Kubernetes中的Service用法及如何通过endpoint关联容器外服务_kubectl svc 修改endpoint-程序员宅基地
技术标签: 云原生 kubernetes 容器
一、Service的概念
Service能够为应用提供一个统一的访问地址(入口地址),并且,Service也提供了负载均衡功能,从而将客户端的请求分发到后端的各个容器中。
Service的两个主要作用:
- 通过标签Label与Pod关联,实现与Pod的通信
- 提供不同的访问策略,以实现访问Pod请求的负载均衡
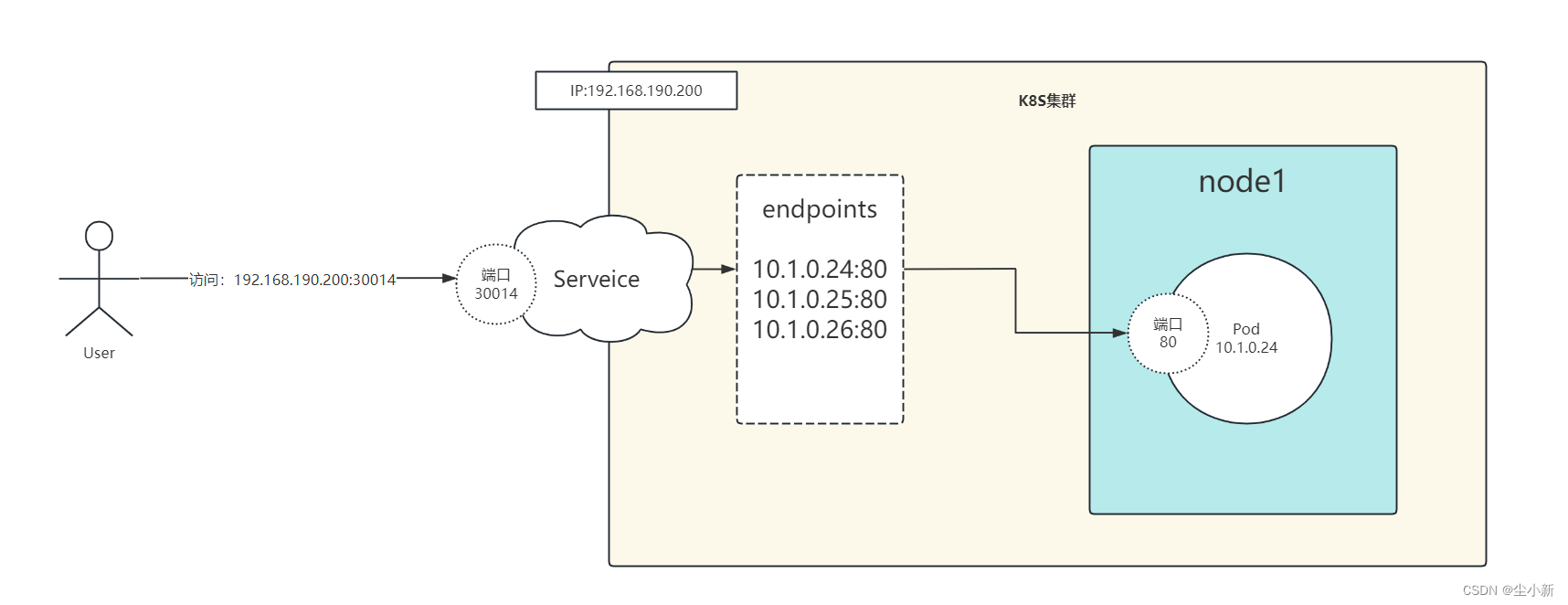
这里以NodePort规则访问来进行说明
1、用户访问192.168.190.200:30014
2、k8s集群根据用户访问的30014端口号找到对应的service
3、service根据同名的endpoints中绑定的Pod IP地址进行负载均衡,转发给其中一个pod
4、根据pod IP 和端口号请求指定服务
二、Service资源的四种类型
2.1 ClusterIP
ClusterIP是Service默认的发布类型。它将在集群内部分配一个可以访问的虚拟IP地址,通过IP地址暴露服务。因此,这类型的Service只能实现同一个集群内部之间的相互访问。
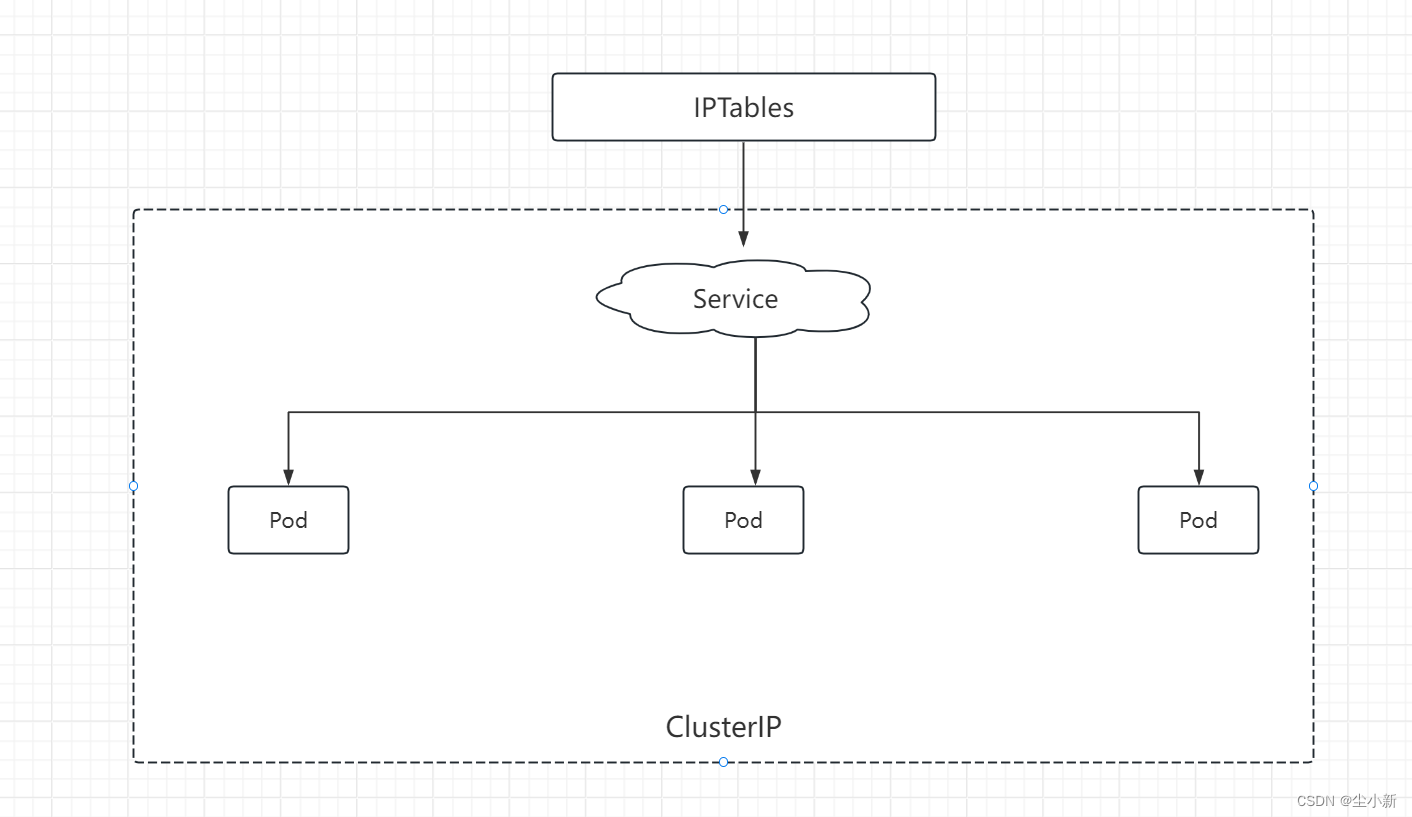
示例:
[root@master clusterIp]# cat service-clusterip.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: deploy-clusterip
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: ngin
---
apiVersion: v1
kind: Service
metadata:
name: service-clusterip
spec:
ports:
- name: http
port: 1234
protocol: TCP
targetPort: 80
selector:
app: nginx
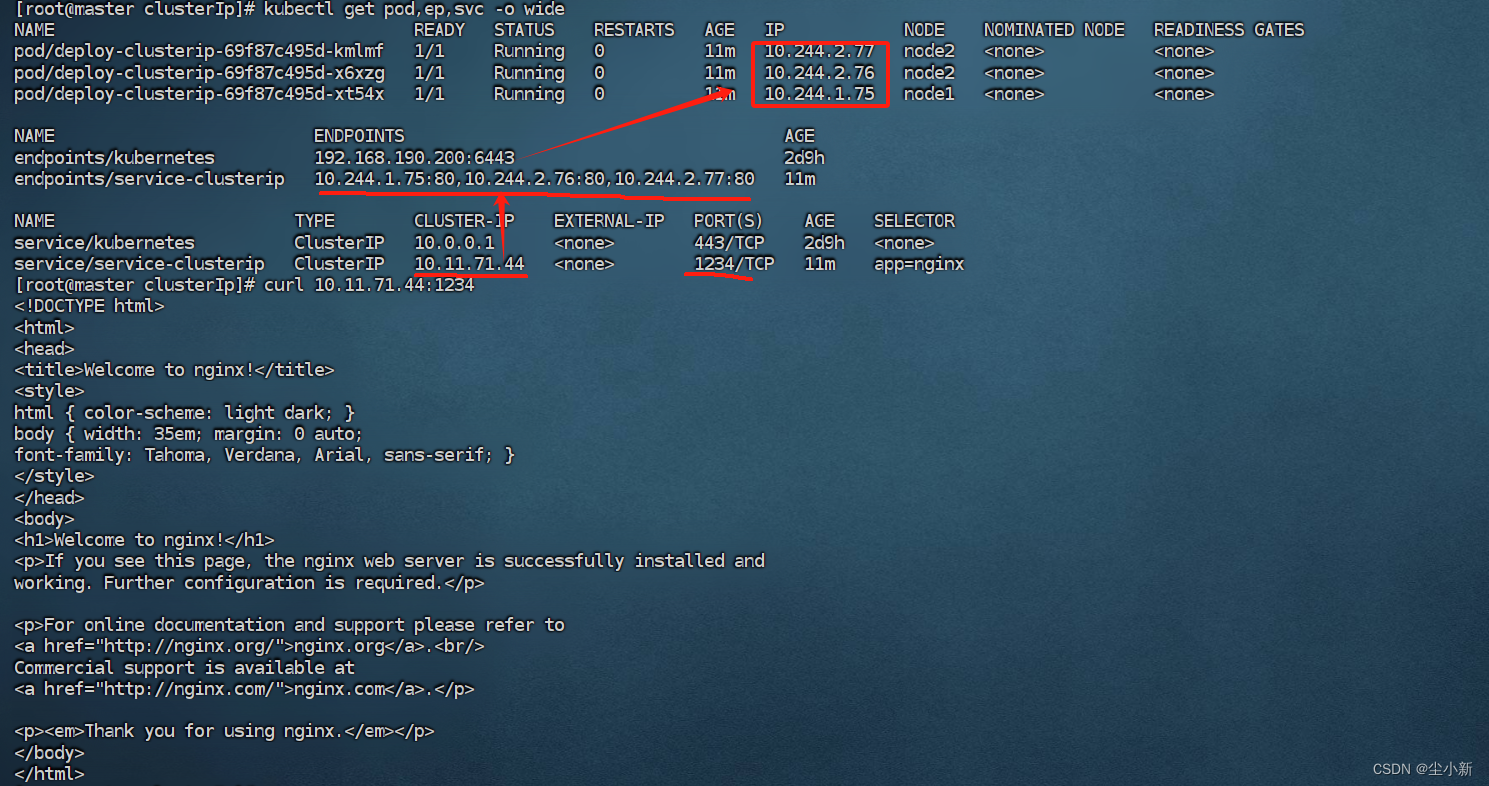
[root@master clusterIp]# kubectl apply -f service-clusterip.yaml
访问:[root@master clusterIp]# curl 10.11.71.44:1234
2.2 NodePort
把Service的type字段设置为NodePort时,Kubernetes将在每个节点上随机分配一个端口作为外部用户的访问入口(该端口号的默认范围是30000-32767,也是可以修改的)。该端口孕妇外部用户访问集群内部的Pod应用。如果用户想指定范围内的某个端口,需要增加一个nodePort字段。
示例:
[root@master clusterIp]# cat nodeport-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: service-nodeport
spec:
type: NodePort
ports:
- name: http
port: 80
targetPort: 80
nodePort: 31234
protocol: TCP
selector:
app: nginx
访问:192.168.190.200:31234
因为我们前面一个案例创建了labes为app: nginx的pod实例,所以我们这里绑定app:nginx也是可以访问这些实例的

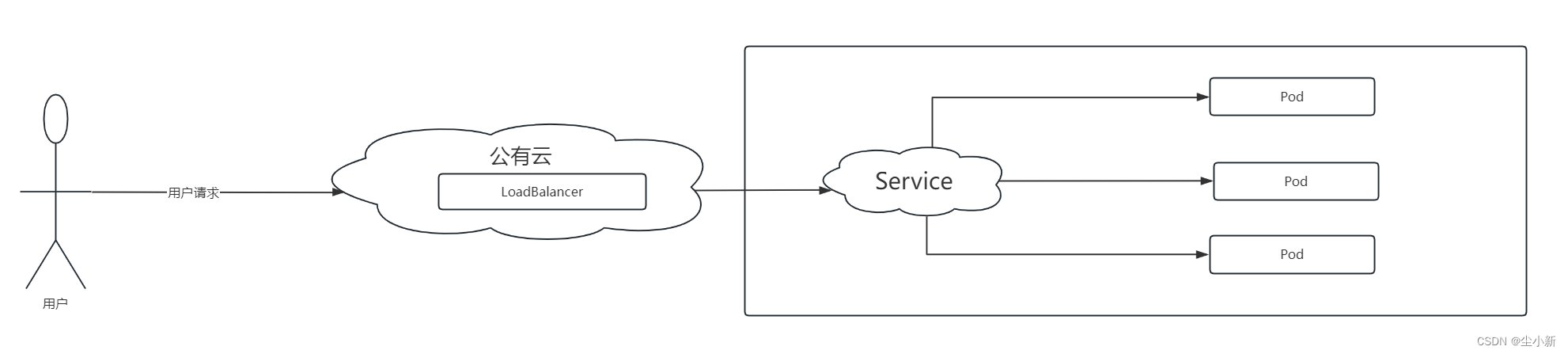
2.3 LoadBalance
如果要使用外部负载均衡器来访问应用(如Google Cloud、AWS和OpenStack等),则可以通过使用LoadBalancer类型的Service将Kubernetes集群中的IP地址和端口号自动加入公有云的LoadBalancer中,从而异步的实现负载均衡。
2.4 ExternalName
ExternalName类型的Service可以将一个已经存在的Service映射到外部的DNS服务,从而达到通过使用外部DNS服务解析服务应用的目的。
范例:
[root@master service-demo]# cat 06-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: svc-externalname
spec:
type: ExternalName
externalName: www.baidu.com
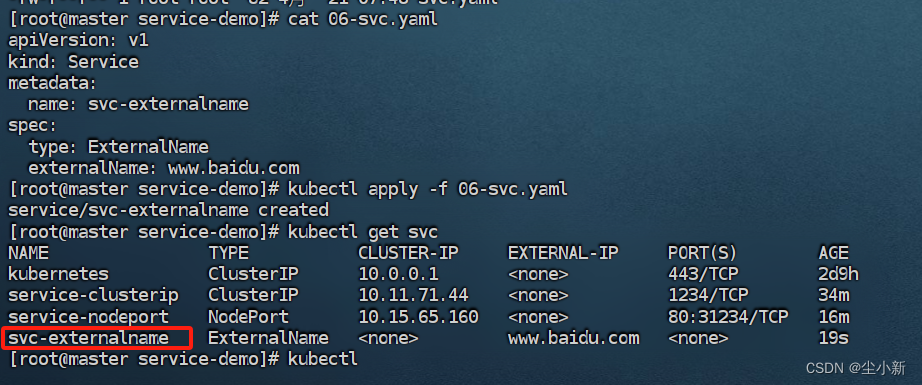
这样我们在集群内部方位svc-externalname服务实际访问的时候www.baidu.com
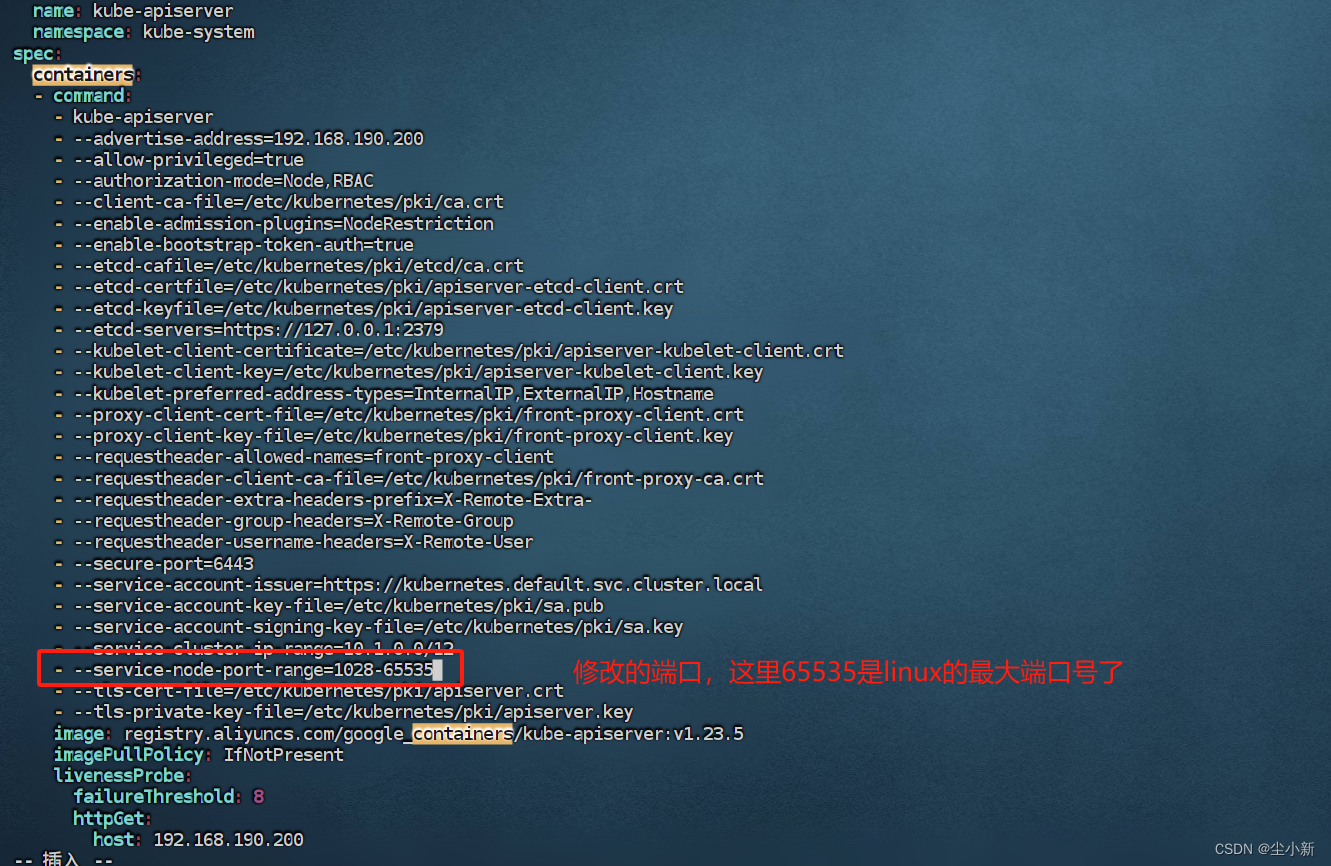
二、修改svc的NodePort类型中宿主机映射端口的范围
默认是30000-32767,可以通过静态pod目录下的/etc/kubernetes/manifests/kube-apiserver.yaml资源清单中加上一条命令,来设置宿主机的映射端口范围
三、svc的endpoint列表
用户通过访问svc资源,进而将请求转发到列表中的pod中,endpoint列表,就是svc将请求转发到目的地
endpoint本质上也是一个单独的资源,只是在我们创建svc资源的时候,系统自动给我们创建的,svc资源与endpoint资源是通过元数据(metadata)中的名称进行关联的,只要endpioint资源的名称与svc资源的名称相同,则,endpoint资源的服务IP就会出现在svc资源的endpoint列表中
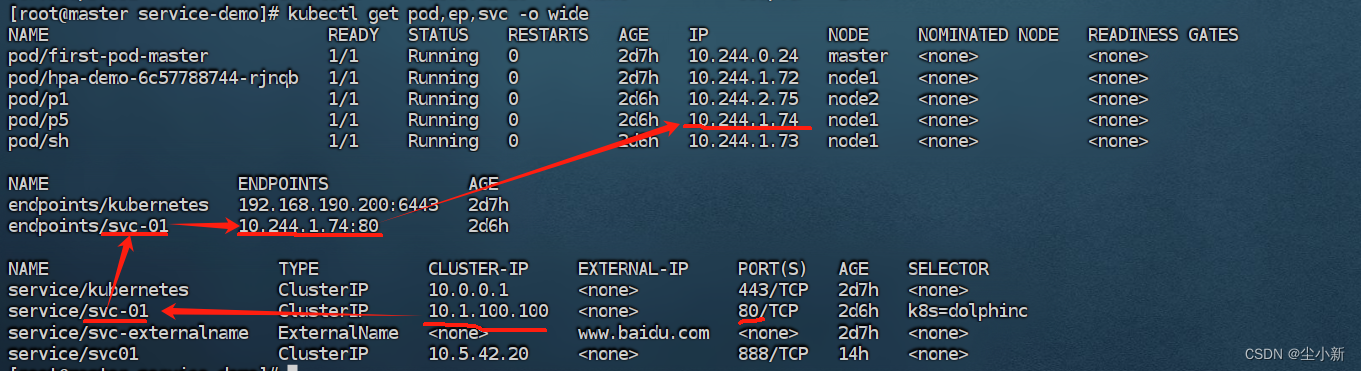
如图,我们访问service/svc-01的地址10.1.100.100:80,endpoint/svc-01会负载均衡转发给其中一个绑定的地址10.244.1.74:80(因为这里就绑定了一个pod实例,所以就会转发给这个地址)
测试访问结果

四、service资源中endpoint列表关联外部服务
4.1 创建一个svc资源(svc01)
4.1.1 编辑svc资源清单
[root@master service-demo]# cat svc.yaml
apiVersion: v1
kind: Service
metadata:
name: svc01
spec:
ports:
- port: 888
4.1.2 创建svc资源
[root@master service-demo]# kubectl apply -f svc.yaml
4.1.3 查看svc资源 (curl 10.5.42.20:888)
[root@master service-demo]# kubectl describe svc svc01
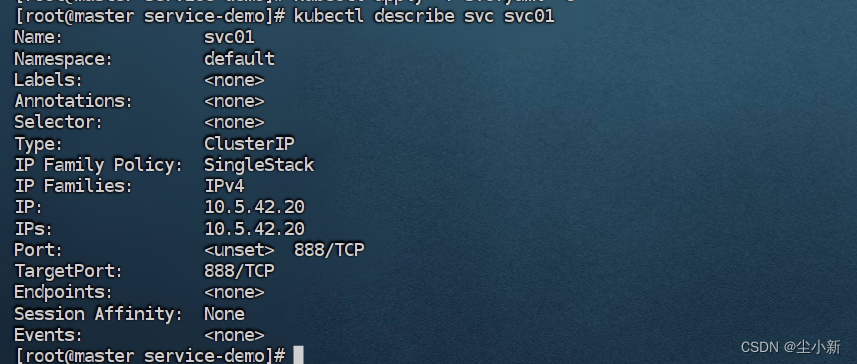

可以看到endpoint列表中什么都没有,也就是说访问svc资源,什么都访问不到;我们还记得上面说的,svc资源是通过"标签选择"来将pod加入到svc的endpoing列表中的,那么我们如何将k8s集群外不到容器添加到endpoint列表中呢?
举例:在生产环境中,我们的数据库服务,就是常年运行的历史性业务,当企业的应用上k8s时,数据的迁移工作非常的频繁,所以,如果将外部的sql服务,加入到svc资源的endpoint列表中,就节省了数据库迁移k8s的复杂工作;
4.2 svc资源与endpoint资源关联
4.2.1 k8s集群外拉取一个nginx服务
[root@master service-demo]# docker run --name dolphin-nginx -p 30080:80 -d nginx
b07bed9083366a4a8eda1ccc20f5e6ed8bcd0f908919ee2274ac315054219be7
4.2.2 测试查看服务
正常访问

4.2.3 创建endpoint资源 (svc01)
[root@master service-demo]# cat endpoints.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: svc01
subsets:
# 指定外部endpoints的宿主机IP
- addresses:
- ip: 192.168.190.200
ports:
- port: 30080
[root@master service-demo]# kubectl apply -f endpoints.yaml
endpoints/svc01 created
4.2.4 查看svc资源 (curl 10.5.42.20:888)
[root@master service-demo]# kubectl describe svc svc01
Name: svc01
Namespace: default
Labels: <none>
Annotations: <none>
Selector: <none>
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.5.42.20
IPs: 10.5.42.20
Port: <unset> 888/TCP
TargetPort: 888/TCP
Endpoints: 192.168.190.200:30080
Session Affinity: None
Events: <none>
绑定成功
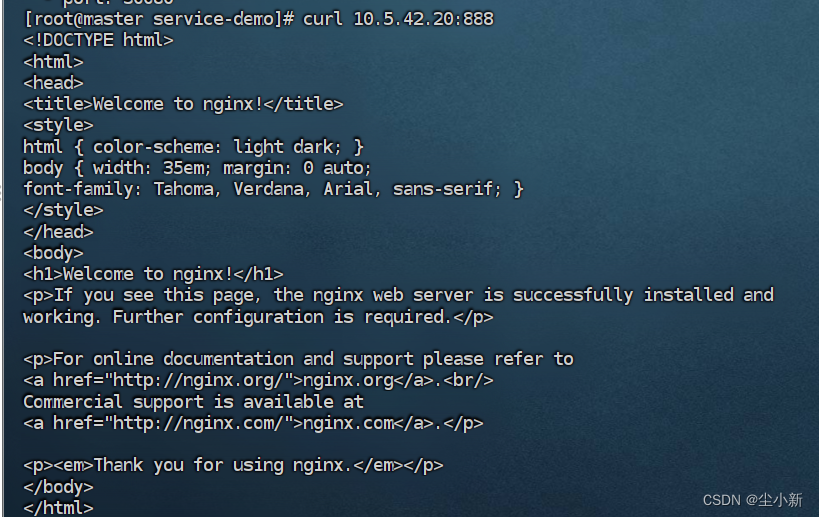
访问成功
4.2.5 k8s内部集群访问服务客户通过 svc01:888 进行访问
访问规则:命名空间.服务名:端口号,因为我们这里是创建在默认命名空间所以省略了default,
完整写法:default.svc01:888
五、集群内部的DNS服务
Service在实现请求代理和负载均衡时,默认采用的是ClusterIP地址。但是ClusterIP地址不是永远不变的,因此建议在应用中不要使用ClusterIP,而是用Service的名称。Kubernetes集群提供DNS服务可以将Service的名称解析为ClusterIP地址。
k8s在kube-system的命名空间中自动启动了Pod来运行DNS服务
[root@master service-demo]# kubectl get pod -n kube-system | grep dns
coredns-6d8c4cb4d-mc78b 1/1 Running 3 (4d7h ago) 4d7h
coredns-6d8c4cb4d-zfjx2 1/1 Running 0 4d7h
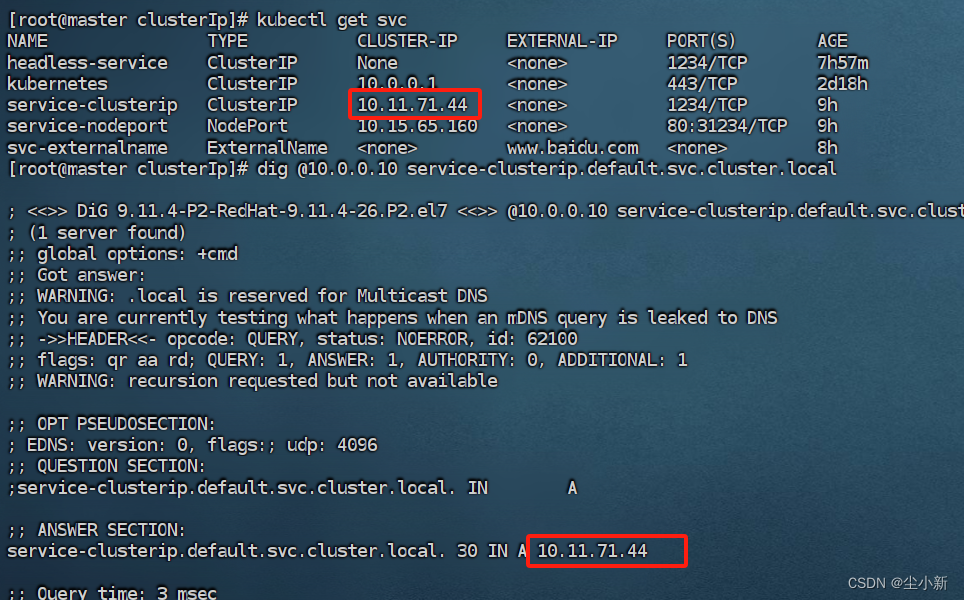
示例:如下图,我们可以通过service-clusterip.default.svc.cluster.local访问service-clusterip的服务,不用去通过IP访问。也可以简写为service-clusterip.default(服务名+名称空间)的形式方位服务,同一个命名空间可以直接省略名称空间,即service-clusterip(服务名)来方位
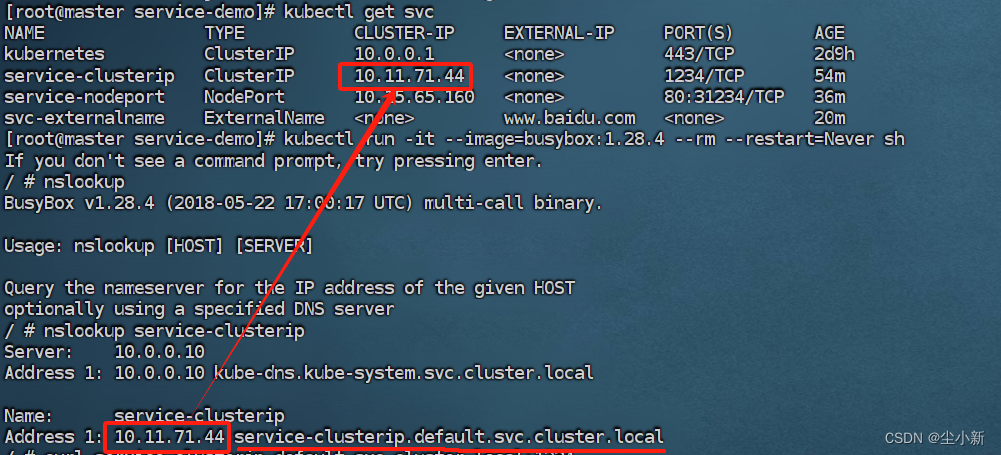
六、无头Service——直接访问Pod IP
每一个Service都会有一个Service名称,并最终由DNS解析成Cluster IP地址,连接到Service的客户端最终通过ClusterIP地址被转发到后端一个随机选择的Pod上。因此,这时客户端并不清楚后端Pod的IP地址。但是对于一些有状态的客户端来说,需要清楚地知道后端每个Pod的IP地址才能与其直接进行通信。这时就需要使用无头Service(Headless Service)。
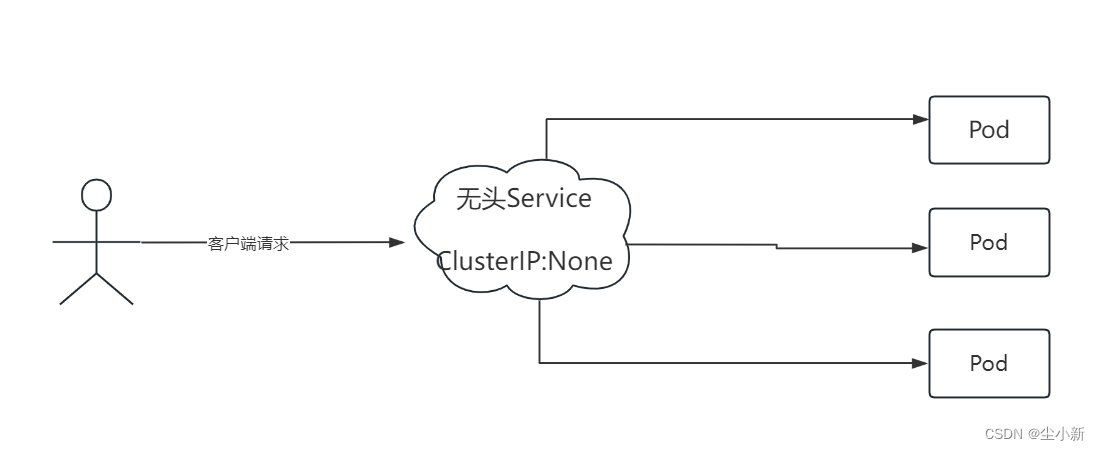
上图说明了无头Service的运行机制,核心是:去掉了DNS解析Cluster IP地址这个过程,直接返回Pod的IP地址,下图可以看到下边的无头Service CLUSTER-IP列为None

示例:
[root@master service-demo]# cat headless-service.yaml
apiVersion: v1
kind: Service
metadata:
name: headless-service
spec:
selector:
name: busybox
clusterIP: None
ports:
- name: http
port: 1234
targetPort: 1234
---
apiVersion: v1
kind: Pod
metadata:
name: headless-service-pod-1
labels:
name: busybox
spec:
hostname: headless-service-pod-1
containers:
- image: busybox
command:
- sleep
- "3600"
name: busybox
---
apiVersion: v1
kind: Pod
metadata:
name: headless-service-pod-2
labels:
name: busybox
spec:
hostname: headless-service-pod-2
containers:
- image: busybox
command:
- sleep
- "3600"
name: busybox
dig访问无头Service,可以看到在ANSWER SELECTION中返回后端两个Pod的IP地址
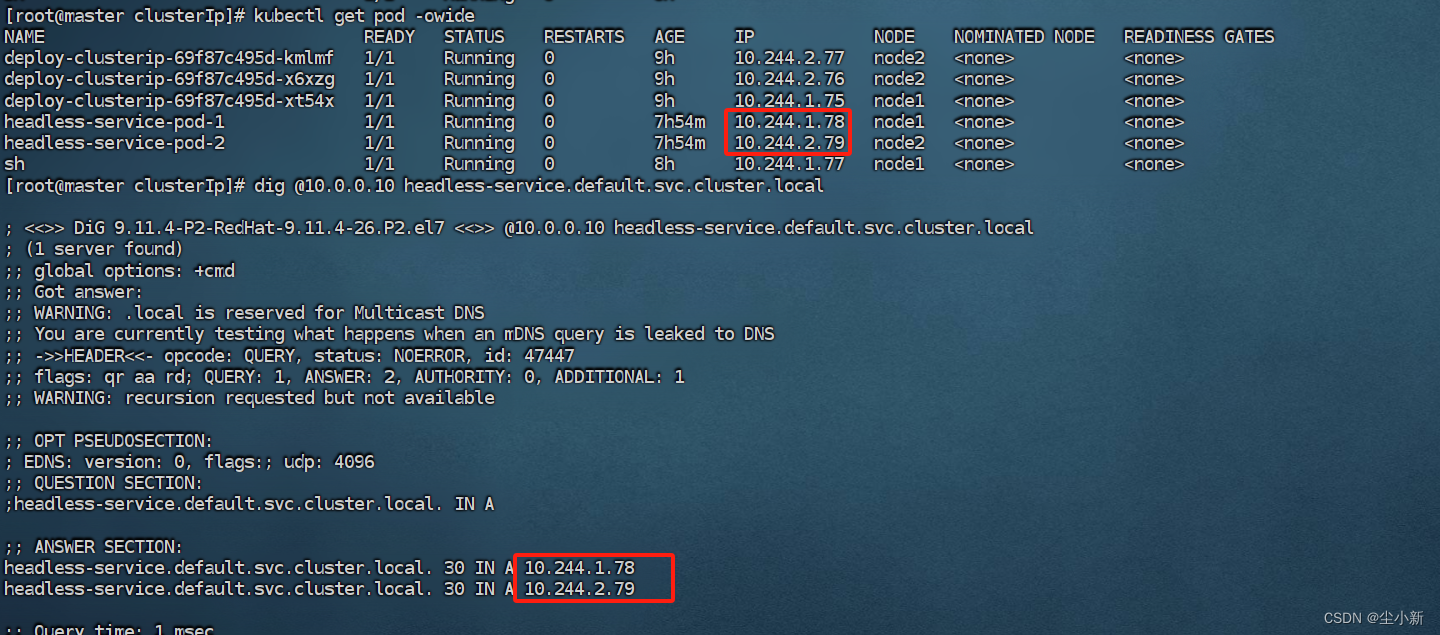
dig访问普通Service,可以看到在ANSWER SELECTION中返回的示Service的ClusterIP地址
智能推荐
pandas 取excel 中的某一列_Pandas进阶修炼120题,给你深度和广度的船新体验-程序员宅基地
文章浏览阅读1.2k次,点赞3次,收藏23次。Pandas 是基于 NumPy 的一种数据处理工具,该工具为了解决数据分析任务而创建。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的函数和方法。和鲸社区的@刘早起同学创作了这个项目,其中包含Pandas基础、Pandas数据处理、金融数据处理、当Pandas遇上NumPy、补充内容 5个部分。在深度和广度上,都相较之前的Pandas习题系列有了很大的提升。此前的..._在运用pandas进行数据分析时,可以用df.append(df.iloc[7])将第8行数据添加到末尾
完美解决tomcat8.5+远程无法登录tomcat问题及jenkins远程部署问题_jenkins远程部署tomcat未启动-程序员宅基地
文章浏览阅读4.5k次。tomcat8.5之后配置了用户名密码之后默认只能本地访问,远程是无法访问的,可用下面方法进行解决1. C:\Users\Administrator\Desktop\apache-tomcat-8.5.27-windows-x64\apache-tomcat-8.5.27\conf\tomcat-users.xml 中增加<role rolename="manager-gui"/>&l..._jenkins远程部署tomcat未启动
【Paper Reading Note】Brief Introduction of Encrypted Traffic Classification Using PEAN_listen to minority: encrypted traffic classificati-程序员宅基地
文章浏览阅读181次。Brief Introduction of Encrypted TrafficClassification[Data Preprocessing-Oriented] [Essay Reading & Understanding Record] [2023.4] [Author : LWC]_listen to minority: encrypted traffic classification for class imbalance wit
Sqlite-- 使用Java程序、cmd命令行来备份恢复Sqlite数据库_java程序,使用sqlite数据库,如何备份-程序员宅基地
文章浏览阅读1w次。引子: 1,Sqlite在Windows、Linux 和 Mac OS X 上的安装过程 2,嵌入式数据库的安装、建库、建表、更新表结构以及数据导入导出等等详细过程记录 3,嵌入式数据库事务理解以及实例操作 4,数据迁移备份--从低版本3.6.2到高版本3.8.6 5,Java使用jdbc连接Sqlite数据库进行各种数据操作的详细过程 ..._java程序,使用sqlite数据库,如何备份
python+selenium+pytest自动化测试之下拉选择框处理_python.pytest 如何选择第一个下拉选项-程序员宅基地
文章浏览阅读2.9k次。应用场景:新增或者查询时,遇到下拉选择框,进行处理,本博客主要用于根据状态查询数据,对列表中的数据进行断言分析。1.BasePage封装select操作: def select_option(self,locator,value,type="index"): self.wait_utilVisible(locator) se=self.get_elemen..._python.pytest 如何选择第一个下拉选项
实例分割学习笔记_sav图像分割-程序员宅基地
文章浏览阅读274次。实例分割是计算机视觉中一种先进的任务,它旨在将图像中的每个对象实例都准确地分割出来,并为每个实例分配一个唯一的标识。与语义分割只关注像素级别的分类不同,实例分割要求在像素级别对每个对象进行分割和标记,能够正确识别多个相同类别的对象,并将它们区分开来。本篇博客介绍了实例分割的基本概念、基本方法和实践步骤。实例分割作为计算机视觉领域的重要任务,具有广泛的应用前景。通过深入学习和实践,你可以掌握实例分割的关键技术,提高模型性能并应用于实际场景。希望本篇学习笔记对你的实例分割学习和研究有所帮助~_sav图像分割
随便推点
ElasticSearch 字段数据存在,但用term查询搜索不到指定的数据_elasticsearch中match查询和term不可用-程序员宅基地
文章浏览阅读6.1k次,点赞11次,收藏13次。近日使用ElasticSearch查询数据时遇到了个问题,在es中该字段对应的数据是存在的,但使用term/terms查询时却查不到。同时,我使用match去查询却能查到:match能查到而term查不到,用过es的都应知道这两者的查询是有区别的:match是全文搜索,用于查询字段类型为text的字段,match进行搜索的时候,会先进行分词拆分,拆完后,再来匹配;而term是精确查询,也就是完全匹配,通常用于对keyword和有精确值的字段进行查询,搜索前不会再对搜索词进行分词拆解。由上面的._elasticsearch中match查询和term不可用
人工智能_机器学习059_非线性核函数_poly核函数_rbf核函数_以及linear核函数效果对比---人工智能工作笔记0099_linear、 poly、rbf-程序员宅基地
文章浏览阅读595次。X += np.random.randn(100,2) 我们从正太分布中拿出100行2列的数据来,拼接到X生成的100行2列的数据里面,现在的原来的X,就变成了。- `X[:,0]`:这是第一个维度(通常是x轴)的值,X 是一个二维数组,`X[:,0]` 表示取X数组的第一列。- `X[:,1]`:这是第二个维度(通常是y轴)的值,X 是一个二维数组,`X[:,1]` 表示取X数组的第二列。这个是5,5 表示图形的大小,x轴,y轴的大小,设置好以后生成的就圆了,要不然是椭圆的,可以看到上面显示的._linear、 poly、rbf
excel取整函数_Excel中-年会必备,教你制作简易抽号系统-程序员宅基地
文章浏览阅读173次。【回顾敲黑板】先把上一期留下来的2个问题解决,这个抽号系统你就有思路了~1、如何让随机数变为整数?【答】使用int()函数,用法就是把:Rand()*10直接放到int()里,即:int(Rand()*10)2、如何去某个固定区间的随机数,比如【0-30】?【答】若要生成 a 与 b 之间的随机实数,应使用: RAND()*(b-a)+a,即RAND()*(30-0)+(0)。脑袋里是不是一团数学..._如何制作抽号
爬虫实战——爬取电影天堂的电影详情页信息_2、请使用不同的爬虫库爬取网站电影信息页面-程序员宅基地
文章浏览阅读2.8k次,点赞2次,收藏12次。爬取电影天堂的电影详情页信息_2、请使用不同的爬虫库爬取网站电影信息页面
hdu 5384 Danganronpa 2015多校联合训练赛#8 ac自动机_danganronpa多校-程序员宅基地
文章浏览阅读716次。DanganronpaTime Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others)Total Submission(s): 171 Accepted Submission(s): 83Problem DescriptionDanganronpa is_danganronpa多校
JavaScript开发工具WebStorm入门教程:用户界面概况_webstorm界面-程序员宅基地
文章浏览阅读1.7k次。本文给大家讲解WebStorm的界面展示,欢迎下载最新版产品体验!_webstorm界面