大数据学习笔记之azkaban(一):azkaban_azkaban executor.maxthreads-程序员宅基地
技术标签: 数据仓库
文章目录
一 概述
1.1为什么需要工作流调度系统
1)一个完整的数据分析系统通常都是由大量任务单元组成:
shell脚本程序,java程序,mapreduce程序、hive脚本等
2)各任务单元之间存在时间先后及前后依赖关系
3)为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行;
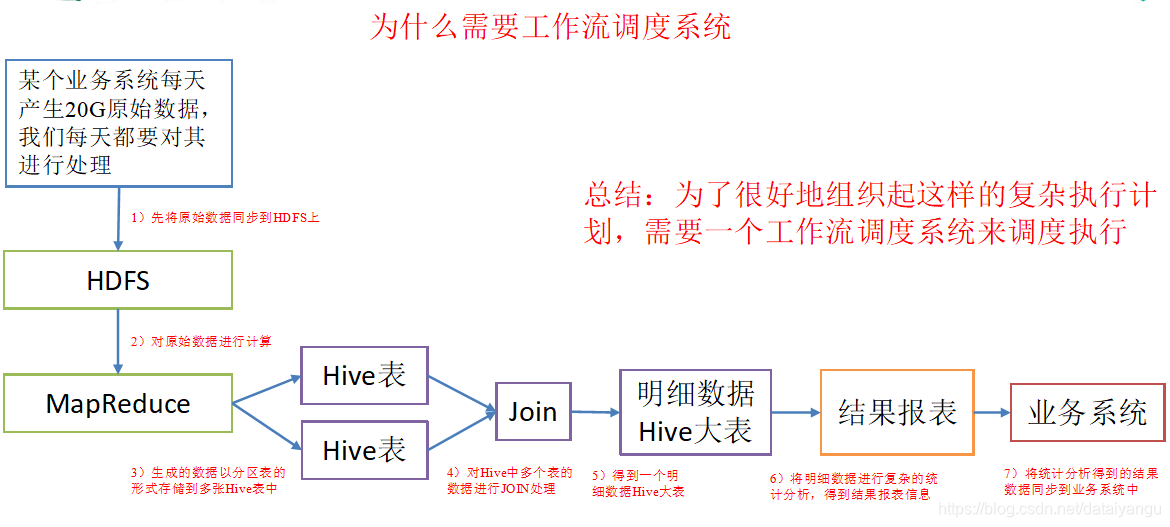
例如,我们可能有这样一个需求,某个业务系统每天产生20G原始数据,我们每天都要对其进行处理,处理步骤如下所示:
(1)通过Hadoop先将原始数据同步到HDFS上;
(2)借助MapReduce计算框架对原始数据进行计算,生成的数据以分区表的形式存储到多张Hive表中;
(3)需要对Hive中多个表的数据进行JOIN处理,得到一个明细数据Hive大表;
(4)将明细数据进行复杂的统计分析,得到结果报表信息;
(5)需要将统计分析得到的结果数据同步到业务系统中,供业务调用使用。
1.2 常见工作流调度系统
1)简单的任务调度:直接使用linux的crontab来定义;
2)复杂的任务调度:开发调度平台或使用现成的开源调度系统,比如ooize、azkaban、 Cascading、Hamake等
1.3 各种调度工具特性对比
下面的表格对上述四种hadoop工作流调度器的关键特性进行了比较,尽管这些工作流调度器能够解决的需求场景基本一致,但在设计理念,目标用户,应用场景等方面还是存在显著的区别,在做技术选型的时候,可以提供参考
| 特性 | Hamake | Oozie | Azkaban | Cascading |
|---|---|---|---|---|
| 工作流描述语言 | XML | XML (xPDL based) | text file with key/value pairs | Java API |
| 依赖机制 | data-driven | explicit | explicit | explicit |
| 是否要web容器 | No | Yes | Yes | No |
| 进度跟踪 | console/log messages | web page | web page | Java API |
| Hadoop job调度支持 | no | yes | yes | yes |
| 运行模式 | command line utility | daemon | daemon | API |
| Pig支持 | yes | yes | yes | yes |
| 事件通知 | no | no | no | yes |
| 需要安装 | no | yes | yes | no |
| 支持的hadoop版本 | 0.18+ | 0.20+ | currently unknown | 0.18+ |
| 重试支持 | no | workflownode evel | yes | yes |
| 运行任意命令 | yes | yes | yes | yes |
| Amazon EMR支持 | yes | no | currently unknown | yes |
1.4 Azkaban与Oozie对比
对市面上最流行的两种调度器,给出以下详细对比,以供技术选型参考。总体来说,ooize相比azkaban是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器azkaban是很不错的候选对象。
详情如下:
1)功能
两者均可以调度mapreduce,pig,java,脚本工作流任务
两者均可以定时执行工作流任务
2)工作流定义
Azkaban使用Properties文件定义工作流
Oozie使用XML文件定义工作流
3)工作流传参
Azkaban支持直接传参,例如 i n p u t O o z i e 支 持 参 数 和 E L 表 达 式 , 例 如 i n p u t O o z i e 支 持 参 数 和 E L 表 达 式 , 例 如 i n p u t O o z i e 支 持 参 数 和 E L 表 达 式 , 例 如 inputOozie支持参数和EL表达式,例如inputOozie支持参数和EL表达式,例如 {input}Oozie支持参数和EL表达式,例如 inputOozie支持参数和EL表达式,例如inputOozie支持参数和EL表达式,例如inputOozie支持参数和EL表达式,例如inputOozie支持参数和EL表达式,例如{fs:dirSize(myInputDir)}
4)定时执行
Azkaban的定时执行任务是基于时间的
Oozie的定时执行任务基于时间和输入数据
5)资源管理
Azkaban有较严格的权限控制,如用户对工作流进行读/写/执行等操作
Oozie暂无严格的权限控制
6)工作流执行
Azkaban有两种运行模式,分别是solo server mode(executor server和web server部署在同一台节点)和multi server mode(executor server和web server可以部署在不同节点)
Oozie作为工作流服务器运行,支持多用户和多工作流
7)工作流管理
Azkaban支持浏览器以及ajax方式操作工作流
Oozie支持命令行、HTTP REST、Java API、浏览器操作工作流
二 Azkaban介绍
Azkaban是由Linkedin开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
它有如下功能特点:
1)Web用户界面
2)方便上传工作流
3)方便设置任务之间的关系
4)调度工作流
5)认证/授权(权限的工作)
6)能够杀死并重新启动工作流
7)模块化和可插拔的插件机制
8)项目工作区
9)工作流和任务的日志记录和审计
下载地址:http://azkaban.github.io/downloads.html
三 Azkaban安装部署
3.1 安装前准备
1)将Azkaban Web服务器、Azkaban执行服务器和MySQL拷贝到hadoop102虚拟机/opt/software目录下
azkaban-web-server-2.5.0.tar.gz
azkaban-executor-server-2.5.0.tar.gz
azkaban-sql-script-2.5.0.tar.gz
mysql-libs.zip
2)目前azkaban只支持 mysql,需安装mysql服务器,本文档中默认已安装好mysql服务器,并建立了 root用户,密码 root。
3.2安装azkaban
1)在/opt/module/目录下创建azkaban目录
[atguigu@hadoop102 module]$ mkdir azkaban
2)解压azkaban-web-server-2.5.0.tar.gz、azkaban-executor-server-2.5.0.tar.gz、azkaban-sql-script-2.5.0.tar.gz到/opt/module/azkaban目录下
[atguigu@hadoop102 software]$ tar -zxvf azkaban-web-server-2.5.0.tar.gz -C /opt/module/azkaban/
[atguigu@hadoop102 software]$ tar -zxvf azkaban-executor-server-2.5.0.tar.gz -C /opt/module/azkaban/
[atguigu@hadoop102 software]$ tar -zxvf azkaban-sql-script-2.5.0.tar.gz -C /opt/module/azkaban/
3)对解压后的文件重新命名
[atguigu@hadoop102 azkaban]$ mv azkaban-web-2.5.0/ server
[atguigu@hadoop102 azkaban]$ mv azkaban-executor-2.5.0/ executor
4)azkaban脚本导入
进入mysql,创建azkaban数据库,并将解压的脚本导入到azkaban数据库。
[atguigu@hadoop102 azkaban]$ mysql -uroot -p000000
mysql> create database azkaban;
mysql> use azkaban;
mysql> source /opt/module/azkaban/azkaban-2.5.0/create-all-sql-2.5.0.sql
3.2 创建SSL配置
参考地址: http://docs.codehaus.org/display/JETTY/How+to+configure+SSL
1)生成 keystore的密码及相应信息
[atguigu@hadoop102 hadoop-2.7.2]$ keytool -keystore keystore -alias jetty -genkey -keyalg RSA
输入keystore密码:
再次输入新密码:
您的名字与姓氏是什么?
[Unknown]:
您的组织单位名称是什么?
[Unknown]:
您的组织名称是什么?
[Unknown]:
您所在的城市或区域名称是什么?
[Unknown]:
您所在的州或省份名称是什么?
[Unknown]:
该单位的两字母国家代码是什么
[Unknown]: CN
CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=CN 正确吗?
[否]: y
输入的主密码
(如果和 keystore 密码相同,按回车):
再次输入新密码:
2)将keystore 考贝到 azkaban web服务器根目录中
[atguigu@hadoop102 hadoop-2.7.2]$ mv keystore /opt/module/azkaban/server/
3.3 时间同步配置
先配置好服务器节点上的时区
1)如果在/usr/share/zoneinfo/这个目录下不存在时区配置文件Asia/Shanghai,就要用 tzselect 生成。
[atguigu@hadoop102 Asia]$ tzselect
Please identify a location so that time zone rules can be set correctly.
Please select a continent or ocean.
- Africa
- Americas
- Antarctica
- Arctic Ocean
- Asia
- Atlantic Ocean
- Australia
- Europe
- Indian Ocean
- Pacific Ocean
- none - I want to specify the time zone using the Posix TZ format.
#? 5
Please select a country. - Afghanistan 18) Israel 35) Palestine
- Armenia 19) Japan 36) Philippines
- Azerbaijan 20) Jordan 37) Qatar
- Bahrain 21) Kazakhstan 38) Russia
- Bangladesh 22) Korea (North) 39) Saudi Arabia
- Bhutan 23) Korea (South) 40) Singapore
- Brunei 24) Kuwait 41) Sri Lanka
- Cambodia 25) Kyrgyzstan 42) Syria
- China 26) Laos 43) Taiwan
- Cyprus 27) Lebanon 44) Tajikistan
- East Timor 28) Macau 45) Thailand
- Georgia 29) Malaysia 46) Turkmenistan
- Hong Kong 30) Mongolia 47) United Arab Emirates
- India 31) Myanmar (Burma) 48) Uzbekistan
- Indonesia 32) Nepal 49) Vietnam
- Iran 33) Oman 50) Yemen
- Iraq 34) Pakistan
#? 9
Please select one of the following time zone regions. - Beijing Time
- Xinjiang Time
#? 1
The following information has been given:
China
Beijing Time
Therefore TZ=‘Asia/Shanghai’ will be used.
Local time is now: Wed Jun 14 09:16:46 CST 2017.
Universal Time is now: Wed Jun 14 01:16:46 UTC 2017.
Is the above information OK? - Yes
- No
#?1
2)拷贝该时区文件,覆盖系统本地时区配置
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
3)集群时间同步
sudo date -s ‘2017-06-14 09:23:45’
hwclock -w
3.4 配置文件
3.4.1 Web服务器配置
1)进入azkaban web服务器安装目录 conf目录,打开azkaban.properties文件
[atguigu@hadoop102 conf]$ pwd
/opt/module/azkaban/server/conf
[atguigu@hadoop102 conf]$ vi azkaban.properties
2)按照如下配置修改azkaban.properties文件。
#Azkaban Personalization Settings
azkaban.name=Test #服务器UI名称,用于服务器上方显示的名字
azkaban.label=My Local Azkaban #描述
azkaban.color=#FF3601 #UI颜色
azkaban.default.servlet.path=/index #
web.resource.dir=web/ #默认根web目录
default.timezone.id=Asia/Shanghai #默认时区,已改为亚洲/上海 默认为美国
#Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager #用户权限管理默认类
user.manager.xml.file=conf/azkaban-users.xml #用户配置,具体配置参加下文
#Loader for projects
executor.global.properties=conf/global.properties # global配置文件所在位置
azkaban.project.dir=projects #
database.type=mysql #数据库类型
mysql.port=3306 #端口号
mysql.host=hadoop102 #数据库连接IP
mysql.database=azkaban #数据库实例名
mysql.user=root #数据库用户名
mysql.password=000000 #数据库密码
mysql.numconnections=100 #最大连接数
#Velocity dev mode
velocity.dev.mode=false
#Jetty服务器属性.
jetty.maxThreads=25 #最大线程数
jetty.ssl.port=8443 #Jetty SSL端口
jetty.port=8081 #Jetty端口
jetty.keystore=keystore #SSL文件名
jetty.password=000000 #SSL文件密码
jetty.keypassword=000000 #Jetty主密码 与 keystore文件相同
jetty.truststore=keystore #SSL文件名
jetty.trustpassword=000000 # SSL文件密码
#执行服务器属性
executor.port=12321 #执行服务器端口
#邮件设置
[email protected] #发送邮箱
mail.host=smtp.163.com #发送邮箱smtp地址
mail.user=xxxxxxxx #发送邮件时显示的名称
mail.password=********** #邮箱密码
[email protected] #任务失败时发送邮件的地址
[email protected] #任务成功时发送邮件的地址
lockdown.create.projects=false #
cache.directory=cache #缓存目录
2)web服务器用户配置
在azkaban web服务器安装目录 conf目录,按照如下配置修改azkaban-users.xml 文件,增加管理员用户。
3.4.2 执行服务器配置
1)进入执行服务器安装目录conf,打开azkaban.properties
[atguigu@hadoop102 conf]$ pwd
/opt/module/azkaban/executor/conf
[atguigu@hadoop102 conf]$ vi azkaban.properties
2)按照如下配置修改azkaban.properties文件。
#Azkaban
default.timezone.id=Asia/Shanghai #时区
#Azkaban JobTypes 插件配置
azkaban.jobtype.plugin.dir=plugins/jobtypes #jobtype 插件所在位置
#Loader for projects
executor.global.properties=conf/global.properties
azkaban.project.dir=projects
#数据库设置
database.type=mysql #数据库类型(目前只支持mysql)
mysql.port=3306 #数据库端口号
mysql.host=192.168.20.200 #数据库IP地址
mysql.database=azkaban #数据库实例名
mysql.user=root #数据库用户名
mysql.password=000000 #数据库密码
mysql.numconnections=100 #最大连接数
#执行服务器配置
executor.maxThreads=50 #最大线程数
executor.port=12321 #端口号(如修改,请与web服务中一致)
executor.flow.threads=30 #线程数
3.4 启动web服务器
在azkaban web服务器目录下执行启动命令
[atguigu@hadoop102 server]$ pwd
/opt/module/azkaban/server
[atguigu@hadoop102 server]$ bin/azkaban-web-start.sh
bin/azkaban-web-start.sh
3.5 启动执行服务器
在执行服务器目录下执行启动命令
[atguigu@hadoop102 executor]$ pwd
/opt/module/azkaban/executor
[atguigu@hadoop102 executor]$ bin/azkaban-executor-start.sh
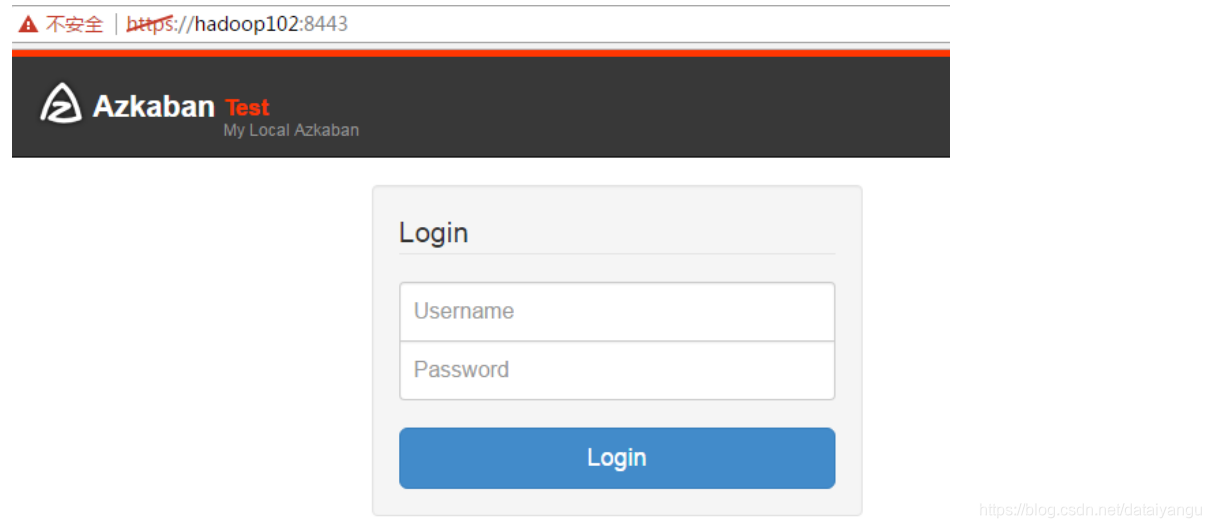
启动完成后,在浏览器(建议使用谷歌浏览器)中输入https://服务器IP地址:8443,即可访问azkaban服务了。在登录中输入刚才新的户用名及密码,点击 login。
四 Azkaban实战
Azkaba内置的任务类型支持command、java
4.1Command类型之单一job案例
1)创建job描述文件
vi command.job
#command.job
type=command
command=echo ‘hello’
2)将job资源文件打包成zip文件
3)通过azkaban的web管理平台创建project并上传job压缩包
首先创建project
上传zip包
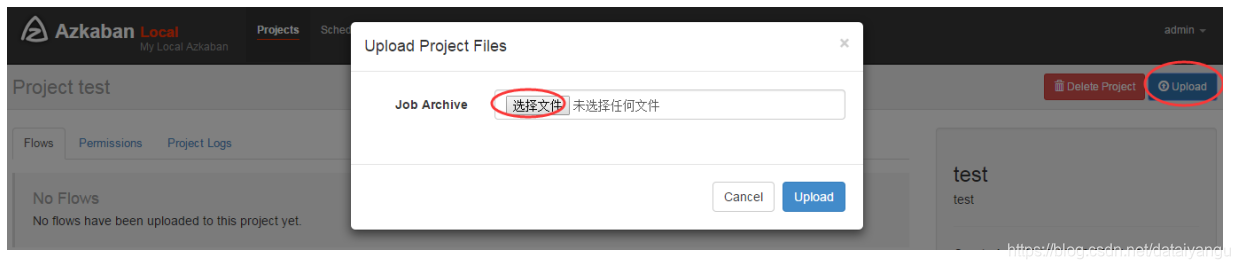
4)启动执行该job

4.2Command类型之多job工作流案例
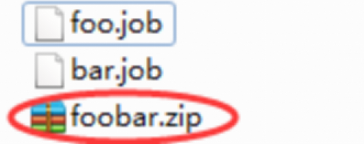
1)创建有依赖关系的多个job描述
第一个job:foo.job
#foo.job
type=command
command=echo foo
第二个job:bar.job依赖foo.job
#bar.job
type=command
dependencies=foo
command=echo bar
2)将所有job资源文件打到一个zip包中
3)创建工程
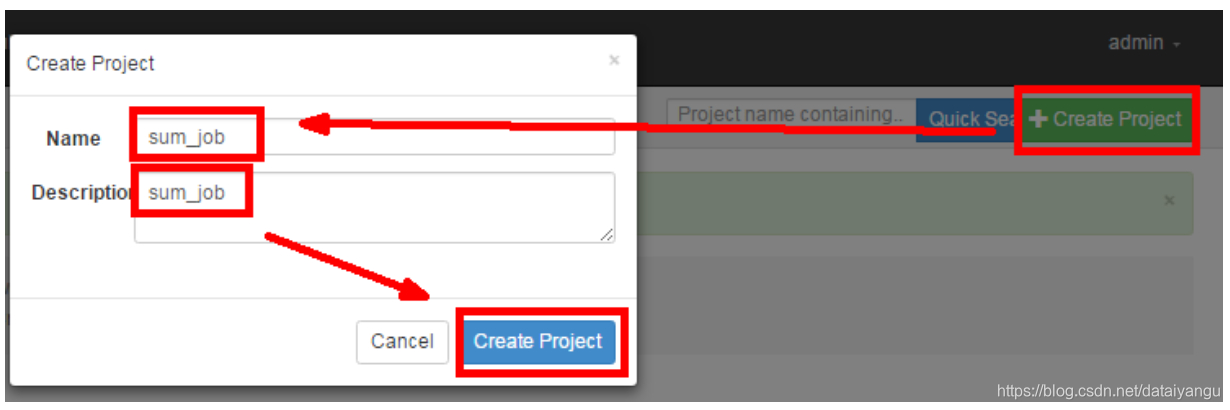
3)在azkaban的web管理界面创建工程并上传zip包
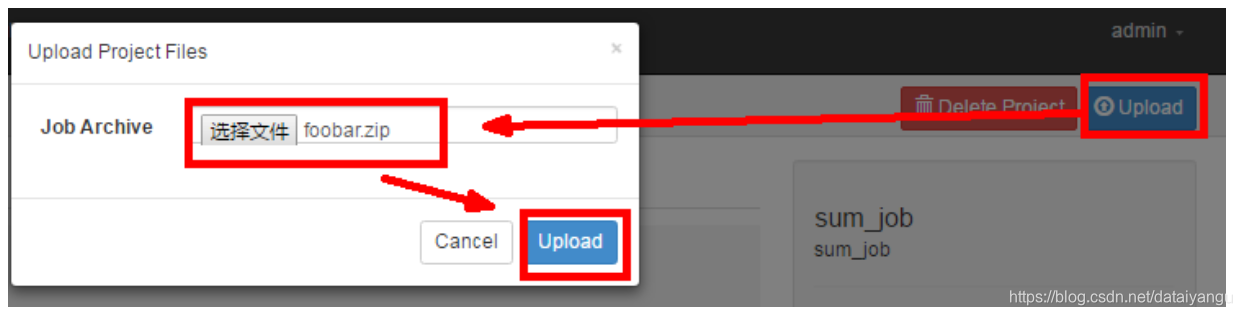
4)启动工作流flow
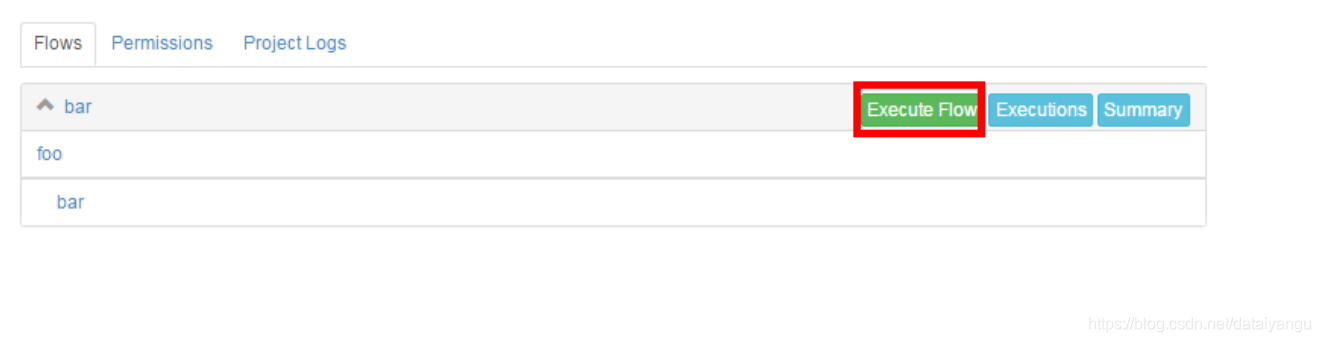
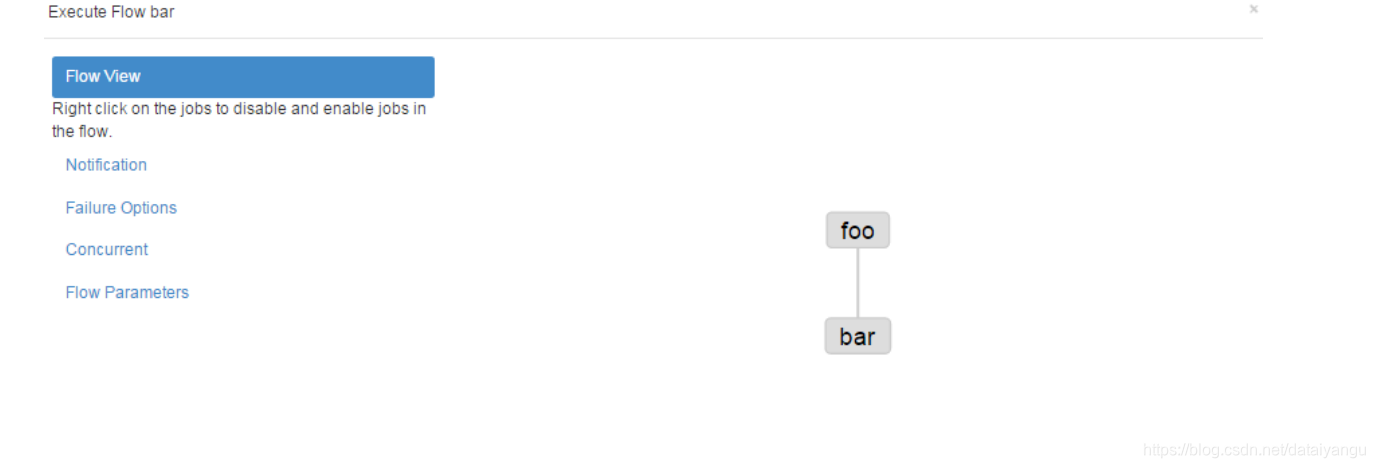
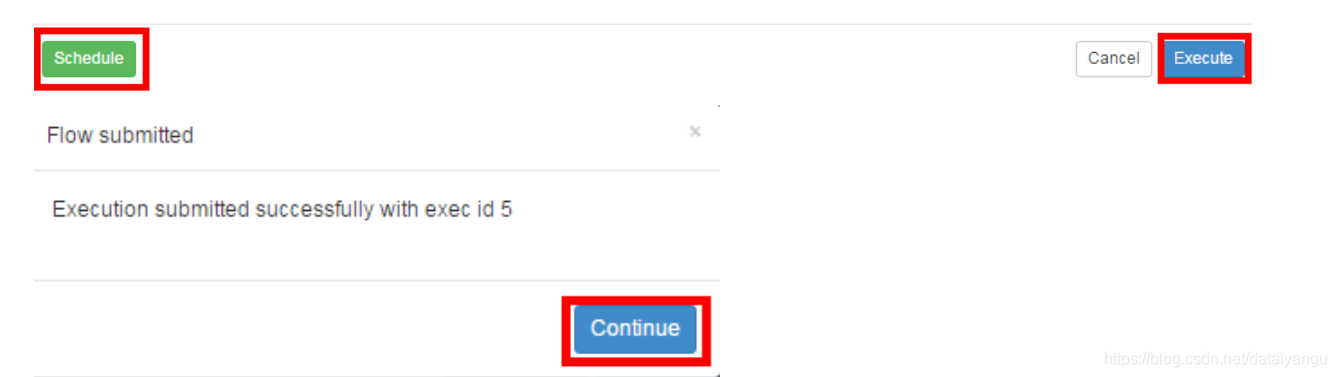
5)查看结果

4.3HDFS操作任务
1)创建job描述文件
#fs.job
type=command
command=/opt/module/hadoop-2.7.2/bin/hadoop fs -mkdir /azkaban
2)将job资源文件打包成zip文件
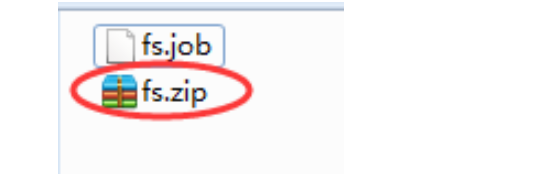
3)通过azkaban的web管理平台创建project并上传job压缩包
4)启动执行该job
5)查看结果
4.4 MapReduce任务
Mr任务依然可以使用command的job类型来执行
1)创建job描述文件,及mr程序jar包(示例中直接使用hadoop自带的example jar)
#mrwc.job
type=command
command=/opt/module/hadoop-2.7.2/bin/hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount /wordcount/input /wordcount/output
2)将所有job资源文件打到一个zip包中
3)在azkaban的web管理界面创建工程并上传zip包
4)启动job
4.4HIVE脚本任务
1)创建job描述文件和hive脚本
(1)Hive脚本: test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ‘,’;
load data inpath ‘/aztest/hiveinput’ into table aztest;
create table azres as select * from aztest;
insert overwrite directory ‘/aztest/hiveoutput’ select count(1) from aztest;
(2)Job描述文件:hivef.job
#hivef.job
type=command
command=/opt/module/hive/bin/hive -f ‘test.sql’
2)将所有job资源文件打到一个zip包中
3)在azkaban的web管理界面创建工程并上传zip包
4)启动job
</div><div data-report-view="{"mod":"1585297308_001","dest":"https://blog.csdn.net/dataiyangu/article/details/97621133","extend1":"pc","ab":"new"}"><div></div></div>
<link href="https://csdnimg.cn/release/phoenix/mdeditor/markdown_views-60ecaf1f42.css" rel="stylesheet">
</div>
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法