rails 模块化
Like many startups of its age, Airtasker was born as a Ruby on Rails monolith which got a bit bloated.
与当时的许多初创公司一样,Airtasker诞生于Ruby on Rails的整体架构,但有点肿。
We believe a modern API architecture consists of a set of loosely-coupled, highly-cohesive bounded contexts. A bounded context is a term from Domain-Driven Design (DDD) which refers to the logical boundaries surrounding a single subdomain of a business.
我们认为,现代的API体系结构由一组松耦合,高度内聚的有界上下文组成 。 有界上下文是域驱动设计(DDD)中的一个术语,指围绕业务的单个子域的逻辑边界。
At Airtasker, greenfield bounded contexts usually come in the form of a Kotlin microservice. But what about the core functionality we already have? When you do the cost-benefits analysis of rewriting a large chunk of code that already exists and works, it’s easy to conclude that you shouldn’t rewrite.
在Airtasker,绿地界定的上下文通常以Kotlin微服务的形式出现。 但是我们已经拥有的核心功能呢? 在进行成本效益分析以重写大量已经存在并且可以正常工作的代码时,很容易得出结论,您不应该重写 。
Fortunately, a bounded context doesn’t necessarily imply a separate service. In fact, there are lots of benefits to having a modular monolith. Like many before us, we’ve made use of Rails engines for modularity within our Rails app.
幸运的是,有限的上下文不一定意味着单独的服务。 实际上,拥有模块化整体结构有很多好处。 像我们之前的许多人一样,我们在Rails应用程序中利用了Rails引擎来实现模块化。
Unfortunately, adding and enforcing boundaries between Rails Engines is a DIY job. In this blog, I’ll walk you through:
不幸的是,在Rails Engines之间添加和加强边界是一项DIY工作。 在此博客中,我将指导您完成:
1. Where we started. The status quo of our Rails Monolith and our use of engines and adaptors.
1.我们从哪里开始 。 我们的Rails Monolith的现状以及我们对引擎和适配器的使用。
2. Why we want to enforce boundaries. Our motivation for trying to enforce strict and explicit boundaries between our Rails Engines.
2.为什么我们要强制执行边界。 我们试图在我们的Rails引擎之间建立严格和明确的界限的动机。
3. How we enforced boundaries. A walk-through of the methods we tried and the benefits and downsides of each.
3.我们如何实施边界。 逐步介绍了我们尝试的方法以及每种方法的优点和缺点。
1.我们从哪里开始 (1. Where we started)
有界上下文 (Bounded Contexts)
Our monolith is partially, but not yet entirely, carved up into a set of bounded contexts.
我们的整体作品被部分地(但不是全部)刻在一组有限的上下文中。
As we mentioned in the intro, a bounded context is a term borrowed from DDD that refers to a single business subdomain with well-defined boundaries. Since this can be difficult to conceptualise, let’s walk through an example.
正如我们在简介中所提到的,有界上下文是从DDD借来的术语,指的是具有明确边界的单个业务子域。 由于很难将其概念化,因此让我们来看一个示例。
Imagine you’re an engineer at the hotshot cat grooming startup Luxuricat that just made it through Series C funding. Your business and codebase have grown so large that it’s no longer feasible to have a unified domain model. Each product team seems to have their own concerns and vocabulary for their respective parts of the app. Yet they’re also constantly treading on each other’s toes.
想象一下,您是热门猫美容公司Luxuricat的工程师 刚刚通过C轮融资实现了目标。 您的业务和代码库已经变得如此庞大,以至于拥有统一的域模型不再可行。 每个产品团队似乎对应用程序的各个部分都有自己的关注点和词汇。 然而,他们也不断地踩着对方的脚趾。
Since you want to keep up momentum, you decide to try and modularise your codebase along the lines of the different subdomains of your business. To identify those subdomains, you chat with domain subject-matter experts.
由于您想保持发展势头,因此您决定尝试按照业务的不同子域的方式对代码库进行模块化。 要标识这些子域,请与域主题专家聊天。
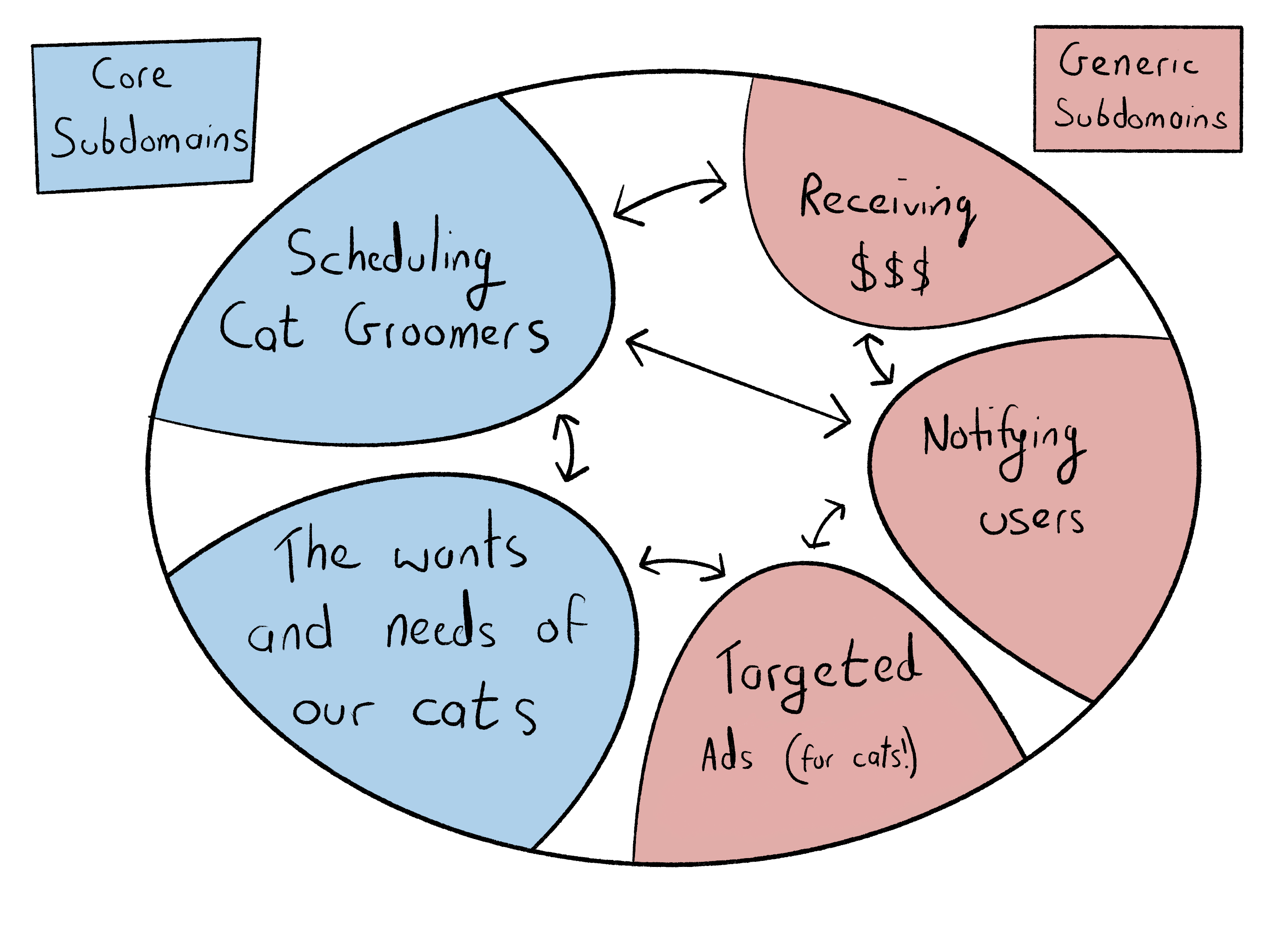
You find a few obvious subdomains that aren’t special to Luxuricat, like Notifications and Payments. These Generic Subdomains are prime candidates to be extracted. You’re also surprised to find out that the needs of your pampered cats have little to do with the rostering of cat groomers. This seems like two different Core Subdomains of your business, so you decide to create two more bounded contexts: CatClients and CatGroomers.
您会发现一些明显的子域 对Luxuricat来说不是特别的 例如通知和付款 。 这些通用子域是要提取的主要候选对象。 您还会惊讶地发现,宠爱的猫的需求与猫美容师的花名册无关。 这似乎是业务的两个不同的核心子域 ,因此您决定创建另外两个有界的上下文: CatClients和CatGroomers。
Each of these bounded contexts has their own domain model and can be owned entirely by a single product team. As long as these contexts have well-defined boundaries, each team can work autonomously within their own business subdomains without fear of disruption to others.
这些有界上下文中的每一个都有其自己的域模型,并且可以完全由一个产品团队拥有。 只要这些上下文具有明确定义的边界,每个团队就可以在自己的业务子域中自主工作,而不必担心会干扰其他人。
Rails engines
Rails引擎
In our monolith we’ve used Rails Engines to encapsulate our bounded contexts. According to the docs, Rails Engines are ‘miniature applications that provide functionality to their host applications’. While they do come with a bunch of useful tools out-of-the-box, the modularity they provide is mostly superficial. We’ll explore why soon.
在我们的整体中,我们使用了Rails Engine来封装我们的有限上下文。 根据文档,Rails引擎是“为其宿主应用程序提供功能的微型应用程序”。 尽管它们确实提供了许多现成的有用工具,但是它们提供的模块化大多只是肤浅的。 我们将尽快探讨原因。
Given this modularity is paper-thin, you may ponder their value. Why not just properly rip out functionality into a service? There’s no boundary harder than an HTTP call.
鉴于此模块化功能非常薄,您可以考虑它们的价值。 为什么不仅仅将功能正确地提取到服务中呢? 没有边界比HTTP调用难。
Other than being a much smaller commitment, there is one massive benefit.
除了做出较小的承诺外,还有一项巨大的好处。
Our engines are essentially nurseries for baby services. According to DDD, your domain model is constantly evolving and you’re going to get a lot wrong. The worst case scenario is you get it wrong enough to end up with a distributed monolith, which is miles worse than the monolith you started with.
我们的引擎实质上是婴儿服务的托儿所。 根据DDD的说法,您的域模型在不断发展,您会发现很多错误。 最坏的情况是您弄错了,最终只能得到分布式整体,这比开始时的整体要差得多。
Getting the boundaries wrong between services means weeks of refactoring. Getting the boundaries wrong between engines means spending 15 minutes moving some code around before your next meeting.
弄清服务之间的界限意味着数周的重构。 弄清引擎之间的界限错误意味着在下一次会议之前花费15分钟左右移动一些代码。
我们的边界是什么样的? (What do our boundaries look like?)
For our Kotlin microservices, we jumped fully onboard the Hexagonal hype train.
对于Kotlin微服务,我们完全跳上了六角炒作列车。
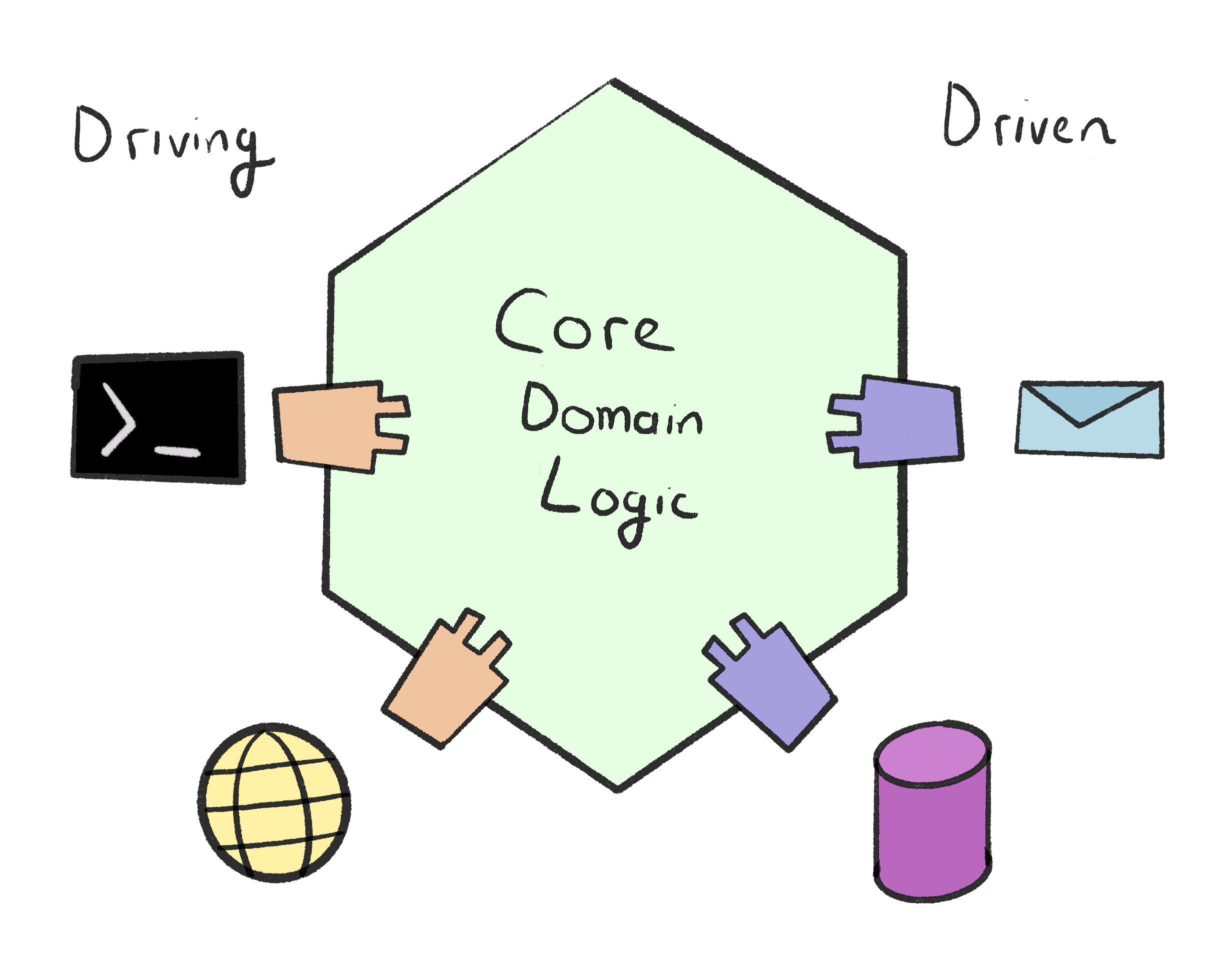
I don’t want to delve too deep into Hexagonal Architecture, but here’s the 5-second summary: protect your domain logic with adaptors.
我不想深入研究六角结构,但这是5秒的摘要:使用适配器保护域逻辑。
Given ActiveRecord and the lack of interfaces, most of Hexagonal doesn’t translate well into the Rails world. You’ll be fighting uphill if you want to truly adopt it. However, one fundamental part does translate perfectly — protect the core domain logic with adaptors.
鉴于ActiveRecord和缺少接口,Hexagonal的大多数不能很好地转换到Rails领域。 如果要真正采用它,您将面临艰巨的挑战。 但是,其中一个基本部分确实可以完美转换-用适配器保护核心域逻辑。
Hexagonal splits the adaptors into two kinds: inbound (driving) adaptors and outbound (driven) adaptors.
六角形将适配器分为两种: 入站 (驱动)适配器 和出站(驱动)适配器。
Inbound adaptors are entry points to an application that drive a particular user flow (for example, a Rails controller). Outbound adaptors are external calls that the application initiates — think the DB, payment providers, email, etc.
入站适配器是驱动特定用户流的应用程序(例如,Rails控制器)的入口点。 出站适配器是应用程序发起的外部调用,例如数据库,支付提供商,电子邮件等。
At its finest, Hexagonal promises to let you switch technologies without touching a single line of business logic. Want to move between REST, gRPC or CLI input? No worries, just write some more adaptors.
最好的是,Hexagonal承诺让您切换技术而无需触及任何业务逻辑。 是否要在REST,gRPC或CLI输入之间切换? 不用担心,只需编写更多适配器。
这如何适用于Rails引擎? (How does that apply to Rails engines?)
Since we’ve established our engines are baby services, there’s no reason they shouldn’t attempt to follow the same pattern. Each of our engines defines a set of inbound and outbound adaptors specifically for inter-engine communication.
由于我们已经确定我们的引擎是婴儿服务,因此没有理由他们不应该尝试遵循相同的模式。 我们的每个引擎都定义了一组专门用于引擎间通信的入站和出站适配器。
Let’s return to our cat grooming startup Luxuricat. If the CatGroomers engine needs to grab information about a cat in the CatClients engine, it doesn’t stick its hand over the fence and call:
让我们回到我们的猫美容创业公司Luxuricat。 如果CatGroomers引擎 需要在CatClients引擎中获取有关猫的信息,它不会把手伸到篱笆上并打电话:
cat = CatClients::Cat.find(cat_id)This would put us straight on the highway to Coupling Town. Instead, we can go through an outbound adaptor:
这将使我们直接进入通往耦合镇的高速公路。 相反,我们可以通过出站适配器:
deserialised_cat_model = CatGroomers::OutboundAdaptors::CatClients.fetch_cat(cat_id)Which at some point would call an inbound adaptor in the CatClients engine:
在某个时候会在CatClients引擎中调用入站适配器:
serialised_cat_model = CatClients::InboundAdaptors::Cat.fetch(id)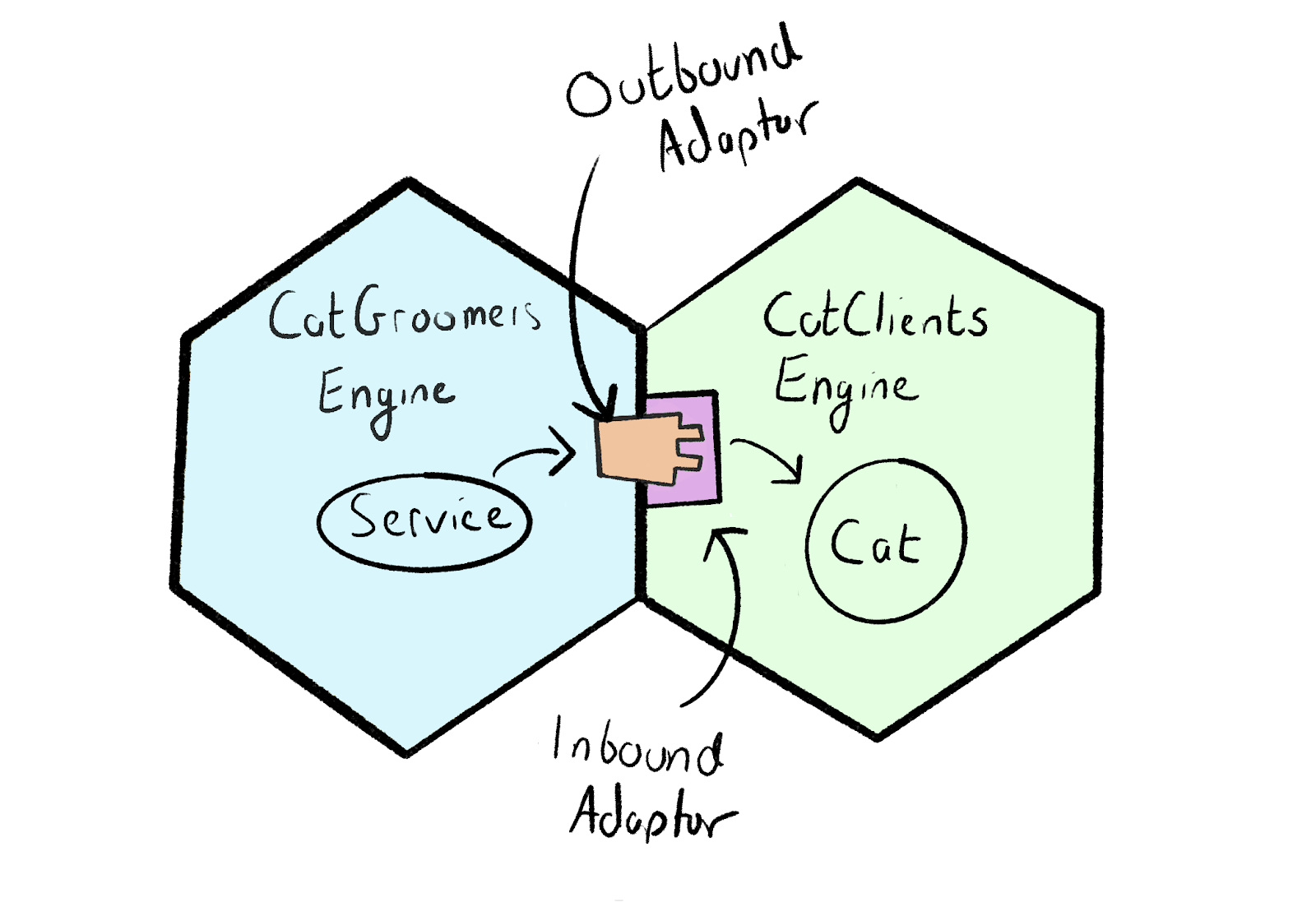
The call between the outbound and inbound adaptor is the engine boundary. Since this essentially forms the interface of the CatClients engine, it’s worthwhile making that interface explicit. We often use dry-validation for this purpose.
出站适配器和入站适配器之间的调用是引擎边界。 由于这实质上构成了CatClients引擎的接口,因此值得将该接口明确化。 为此,我们经常使用干燥验证 。
At first glance this may seem like a lot of extra boilerplate. However, since these adaptors use the medium of method calls rather than HTTP, their contents are generally super slim. Serialisation is barely more than putting attributes of a domain model into a hash, and you don’t need to bang your head on the wall with retries or handling response codes.
乍一看,这似乎是很多额外的样板。 但是,由于这些适配器使用方法调用的介质而不是HTTP,因此它们的内容通常非常薄。 序列化只不过是将域模型的属性放入哈希中而已,您无需重试或处理响应代码,就可以使工作陷入困境。
Adding these adaptors has additional value:
添加这些适配器具有附加价值:
1. It encourages interface-first development.
1.鼓励界面优先的开发。
2. It makes inter-engine communication explicit and observable.
2.它使引擎间的通信变得清晰可见。
3. If we do need to pull out an engine into a service, no domain logic needs to change.
3.如果确实需要将引擎引入服务中,则无需更改域逻辑。
那是什么问题呢? (So what’s the issue?)
Great, so we can add a bunch of these adaptors and only communicate through them to other domains. Problem solved, right?
很好,因此我们可以添加一堆这些适配器,并且仅通过它们与其他域进行通信。 问题解决了吧?
Unfortunately not.
不幸的是没有。
Rails has something it calls an ‘autoloader’. In Rails 6 this is handled by the gem Zeitwerk, which according to the README means you ‘don’t need to write require calls for your own files, rather, you can streamline your programming knowing that your classes and modules are available everywhere’.
Rails称之为“自动加载器”。 在Rails 6中,这是由Geit Zeitwerk处理的,根据README的说法 ,这意味着您“ 不需要为自己的文件编写require调用,而是可以在知道类和模块随处可见的情况下简化程序 ”。
In your Rails app, pretty much every class is available everywhere. Yet in our case, we’re deliberately trying to protect our domain logic so it isn’t available outside of its bounded context.
在您的Rails应用中,几乎所有课程都可以在任何地方使用。 但是,在我们的案例中,我们正在故意保护域逻辑,以使其在其有限上下文之外不可用。
2.为什么我们要强制执行边界 (2. Why we want to enforce boundaries)
What we’ve described is the state of Airtasker’s monolith. We’ve got subdomains inside engines using inbound and outbound adaptors, relying on culture and code review to encourage their use.
我们所描述的是Airtasker的整体状态。 引擎内部有使用入站和出站适配器的子域,它们依靠文化和代码审查来鼓励它们的使用。
So why experiment with enforcing boundaries? There are two motivations.
那么,为什么要尝试使用边界? 有两个动机。
2.1 —很难做错事 (2.1 — Make it hard to do the wrong thing)
The first benefit is the obvious one that comes to mind: encouraging good behaviour.
第一个好处是显而易见的好处:鼓励良好的举止。
When a developer writes code in a domain and realises they need information from an entity in another domain, ideally they’d pause and go back to the domain model and ask themselves questions.
当开发人员在一个域中编写代码并意识到他们需要来自另一个域中实体的信息时,理想情况下,他们会暂停并返回域模型并向自己提问。
1. Is this model in the right domain?
1.此模型在正确的域中吗?
2. If it is, should I add adaptors between these two domains?
2.如果是,是否应该在这两个域之间添加适配器?
3. What should the contract look like?
3.合同应该是什么样的?
Whatever the outcome of their domain puzzling session is, 90% of the time it’s going to be more effort than simply reaching out and grabbing the model directly. And if a developer is new to the codebase, they may not even be aware of the adaptor pattern at all.
无论他们的领域令人困惑的会议结果如何,在90%的时间里,与简单地直接接触并抓住模型相比,这将需要更多的精力。 而且,如果开发人员对代码库不熟悉,他们甚至可能根本不了解适配器模式。
‘But wait!’ you cry out. The developers that work on your application are super switched-on and go through a rigorous code review process. They’d never let human error like that get through.
'可是等等!' 你哭了。 在您的应用程序上工作的开发人员将超级开机,并经过严格的代码审查过程。 他们绝不会让这样的人为错误解决。
That is fair — we can presume most instances of boundary leakage would never make it through PR. However, not all boundary leakage issues will be so obvious as leaky_model = AnotherDomain::LeakyModel. In our decoupling efforts, we discovered some real head-scratchers.
这是公平的-我们可以假设大多数边界泄漏实例永远不会通过PR实现。 但是,并非所有的边界泄漏问题都将非常明显,如leaky_model = AnotherDomain::LeakyModel 。 在我们进行脱钩的过程中,我们发现了一些真正的头抓挠者。
Cultural practises can only take you so far. When the path of least resistance is at cross-purposes with your architecture, time and entropy will slowly erode code quality.
文化习俗只能带您走远。 当阻力最小的路径与您的体系结构交叉使用时,时间和熵将慢慢侵蚀代码质量。
2.2 —衡量进度 (2.2 — Measure progress)
If it’s worth doing, it’s worth measuring.
如果值得做,那就值得衡量。
If you start with a bloated monolith and want to take proactive steps towards decoupling it, you need to invest significant time, effort and creativity. Progress will be slow and improvements won’t be obvious. At first, developer productivity on the monolith may even start to decline. You may have to deal with sceptics.
如果您从膨胀的整体开始,并想采取积极的步骤来使其脱钩,则需要投入大量的时间,精力和创造力。 进展将会很缓慢,并且改进不会很明显。 首先,整体上的开发人员生产力甚至可能开始下降。 您可能必须与怀疑论者打交道。
Adding a bunch of adaptors and reducing coupling is a vague goal. Humans hate vague goals. It makes us anxious and unmotivated.
添加一堆适配器并减少耦合是一个模糊的目标。 人类讨厌模糊的目标。 这使我们感到焦虑和无动力。
On the flip side, humans love seeing numbers go up or down. We love discrete blocks of work that can be said to be done.
另一方面,人类喜欢看到数字上升或下降。 我们喜欢可以完成的离散工作。
For us, the biggest motivator for enforcing boundaries is to produce 1) a metric for progress and 2) a set of small, discrete goals.
对我们而言,执行边界的最大动机是产生1)进度指标和2)一组小的离散目标。
3.加强边界的方法 (3. Methods of enforcing boundaries)
We had decided to enforce our engine boundaries. But in order to proceed, we had to clearly define what our goal was. What does it actually mean to enforce a boundary?
我们已经决定强制执行引擎边界。 但是为了进行下去,我们必须明确定义我们的目标是什么。 强制执行边界实际上意味着什么?
We settled on the definition of an enforced engine boundary as one with 0 instances of inbound and outbound leakage. Inbound leakage is when another part of the codebase reaches in and pilfers domain logic inside your engine. Outbound leakage is when your engine reaches outwards to pilfer another.
我们将强制性发动机边界的定义确定为一个具有0个入站和出站泄漏实例的边界。 入站泄漏是指代码库的另一部分进入并窃取引擎内部的域逻辑。 向外泄漏是指您的发动机向外扩散以偷窃另一个。
With our goal spelled out, our next course of action was clear. Google the problem!
明确了我们的目标之后,我们的下一步行动就很明确了。 谷歌的问题!
We quickly discovered that enforcing engine boundaries isn’t a road well travelled. However, we did manage to find a few trailblazing blogs (links below) that were extremely helpful. It seemed there was precedent for two methods of boundary enforcement: isolated test suites and linting. We decided to experiment with both.
我们很快发现,强制执行引擎边界并不是行之有效的道路。 但是,我们确实找到了一些非常有用的开拓性博客(下面的链接)。 似乎有两种边界执行方法的先例:隔离测试套件和棉绒。 我们决定尝试两者。
Our guinea pig was an engine built before we introduced the pattern of adaptors. The team that owns the domain had a spare few weeks to dedicate to the project and were keen on introducing adaptors and reducing leakage.
我们的豚鼠是在介绍适配器模式之前制造的引擎。 拥有该域的团队有空闲的几周时间致力于该项目,并热衷于引入适配器并减少泄漏。
3.1 —隔离发动机单元测试 (3.1 — Isolating engine unit tests)
Your Rails app is going to autoload every class it can get its hands on. But do your tests need to? What if each engine had an independent set of unit tests that only loaded the constants available inside the engine? That way if your engine tried to sneak into another domain, the class it accessed would be unavailable and the tests would fail.
您的Rails应用程序将自动加载它可以使用的每个课程。 但是您的测试需要吗? 如果每个引擎都有一组独立的单元测试,这些测试仅加载引擎内部可用的常量,该怎么办? 这样,如果您的引擎试图潜入另一个域,则它访问的类将不可用,并且测试将失败。
This seemed really intuitive. If you have a bunch of services, each one would have their own independent set of units tests. So why shouldn’t engines?
这似乎非常直观。 如果您有一堆服务,那么每个服务将有自己独立的一组单元测试。 那么为什么不引擎呢?
We set to work on our guinea-pig engine, determined to introduce an independent test suite that would enforce against outbound leakage.
我们着手研究豚鼠发动机,并决定引入独立的测试套件,以防止出站泄漏。
向Rails引擎添加测试 (Adding tests to a Rails Engine)
We’ve always run the tests for our monolith from a single RSpec config. So we were surprised to learn that the conventional way to test an engine is using a ‘dummy’ rails application. This is an empty, yet fully-functional, rails application used as a ‘mounting point’ for the engine during testing.
我们始终从单个RSpec配置运行针对整体的测试。 因此,令我们惊讶的是, 传统的测试引擎的方法是使用“虚拟”导轨应用程序。 这是一个空的但功能齐全的导轨应用程序,在测试过程中用作引擎的“安装点”。
It seemed we’d generated our engine without the dummy app, so we needed to go back and regenerate it. Afterwards, we naively typed rspec and hoped nothing would break.
看来我们是在没有虚拟应用程序的情况下生成引擎的,所以我们需要返回并重新生成它。 之后,我们天真地输入了rspec ,希望不会有任何问题。
Turns out, a lot of things broke. This was our first learning: expect to spend a lot of time introducing and maintaining config.
原来,很多事情坏了。 这是我们的第一次学习:期望花费大量时间介绍和维护配置。
At minimum, you’ll need to maintain separate rails_helper.rb and spec_helper.rb with only the config relevant to that specific engine and its dependencies. Your engine .gemspec needs to be in tip-top shape as well, with all gems manually imported with require.
至少,您需要仅使用与该特定引擎及其依赖项相关的配置来维护单独的rails_helper.rb和spec_helper.rb 。 您的引擎.gemspec也需要处于顶部形状,所有宝石都需要手动导入。
Once we’d solved the config problem, we were greeted with a towering list of failing tests. And we had our second learning: isolated test suites are brutal at catching boundary leakage.
解决配置问题后,我们将看到一系列失败的测试。 我们有了第二个学习:孤立的测试套件在捕获边界泄漏方面很残酷。
隔离测试有效 (Isolated tests were effective)
The tests caught a lot more leakage than we expected. Some of the leakage was obvious, others hidden and implicit. Some were quick changes, while others took days of work for a single green test.
测试发现了比我们预期更多的泄漏。 其中一些泄漏是显而易见的,其他泄漏是隐性的和隐性的。 有些是快速更改,而另一些则花了几天时间进行一次绿色测试。
They were also a superb motivator. Slowly reducing the failing tests to 0 was addictive and ultimately adding it as CI step was a proud moment.
他们也是一个极好的动力。 将失败的测试缓慢地减少到0会令人上瘾,最终在CI步骤中添加它是一个值得骄傲的时刻。
There was an additional benefit which we hadn’t expected. We’d known our engine was coupled — but what about our tests? It turns out our tests, specifically their use of FactoryBot factories, were in a much worse state than the code they were testing. Our factories were ripe with associations created across engine boundaries.
还有一个我们没想到的额外好处。 我们知道我们的引擎是耦合的-但是我们的测试呢? 事实证明,我们的测试(尤其是他们对FactoryBot工厂的使用)处于比他们要测试的代码更糟糕的状态。 我们的工厂已经建立了跨引擎边界的关联。
入站泄漏怎么办? (What about inbound leakage?)
We’d had such a blast enforcing against outbound leakage for our guinea-pig engine, we were excited to do the same for inbound leakage. We eagerly sought the advice of our original inspiration, the awesome blog Modular Monolith.
我们对豚鼠发动机进行了爆炸,以防止出站泄漏,我们很高兴为入站泄漏做同样的事情。 我们热切地寻求原始灵感的建议,即很棒的博客Modular Monolith 。
It had an interesting approach. To illustrate, let’s return back to our cat grooming startup with their two engines: CatClients and CatGroomers. CatClients is a dependency of CatGroomers — to groom a cat you need to know that cats exist, but cats don’t need to know that the cat grooming profession exists.
它有一个有趣的方法。 为了说明,让我们回到我们的Cat美容初创公司,他们有两个引擎: CatClients和CatGroomers 。 CatClients是CatGroomers的依赖项 -修饰猫只需要知道猫的存在,而猫则不需要知道猫的修饰专业。
To follow the blog’s approach, the test suite for CatClients would run in complete isolation. However, the test suite for CatGroomers would also load the CatClients engine as a dependency.
为了遵循博客的方法, CatClients的测试套件将完全隔离地运行。 但是,用于CatGroomers的测试套件也会将CatClients引擎作为依赖项加载。
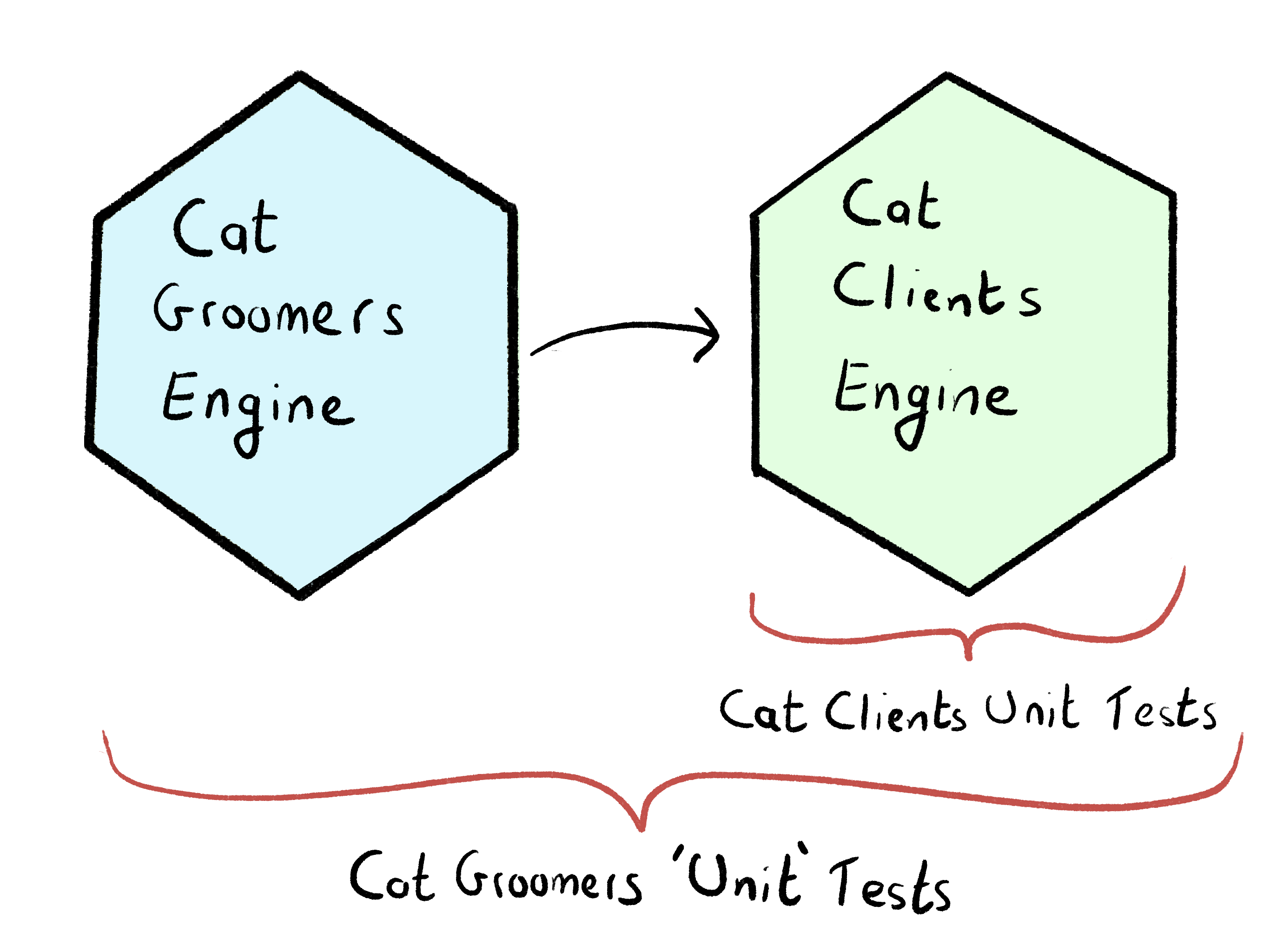
In this instance, a portion of the tests inside the CatGroomers engine are acting as integration tests. If you test a CatGroomers method that fetches a cat, you run code inside the CatClients engine and can be confident that no integration issues occur for that user path.
在这种情况下, CatGroomers引擎内部的部分测试充当集成测试。 如果您测试获取猫的CatGroomers方法,则可以在CatClients引擎内运行代码,并且可以确信该用户路径不会发生任何集成问题。
That’s awesome. But how do you know that the CatClients domain hasn’t leaked into the CatGroomers domain? How do you know that a service in the CatGroomers domain isn’t ignoring adaptors and reaching in to grab CatClients domain models?
棒极了。 但是,您如何知道CatClients域尚未泄漏到CatGroomers域中呢? 您如何知道CatGroomers域中的服务不会忽略适配器并伸手抓住CatClients域模型?
整合问题 (Integration issues)
There is an immediate solution to this problem. If isolating the CatClients test protects against outbound leakage, we can protect against inbound leakage by isolating the CatGroomers tests.
有一个立即解决此问题的方法。 如果隔离CatClients测试 可以防止出站泄漏,我们可以通过隔离CatGroomers测试来防止入站泄漏。
Therein lies another problem. If you have two engines that collaborate together, both unit tested by mocking the boundaries between each other, how can you gain confidence that there are no integration issues?
其中存在另一个问题。 如果您有两个相互协作的引擎,并且两个引擎都通过模拟彼此之间的边界进行了单元测试,那么您如何才能确信没有集成问题?
If these were truly two separate services, the solution would be clear. CatGroomers needs a separate set of integration tests.
如果这些确实是两个单独的服务,则解决方案将很清楚。 CatGroomers需要单独的一组集成测试。
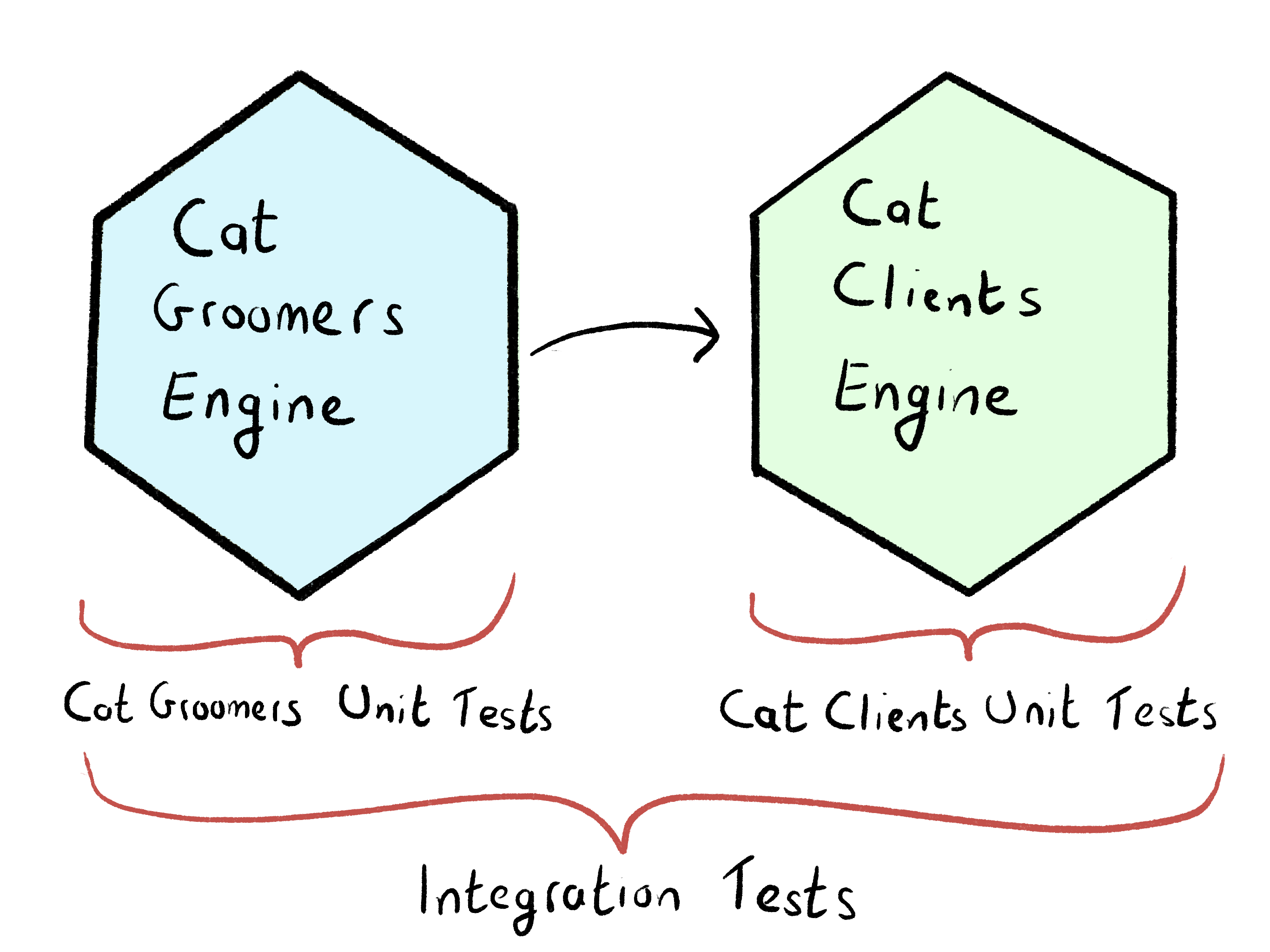
While this does sound like the ideal long-term solution, the upfront commitment to write a new set of integration tests is high.
尽管这听起来似乎是理想的长期解决方案,但是编写一组新的集成测试的前期承诺很高。
Is there a nearer-term method of measuring and enforcing inbound leakage?
有没有一种近期方法来衡量和执行入站泄漏?
3.2 —用Rubocop整理 (3.2 — Linting with Rubocop)

Enter our second experiment, courtesy of this amazing blog by Flexport. The idea is pretty neat — just lint boundary leakage with Rubocop!
进入我们的第二个实验, 这是Flexport撰写的这个很棒的博客 。 这个想法非常简洁-Rubocop的边界泄漏很少!
Flexport wrote three custom cops: one to prevent new models being created in the core /app, one to stop engines accessing code inside the core /app, and one to protect against access into an engine. They’ve even admirably open-sourced them.
Flexport编写了三个自定义警察:一个阻止在/app核心中创建新模型,一个阻止引擎访问内核/app代码,另一个防止访问引擎。 他们甚至将它们开源 。
Our main interest was the final cop that linted direct access into engines. This sounded like a great next step. We could measure and enforce inbound leakage for our guinea-pig engine while still keeping the existing tests that were inadvertently acting as integration tests.
我们的主要兴趣是阻止直接访问引擎的最终警察。 这听起来像是一个很好的下一步。 我们可以为豚鼠发动机测量并强制执行入站泄漏,同时仍保留不经意充当集成测试的现有测试。
We dug into the cop implementation. To our pleasant surprise, our first learning was that custom rubocop cops are pretty intuitive and a lot of fun. Definitely recommend playing around with them.
我们研究了cop的实现。 令我们感到惊喜的是,我们的第一个了解是定制的鲁宾科警察非常直观,也很有趣。 绝对建议和他们一起玩。
The idea behind the cop is fairly simple and replicable in our codebase. Essentially, the cop lints for two specific scenarios:
cop背后的思想在我们的代码库中相当简单并且可复制。 从本质上讲,警察对两种特定情况进行了评估:
Uses of classes with an engine namespace:
具有引擎名称空间的类的使用:
NotYourEngineNamespace::LeakyService.important_methodAnd associations using an engine namespace:
以及使用引擎名称空间的关联:
has_one :leaky_model, class_name: “NotYourEngineNamespace::LeakyModel”The simplicity was reassuring, but also brought us back to earth. Linting wasn’t going to be a silver bullet — the subtle leakage issues the isolated tests caught were going to fly under the radar.
简单性令人放心,但也带我们回到了现实。 Linting不会成为灵丹妙药-孤立的测试所捕获的细微泄漏问题将在雷达下飞行。
This approach does have a lot of benefits: it’s super easy to get set up and starts to enforce against leakage from the get-go. It’s definitely a lighter touch than the isolated tests, which required a whole heap of config and didn’t enforce until we cleared the failing tests and added it as a CI step.
这种方法确实有很多好处:设置起来超级容易,并且可以从一开始就强制执行以防泄漏。 这绝对比隔离测试要轻松,隔离测试需要一整套配置,并且直到我们清除失败的测试并将其添加为CI步骤后才强制执行。
现在怎么办? (What now?)
That’s the result of our experimentation so far. We’ve got a single engine enforcing against outbound leakage with an isolated test suite and enforcing against inbound leakage via a custom Rubocop cop.
到目前为止,这是我们实验的结果。 我们有一个单独的引擎,可以通过隔离的测试套件来防止出站泄漏,并可以通过定制的Rubocop警察来防止进站泄漏。
Using Rubocop was a lot easier to get started and produced results immediately. However, the coverage wasn’t exhaustive. Isolating the tests was a pain in the arse, yet caught way more leakage than we ever imagined.
使用Rubocop可以轻松上手,并立即产生结果。 但是,报道并不详尽。 隔离测试是一个麻烦,但是却比我们想象的要多得多。
Overall, we’re satisfied with these approaches and plan to use a mix of both — Rubocop in the short term, working towards the goal of an independent test suite for each engine and a supporting set of engine integration tests.
总体而言,我们对这些方法感到满意,并计划在短期内将二者结合使用-Rubocop,以实现针对每个发动机的独立测试套件和一组发动机集成测试的目标为目标。
Let us know if you have any questions or want to share your own views of enforcing Rails engine boundaries!
让我们知道您是否有任何疑问,或者想分享自己对执行Rails引擎边界的看法!
翻译自: https://medium.com/airtribe/enforcing-modularity-inside-a-rails-monolith-f856adb54e1d
rails 模块化