C++初阶:初识C++-程序员宅基地
1. 前言:C++ 与 C语言
- 相对于C语言面向过程的编程语言,C++在继承C的基础上进行发展与补足,为C语言添加了面向对象方面的内容(类与对象,继承多态,模板)
- 面向对象与面向过程:如果将编程比作洗衣服,那么面向过程的编程就好比我们自己一步一步的进行衣物浆洗(接水,放入洗衣液,浸泡,手搓),而面向对象编程就是洗衣机,我们只用将衣服放入,倒水倒洗衣液,具体的细节我们无需关系。总的来说,C关心得是过程,而C++只用关注对象与对象及其他们的关系。
2. C++对于C语言语法的完善与补充
2.1 命名冲突与命名空间
在C语言的学习中,我们了解,在一个变量或函数的声明周期内,与它同一作用域中,不能创建与其同名的变量或函数。这在很多时候导致了不便,对于代码的可读性与灵活性也存在一定影响,而在C++中引入了命名空间这一新语法很好的解决了这一问题,接下来就让我们进行这方面的学习。
2.1.1 命名空间的定义
- 定义方式:关键字namespace后加空间名
- 作用:
<1>正常变量的作用范围是它声明周期内的整个作用域,而命名空间就像是一个院子,将其空间内变量函数等封装了起来。
<2> 正常检索下不会进入命名空间内,只有使用时指定才会在进入其中检索。
<3> 命名空间内的变量,函数,自定义类型等与命名空间外的同名变量,函数,自定义类型不冲突。
定义方式:
namespace space1//[自定义名称]
{
//变量。。。。
int a;
//函数。。。。
int Add(int num1, int num2)
{
}
//自定义类型。。。。
typedef struct Node
{
}Node;
}
补充1:命名空间可以嵌套使用
namespace space1
{
namespace space2
{
int a;
}
}
补充2:不同文件中可有相同名称的命名空间,而这些同名命名空间在编译时会被合并
2.1.2 调用方式
调用方式1:(指定命名空间)
//调用命名空间内的资源
//变量
space::a = 1;
//函数
int ret = space::Add(1, 2);
//自定义类型
space1::Node node1;
//嵌套命名空间的调用方式
space1::space2::a = 1;
调用方式2:(打开命名空间)
//打开命名空间,打开命名空间后可以不使用后缀访问其内资源
using namespace space;
using namespace space1::space2;
调用方式3:(将单个命名空间中的资源引入)
//引入space1空间中的a
using space1::a;
a = 2;
using space1::space2::a;
补充:
C++库中有自己的命名空间,比如std,是C++头文件
<iostream>中的命名空间,其内部有一些很重要的资源。示例如下:
- 注:C++中的头文件不带
.h,以与C中的头文件做区分
using namespace std;
//cout为继承ostream类型的对象
// << 为流插入操作符
//endl为行结束标志
cout << "hello world" << endl;
- 语句意义:向cout中插入信息,将信息插入到显示器上
- <<流插入操作符
2.3 补充:流的概念
- 因为有各种各样的硬件设备,它们之间的组成与结构不同,为了方便各个硬件间的协同工作,我们引入流的概念。
- 将电脑中的信息理解为一股有方向的流,我们不关心信息交换的具体方式,只理解为有一条条信息组成的"河流"从源头设备流入向目标设备。
- 流插入操作符的意义即为,将指定的信息插入到指定设备中去。(cout标准输出对象:控制台,cin标准输入对象:键盘)
int num1 = 0;
//从键盘上读取数据将其存放入变量num中
cin >> num1;
int num2, num3;
//可连续读取
//回车或空格间隔
cin >> num2 >> num3;
//可连续插入
cout << num1 << ' ' << num2 << ' ' << num3 << endl;
2.4 缺省参数
2.4.1 缺省参数的使用
- 我们在创建定义函数时,往往要给函数定义参数。带有参数的函数,当我们调用时传参不可缺漏。
- 而在C++中对于函数参数添加了新的内容,使得这一定则有了新的补充,方便了我们的日常使用
- 在C语言程序中,函数参数的传递是不可省略的,否则必将报错 ,C++中在传参中有时可以省略,具体规则如下:
全缺省:
函数参数都赋予缺省值,方式如下:
void Print(int a = 0, int b = 0, int c = 0)
{
cout << a << ' ' << b << ' ' << c << endl;
}
半缺省:
函数参数赋予部分缺省值,方式如下:
- 注1:缺省值的赋予不可中断不连续
- 注2:半缺省的赋予,必须从尾部开始
- 注3:从头开始半缺省无法判断调用函数时的值赋予哪个参数
//示例1:(正确)
void Print(int a, int b = 0, int c = 0)
{
cout << a << ' ' << b << ' ' << c << endl;
}
//示例2:(错误)
void Print(int a = 0, int b, int c = 0)
{
cout << a << ' ' << b << ' ' << c << endl;
}
//示例3:(错误)
void Print(int a = 0, int b = 0, int c)
{
cout << a << ' ' << b << ' ' << c << endl;
}
2.5 函数重载
2.5.1 什么是函数重载
编程习惯上,我们常常说 “名称即含义”,因此,函数名也会简单概括函数的功能,使得代码的可读性大大提高。
//示例1:
void swap1(int* num1, int* num2)
{
int tmp = *num1;
*num1 = *num2;
*num2 = tmp;
}
void swap2(char* str1, char* str2)
{
char tmp = *str1;
*str1 = *str2;
*str2 = tmp;
}
//示例2:
int Add1(int num1, int num2)
{
return num1 + num2;
}
int Add1(int num1, int num2, int num3)
{
return num1 + num2 + num3;
}
可是,随着代码量的提高,很多函数都会具有类似的功能,可是细节不同,参数类型不同此时,此时函数的命名就会变得非常繁琐与麻烦,无法很好的在场景中应用。因为存在这一问题,C++添加了函数重载的内容。
函数重载与编译器的函数名修饰规则:
在C/C++中,一份程序想要运行要经历预处理,编译,汇编,链接,这几个阶段。当程序编译运行时,检测到调用的函数,在调用处是没有函数定义的,所以就要进行项目内各个文件的链接合并,在符号表中查询函数名并调用相应的函数地址。
- C语言中符号并表中只存有简单的函数名,当存在同名函数时编译器无法识别。
- C++中会对编译链接时会对函数名进行,下面简述Linux操作系统下g++的函数名修饰规则,[_Z] + [函数名长度] + [函数名首字母] + [函数类型首字母]
2.5.2 函数重载的使用
两个同名函数之间是否构成重载,只与参数类型,参数个数有关,与返回值无关。
参数类型不同(构成):
//构成重载
void swap(int* left, int* right)
{
int tmp = *left;
*left = *right;
*right = tmp;
}
void swap(char* left, char* right)
{
char tmp = *left;
*left = *right;
*right = tmp;
}
//调用方式:
int a = 10;
int b = 20;
swap(&a, &b);
char c1 = 'a';
char c2 = 'b';
swap(&c1, &c2);
参数个数不同(构成):
int Add(int nums1, int nums2)
{
return nums1 + nums2;
}
int Add(int nums1, int nums2, int nums3)
{
return nums1 + nums2 + nums3;
}
//调用方式:
cout << Add(10, 20) << endl;
cout << Add(10, 20, 30) << endl;
参数数量与类型相同,返回值不同(不构成):
int f()
{
return 10;
}
void f()
{
cout << 10 << endl;
}
2.5.3 特殊情况:函数重载与缺省参数的冲突
//记作Print1
void Print(int a = 0)
{
cout << a << endl;
}
//记作Print2
void Print()
{
cout << 0 << endl
}
上述情况下,Print1的缺省调用与Print2的调用具有相同的语句,编译无法处理会进行报错,在编写代码的过程中,不要进行如上操作。
2.6 引用与指针
- 在C语言的学习中,我们知道在对函数进行传参时,我们正常情况下向函数传递的只是参数的拷贝,如果我们想要在函数内对参数进行操作更改,我传参时就需要给函数传递参数的指针,再于函数内部对参数地址解引用,然后再对参数本身进行操作。
- 在C++中,我们有了可以简化这一过程的新增语法操作,“引用”,接下来就让我们对其进行学习。
2.6.1 什么是引用
引用,我们可以从语法层面将其简单理解为,对一个已经存在的元素"取别名",取名后新的名称也同样代表着原本的那个元素,对别名操作同样会对参数造成影响,两者的区别只有名称上的不同。
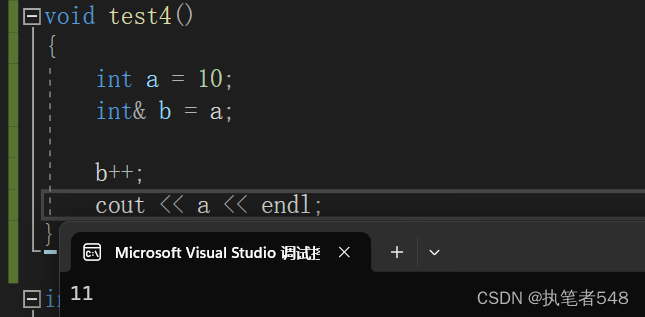
int a = 10;
int& b = a;
b++;
cout << a << endl;
2.6.2 引用的使用方式
定义方式:[参数类型]& 变量别名 = 变量
- 注:引用必须进行初始化,否则会发生报错
- 注:一个变量可以取多个别名,即被多次引用
- 注:引用一个变量后,就无法再引用其他的变量
int a = 10;
//定义方式
int& b = a;
//报错,必须初始化
int& c;
2.6.3 const常引用
- C语言中,我们学习过const修饰变量,const修饰的变量具有常属性,而具有常属性的变量无法被修改。
- 在引用中,const修饰的变量我们正常情况下无法正常引用,需要对引用也进行const修饰才能正常引用,此种别名也具有常性不能被修改。
//常变量
const int a = 10;
//常引用
const int& b = a;
- 因为常引用只读不改的特性,所以它也可以直接引用常量
const int& b = 10;
- 常引用可以引用变量,但引用不可以引用常变量(权限可以缩小不能放大)
- 跨类型的常饮用同样可能会导致数据精度的丢失
double c = 3.14;
//精度丢失
const int& d = c;
//3
2.6.4 引用的应用场景
- 作参数
void swap(int& num1, int& num2)
{
int tmp = num1;
num1 = num2;
num2 = tmp;
}
- 做返回值
int& Add(int num1, int num2)
{
static int sum = 0;
sum = num1 + num2;
return sum;
}
- 引用做返回值,源变量的销毁(源变量的声明周期仅为函数体内,随着函数调用结束,变量销毁)
int& Add(int num1, int num2)
{
int sum = num1 + num2;
return sum;
}
//err
int ret = Add(10, 20);
2.6.5 补充
- 值返回比引用返回的效率低,值返回会在返回过程中创建一个中间变量,而引用则是直接返回数据本身。
- 引用与指针的区别:
<1> 在概念上,引用是定义了一个变量的别名,而指针是存储了变量的地址
<2> 在初始化时,引用必须进行初始化,而指针可以不初始化
<3> 指针存在NULL指针,而引用不存在空引用
<4> 引用在初始化引用一个目标后,后续不可再更改引用其他目标,而指针可以
<5> 引用的大小是引用目标本身的大小,而指针大小只会是4/8字节
<6> 引用加1是对本身元素加1,而指针则是加一步(指针步长由指针类型决定)
<7> 使用上,指针需要解引用才能对指向对象进行操作,引用我们则是可以直接进行操作(具体细节由编译器执行)
<8> 有多级指针,但没有多级引用
<9> 引用比指针更加安全
2.7 内联函数
2.7.1 什么是内联函数
- 在编写程序时,我们经常会进行函数的定义,将需要的功能模块化从而优化代码的结构,提高代码的可读性。
- 可是有些时候,编写的函数非常短小,为此再专门开辟栈帧来调用,当此函数被多次反复调用时反而会很大程度上影响程序的效率,因此我们引入内联函数。
内联函数的定义方式:在函数名前加上关键字inline
inline int Add(int num1, int num2)
{
return num1 + num2;
}
2.7.2 内联函数的调用机制
- 内联函数不会再去额外开辟栈帧,而是将函数体内的语句在调用处直接展开,然后依次执行
- 我们对于函数的inline声明,编译器并不一定会进行执行,此行为只相当于我们给编译器提建议,具体如何操作由编译器考量(当函数过于复杂,语句数量超过一定限度,如:75)
- 内联函数可能会导致目标文件内代码量的膨胀
- 内联函数不建议使用定义与声明分离的操作,因为内联函数会在条用处直接展开,声明展开后就无法找打定义处的函数地址
2.7.3 C++与宏
- 在C语言中我们学习过宏,它的存在可以让增强了代码的复用性,提升了代码效率。可同时他也有着不可忽视的缺点,它的替换机制为我们的调试代码很大的不方便,维护起来及其不方便,同时也没有类型检查使得安全下降,针对他的两个使用场景C++中有了其的上位选择(有同时优点的同时,规避了缺点)
- 使用场景:
<1> 短小函数 :内联函数
<2> 替换常量:枚举
枚举示例:
//宏
//#define day 0
//枚举可调试
enum Day
{
Mon,
Tues,
Feb,
Thu,
Fir,
Sat,
Sun
}
Day day = Tue;
cout << "today is " << day << endl;
2.8 关键字auto
- 使用场景:auto可以自动推导处变量的类型,当参数类型过长,或复杂易错时我们可以用auto关键字代替。
- 可搭配指针与引用使用,具体如下:
int i = 10;
auto a = &i;
auto* b = &i;
auto& c = i;
//得到变量的类型
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
*a = 20;
*b = 30;
c = 40;
- auto不可作为函数参数,无法得出函数的参数类型
//err
int Add(auto num1, auto num2)
{
return num1 + num2;
}
- auto无法直接定义数组
//err
auto arr[] = {
1,2,3,4,5,6};
2.9 范围for
在C语言的逻辑for语句中,我们想要利用其进行数组的遍历时,必须要创建一个中间变量作为下标来进行元素的遍历,而范围for只需要给定需遍历数组即可,语法上更为方便简洁,具体如下:
int arr[] = {
1,2,3,4,5,6};
//普通for循环
int i = 0;
for(i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
cout << arr[i] << endl;
}
//范围for
for(auto e : arr)
{
cout << e << endl;
}
- 范围for中的变量只是临时拷贝,对其的更改无法直接影响数组,需要指定变量类型为引用才可对值进行更改
for(auto e : arr)
{
e *= 2;
}
for(auto e : arr)
{
cout << e << endl;
}
for(auto& e : arr)
{
e *= 2;
}
- 在后续的类与对象中我们会了解到其与迭代器的关系(实为傻瓜式的替换)
2.10 指针空值nullptr
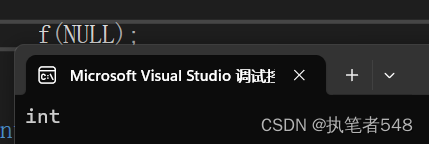
在C语言中,我们查看源文件会发现NULL是0的宏替换,因为此种定义方式,其可能会在使用中造成如下的一些错误。
void f(int* p)
{
cout << "int*" << endl;
}
void f(int p)
{
cout << "int" << endl;
}
f(NULL);
运行结果:
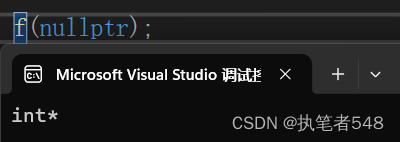
在C++中,对这一缺漏有了补足,C++中新增空指针为nullptr,相当于(void)0*。
智能推荐
TRACCAR支持的设备列表-程序员宅基地
文章浏览阅读1.7k次。GT06_traccar支持的设备
基于连接的每IP限速实现_netfilter限速-程序员宅基地
文章浏览阅读9.7k次,点赞2次,收藏2次。在《修改netfilter的limit模块实现基于单个ip的流量监控》中,介绍了一种方式实现针对一个网段每个IP地址的流量控制,如果细化到流,那个就叫做针对每个流的流量控制,我们知道,一个IP地址可以和很多流相关联,针对流的流控限制的不是主机,而是主机上的一个连接,它的约束要比针对IP地址的流控更加小。 然而如何来实现这个呢?实际上在Linux中,几乎所有的流控都可以用TC工具配置出_netfilter限速
Java 获取linux根目录下的文件夹_java获取指定文件夹下的所有文件名-程序员宅基地
文章浏览阅读1.8k次。原文链接:java获取指定文件夹下的所有文件名_tomorrowzm的专栏-程序员宅基地_java查询指定文件夹下的所有文件输出文件名 site:blog.csdn.netblog.csdn.netpackage 这里我们主要使用的是listFiles函数来得到file文件夹下的所有文件,包括文件夹。然后通过File类的isFile和isDirectory来区分,如果是文件,就输出对应的信息,如..._java读取linux服务器下指定目录下的文件名称
Update批量更新(高性能、动态化)_批量update-程序员宅基地
文章浏览阅读7.6k次,点赞7次,收藏20次。文章目录前言一、环境开发环境测试环境二、灵光乍现MyBatis-Plus源码2.初见真正的批量更新语法三、开工基础类搭建SysUser(表sys_user实体类)Stash(拼接SQL服务,内部类)TableCacheDTO(数据表信息存储)TableCache(表信息缓存)MySQL拼接常量类缓存数据库表信息1. 继承AbstractMethod2. 自定义sql注入器3. 自定义注入器生效事务工具类制作SQL工具类SQL执行类四、测试100条测试数据1千条测试数据1万条测试数据10万条测试数据五、弊端总_批量update
PID优化系列之目标值平滑(斜坡函数梯形图+完整SCL代码)_控制斜坡pid-程序员宅基地
文章浏览阅读2.2k次,点赞4次,收藏6次。作为PID系列专题,这些文章,我都会给出PLC梯形图的源代码和SCL代码方便大家对比学习,文章中的错误和不严谨之处,也请大家指正。1、专题1:设定值响应问题 2、PLC的梯形图代码,这部分我们可以做成功能块,启用PID运算时,我们可以对设定值进行线性化平滑处理,也可以不处理。......_控制斜坡pid
编程实现36进制和10进制之间的相互转换_36进制转换10进制-程序员宅基地
文章浏览阅读1w次,点赞3次,收藏4次。36进制转换成10进制的方法,以R9和10Y为例R9就是 27 * 36^1 + 9*36^0 = 98110Y 就是 1* 36^2 + 0 * 36^1 + 34*36^0 =133010进制转换成36进制的方法,以1079和52360为例(1079/36^0) % 36 = 35(1079/36^1) % 36 = 29(1079/36^2) 所以_36进制转换10进制
随便推点
微平均的服务拓扑管理与可视化-程序员宅基地
文章浏览阅读350次,点赞9次,收藏9次。1.背景介绍微平均(Microservices)是一种软件架构风格,它将应用程序拆分成小的、独立运行的服务。这些服务通过轻量级的通信协议(如HTTP和gRPC)相互协同,以实现整个应用程序的功能。微服务架构的优势在于它的可扩展性、灵活性和容错性。然而,随着微服务数量的增加,服务之间的依赖关系也变得复杂,这导致了服务拓扑管理和可视化的问题。在这篇文章中,我们将讨论如何使用微平均的服务拓扑管理..._微服务 拓扑 可视化
无法安全地连接到此页面,这可能是因为该站点使用过期的或不安全的 TLS 安全设置._无法安全地连接到此页面 这可能是因为该站点使用过期的或不安全的 tls 安全设置。-程序员宅基地
文章浏览阅读2w次,点赞3次,收藏15次。问题描述:网页中的链接打不开,页面显示如标题所述,原因可能是因为我之前打开了很多内容,后来电脑没电直接关机了,导致出错。解决方法:1、按住win+R打开运行,输入inetcpl.cpl,点击确定,打开internet属性。2、打开在internet属性后,点击【安全】选卡,再点击【安全】页面中的“Internet”,选择“自定义级别”。如下图所示:3、在中间偏下位置找到“显示混合模式”,将其改为“启用”。如下图所示:4、再在Internet属性窗口中点击【高级】选项卡,找到“使用TLS 1_无法安全地连接到此页面 这可能是因为该站点使用过期的或不安全的 tls 安全设置。
B/S與C/S_当今世界开发模式技术架构的两大主流技术?-程序员宅基地
文章浏览阅读1.3k次。一、什么是C/S和B/S 要想对“C/S”和“B/S”技术发展变化有所了解,首先必须搞清楚三个问题。 第一、什么是C/S结构。 C/S (Client/Server)结构,即大家熟知的客户机和服务器结构。它是软件系统体系结构,通过它可以充分利用两端硬件环境的优势,将任务合理分配到Client端和Server端来实现,降低了系统的通讯开销。目前大多数应用软件系统都是Client/Server形式的两_当今世界开发模式技术架构的两大主流技术?
MDK配置jlink仿真器步骤_mdk5如何定义swd-程序员宅基地
文章浏览阅读5.5k次。MDK配置jlink仿真器步骤:1.如下图2.设置为SW模式3.选择处理器的flash大小4.设置utilities5.查看是否是SW模式6.查看Flash大小重新编译程序download就好了..._mdk5如何定义swd
渗透测试17---Metasploit (MSF) 部署与功能_msf war包部署 渗透-程序员宅基地
文章浏览阅读7.5k次。MetasploitMetasploit Framework简称MSF(ruby语言开发的)实验环境准备Metasploit的使用第一次使用要进行数据库的初始化msfdb init用的时候就:msfconsole也可以:msfdb run (就等于msfdb init 和msfconsole)Metasploit指令search ms17_010 会列出许多模..._msf war包部署 渗透
python实战:将cookies添加到requests.session中实现淘宝的模拟登录_浏览器登录淘宝后使用其cookie再用requests登录-程序员宅基地
文章浏览阅读1.4w次,点赞11次,收藏89次。将cookies添加到requests.session中实现淘宝的模拟登录声明:本文仅供学习用,旨在分享我们知道现在爬取淘宝商品是必须要登录的,在没有登录的情况下搜索商品也会自动重定向到登录页面。之前学着用selenium,pyppeteer等自动化框架模拟登录淘宝,但是无论怎么滑动滑块验证都失败。然而就像星爷《新喜剧之王》中所说得:只要不投降就是成功,同时为了安慰自己受伤的小心灵,决定用co..._浏览器登录淘宝后使用其cookie再用requests登录