Oracle递归查询树形数据_oracle 树形结构递归查询-程序员宅基地
概述
实际生活有很多树形结构的数据,比如公司分为多个部门,部门下分为多个组,组下分为多个员工;省市县的归属;页面菜单栏等等。
如果想查询某个节点的父节点或者子节点,一般通过表自身连接完成,但如果该节点的子节点还有多层结构,就需要使用递归调用。但如果数据量特别大,递归的次数指数级上升,而且查询数据库的次数也指数级上升,导致程序和数据库压力剧增,查询时间特别长。那数据库有没有递归查询语句呢?答案是肯定的。
start with connect by prior 递归查询
1、数据准备
create table area_test(
id number(10) not null,
parent_id number(10),
name varchar2(255) not null
);
alter table area_test add (constraint district_pk primary key (id));
insert into area_test (ID, PARENT_ID, NAME) values (1, null, '中国');
insert into area_test (ID, PARENT_ID, NAME) values (11, 1, '河南省');
insert into area_test (ID, PARENT_ID, NAME) values (12, 1, '北京市');
insert into area_test (ID, PARENT_ID, NAME) values (111, 11, '郑州市');
insert into area_test (ID, PARENT_ID, NAME) values (112, 11, '平顶山市');
insert into area_test (ID, PARENT_ID, NAME) values (113, 11, '洛阳市');
insert into area_test (ID, PARENT_ID, NAME) values (114, 11, '新乡市');
insert into area_test (ID, PARENT_ID, NAME) values (115, 11, '南阳市');
insert into area_test (ID, PARENT_ID, NAME) values (121, 12, '朝阳区');
insert into area_test (ID, PARENT_ID, NAME) values (122, 12, '昌平区');
insert into area_test (ID, PARENT_ID, NAME) values (1111, 111, '二七区');
insert into area_test (ID, PARENT_ID, NAME) values (1112, 111, '中原区');
insert into area_test (ID, PARENT_ID, NAME) values (1113, 111, '新郑市');
insert into area_test (ID, PARENT_ID, NAME) values (1114, 111, '经开区');
insert into area_test (ID, PARENT_ID, NAME) values (1115, 111, '金水区');
insert into area_test (ID, PARENT_ID, NAME) values (1121, 112, '湛河区');
insert into area_test (ID, PARENT_ID, NAME) values (1122, 112, '舞钢市');
insert into area_test (ID, PARENT_ID, NAME) values (1123, 112, '宝丰市');
insert into area_test (ID, PARENT_ID, NAME) values (11221, 1122, '尚店镇');
2 start with connect by prior递归查询
start with子句:遍历起始条件。如果要查父结点,这里可以用子结点的列,反之亦然。connect by子句:连接条件。prior跟父节点列parentid放在一起,就是往父结点方向遍历;prior跟子结点列subid放在一起,则往叶子结点方向遍历。parent_id、id两列谁放在 “=” 前都无所谓,关键是prior跟谁在一起。order by子句:排序。
常用的select项:
LEVEL:级别
connect_by_root:根节点
sys_connect_by_path:递归路径
2.1 查询所有子节点
select t.*,LEVEL
from area_test t
start with name ='郑州市'
connect by prior id=parent_id

其实,如果单层结构,使用表自身连接也可以实现:
select * from area_test t1,area_test t2
where t1.ID = t2.PARENT_ID and t1.NAME='郑州市'

当查询节点下有多层数据:
select t.*,LEVEL
from area_test t
start with name ='河南省'
connect by prior id=parent_id
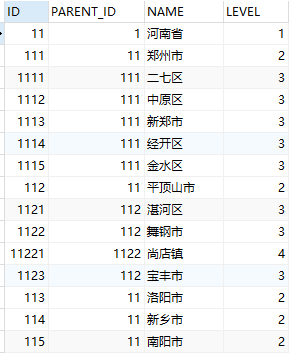
select * from area_test t1,area_test t2
where t1.PARENT_ID = t2.ID and t2.name='河南省';
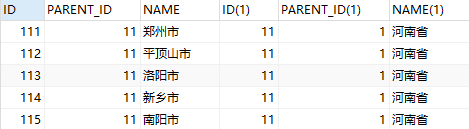
如果使用自身连接,也只能查到子一级节点的数据,需要遍历子一级节点,递归查询每个子一级节点下的子节点。明显麻烦很多!!!
2.2 查询所有父节点
select t.*,level
from area_test t
start with name ='郑州市'
connect by prior t.parent_id=t.id
order by level asc;

2.3 查询指定节点的根节点
select d.*,
connect_by_root(d.id) rootid,
connect_by_root(d.name) rootname
from area_test d
where name='二七区'
start with d.parent_id IS NULL
connect by prior d.id=d.parent_id

select d.*,
connect_by_root(d.id) rootid,
connect_by_root(d.name) rootname
from area_test d
start with d.parent_id IS NULL
connect by prior d.id=d.parent_id

2.4 查询下行政组织递归路径
select id, parent_id, name, sys_connect_by_path(name, '->') namepath, level
from area_test
start with name = '平顶山市'
connect by prior id = parent_id

3 with递归查询
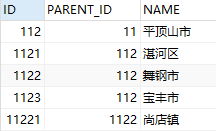
3.1 with递归子类
with tmp(id, parent_id, name)
as (
select id, parent_id, name
from area_test
where name = '平顶山市'
union all
select d.id, d.parent_id, d.name
from tmp, area_test d
where tmp.id = d.parent_id
)
select * from tmp;
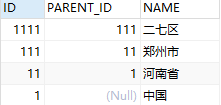
3.2 递归父类
with tmp(id, parent_id, name)
as
(
select id, parent_id, name
from area_test
where name = '二七区'
union all
select d.id, d.parent_id, d.name
from tmp, area_test d
where tmp.parent_id = d.id
)
select * from tmp;
4 MySQL 递归查找树形结构
参考文章:Oracle递归查询
智能推荐
Java创建对象的最佳方式:单例模式(Singleton)
单例模式是java中最简单的设计模式之一,属于创建式模式,提供了一种创建对象的最佳方式。具体而言,单例模式涉及到一个具体的类,这个类可以确保只有单个对象被创建。它包含一个访问其唯一对象的方法,供外部直接调用,而不需要创建这个类的示例。简而言之,可以不再new一个他的实例,而是直接调用方法。
基于STM32F103的增量式PI算法_通过pi控制算法得到的增量怎么转化为pwm的频率-程序员宅基地
文章浏览阅读2.7k次。增量式PI的程序百度一搜由算法可以看出,主要是误差参与运算,控制量可以理解为误差的累计和消除过程,比如第一次调节有误差1,第二次调节有误差2,误差2的出现说明第一次调节没有调整到给定值,控制量在第二次会改变,这样继续调节下去,调整到给定值时候,理论上是0了。比例积分系数和控制量的关系比例可认为是快速到达给定值积分可认为是消除稳态误差一般的系统,PI就够用了基本思路1初始化给定值,或是外部给予2实时采样被控对象3采样值与外部给予比较,并进行算法处理,得到控制量4由控_通过pi控制算法得到的增量怎么转化为pwm的频率
Ansible自动化运维工具主机清单配置
Ansible 提供了多种方式来定义和管理主机列表,除了默认的文件之外,您还可以使用自定义主机列表。这提供了更大的灵活性,允许您根据需要从不同来源获取主机信息。
堆栈的实现(C语言)_c语言堆栈-程序员宅基地
文章浏览阅读1.8k次,点赞6次,收藏36次。堆栈(stack)的基本概念堆栈是一种特殊的线性表,堆栈的数据元素及数据元素之间的逻辑关系和线性表完全相同,其差别是:线性表允许在任意位置插入和删除数据元素操作,而堆栈只允许在固定一端进行插入和删除数据元素操作。 堆栈中允许进行插入和删除数据元素操作的一端称为栈顶,另一端称为栈底。栈顶的当前位置是动态的,用于标记栈顶当前位置的变量称为栈顶指示器(或栈顶指针)。 堆栈的插入操作通常称为进栈或入栈,每次进栈的数据元素都放在原当前栈顶元素之前而成为新的栈顶元素。堆栈的删除操作通常称为出栈或退栈,每次出栈的_c语言堆栈
如何过滤敏感词免费文本敏感词检测接口API_违规关键词过滤api-程序员宅基地
文章浏览阅读1.6k次。敏感词过滤是随着互联网社区发展一起发展起来的一种阻止网络犯罪和网络暴力的技术手段,通过对可能存在犯罪或网络暴力可能的关键词进行有针对性的筛查和屏蔽,很多时候我们能够防患于未然,把后果严重的犯罪行为扼杀于萌芽之中。_违规关键词过滤api
ns3测吞吐量_ns3计算吞吐量-程序员宅基地
文章浏览阅读9.1k次,点赞2次,收藏42次。———————10月14日更—————————- 发现在goal-topo.cc中,由于Node#14被放在初始位置为0的地方,然后它会收到来自AP1和AP2的STA的OLSR消息(距离他们太近了吧)。 然而与goal-topo-trad.cc不同,goal-topo-trad.cc中Node#14可以在很远就跟自己的AP3通信,吞吐量比较稳定。而goal-topo.cc在开始的很长时间内并_ns3计算吞吐量
随便推点
ARFoundation系列讲解 - 39 AR看车六_arfoundation 关闭动画位移计算-程序员宅基地
文章浏览阅读1k次。十二、播放模型动画1.这里我们要做的是第一次点击中心按钮播放打开车门动画,第二次点击中心按钮关闭车门动画。2.新建一个脚本,命名为“AnimationManager.cs”。(代码如下)using System.Collections.Generic;using UnityEngine;/// <summary>动画管理</summary>public class AnimationManager : MonoBehaviour{ /// <s._arfoundation 关闭动画位移计算
Idea 运行spring项目 出现的bug_idea spring代理对象出bug-程序员宅基地
文章浏览阅读220次。Idea 运行spring项目 出现的bugbug 1错误信息:Cannot start compilation: the output path is not specified for module “02_primary”.Specify the output path in the Project Structure dialog.解决办法:..._idea spring代理对象出bug
JavaFx基础学习【四】:UI控件的通用属性_javafx教程-ui控件-程序员宅基地
文章浏览阅读1k次,点赞2次,收藏6次。Node,就是节点,在整体结构中,就是黄色那一块,红色也算个人理解,在实际中,Node可以说是我们的UI页面上的每一个节点了,比如按钮、标签之类的控件,而这些控件,大多都是有一些通用属性的,以下简单介绍一下。_javafx教程-ui控件
【嵌入式Linux】03-Ubuntu-文件系统结构_嵌入式linux使用ubuntu文件系统-程序员宅基地
文章浏览阅读136次。此笔记由个人整理塞上苍鹰_fly课程来自:正点原子_手把手教你学Linux一、文件系统结构g根目录:Linux下“/”就是根目录!所有的目录都是由根目录衍生出来的。/bin存放二进制可执行文件,这些命令在单用户模式下也能够使用。可以被root和一般的账号使用。/bootUbuntu内核和启动文件,比如vmlinuz-xxx。gurb引导装载程序。/dev设备驱动文件/etc存放一些系统配置文件,比如用户账号和密码文件,各种服务的起始地址。._嵌入式linux使用ubuntu文件系统
Win10黑屏卡死原因分析--罕见的内核pushlock死锁问题-程序员宅基地
文章浏览阅读2.1k次。此问题已向微软公司反馈,仅供学习参考这是微软内核的一个Bug.发生在内核函数 MmEnumerateAddressSpaceAndReferenceImages 和 MiCreateEnclave之间,如果时机不当会造成这两个函数之间死锁,而且还是一个pushlock死锁问题,十分罕见,这也是导致系统开机黑屏,系统突然卡死的元凶之一。Win10被骂了很久了,这次真的被我遇上了,系统无缘无故卡死_win10黑屏卡死原因分析--罕见的内核pushlock死锁问题
ie不支持java_巧用批处理解决IE不支持javascript等问题(转)-程序员宅基地
文章浏览阅读112次。巧用批处理解决IE不支持javascript等问题rem=====批处理开始========regsvr32actxprxy.dllregsvr32shdocvw.dllRegsvr32URLMON.DLLRegsvr32actxprxy.dllRegsvr32shdocvw.dllregsvr32oleaut32.dllrundll32.exeadvpack.dll/DelNo..._ie不支持javasript批处理