使用python3爬取网页,利用aria2下载电影,Jellyfin自动更新最新电影_jellyfin自动播放下一集-程序员宅基地
前言:在我搭建好Jellyfin软件后,因为只能播放本地视频,就想能不能播放网络上的电影,可以每天自动下载并更新,这样就不用我手工下载好,再上传到NAS中播放。或许有更好的方法,那就是直接用电影播放源,那就有个问题了,没有那个视频网愿意给播放源,所以还是自己慢慢下载后再播放吧。个人对于python语言也是小白,在网络上寻找大神的脚本稍加修改得到的。
如果需要搭建jellyfin,请看我之前的博客-家庭影院Jellyfin搭建,linux网页视频播放器。
环境:centos7
工具:python3、jellyfin、shell脚本、aria2
1、安装python3
默认安装好centos7系统后,自带有python2.7.5的版本,所以需要安装python3的版本。2.7.5的版本不能删除,否则centos系统会崩溃。请从官网下载python3.8版本。
关于python2升级至python3,会有一些问题,但都能解决,请参考以下资料:
2)pbzip2: error while loading shared libraries: libbz2.so.1.0: cannot open shared object file
3)centos7安装python3及其配置pip(建立软连接)
2、编辑python脚本
命名脚本为movie.py,将以下复制到py脚本保存,执行python3 movie.py。查看爬取结果,是否生成文件。
脚本不是我编写的,是借鉴大神,然后根据电影天堂现在的地址和信息,做了一些改动,获取下载电影地址
# encoding: gbk
# 我们用到的库
import requests
import bs4
import re
import pandas as pd
def get_data(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = 'gbk'
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !")
def parse_data(html):
'''
功能:提取 html 页面信息中的关键信息,并整合一个数组并返回
参数:html 根据 url 获取到的网页内容
返回:存储有 html 中提取出的关键信息的数组
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
info = []
# 获取电影列表
tbList = bsobj.find_all('table', attrs = {'class': 'tbspan'})
# 对电影列表中的每一部电影单独处理
for item in tbList:
movie = []
link = item.b.find_all('a')[0]
# 获取电影的名称
name = link.string
# 获取详情页面的 url
url = 'https://www.dytt8.net' + link["href"]
# 将数据存放到电影信息列表里
movie.append(name)
movie.append(url)
try:
# 访问电影的详情页面,查找电影下载的磁力链接
temp = bs4.BeautifulSoup(get_data(url),'html.parser')
tbody = temp.find_all('a')
print(tbody)
#^magnet.*?fannouce
# 下载链接有多个(也可能没有),这里将所有链接都放进来
for i in tbody:
lines = i.get("href")
if "magnet" in lines:
#download = lines.a.text
#print(lines)
movie.append(lines)
print(movie)
# 将此电影的信息加入到电影列表中
info.append(movie)
except Exception as e:
print(e)
return info
def save_data(data):
'''
功能:将 data 中的信息输出到文件中/或数据库中。
参数:data 将要保存的数据
'''
filename = 'C:/Users/Administrator/Desktop/movie.txt'
dataframe = pd.DataFrame(data)
dataframe.to_csv(filename, mode='a', index=False, sep=';', header=False)
def main():
# 循环爬取多页数据
#for page in range(1, 114):
# print('正在爬取:第' + str(page) + '页......')
# 根据之前分析的 URL 的组成结构,构造新的 url
#if page == 1:
# index = 'index'
#else:
# index = 'index_' + str(page)
# url = 'https://www.dy2018.com/2/'+ index +'.html'
#url='https://www.dy2018.com/2/index.html'
url='https://www.dytt8.net/html/gndy/dyzz/index.html'
# 依次调用网络请求函数,网页解析函数,数据存储函数,爬取并保存该页数据
html = get_data(url)
movies = parse_data(html)
save_data(movies)
#print('第' + str(page) + '页完成!')
if __name__ == '__main__':
print('爬虫启动成功!')
main()
print('爬虫执行完毕!')
3、安装aria2
安装教程,请访问我的博客第一条,安装nextcloud里面有详细的安装aria2教程
4、编写aria2下载的shell脚本
#!/bin/bash
cd /downloads
count=0
#/root/shell/movie.txt,这个地址是movie.py执行后生成的下载地址,请根据你实际的地址填写
route=/root/shell/movie.txt
name=(`awk -F ";" '{print $1}' $route | cut -d '《' -f2|cut -d '》' -f1 | cut -d '/' -f1`)
addr=(`awk -F ";" '{print $3}' $route`)
nr=`awk '{print NR}' $route | tail -n1`
prop=`awk -F ";" '{print $3}' $route | cut -d '&' -f2 | awk -F "." '{print $8}'`
for ((i=0; i<=nr; i++))
do
let count++
echo "正在下载第$count个电影,《${name[$i]}》"
sudo -u www nohup aria2c -o "${name[$i]}.${prop[$i]}" "${addr[$i]}" &
echo "第$count个电影完成创建,转后台下载中"
sleep 2
done
rm -rf /root/shell/movie.txt5、测试
执行脚本,请注意先后顺序,先执行python3 movie.py。等待爬取下载电影地址完成后,执行sh movie.sh。
6、增加自动任务,添加到crontab
crontab -e中增加以下信息,获取这个方法不完善,但仍在改进
#每2天运行python脚本,获取电影天堂下载地址
20 1 */2 * * python3 /root/shell/movie.py
#每2天运行一次aria2下载电影
30 1 */2 * * sh /root/shell/movie.sh
7、使用jellyfin添加媒体库
在这里,把媒体库的自动扫描调整为每个小时都扫描一次,这样可以很快的增加到媒体库。
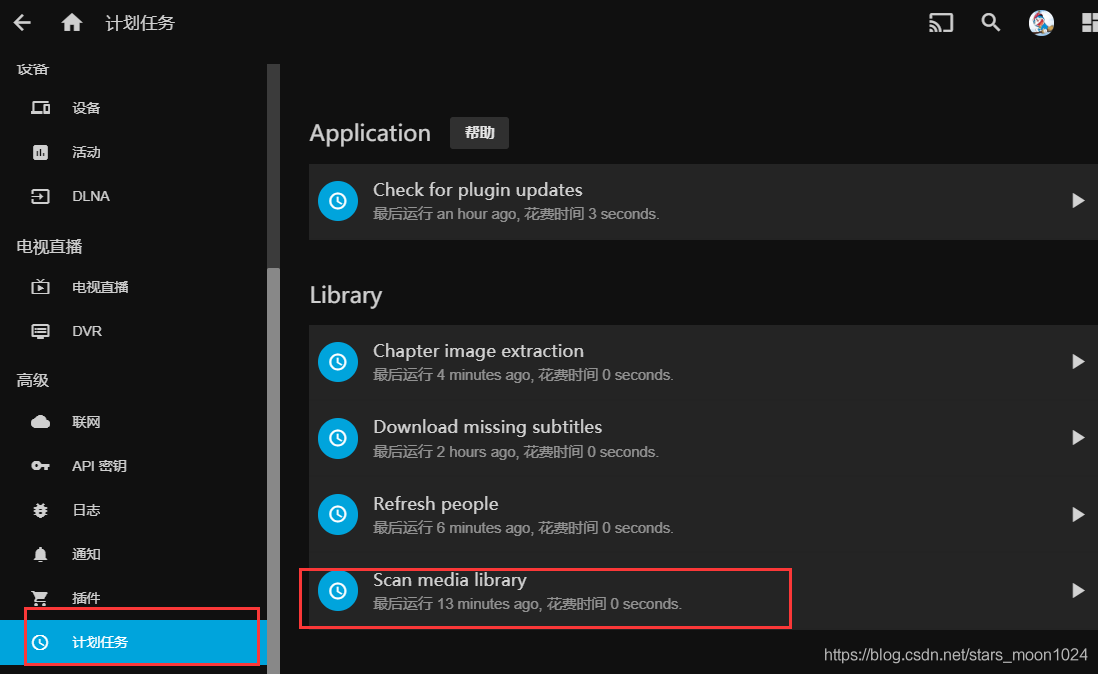
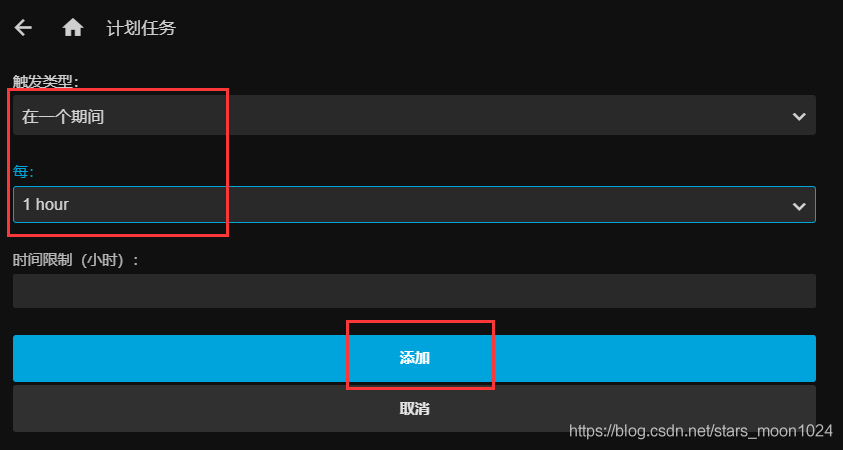
至此,已经完成了自动从电影网下载电影,并自动扫描到媒体库,就可以不用管了,每2天自动更新。写的脚本只下载了详情页的第一页,如果想下载很多页,请把主方法中的循环打开调整数字就可以了
智能推荐
JavaScript学习笔记_curry函数未定义-程序员宅基地
文章浏览阅读343次。五种原始的变量类型1.Undefined--未定义类型 例:var v;2.String -- ' '或" "3.Boolean4.Number5.Null--空类型 例: var v=null;Number中:NaN -- not a number非数本身是一个数字,但是它和任何数字都不相等,代表非数,它和自己都不相等判断是不是NaN不能用=_curry函数未定义
兑换码编码方案实践_优惠券编码规则-程序员宅基地
文章浏览阅读1.2w次,点赞2次,收藏17次。兑换码编码设计当前各个业务系统,只要涉及到产品销售,就离不开大大小小的运营活动需求,其中最普遍的就是兑换码需求,无论是线下活动或者是线上活动,都能起到良好的宣传效果。兑换码:由一系列字符组成,每一个兑换码对应系统中的一组信息,可以是优惠信息(优惠券),也可以是相关奖品信息。在实际的运营活动中,要求兑换码是唯一的,每一个兑换码对应一个优惠信息,而且需求量往往比较大(实际上的需求只有预期_优惠券编码规则
c语言周林答案,C语言程序设计实训教程教学课件作者周林ch04结构化程序设计课件.ppt...-程序员宅基地
文章浏览阅读45次。C语言程序设计实训教程教学课件作者周林ch04结构化程序设计课件.ppt* * 4.1 选择结构程序设计 4.2 循环结构程序设计 4.3 辅助控制语句 第四章 结构化程序设计 4.1 选择结构程序设计 在现实生活中,需要进行判断和选择的情况是很多的: 如果你在家,我去拜访你 如果考试不及格,要补考 如果遇到红灯,要停车等待 第四章 结构化程序设计 在现实生活中,需要进行判断和选择的情况..._在现实生活中遇到过条件判断的问
幻数使用说明_ioctl-number.txt幻数说明-程序员宅基地
文章浏览阅读999次。幻数使用说明 在驱动程序中实现的ioctl函数体内,实际上是有一个switch{case}结构,每一个case对应一个命令码,做出一些相应的操作。怎么实现这些操作,这是每一个程序员自己的事情。 因为设备都是特定的,这里也没法说。关键在于怎样组织命令码,因为在ioctl中命令码是唯一联系用户程序命令和驱动程序支持的途径 。 命令码的组织是有一些讲究的,因为我们一定要做到命令和设备是一一对应的,利_ioctl-number.txt幻数说明
ORB-SLAM3 + VScode:检测到 #include 错误。请更新 includePath。已为此翻译单元禁用波浪曲线_orb-slam3 include <system.h> 报错-程序员宅基地
文章浏览阅读399次。键盘按下“Shift+Ctrl+p” 输入: C++Configurations,选择JSON界面做如下改动:1.首先把 “/usr/include”,放在最前2.查看C++路径,终端输入gcc -v -E -x c++ - /usr/include/c++/5 /usr/include/x86_64-linux-gnu/c++/5 /usr/include/c++/5/backward /usr/lib/gcc/x86_64-linux-gnu/5/include /usr/local/_orb-slam3 include 报错
「Sqlserver」数据分析师有理由爱Sqlserver之十-Sqlserver自动化篇-程序员宅基地
文章浏览阅读129次。本系列的最后一篇,因未有精力写更多的入门教程,上篇已经抛出书单,有兴趣的朋友可阅读好书来成长,此系列主讲有理由爱Sqlserver的论证性文章,希望读者们看完后,可自行做出判断,Sqlserver是否真的合适自己,目的已达成。渴望自动化及使用场景笔者所最能接触到的群体为Excel、PowerBI用户群体,在Excel中,我们知道可以使用VBA、VSTO来给Excel带来自动化操作..._sqlsever 数据分析
随便推点
智慧校园智慧教育大数据平台(教育大脑)项目建设方案PPT_高校智慧大脑-程序员宅基地
文章浏览阅读294次,点赞6次,收藏4次。教育智脑)建立学校的全连接中台,对学校运营过程中的数据进行处理和标准化管理,挖掘数据的价值。能:一、原先孤立的系统聚合到一个统一的平台,实现单点登录,统一身份认证,方便管理;三、数据共享,盘活了教育大数据资源,通过对外提供数。的方式构建教育的通用服务能力平台,支撑教育核心服务能力的沉淀和共享。物联网将学校的各要素(人、机、料、法、环、测)全面互联,数据实时。智慧校园解决方案,赋能教学、管理和服务升级,智慧教育体系,该数据平台具有以下几大功。教育大数据平台底座:教育智脑。教育大数据平台,以中国联通。_高校智慧大脑
编程5大算法总结--概念加实例_算法概念实例-程序员宅基地
文章浏览阅读9.5k次,点赞2次,收藏27次。分治法,动态规划法,贪心算法这三者之间有类似之处,比如都需要将问题划分为一个个子问题,然后通过解决这些子问题来解决最终问题。但其实这三者之间的区别还是蛮大的。贪心是则可看成是链式结构回溯和分支界限为穷举式的搜索,其思想的差异是深度优先和广度优先一:分治算法一、基本概念在计算机科学中,分治法是一种很重要的算法。字面上的解释是“分而治之”,就是把一个复杂的问题分成两_算法概念实例
随笔—醒悟篇之考研调剂_考研调剂抑郁-程序员宅基地
文章浏览阅读5.6k次。考研篇emmmmm,这是我随笔篇章的第二更,原本计划是在中秋放假期间写好的,但是放假的时候被安排写一下单例模式,做了俩机试题目,还刷了下PAT的东西,emmmmm,最主要的还是因为我浪的很开心,没空出时间来写写东西。 距离我考研结束已经快两年了,距离今年的考研还有90天左右。 趁着这个机会回忆一下青春,这一篇会写的比较有趣,好玩,纯粹是为了记录一下当年考研中发生的有趣的事。 首先介绍..._考研调剂抑郁
SpringMVC_class org.springframework.web.filter.characterenco-程序员宅基地
文章浏览阅读438次。SpringMVC文章目录SpringMVC1、SpringMVC简介1.1 什么是MVC1.2 什么是SpringMVC1.3 SpringMVC的特点2、HelloWorld2.1 开发环境2.2 创建maven工程a>添加web模块b>打包方式:warc>引入依赖2.3 配置web.xml2.4 创建请求控制器2.5 创建SpringMVC的配置文件2.6 测试Helloworld2.7 总结3、@RequestMapping注解3.1 @RequestMapping注解的功能3._class org.springframework.web.filter.characterencodingfilter is not a jakart
gdb: Don‘t know how to run. Try “help target“._don't know how to run. try "help target".-程序员宅基地
文章浏览阅读4.9k次。gdb 远程调试的一个问题:Don't know how to run. Try "help target".它在抱怨不知道怎么跑,目标是什么. 你需要为它指定target remote 或target extended-remote例如:target extended-remote 192.168.1.136:1234指明target 是某IP的某端口完整示例如下:targ..._don't know how to run. try "help target".
c语言程序设计教程 郭浩志,C语言程序设计教程答案杨路明郭浩志-程序员宅基地
文章浏览阅读85次。习题 11、算法描述主要是用两种基本方法:第一是自然语言描述,第二是使用专用工具进行算法描述2、c 语言程序的结构如下:1、c 语言程序由函数组成,每个程序必须具有一个 main 函数作为程序的主控函数。2、“/*“与“*/“之间的内容构成 c 语言程序的注释部分。3、用预处理命令#include 可以包含有关文件的信息。4、大小写字母在 c 语言中是有区别的。5、除 main 函数和标准库函数以..._c语言语法0x1e