。
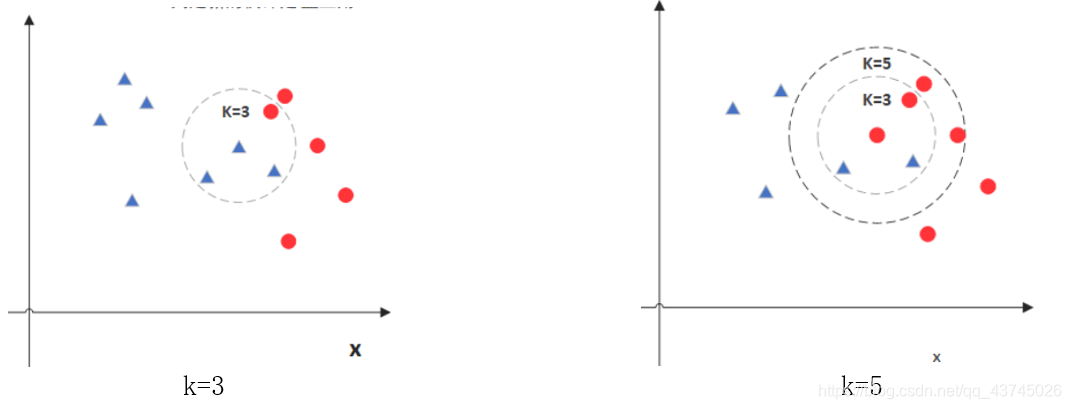
从上图可见k为3时,周围蓝色多,中心点为蓝色;k=5时,周围红色多,中心点为红色。故k值会影响准确度,一般来说会直接选3或5,后面步骤会遍历3,5,7,9,11…,分别查看精确度,选出最佳k值
2.4 算法优点
(1)简单易用,相比其他算法,KNN算是比较简洁明了的算法。
(2)模型训练时间快。
(3)预测效果好。
(4)对异常值不敏感
2.5 算法缺点
(1)对内存要求较高,因为该算法存储了所有训练数据
(2)预测阶段可能很慢
(3)对不相关的功能和数据规模敏感
三、实验过程和结果分析
3.1导入数据集
使用csv方式直接读取文件,并获取对应的dataFrame,因为adult.csv中的第一行是无用数据,所以需要跳过(采用skiprows),names给每一列加上属性名。此时测试数据集也用train.csv,因为有income结果,方便后面统计正确率。最后输出结果时改成test.csv
3.2 查看数据
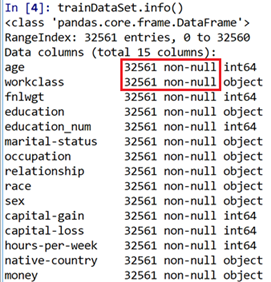
首先查看数据信息,发现全是not-null。居然没有缺失值,但我们知道数据中有缺失值
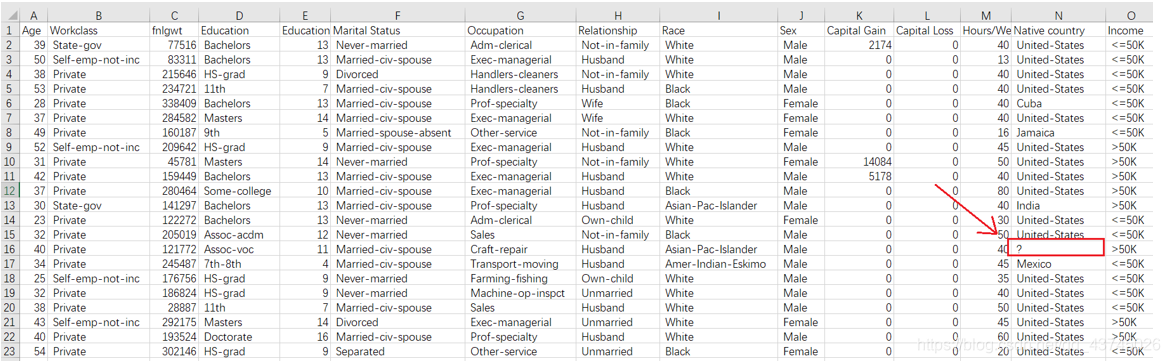
在excel中打开文件,大致浏览一下,发现缺失值用**’ ?’空格问号**这一字符串填充,造成了没有缺失值的假象
然后使用lambda公式查看是否有’ ?’这样的缺失值
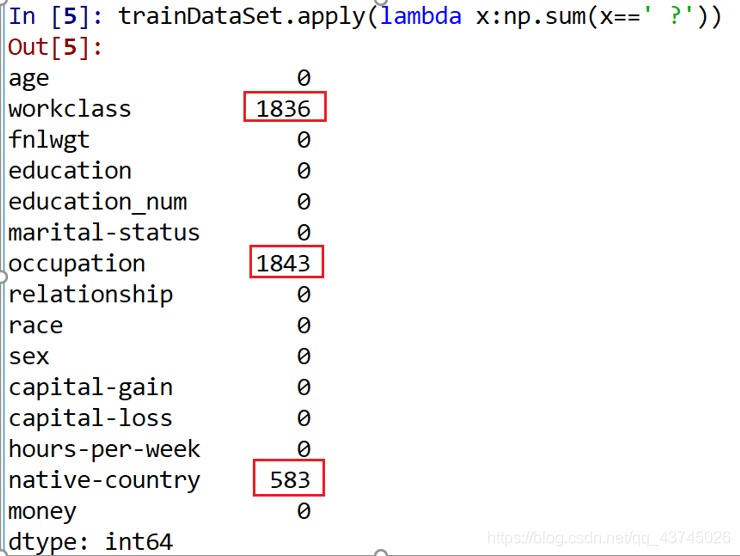
从上面的结果可以发现,居民的收入数据集中有3个变量存在数值缺失,分别是居民的工作类型workclass(离散型)缺1836、职业occupation(离散型)缺1843和国籍native-country(离散型)缺583。缺失值的存在一般都会影响分析或建模的结果,所以需要对缺失数值做相应的处理。
3.3 缺失值填充
缺失值的处理一般采用三种方法:
- 删除法:缺失的数据较少时适用;
- 替换法:用常数替换缺失变量,离散变量用众数,数值变量用均值或中位数;
- 插补法:用未缺失的预测该缺失变量。
这里我采用第三种插补法。
而插补法又分为:填充固定值,均值,中位数,众数,上一条,下一条等等;
根据上述方法,三个缺失变量都为离散型,可用众数替换。pandas中fillna()方法,
能够使用指定的方法填充NA/NaN值。而先要将 ?字符转化为NAN,然后填充众数
3.4 查看数值型变量
首先,需要知道每个变量的基本统计值,如均值、中位数、众数等,只有了解了所需处理的数据特征,才能做到“心中有数”。
查看代码:
print(dataSet.describe())
结果:
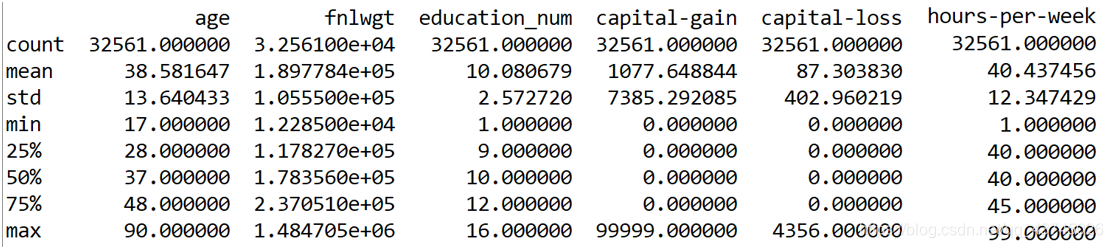
上面的结果描述了有关数值型变量的简单统计值,包括非缺失观测的个数(count)、平均值(mean)、标准差(std)、最小值(min)、下四分位数(25%)、中位数(50%)、上四分位数(75%)和最大值(max)
3.5 查看离散型变量
查看代码:
income.describe(include= ['object'])
结果:

上面为离散变量的统计值,包含每个变量非缺失观测的数量(count)、不同离散值的个数(unique)、出现频次最高的离散值(top)和最高频次数(freq)。以教育education变量为例,一共有16种不同的教育水平;3万多居民中,高中毕业HS-grad的学历是出现最多的,一共有10 501名。
3.6 删去冗余数据
在adult数据集中,关于受教育程度的有两个变量,一个是education(教育水平),另一个是education-num(受教育时长),而且这两个变量的值都是一一对应的,只不过一个是字符型,另一个是对应的数值型。如果将这两个变量都包含在模型中的话,就会产生信息的冗余;fnlwgt变量代表的是一种序号,其对收入水平的高低并没有实际意义。同理删去capital-gain,capital-loss这两列属性。故为了避免冗余信息和无意义变量对模型的影响,共删除education,fnlwgt,capital-gain,capital-loss这四列属性。
#删去不相关属性
dataSet.drop('fnlwgt',axis=1, inplace=True) #fnlgwt
dataSet.drop('education',axis=1, inplace=True) #Education
dataSet.drop('capital-gain',axis=1, inplace=True) #Capital Gain
dataSet.drop('capital-loss',axis=1, inplace=True) #Capital Loss
打开所有列,查看前十行数据
不加第一句话,只能显示一部分列,中间是……,加了就能看到所有列
pd.set_option('display.max_columns', None)
print(dataSet.head(10))
结果:还剩11列数据
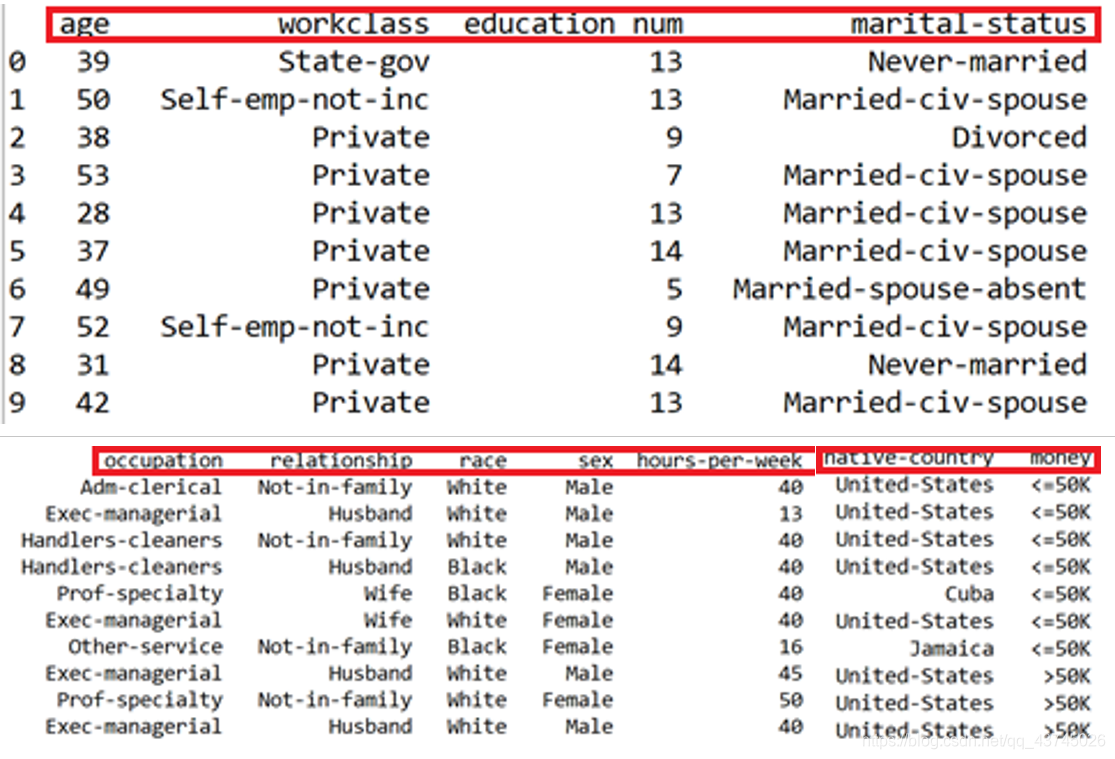
这里有很多地方参考这篇博客 https://blog.csdn.net/qq_38249388/article/details/105211405
3.7 离散变量重编码
此时数据已经处理的差不多了,但由于数据集中有很多离散型变量,这些变量的值为字符
串,不利于建模。因此,需要先对这些变量进行重新编码。
编码的方法有很多种:
(1)将字符型的值转换为整数型的值
(2)哑变量处理(0-1变量)
(3)One-Hot热编码(类似于哑变量)
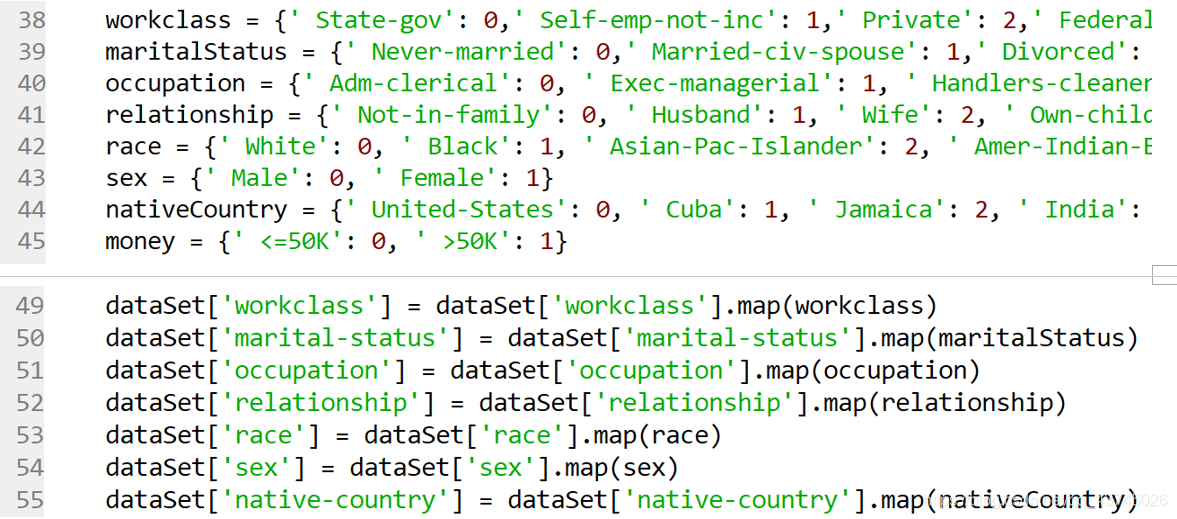
这里采用字符转数值的方法对离散型变量进行重编码
以workclass为例,查看一下workclass的几个值

结果如下:

用数字替换映射文本:
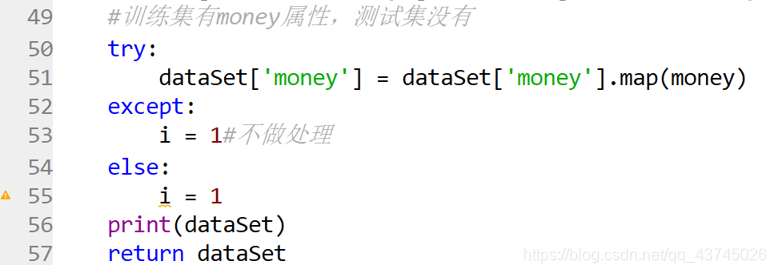
这里income也就是money属性需要特殊对待,因为train有,test没有;使用try…catch错误处理语句,i=1就是不做任何处理,防止编译器报错
这里是可以不用写那么多的,只是我当时写都写了,懒得删了,可以使用映射的方法:
for col in X.columns[1::]: #循环修改数据类型的数组
u = X[col].unique() #将当前循环的数组加上索引
def convert(x):
return np.argwhere(u == x)[0,0] #返回值是u中的数据等于x的索引数组,[0,0]截取索引数组的第一排第一个
X[col] = X[col].map(convert) #索引替换映射数据
结果:连续化完成,现在的就是‘干净’的数据集
train训练集(前10条)
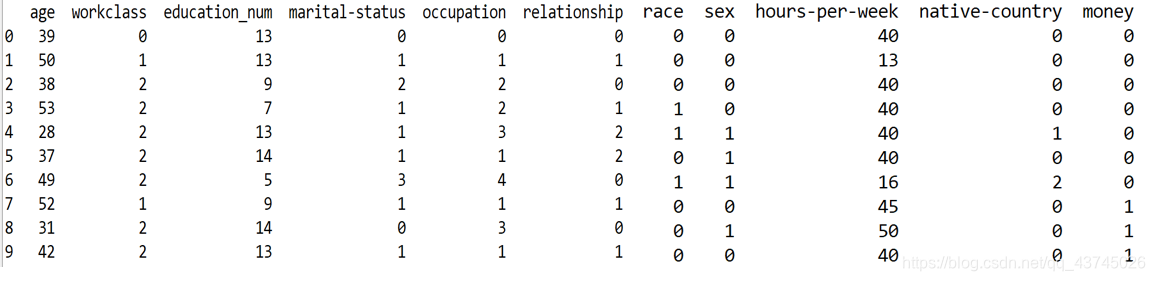
test测试集
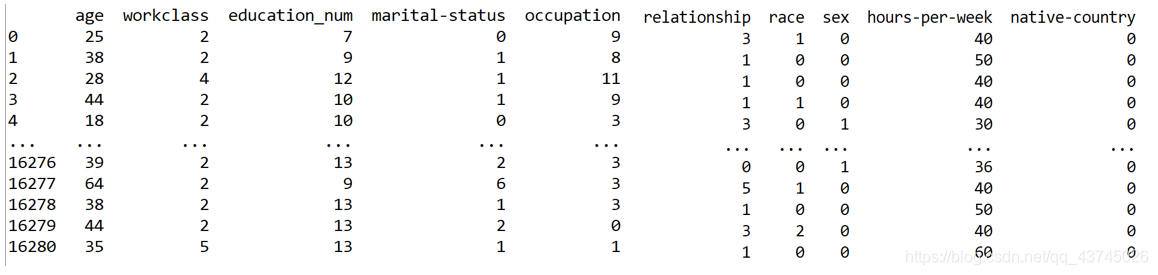
3.8 Knn距离计算
这里使用的是曼哈顿距离,求测试数据和训练数据每个属性之差的绝对值,然后全部加起来,得到这两个数据的距离。
def findDistance(oneTest,oneTrain):
#print(oneTest.shape[0])
distance = 0
for i in range(oneTest.shape[0]-1):
distance += (abs(oneTest[i] - oneTrain[i]))
return distance
3.9 实现Knn算法
首先初始化两个列表为0,用来存储最近的k+2个邻居下标和到它们的距离;
1000和-1是为了方便第一次比较
for i in range(testNum):
print('i=',i)
#初始化
neighbors = np.zeros(k + 2)
distances = np.zeros(k + 2)
for j in range(k+2):
distances[j]=1000
distances[0]=-1
接下来对每个距离排序,如果比当前最小的k个小,就不停往前,直到停止时,记录当前数据的距离和下标
for j in range(trainNum):
#print(testDataSet.loc[i],trainDataSet.loc[j])
distance=findDistance(testDataSet.loc[i],trainDataSet.loc[j])
#print(distance)
index=k
while True:
if distance < distances[index] :
neighbors[index+1] = neighbors[index]
distances[index+1] = distances[index]
index-=1
else:
#Insert
distances[index+1] = distance
neighbors[index+1] = j
break
然后便是投票阶段,也就是看当前最近的k个邻居数据的收入income类型,将出现多的一方的类型当作预测值,放进predicts这个列表里面
#投票
labels=[]
for j in range(k):
index = int(neighbors[j+1])
labels.append(int(trainDataSet.loc[index]['money']))#获得邻居的money值
#print(int(trainDataSet.loc[index]['money']))
counts = []
for label in labels:
counts.append(int(labels.count(label)))
#print('counts=',counts)
predicts[i]=labels[np.argmax(counts)]
最后计算正确率,这一步就是把已知的正确答案和predicts里的预测值做对比,正确数除总数得到正确率
wrong=0
for i in range(testNum):
#print(predicts[i],testDataSet.loc[i]['money'])
if predicts[i]!=testDataSet.loc[i]['money']:
wrong+=1
return (testNum-wrong)/testNum
结果:

3.10 选择K值
刚刚选择的是k为5的情况,这里可以看看k为其它值时精确度怎么样
k为[1,29]内的奇数
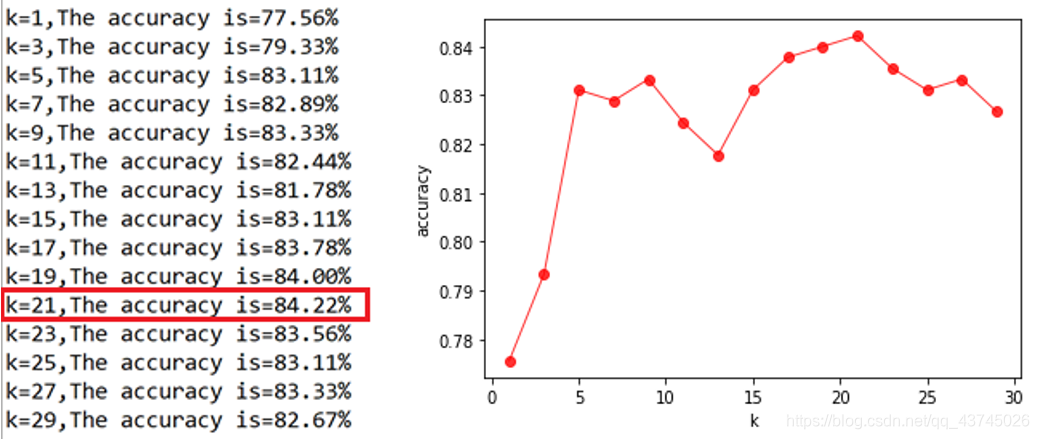
结果:
看的出准确度随着k值变化而变化,当k=21时,精度最高为0.8422;而k在27以后准确度逐渐减小。这是符合预期的, k值的减小意味着整体模型变得复杂,容易发生过拟合;k值很大时,容易欠拟合。
3.11 写入csv文件
本题要求为预测测试集的收入income,并写入学号.csv内,而上面所说的计算准确率是基于有income属性的训练集3:1划分结果。所以为了得到最后结果,前面部分代码有修改,最后要将得到的predict列表转化为dataframe对象,然后用to_csv函数写入csv文件即可
data = pd.DataFrame(predicts, columns=['Income'])
data.to_csv('./新的文件.csv',index=False)
预测结果:
四、代码
4.1 方法一
自己写knn函数
# -*- coding: utf-8 -*-
"""
Created on Thu Jun 18 09:04:24 2020
@author: DZY
"""
import pandas as pd
import numpy as np
def loadData():
#读文件跳过第一行,为方便计算,可以取前450行数据
trainDataSet = pd.read_csv('./train.csv', header=None, skiprows = 1, names=["age","workclass","fnlwgt","education","education_num","marital-status","occupation","relationship","race","sex","capital-gain","capital-loss","hours-per-week","native-country","money"]).head(450)
testDataSet = pd.read_csv('./test.csv', header=None, skiprows = 1, names=["age","workclass","fnlwgt","education","education_num","marital-status","occupation","relationship","race","sex","capital-gain","capital-loss","hours-per-week","native-country"])
return trainDataSet,testDataSet
def dataCleaning(dataSet):
#删去不相关属性
dataSet.drop('fnlwgt',axis=1, inplace=True) #fnlgwt
dataSet.drop('education',axis=1, inplace=True) #Education
dataSet.drop('capital-gain',axis=1, inplace=True) #Capital Gain
dataSet.drop('capital-loss',axis=1, inplace=True) #Capital Loss
dataSet = dataSet.replace(' ?', np.nan)
# 缺失值处理,采用众数替换法(mode()方法取众数)
dataSet.fillna(value={
'workclass':dataSet['workclass'].mode()[0], #Workclass
'occupation':dataSet['occupation'].mode()[0], #Occupation
'native-country':dataSet['native-country'].mode()[0]}, #Native country
inplace = True)
#print(dataSet.describe())
#print(dataSet.describe(include= ['object']))
#离散数据连续化
workclass = {
' State-gov': 0,' Self-emp-not-inc': 1,' Private': 2,' Federal-gov': 3,' Local-gov': 4,' Self-emp-inc': 5, ' Without-pay': 6, ' Never-worked': 7}
maritalStatus = {
' Never-married': 0,' Married-civ-spouse': 1,' Divorced': 2,' Married-spouse-absent': 3, ' Separated': 4, ' Married-AF-spouse': 5, ' Widowed': 6}
occupation = {
' Adm-clerical': 0, ' Exec-managerial': 1, ' Handlers-cleaners': 2, ' Prof-specialty': 3, ' Other-service': 4, ' Sales': 5, ' Craft-repair': 6, ' Transport-moving': 7, ' Farming-fishing': 8, ' Machine-op-inspct': 9, ' Tech-support': 10, ' Protective-serv': 11,' Armed-Forces': 12, ' Priv-house-serv': 13}
relationship = {
' Not-in-family': 0, ' Husband': 1, ' Wife': 2, ' Own-child': 3, ' Unmarried': 4, ' Other-relative': 5}
race = {
' White': 0, ' Black': 1, ' Asian-Pac-Islander': 2, ' Amer-Indian-Eskimo': 3, ' Other': 4}
sex = {
' Male': 0, ' Female': 1}
nativeCountry = {
' United-States': 0, ' Cuba': 1, ' Jamaica': 2, ' India': 3, ' Mexico': 4, ' South': 5, ' Puerto-Rico': 6, ' Honduras': 7, ' England': 8, ' Canada': 9, ' Germany': 10, ' Iran': 11, ' Philippines': 12, ' Italy': 13, ' Poland': 14, ' Columbia': 15, ' Cambodia': 16, ' Thailand': 17, ' Ecuador': 18, ' Laos': 19, ' Taiwan': 20, ' Haiti': 21, ' Portugal': 22, ' Dominican-Republic': 23, ' El-Salvador': 24, ' France': 25, ' Guatemala': 26, ' China': 27, ' Japan': 28, ' Yugoslavia': 29, ' Peru': 30, ' Outlying-US(Guam-USVI-etc)': 31, ' Scotland': 32, ' Trinadad&Tobago': 33, ' Greece': 34, ' Nicaragua': 35, ' Vietnam': 36, ' Hong': 37, ' Ireland': 38, ' Hungary': 39, ' Holand-Netherlands': 40}
money = {
' <=50K': 0, ' >50K': 1}
dataSet['workclass'] = dataSet['workclass'].map(workclass)
dataSet['marital-status'] = dataSet['marital-status'].map(maritalStatus)
dataSet['occupation'] = dataSet['occupation'].map(occupation)
dataSet['relationship'] = dataSet['relationship'].map(relationship)
dataSet['race'] = dataSet['race'].map(race)
dataSet['sex'] = dataSet['sex'].map(sex)
dataSet['native-country'] = dataSet['native-country'].map(nativeCountry)
#训练集有money属性,测试集没有
try:
dataSet['money'] = dataSet['money'].map(money)
except:
i = 1#不做处理
else:
i = 1
#pd.set_option('display.max_columns', None)
#print(dataSet.head(10))
return dataSet
def findDistance(oneTest,oneTrain):
#print(oneTest.shape[0])
distance = 0
for i in range(oneTest.shape[0]-1):
distance += (abs(oneTest[i] - oneTrain[i]))
return distance
def knnTest(trainDataSet,testDataSet, k):
#print(trainDataSet.loc[0])
#print(testDataSet)
testNum = testDataSet.shape[0]#测试数据行数
trainNum = trainDataSet.shape[0]#训练数据行数
predicts = np.zeros((testNum))
#print(testDataSet.shape[1])
for i in range(testNum):
print('i=',i)
#初始化
neighbors = np.zeros(k + 2)
distances = np.zeros(k + 2)
for j in range(k+2):
distances[j]=1000
distances[0]=-1
for j in range(trainNum):
#print(testDataSet.loc[i],trainDataSet.loc[j])
distance=findDistance(testDataSet.loc[i],trainDataSet.loc[j])
#print(distance)
index=k
while True:
if distance < distances[index] :
neighbors[index+1] = neighbors[index]
distances[index+1] = distances[index]
index-=1
else:
#Insert
distances[index+1] = distance
neighbors[index+1] = j
break
#投票
labels=[]
for j in range(k):
index = int(neighbors[j+1])
labels.append(int(trainDataSet.loc[index]['money']))#获得邻居的money值
#print(int(trainDataSet.loc[index]['money']))
counts = []
for label in labels:
counts.append(int(labels.count(label)))
#print('counts=',counts)
predicts[i]=labels[np.argmax(counts)]
#print("The prediction[{}] = {}".format(i,predicts[i]))
data = pd.DataFrame(predicts, columns=['Income'])
data.to_csv('./201731061220.csv',index=False)
'''
#基于train的精确率
wrong=0
for i in range(testNum):
#print(predicts[i],testDataSet.loc[i]['money'])
if predicts[i]!=testDataSet.loc[i]['money']:
wrong+=1
return (testNum-wrong)/testNum
'''
def main():
trainDataSet,testDataSet = loadData()
print('训练数据集加载完成,{}行{}列\n'.format(trainDataSet.shape[0],trainDataSet.shape[1]));
print('测试数据集加载完成,{}行{}列\n'.format(testDataSet.shape[0],testDataSet.shape[1]));
trainDataSet = dataCleaning(trainDataSet)
print('训练数据集清理连续化完成,{}行{}列\n'.format(trainDataSet.shape[0],trainDataSet.shape[1]));
testDataSet = dataCleaning(testDataSet)
print('测试数据集清理连续化完成,{}行{}列\n'.format(testDataSet.shape[0],testDataSet.shape[1]));
#print(trainDataSet)
k=11
knnTest(trainDataSet, testDataSet, k)
#accuracy = knnTest(trainDataSet, testDataSet, k)
#print("The accuracy is={:.2f}%".format(accuracy*100))
main()
4.2 方法二
调用sklearn里的库函数
写的很潦草
#导入需要得包
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
salary = pd.read_csv('train.csv') #读取文件
#salary.shape
#salary.head() #数据预处理
salary2 = pd.read_csv('test.csv') #读取文件
X = salary #选取所有行
X2 = salary2 #选取所有行
for col in X.columns[1::]: #循环修改数据类型的数组
u = X[col].unique() #将当前循环的数组加上索引
def convert(x):
return np.argwhere(u == x)[0,0] #返回值是u中的数据等于x的索引数组,[0,0]截取索引数组的第一排第一个
X[col] = X[col].map(convert) #索引替换映射数据
for col in X2.columns[1::]: #循环修改数据类型的数组
u = X2[col].unique() #将当前循环的数组加上索引
def convert(x):
return np.argwhere(u == x)[0,0] #返回值是u中的数据等于x的索引数组,[0,0]截取索引数组的第一排第一个
X2[col] = X2[col].map(convert) #索引替换映射数据
X = salary.iloc[:,[0,1,3,5,6,8,9,-2,-3]] #选取所有行
X2 = salary2.iloc[:,[0,1,3,5,6,8,9,-2,-3]] #选取所有行
y = salary['Income']
for num in range(15):
k = 2*num+1
Knn = KNeighborsClassifier(n_neighbors=k)
Knn.fit(X,y)
print("k={},score={}",format(k,Knn.score(X,y)))
'''
plist = np.zeros(X2.shape[0])
j=0
#print(Knn.predict(X2))
for i in Knn.predict(X2):
plist[j] = i
j+=1
data = pd.DataFrame(plist, columns=['Income'])
data.to_csv('./目标文件.csv',index=False)
#print(result.mean())
'''
五、参考
最后加上参考的博客地址:
https://blog.csdn.net/Dorisi_H_n_q/article/details/82595188?utm_source=blogxgwz4
https://blog.csdn.net/jingyi130705008/article/details/82670011
https://blog.csdn.net/worldeert/article/details/103465303
https://blog.csdn.net/qq_38249388/article/details/105211405
https://blog.csdn.net/zhw864680355/article/details/102582788
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象