使用ip代理池爬取中国高校百度百科(Ajax加载)_ajax实现ip代理-程序员宅基地
最近接了一个任务,爬取中国高校的百度百科,记录其信息以及图片并存入MySQL中。
第一步,分析网页,并尝试获取每个学校对应的URL
点进去以后猜测是Ajax加载的网页(鼠标滚轮往下滚的同时加载出新的内容,并且没有改变URL)
为了验证猜测,打开chrome开发者工具(右击,检查)
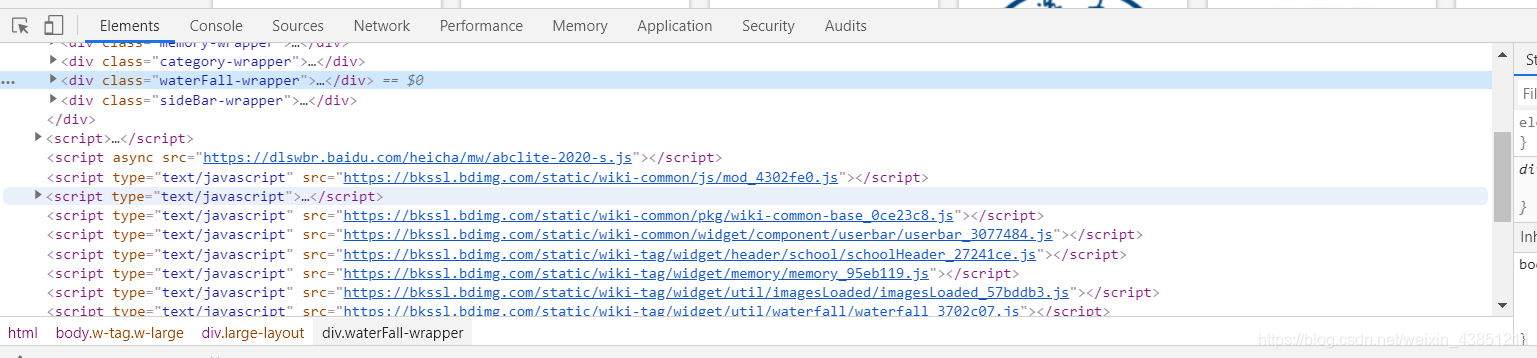
点击‘Network’,检查网页在动态加载过程中发送的请求

Ajax请求一般都能在‘XHR栏目中找到’
保持打开开发者工具,将鼠标一直往下滚动,可以发现在不断加载出新内容的同时,浏览器一直在发送名叫getlemmas的请求

猜测正确,确实是Ajax加载的网页
中国高校信息百度百科网页的url是‘https://baike.baidu.com/wikitag/taglist?tagId=60829’
但是如果单单请求这个url,我们只能得到第一页的内容,仅仅三十条高校信息,而实际上一共有两千五百多条信息
所以,想要爬取每个页面的信息,就要找到每个页面对应的url
随便点击一个getlemmas的请求,能看到如下界面

从Request URL中我们得到了这些请求真正访问的网页的url:‘https://baike.baidu.com/wikitag/api/getlemmas’
但是我们在浏览器中输入这个url并回车的时候会发现根本无法访问
这是因为在访问的时候缺少了某些参数,我们继续探究getlemmas的请求的界面

在底部,我们发现了一些参数。切换getlemmas请求,发现改变的值只有page。可以轻易地发现,page代表的就是访问的页数,一直往下翻翻到底,一共有81页。显然的,在我们请求该网页的时候需要带上这些参数
同时注意,该网页的请求方式不是get,而是post

那么,获取源码的代码就可以写出来了
for i in range(1, 82):#一共有81页
params = {
'limit': '30',
'timeout': '3000',
'filterTags': '[0,0,0,0,0,0,0]',
'tagId': '60829',
'fromLemma': 'false',
'contentLength': '40',
'page': str(i)
}
r = requests.post('https://baike.baidu.com/wikitag/api/getlemmas', headers=headers, data=params)#注意是post形式
json_ans = r.json()#返回json数据,并对json数据进行解析。当然,返回text数据并用etree来解析也是一样的效果
for i in range(0, 30):#每个页面有30所学校
sc_url = json_ans['lemmaList'][i]['lemmaUrl']
try:
spider_detail(sc_url)#爬取每个学校的详细信息。该函数的代码会出现在后面
except AttributeError:#防止异常中断程序
print('err')
pass
就这样,我们完成了第一步,获取每个学校的URL,下面,我们进行对每个学校信息的爬取
第二部,根据每个学校对应的URL,获取其信息
这一步难度不是很大,注意xpath书写的正确性,想要的信息就都能得到
但是要注意,某些学校缺少一些信息(如有些学校有显示官方网址,而有些网站没有),这样进行xpath定位的时候就会报错.但是我们又想尽量多地爬到信息,所以就在每个信息上都设置了异常处理,如果找不到对应的xpath,就把该信息设置成‘无’
下面是代码
def spider_detail(url):
selector = download(url)
try:
name = selector.xpath('string(//*[@class="lemmaWgt-lemmaTitle-title"]/h1)')
except IndexError:
name = '无'
infor = selector.xpath('string(//*[@class="lemma-summary"])')
time = selector.xpath('string(//*[@class="dl-baseinfo"]/dl/dd)')
try:
species = selector.xpath('string(//*[@class="dl-baseinfo"][2]/dl/dd)')
except IndexError:
species = '无'
try:
attribute = selector.xpath('//*[@class="dl-baseinfo"]/dl[2]/dd/@title')[0]
except IndexError:
attribute = '无'
try:
sc_friend = selector.xpath('//*[@class="dl-baseinfo"]/dl[2]/dd/@title')[1]
except IndexError:
sc_friend = '无'
try:
agent = selector.xpath('string(//*[@class="dl-baseinfo"]/dl[3]/dd)')
except IndexError:
agent = '无'
try:
offical_url = selector.xpath('//*[@class=" bottomLine"]/dd/@title')[1]
except IndexError:
offical_url = '无'
try:
pic = selector.xpath('//*[@class="summary-pic"]/a/img/@src')[0]
xx = download_pic(name, pic)
except IndexError:
xx = '无'
write_in_sql(name, infor, time, species, attribute + '\n', sc_friend, agent, offical_url, xx)
download函数是自己写的,就是通过请求网页的url返回其源码
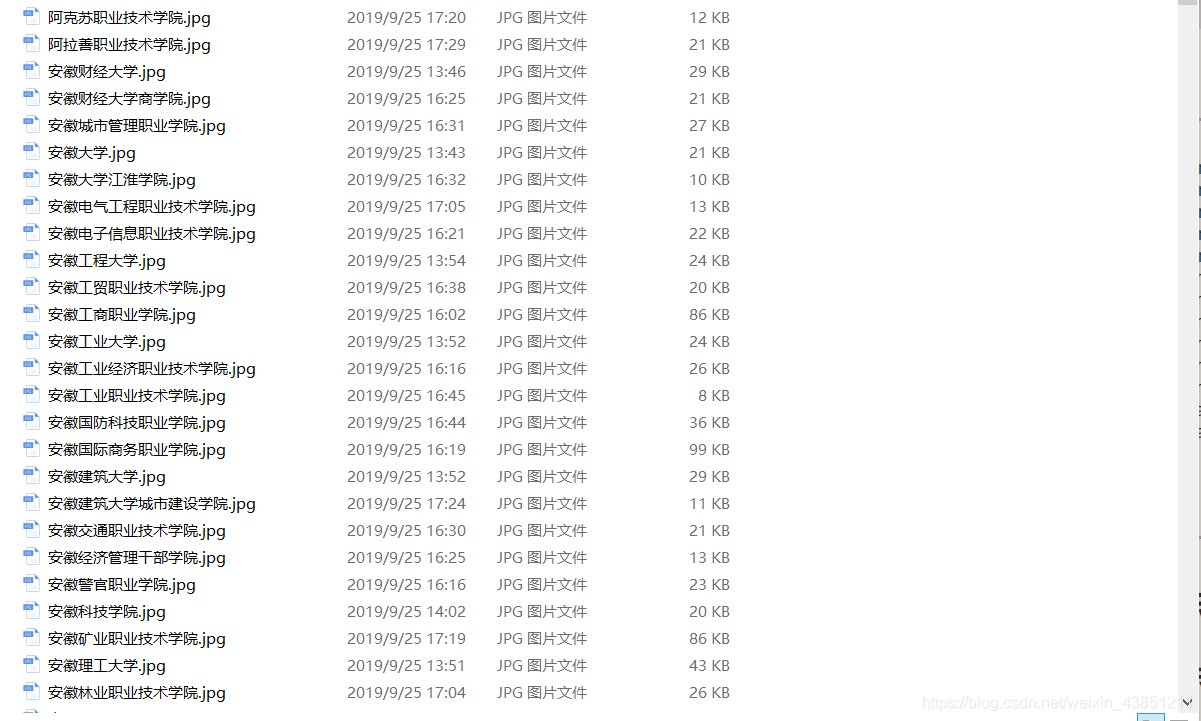
根据要求,图片要单独保存在某个文件夹中,于是写了download_pic函数
其他信息写入SQL server,所以写了write_in_sql函数
这些函数会在后面贴出来,这部分主要就是获取信息
这个时候,爬虫已经可以运行了。但是因为没有更换ip和访问频率的问题,容易被对方服务器检查出来,所以进入第三部分。
第三步,优化代码,使用IP池,并添加报错处理机制
这个时候就需要使用更换ip。但是单一的代理无法完成两千多个网页的爬取,手动收集的话效率又太低。于是这个时候就需要用到ip代理池
关于代理池的问题,可以直接在百度上找(如快代理),也可以在淘宝上搜索,商家都能提供高匿代理
第一次使用ip代理池,废了好大劲,回头来发现其实是很简单的事情。小伙伴们可以自己先试试,有问题联系我鸭(大佬走开!!)
这里要注意的是在使用代理池时需要配套使用动态 UA,不然同样可能出错。联系商家,他们应该会提供UA给你
使用代理池之后爬虫不会那么容易被服务器检查出来啦,但是由于访问频率的问题,服务器仍然有可能将你判定为爬虫。当我们的代码因为访问被拒绝而报错时,前面辛辛苦苦爬的内容就都浪费了。所以,我们需要一个报错处理机制,当因为访问频率问题被拒绝访问时,代码不应该直接报错退出爬取,而是等待一段时间以后继续爬取,这样,就不用怕功亏一篑啦
下面是代码
def download(targetUrl):
proxyHost = 'u3462.b5.t.16yun.cn'
proxyPort = "6460"
# 代理隧道验证信息
proxyUser = "16AOTZQK"
proxyPass = "860038"
proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host": proxyHost,
"port": proxyPort,
"user": proxyUser,
"pass": proxyPass,
}
# 设置 http和https访问都是用HTTP代理
proxies = {
"http": proxyMeta,
"https": proxyMeta,
}
# 设置IP切换头
tunnel = random.randint(1, 10000)
headers = {"Proxy-Tunnel": str(tunnel),
'User-Agent': ua_list[random.randint(0, 9)],
'Connection': 'close'}
while(1):
try:
resp = requests.get(targetUrl, proxies=proxies, headers=headers)
time.sleep(2)
resp.encoding = 'utf-8'
return etree.HTML(resp.text)
except :
print('sleep 10 s')
time.sleep(10)
continue
现在,我们已经能成功地爬到想要的信息了。注意如果没有设置多协程,爬取时间会较长,千万不要让电脑休眠了,不然代码就会停下来
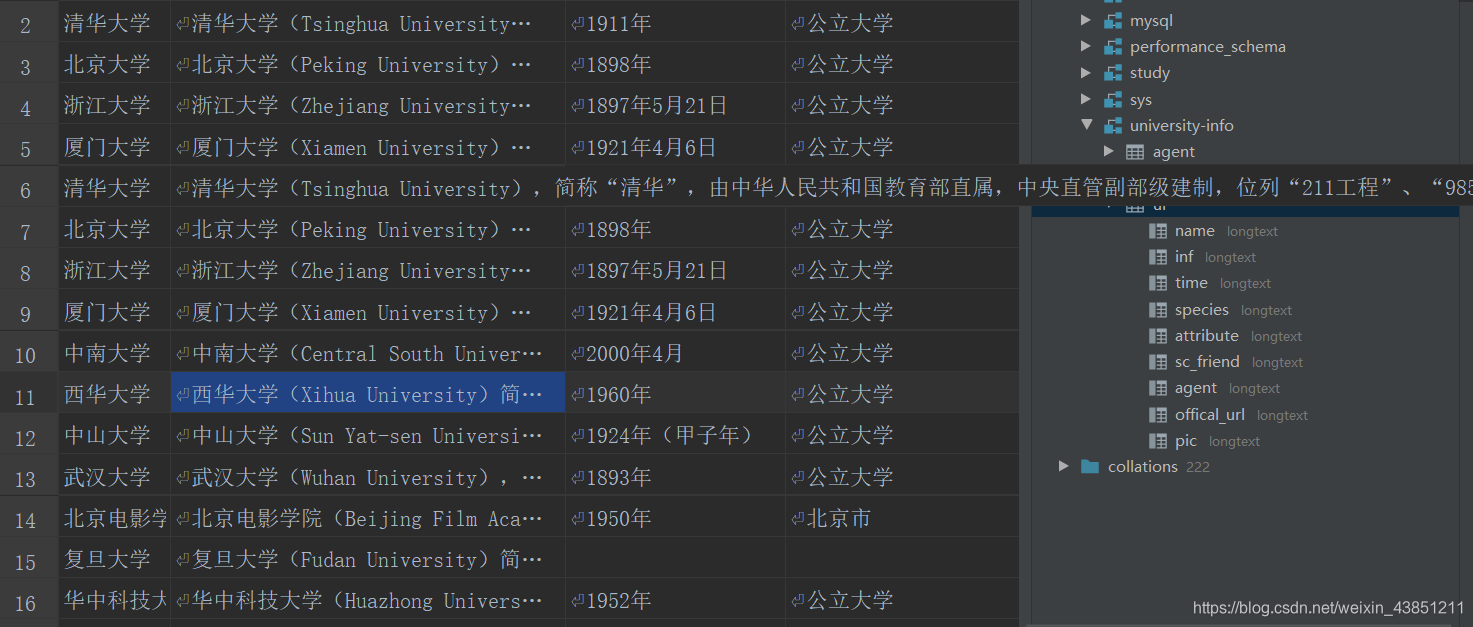
那么,只剩最后一步,将爬到的信息写入MySQL中了
第四步,将信息写入数据库
def write_in_sql(name, infor, time, species, attribute, sc_friend, agent, offical_url, xx):
db = pymysql.connect(host="*****", port=10136, user="*****", passwd="*****", db="university-info")
cursor = db.cursor()
sql = """INSERT INTO ui VALUE ('%s','%s','%s','%s','%s','%s','%s','%s','%s')""" % (name, infor, time, species, attribute, sc_friend, agent, offical_url, xx)
try:
cursor.execute(sql)
db.commit()
print('正在爬取:'+name)
db.close()
except pymysql.err.ProgrammingError:
print('error')
pass
那么到此为止任务就完成了,下面贴出全部代码,仅供跟我一样的萌新参考,大佬就笑着看看就行了
import requests
from lxml import etree
import random
from string import punctuation
import re
import time
import pymysql
ua_list = ['Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US; rv:1.9.2.3) Gecko/20100401 Firefox/3.6.3 GTB6 (.NET CLR 3.5.30729)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:26.0) Gecko/20100101 Firefox/26.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.120 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.115 Safari/537.36',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0; en-US; .NET CLR 1.0.3328)',
'Mozilla/5.0 (Windows NT x.y; rv:10.0) Gecko/20100101 Firefox/10.0',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 7.1; Trident/5.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)'
]
def download(targetUrl):
proxyHost = 'u3462.b5.t.16yun.cn'
proxyPort = "6460"
# 代理隧道验证信息
proxyUser = "16AOTZQK"
proxyPass = "860038"
proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host": proxyHost,
"port": proxyPort,
"user": proxyUser,
"pass": proxyPass,
}
# 设置 http和https访问都是用HTTP代理
proxies = {
"http": proxyMeta,
"https": proxyMeta,
}
# 设置IP切换头
tunnel = random.randint(1, 10000)
headers = {"Proxy-Tunnel": str(tunnel),
'User-Agent': ua_list[random.randint(0, 9)],
'Connection': 'close'}
while(1):
try:
resp = requests.get(targetUrl, proxies=proxies, headers=headers)
time.sleep(2)
resp.encoding = 'utf-8'
return etree.HTML(resp.text)
except :
print('sleep 10 s')
time.sleep(10)
continue
def write_in_sql(name, infor, time, species, attribute, sc_friend, agent, offical_url, xx):
db = pymysql.connect(host="xxxxx", port=xxxxx, user="root", passwd="xxxxx", db="university-info")
cursor = db.cursor()
sql = """INSERT INTO ui VALUE ('%s','%s','%s','%s','%s','%s','%s','%s','%s')""" % (name, infor, time, species, attribute, sc_friend, agent, offical_url, xx)
try:
cursor.execute(sql)
db.commit()
print('正在爬取:'+name)
db.close()
except pymysql.err.ProgrammingError:
print('error')
pass
def download_pic(name, url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
r = requests.get(url).content
path = 'E:\Download\pic\\' + name + '.jpg'
with open(path, 'wb') as f:
f.write(r)
return path
def spider_detail(url):
selector = download(url)
try:
name = selector.xpath('string(//*[@class="lemmaWgt-lemmaTitle-title"]/h1)')
except IndexError:
name = '无'
infor = selector.xpath('string(//*[@class="lemma-summary"])')
time = selector.xpath('string(//*[@class="dl-baseinfo"]/dl/dd)')
try:
species = selector.xpath('string(//*[@class="dl-baseinfo"][2]/dl/dd)')
except IndexError:
species = '无'
try:
attribute = selector.xpath('//*[@class="dl-baseinfo"]/dl[2]/dd/@title')[0]
except IndexError:
attribute = '无'
try:
sc_friend = selector.xpath('//*[@class="dl-baseinfo"]/dl[2]/dd/@title')[1]
except IndexError:
sc_friend = '无'
try:
agent = selector.xpath('string(//*[@class="dl-baseinfo"]/dl[3]/dd)')
except IndexError:
agent = '无'
try:
offical_url = selector.xpath('//*[@class=" bottomLine"]/dd/@title')[1]
except IndexError:
offical_url = '无'
try:
pic = selector.xpath('//*[@class="summary-pic"]/a/img/@src')[0]
xx = download_pic(name, pic)
except IndexError:
xx = '无'
write_in_sql(name, infor, time, species, attribute + '\n', sc_friend, agent, offical_url, xx)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'Referer': 'https://baike.baidu.com/wikitag/taglist?tagId=60829',
'Cookie': 'BAIDUID=EC95F5E6FCDA1C64E019CD2D2B1EA6D7:FG=1; BIDUPSID=EC95F5E6FCDA1C64E019CD2D2B1EA6D7; PSTM=1566982298; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; Hm_lvt_55b574651fcae74b0a9f1cf9c8d7c93a=1566996146,1568346698,1569165138,1569213110; pgv_pvi=7965312000'
}
for i in range(1, 82):
params = {
'limit': '30',
'timeout': '3000',
'filterTags': '[0,0,0,0,0,0,0]',
'tagId': '60829',
'fromLemma': 'false',
'contentLength': '40',
'page': str(i)
}
r = requests.post('https://baike.baidu.com/wikitag/api/getlemmas', headers=headers, data=params)
json_ans = r.json()
for i in range(0, 30):
sc_url = json_ans['lemmaList'][i]['lemmaUrl']
try:
spider_detail(sc_url)
except AttributeError:
print('err')
pass
第五步,总结和思考
希望有朋友能多多跟我交流鸭
这篇博客我写了好久,应该是自己第一篇认认真真写的博客了,希望看到的朋友们能指出我的错误和不足,给我这个新手提供一些意见和建议~
其实是一个非常简单和基本的任务,因为经验不足,我做了一天半才做完。主要是对ip代理池的不熟练,对报错的处理能力不够及对MySQL的基本操作不是特别熟练造成的
因为对多协程的不熟练,同时任务时间又比较赶,代码中就没有尝试使用多协程(爬了两个多小时才爬完)
同时,如果熟悉scrapy,爬取的效率肯定比现在高很多
给自己定个小目标,尽早熟悉多协程和scrapy
什么时候才能不这么菜呢
以上。
智能推荐
CLion使用相关问题_clion不能复制粘贴-程序员宅基地
文章浏览阅读355次。Ctrl + Shift + F 搜索整个工程或指定目录 (连续按两次Esc,搜索框就会消失)Ctrl + W 可以实现一个字符、一个字符串、一行、两行代码的扩选。Alt + Shift + 快速查看最近对项目进行的变更。Ctrl+G,输入跳到的行数进行代码编辑。Ctrl + D 快速复制光标所在行。Ctrl + N 类查找。_clion不能复制粘贴
Java SPI机制详解-程序员宅基地
文章浏览阅读699次,点赞23次,收藏13次。首先需要定义一个接口,用于表示需要被扩展的功能。通过Java SPI机制,我们可以方便地为接口提供多个实现,并通过配置文件动态加载这些实现,而不需要修改代码。这种方式使得系统更加灵活和可扩展。希望对看到本文的你有帮助。上一篇CGLIB实现动态代理详解!!!!!下一篇Java的强引用、软引用、弱引用和虚引用详解。CGLIB实现动态代理详解!!!Java的强引用、软引用、弱引用和虚引用详解。
三维立方体剖分绘图(matlab)_matlab画三维图剖面-程序员宅基地
文章浏览阅读2.9k次。有限元或者其他数值计算程序中经常会涉及到对求解空间的剖分(均匀剖分或者非均匀剖分),在数据可视化过程中,需要绘制剖分单元,反映分布结果。下面给出matlab程序。function [x,y,z] = plotcube( p1, cube_x, cube_y, cube_z )%% p1: 立方体左下角顶点坐标%% cube_x, cube_y, cube_z 是立方体三个方向边长v = z..._matlab画三维图剖面
剑指offer-62.圆圈中最后剩下的数字(约瑟夫问题)★_个人围成一圈,1-m报数,叫到m的出圈,剩下继续报数,剩最后一个人的时候 他的编-程序员宅基地
文章浏览阅读171次。题目来源:https://leetcode-cn.com/problems/yuan-quan-zhong-zui-hou-sheng-xia-de-shu-zi-lcof/0,1,,n-1这n个数字排成一个圆圈,从数字0开始,每次从这个圆圈里删除第m个数字。求出这个圆圈里剩下的最后一个数字。例如,0、1、2、3、4这5个数字组成一个圆圈,从数字0开始每次删除第3个数字,则删除的前4个数..._个人围成一圈,1-m报数,叫到m的出圈,剩下继续报数,剩最后一个人的时候 他的编
在右键菜单中加入BitLocker重新上锁功能-程序员宅基地
文章浏览阅读3.5k次。当使用BitLocker给磁盘上锁后,可以通过命令:manage-bde -lock d: -forcedismount 将已经解锁的磁盘重新上锁,如果觉得每次都通过命令行写命令很麻烦,那可以通过修改注册表的方式在右键菜单上增加一个上锁功能。步骤如下:1、打开注册表编辑器2、在键值【HKEY_CLASSES_ROOT\Drive\shell】下添加项【runas】,然后..._manage-bde -unlock d:
sqoop 报错:Could not load db driver class: com.microsoft.sqlserver.jdbc.SQLServerDriver-程序员宅基地
文章浏览阅读4k次。一、问题描述将sql server的数据导入hive,结果报错:Warning: /opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/bin/../lib/sqoop/../accumulo does not exist! Accumulo imports will fail.Please set $ACCUMULO_HOME to th..._could not load db driver class
随便推点
C/C++MFC模拟校园卡消费记录查询系统[2024-04-10]-程序员宅基地
文章浏览阅读252次,点赞3次,收藏6次。同学们都在机房做实验或自由上机,请根据自己实际使用情况编写一份模拟校园卡消费记录查询系统,实现登录,计费,挂失,统计等相关功能。可以选择TC2.0、TC3.0、VC++6.0等开发环境,或者与老师讨论,选择自己熟悉的开发工具与平台。(5)如有可能,可使用MFC 等开发工具,实现彩色或图形操作界面。//状态 ,正常、挂失、冻结。char state;//状态 ,是否上机中。
java/php/node.js/python微信小程序的网上购物商城平台【2024年毕设】-程序员宅基地
文章浏览阅读69次。本系统带文档lw万字以上文末可领取本课题的JAVA源码参考。
51单片机学习——9--温度传感器DS18B20_ds18b02在ad中怎么搜索-程序员宅基地
文章浏览阅读3.3k次,点赞2次,收藏31次。温度传感器DS18B20简介特点实物图原理图内部结构(1) 64位(激)光刻只读存储器(2) DS18B20温度转换规则(3) DS18B20温度传感器的存储器(4) 配置寄存器ROM指令RAM指令编程原理DS18B20初始化DS18B20读时序DS18B20写时序大致过程代码实现DS18B20简介DS18B20数字温度传感器接线方便,封装后可应用于多种场合,如管道式,螺纹式,磁铁吸附式,不锈钢封装式。主要根据应用场合的不同而改变其外观。封装后的DS18B20可用于电缆沟测温,高炉水循环测温,锅炉测温_ds18b02在ad中怎么搜索
专科毕业三年,从外包公司到今日头条offer,我想把面试心得分享给你-程序员宅基地
文章浏览阅读736次,点赞28次,收藏12次。WebView 与 JS 交互方式,shouldOverrideUrlLoading、onJsPrompt使用有啥区别 -Flutter、Kotlin接触使用过没有其他项目相关问题算法 - 二叉树输出第 k 层节点元素。
作为程序员,其实你并没真正努力(一)_程序员努力的方向-程序员宅基地
文章浏览阅读5.9k次,点赞11次,收藏15次。IT技术发展迅猛,新技术层出不穷,具有良好的学习能力,并及时获取新知识,成为程序员职业发展的核心竞争力。本文作者结合多年学习经验总结出提高程序员学习能力的三个要点,即要善于读书、要高效学习、要有好心态。IT技术的发展日新月异,新技术层出不穷,具有良好的学习能力,能及时获取新知识、随时补充和丰富自己,已成为程序员职业发展的核心竞争力。本文中,作者结合多年的学习经验总结出了提高程序员学习能_程序员努力的方向
FreeMarker详细介绍-程序员宅基地
文章浏览阅读6.7w次,点赞134次,收藏738次。FreeMarker概述FreeMarker 是一款 模板引擎: 即一种基于模板和要改变的数据, 并用来生成输出文本(HTML网页,电子邮件,配置文件,源代码等)的通用工具。 是一个Java类库。FreeMarker 被设计用来生成 HTML Web 页面,特别是基于 MVC 模式的应用程序,将视图从业务逻辑中抽离处理,业务中不再包括视图的展示,而是将视图交给 FreeMarker 来输出。虽然 FreeMarker 具有一些编程的能力,但通常由 Java 程序准备要显示的数据,由 FreeMar_freemarker