字符串基础知识总结_什么是字符串-程序员宅基地
字符串
什么是字符串
字符串是由数字、字⺟、下划线组成的⼀串字符
注意:
单引号和双引号不能混合使⽤
Python中⽤⼀对双引号或者⼀对单引号包裹的内容就是字符串
转义字符
转义字符是⼀种特殊的字符常量。转义字符以反斜线""开头,后跟⼀个或⼏个
字符。转义字符具有特定的含义,不同于字符原有的意义,故称“转义”字符
\t 表示制表符
\n 表示换⾏符
\ 表示反斜杠
’ 表示 ’
⻓字符串
⻓字符串 ⼜叫做⽂档字符串 我们使⽤三重引号来表示⼀个⻓字符串’’’ ‘’’
三重引号可以换⾏,并且会保留字符串中的格式
字符串复制
使用*可以实现字符串复制
从控制台读取字符串
我们可以使用 input()从控制台读取键盘输入的内容
str()实现数字转型字符串
str()可以帮助我们将其他数据类型转换为字符串
字符串切片 slice 操作
`
字符串反转
x[::-1]
截取字符串
str = '0123456789′
print str[0:3] #截取第一位到第三位的字符
print str[:] #截取字符串的全部字符
print str[6:] #截取第七个字符到结尾
print str[:-3] #截取从头开始到倒数第三个字符之前
print str[2] #截取第三个字符
print str[-1] #截取倒数第一个字符
print str[::-1] #创造一个与原字符串顺序相反的字符串
print str[-3:-1] #截取倒数第三位与倒数第一位之前的字符
print str[-3:] #截取倒数第三位到结尾
print str[:-5:-3] #逆序截取
[起始偏移量 start:终止偏移量 end:步长 step]
| 操作和说明 | 示例 | 结果 |
|---|---|---|
| [:] 提取整个字符串 | “abcdef”[:] | “abcdef” |
| [start:]从 start 索引开始到结尾 | “abcdef”[2:] | “cdef” |
| [:end]从头开始知道 end-1 | “abcdef”[:2] | “ab” |
| [start:end]从 start 到 end-1 | “abcdef”[2:4] | “cd” |
| [start: end:step]从 start 提取到end-1,步长是 step | “abcdef”[1:5:2] | “bd” |
| – | – | – |
| “abcdefghijklmnopqrstuvwxyz”[-3:] | 倒数三个 | “xyz” |
| “abcdefghijklmnopqrstuvwxyz”[-8:-3] | 倒数第八个到倒数第三个(包头不包尾) | ‘stuvw’ |
| “abcdefghijklmnopqrstuvwxyz”[::-1] | 步长为负,从右到左反向提取 | ‘zyxwvutsrqponmlkjihgfedcba’ |
切片操作时,起始偏移量和终止偏移量不在[0,字符串长度-1]这个范围,也不会报错。起始偏移量小于 0 则会当做 0,终止偏移量大于“长度-1”会被当成-1
常用方法
字符串比较和同一性
我们可以直接使用==,!=对字符串进行比较,是否含有相同的字符。
我们使用 is / not is,判断两个对象是否同一个对象。比较的是对象的地址,即 id(obj1)是否和 id(obj2)相等。
成员操作符
in /not in 关键字,判断某个字符(子字符串)是否存在于字符串中
a = "abcde"
print("b" in a)
print("x" in a)
print("x" not in a)
# True
# False
# True
大小写转换a.title(),a.upper(),a.lower()
- a.capitalize():产生新的字符串,首字母大写
a = "tom,Jack,Tom,xiaohong"
b=a.capitalize()
print(b)#Tom,jack,tom,xiaohong
- a.title():产生新的字符串,每个单词都首字母大写
a = "tom,Jack,Tom,xiaohong"
b= a.title()
print(b)#Tom,Jack,Tom,Xiaohong
- a.upper():产生新的字符串,所有字符全转成大写
a = "tom,Jack,Tom,xiaohong"
b=a.upper()
print(b)#TOM,JACK,TOM,XIAOHONG
- a.lower():产生新的字符串,所有字符全转成小写
a = "tom,Jack,Tom,xiaohong"
b=a.lower()
print(b)#tom,jack,tom,xiaohong
a.swapcase():产生新的,所有字母大小写转换
a = "tom,Jack,Tom,xiaohong"
b=a.swapcase()
print(b)#TOM,jACK,tOM,XIAOHONG
- max() 最⼤值
a = "2 ,5 ,6 ,8"
b=max(a)
print(b) #8
min() 最⼩值
注意:
a = [1,5,6,8]
b=max(str(a)) # ]
print(b)
print(type(str(a)))
# <class 'str'>
格式排版center()、ljust()、rjust()
- zfill(width)
width – 指定字符串的长度。原字符串右对齐,前面填充0
center()、ljust()、rjust()这三个函数用于对字符串实现排版
>>> a="S"
>>> a.center(10,"*")
'***S****'
>>> a.center(10)
' S '
>>> a.ljust(10,"*")
'S*******'
检查查找:find(),startswith(),index()
- find()方法:符号首次出现的位置索引,找不到返回-1
a = "ansdhdnddh-/uuu"
b = a.find("-")
print(b) #10
c = a.find("x")
print(c) #-1
- startswith()方法:返回起始字符
txt = "Hello, welcome to my world."
x = txt.startswith("Hello")
print(x)
#True
-
endswith()方法:返回结尾字符
-
index():检测字符串是否包含指定字符,如果包含,则返回开始的索引值,否则,提示错误
txt = "Hello, welcome to my world."
x = txt.index("w")
print(x) 7
x = txt.index("Hello")
print(x) 0
- rfind(str, beg=0 end=len(string))返回字符串最后一次出现的位置,如果没有匹配项则返回-1
- rindex(str, beg=0 end=len(string))
返回子字符串 str 在字符串中最后出现的位置,如果没有匹配的字符串会报异常,你可以指定可选参数[beg:end]设置查找的区间。
检测判断字母大小写问题
- isalnum() 是否为字母或数字
- isalpha() 检测字符串是否只由字母组成(含汉字)。
- isdigit() 检测字符串是否只由数字组成。
- isspace() 字符串是否只由空白字符组成
- isupper() 是否为大写字母
- islower() 是否为小写字母
- istitle()检测所有的单词拼写首字母是否为大写,且其他字母为小写
删除:strip(),lstrip(),rstrip()
rstrip([chars])删除 string 字符串末尾的指定字符(默认为空格)
lstrip([chars])删除 string 字符串开头的指定字符(默认为空格)
strip([chars])用于移除字符串头尾指定的字符(默认为空格)或字符序列。
拼接,join
可以使用+将多个字符串拼接起来。例如:’aa’+ ’bb’ ==>’aabb’
(1) 如果+两边都是字符串,则拼接。
(2) 如果+两边都是数字,则加法运算。
(3) 如果+两边类型不同,则抛出异常。
可以将多个字面字符串直接放到一起实现拼接。例如:’aa’’bb’==>’aabb’
- os.path.join(): 将多个路径组合后返回
- join(sequence)用于将序列中的元素以指定的字符连接生成一个新的字符串
a = ['yun','s100','st200']
b = '*'.join(a)
print(b)
# yun*s100*st200
使用字符串拼接符+,会生成新的字符串对象,因此不推荐使用+来拼接字符串。推荐使用 join 函数,因为 join 函数在拼接字符串之前会计算所有字符串的长度,然后逐一拷贝,仅新建一次对象
推荐使用生成器表达式,如果列表很大,可以节省很多内存空间
li = [3, 'cxk', 'kk', 'caibi']
''.join(str(i) for i in li)
分割: split(),
- split(str="", num):通过指定分隔符对字符串进行切片,如果第二个参数 num 有指定值,则分割为 num+1 个子字符串。如果不指定分隔符,则默认使用空白字符(换行符/空格/制表符)
a = "to be or not to be"
a.split()
- rsplit()函数
描述:拆分字符串。通过指定分隔符sep对字符串进行分割,并返回分割后的字符串列表,类似于split()函数,只不过 rsplit()函数是从字符串右边(末尾)开始分割 - splitlines()函数
描述:按照(’\n’, ‘\r’, \r\n’等)分隔,返回一个包含各行作为元素的列表,默认不包含换行符
python 中的 split() 方法 由于 split 一次处理一个分隔符,
使用 re 模块的中 split() 方法,可以一次性分隔字符串
import re
s = "ab;fd/ft|fs,f\tdf.fss*dfd;fs:uu}fsd"
print(re.split('[;/|,.}:*\t]', s))
#['ab', 'fd', 'ft', 'fs', 'f', 'df', 'fss', 'dfd', 'fs', 'uu', 'fsd']
- partition()函数:
描述:根据指定的分隔符(sep)将字符串进行分割。从字符串左边开始索引分隔符sep,索引到则停止索引。
语法: str.partition(sep) -> (head, sep, tail) 返回一个三元元组,head:分隔符sep前的字符串,sep:分隔符本身,tail:分隔符sep后的字符串。
sep —— 指定的分隔符。
如果字符串包含指定的分隔符sep,则返回一个三元元组,第一个为分隔符sep左边的子字符串,第二个为分隔符sep本身,第三个为分隔符sep右边的子字符串。
如果字符串不包含指定的分隔符sep,仍然返回一个三元元组,第一个元素为字符串本身,第二第三个元素为空字符串
str = "https://www.baidu.com/"
print(str.partition("://")) #字符串str中存在sep"://"
print(str.partition(",")) #字符串str中不存在sep",",返回了两个空字符串。
print(str.partition(".")) #字符串str中存在两个"." 但索引到www后的"." 停止索引。
print(type(str.partition("://"))) #返回的是tuple类型, 即元组类型
('https', '://', 'www.baidu.com/')
('https://www.baidu.com/', '', '')
('https://www', '.', 'baidu.com/')
<class 'tuple'>
- rpartition()函数:
与partition()函数用法相似,rpartition()函数从右边(末尾)开始索引,partition()函数从左边开始索引
计算数量:count(),len()
- count(sub, start= 0,end=len(string))用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置。
len( s )返回对象(字符、列表、元组等)长度或项目个数
注意:
1 :在实际开发时,有时需要获取字符串实际所占的字节数,即如果采用UTF-8编码,汉字(汉字逗号也是一个汉字占位)占3个字节,
采用GBK或者GB2312时,汉字占2个字节。这时,可以通过使用encode()方法进行编码后再进行获取。
例如,如果要获取采用UTF-8编码的字符串的长度,可以使用下面的代码:
tr1 = '人生苦短,我用Python!' # 定义字符串
length = len(str1.encode()) # 计算UTF-8编码的字符串的长度
print(length)
#28
替代replace(),re.sub(),maketrans()
- replace(“a”,“b”,n) 用b替换a,替换前n个
以及字符串映射表
str.replace(old, new[, max])
a = "abcde123"
b = a.replace("a","哈哈哈")
print(b)
# 哈哈哈bcde123
- maketrans()
创建一个字符串映射表,将字符串中对应"a"字符转换成"6",“c"转换成"5”
t = str.maketrans("ac","65")
str8 = "ace,nice,apple"
str9 = str8.translate(t)
print (str9)
#结果:65e,ni5e,6pple
-
expandtabs(tabsize=8)
把字符串中的 tab 符号(’\t’)转为空格,tab 符号(’\t’)默认的空格数是 8。 -
re.sub()函数
快速删除字符串非中文字符:re.sub()函数
import re
str = 'kakka哈哈哈哈,,,L《《《》》'
a = re.sub(r'[^\u4e00-\u9fa5]',"",str) #[^/u4e00-/u9fa5] 运行结果:哈哈哈哈
b = re.sub(r'[\u4e00-\u9fa5]',"",str) #运行结果:kakka,,,L《《《》》
print(a,b)
str = "abd123?,"
a = re.sub(r'[\d|?]',"",str)
print(a)
#abd,
调整字符串中文本的格式
2019-06-12 改成 06-12-2019 格式
#
str = "今天时间:2019-06-12"
b = re.sub('(\d{4})-(\d{2})-(\d{2})', r'\2-\3-\1', str)
print(b)
# 今天时间:06-12-2019
eval()函数对字符串的处理
eval(str) 功能:将字符串str当成有效的表达式来求值并返回计算结果
numb2 = eval('123')
print (numb2)
numb2 = eval('12+3')
print (numb2)
numb2 = eval('12-3')
print (numb2)
调整字符串中文本的格式
编码,解码
.encode(enconding=‘utf-8’)
data.decode(“utf-8”)
ASCII码转换
- ord()转换字符为ASCII码
- chr()转换ASCII码为字符
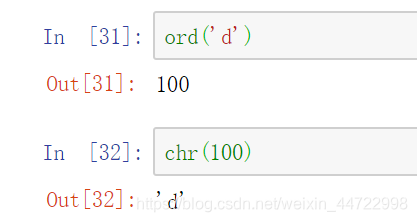
字符串比较大小,从第一个字符开始比较,谁的ASCII码值大谁就大,如果相等会比较下一个字符的ASCII码值大小,那么谁的值大谁就大
print (“bazzzz” > “ba”)
True
格式化字符串
- 方法一: 拼串
# 拼接字符串
str1 = '今天我一共走了' # 定义字符串
num = 12098 # 定义一个整数
str2 = '步' # 定义字符串
print(str1 + str(num) + str2)
今天我一共走了12098步
- 方法二:参数传递
- 方法三: 占位符
%s 字符串占位
%d 整数占位
%f 浮点数占位
# 格式化字符串,(1)使用“%”操作符
# %s:字符串,%d:十进制整数
name = "小明"
age = 18
price = 5.8
str = "我叫%s,今年%d岁,买了一本本%f元" % (name,age,price)
print(str)
我叫小明,今年18岁,买了一本本5.800000元
- 方法四:f’{变量}’/ str.format
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的
功能。
基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序
- 1:使用字符串对象的format()方法
name = "Q1mi"
age = 18
b = f"My name is {name}.I'm {age}"
print(b)
注意: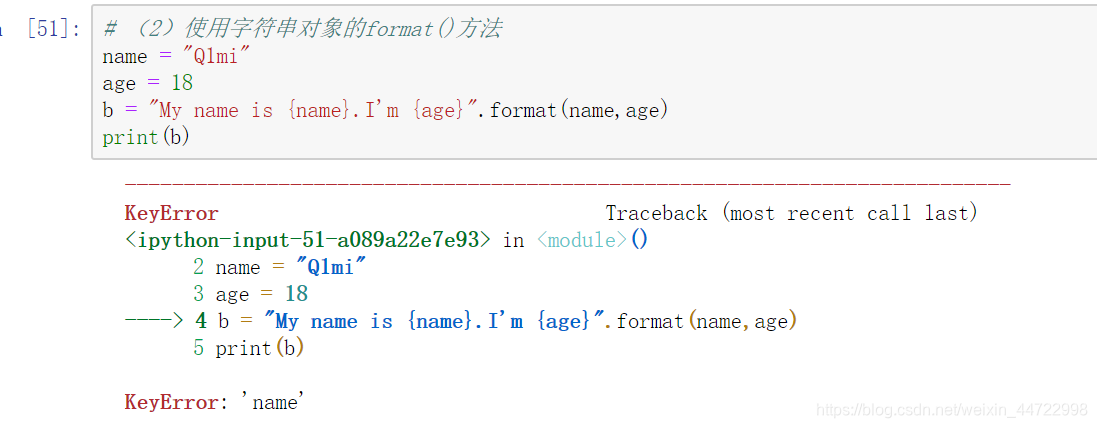
更改为:
- 通过关键字
name = "Q1mi"
age = 18
b = "My name is {name}.I'm {age}".format(name=name,age=age)
print(b)
My name is Q1mi.I'm 18
- 通过位置
data = ["Q1mi", 18]
"Name:{0}, Age:{1}".format(*data)
'Name:Q1mi, Age:18'
- 通过字典传输
dic = {
'name': 'Jack', 'age': 18, 'favorite': 'Python'}
'I am {0[age]} years old.I am {0[name]} and I love {0[favorite]}'.format(dic)
'I am 18 years old.I am Jack and I love Python'
- 通过下标
data = ["Q1mi", 18]
"{0[0]} is {0[1]} years old.".format(data)
'Q1mi is 18 years old.'
‘’'我们还可以主动为花括号进行编号。在待格式化的字符串中,从左到右依次为{0}、{1}、{2}……其中,
{0}对应第一个参数、{1}对应第二个参数、{2}对应第三个参数……
在对花括号进行了编号之后,我们就可以灵活地调整它们的位置了。
‘’’
'I am {2} years old.I am {1} and I love {0}'.format('Python','Jack',18)
'I am 18 years old.I am Jack and I love Python'
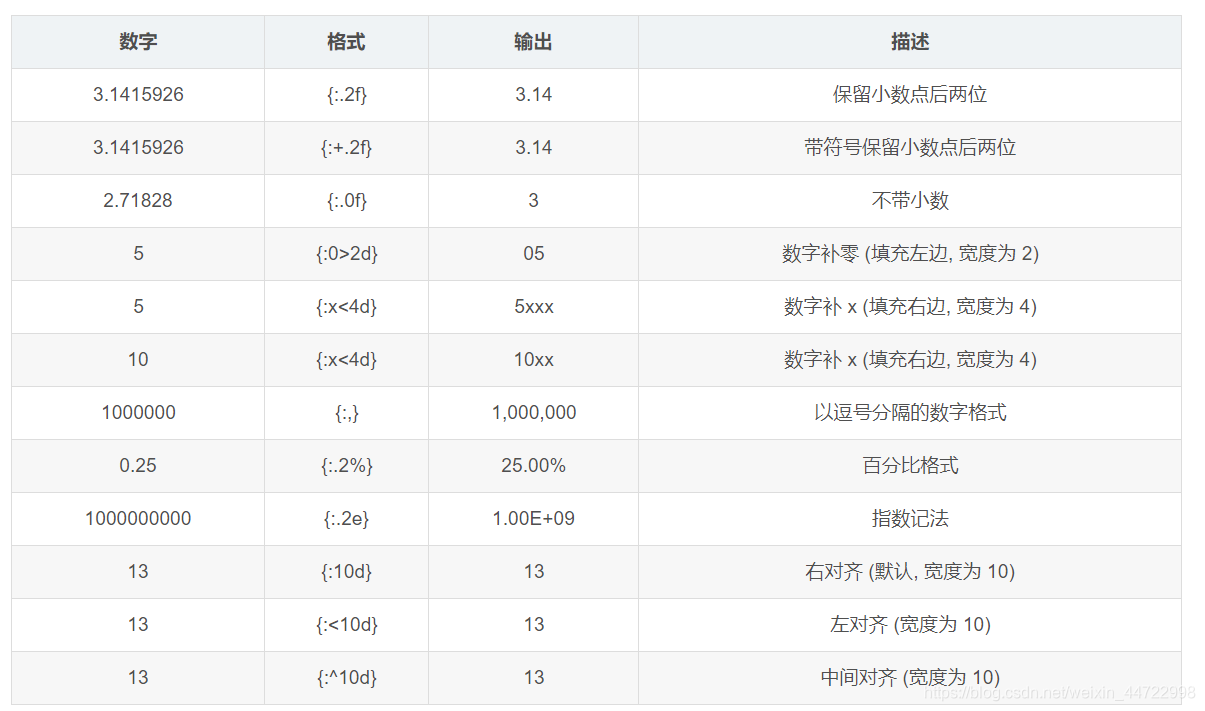
数字格式化
浮点数通过 f,整数通过 d 进行需要的格式化
>>> a = "我是{0},我的存款有{1:.2f}"
>>> a.format("高淇",3888.234342)
'我是效效,我的存款有 3888.23'
位置填充
填充常跟对齐一起使用
^、<、>分别是居中、左对齐、右对齐,后面带宽度
:号后面带填充的字符,只能是一个字符,不指定的话默认是用空格填充
>>> "{:*>8}".format("245")
'*****245'
>>> "我是{0},我喜欢数字{1:*^8}".format("小明","666")
'我是小明,我喜欢数字**666***'
智能推荐
攻防世界_难度8_happy_puzzle_攻防世界困难模式攻略图文-程序员宅基地
文章浏览阅读645次。这个肯定是末尾的IDAT了,因为IDAT必须要满了才会开始一下个IDAT,这个明显就是末尾的IDAT了。,对应下面的create_head()代码。,对应下面的create_tail()代码。不要考虑爆破,我已经试了一下,太多情况了。题目来源:UNCTF。_攻防世界困难模式攻略图文
达梦数据库的导出(备份)、导入_达梦数据库导入导出-程序员宅基地
文章浏览阅读2.9k次,点赞3次,收藏10次。偶尔会用到,记录、分享。1. 数据库导出1.1 切换到dmdba用户su - dmdba1.2 进入达梦数据库安装路径的bin目录,执行导库操作 导出语句:./dexp cwy_init/[email protected]:5236 file=cwy_init.dmp log=cwy_init_exp.log 注释: cwy_init/init_123..._达梦数据库导入导出
js引入kindeditor富文本编辑器的使用_kindeditor.js-程序员宅基地
文章浏览阅读1.9k次。1. 在官网上下载KindEditor文件,可以删掉不需要要到的jsp,asp,asp.net和php文件夹。接着把文件夹放到项目文件目录下。2. 修改html文件,在页面引入js文件:<script type="text/javascript" src="./kindeditor/kindeditor-all.js"></script><script type="text/javascript" src="./kindeditor/lang/zh-CN.js"_kindeditor.js
STM32学习过程记录11——基于STM32G431CBU6硬件SPI+DMA的高效WS2812B控制方法-程序员宅基地
文章浏览阅读2.3k次,点赞6次,收藏14次。SPI的详情简介不必赘述。假设我们通过SPI发送0xAA,我们的数据线就会变为10101010,通过修改不同的内容,即可修改SPI中0和1的持续时间。比如0xF0即为前半周期为高电平,后半周期为低电平的状态。在SPI的通信模式中,CPHA配置会影响该实验,下图展示了不同采样位置的SPI时序图[1]。CPOL = 0,CPHA = 1:CLK空闲状态 = 低电平,数据在下降沿采样,并在上升沿移出CPOL = 0,CPHA = 0:CLK空闲状态 = 低电平,数据在上升沿采样,并在下降沿移出。_stm32g431cbu6
计算机网络-数据链路层_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏8次。数据链路层习题自测问题1.数据链路(即逻辑链路)与链路(即物理链路)有何区别?“电路接通了”与”数据链路接通了”的区别何在?2.数据链路层中的链路控制包括哪些功能?试讨论数据链路层做成可靠的链路层有哪些优点和缺点。3.网络适配器的作用是什么?网络适配器工作在哪一层?4.数据链路层的三个基本问题(帧定界、透明传输和差错检测)为什么都必须加以解决?5.如果在数据链路层不进行帧定界,会发生什么问题?6.PPP协议的主要特点是什么?为什么PPP不使用帧的编号?PPP适用于什么情况?为什么PPP协议不_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输
软件测试工程师移民加拿大_无证移民,未受过软件工程师的教育(第1部分)-程序员宅基地
文章浏览阅读587次。软件测试工程师移民加拿大 无证移民,未受过软件工程师的教育(第1部分) (Undocumented Immigrant With No Education to Software Engineer(Part 1))Before I start, I want you to please bear with me on the way I write, I have very little gen...
随便推点
Thinkpad X250 secure boot failed 启动失败问题解决_安装完系统提示secureboot failure-程序员宅基地
文章浏览阅读304次。Thinkpad X250笔记本电脑,装的是FreeBSD,进入BIOS修改虚拟化配置(其后可能是误设置了安全开机),保存退出后系统无法启动,显示:secure boot failed ,把自己惊出一身冷汗,因为这台笔记本刚好还没开始做备份.....根据错误提示,到bios里面去找相关配置,在Security里面找到了Secure Boot选项,发现果然被设置为Enabled,将其修改为Disabled ,再开机,终于正常启动了。_安装完系统提示secureboot failure
C++如何做字符串分割(5种方法)_c++ 字符串分割-程序员宅基地
文章浏览阅读10w+次,点赞93次,收藏352次。1、用strtok函数进行字符串分割原型: char *strtok(char *str, const char *delim);功能:分解字符串为一组字符串。参数说明:str为要分解的字符串,delim为分隔符字符串。返回值:从str开头开始的一个个被分割的串。当没有被分割的串时则返回NULL。其它:strtok函数线程不安全,可以使用strtok_r替代。示例://借助strtok实现split#include <string.h>#include <stdio.h&_c++ 字符串分割
2013第四届蓝桥杯 C/C++本科A组 真题答案解析_2013年第四届c a组蓝桥杯省赛真题解答-程序员宅基地
文章浏览阅读2.3k次。1 .高斯日记 大数学家高斯有个好习惯:无论如何都要记日记。他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210后来人们知道,那个整数就是日期,它表示那一天是高斯出生后的第几天。这或许也是个好习惯,它时时刻刻提醒着主人:日子又过去一天,还有多少时光可以用于浪费呢?高斯出生于:1777年4月30日。在高斯发现的一个重要定理的日记_2013年第四届c a组蓝桥杯省赛真题解答
基于供需算法优化的核极限学习机(KELM)分类算法-程序员宅基地
文章浏览阅读851次,点赞17次,收藏22次。摘要:本文利用供需算法对核极限学习机(KELM)进行优化,并用于分类。
metasploitable2渗透测试_metasploitable2怎么进入-程序员宅基地
文章浏览阅读1.1k次。一、系统弱密码登录1、在kali上执行命令行telnet 192.168.26.1292、Login和password都输入msfadmin3、登录成功,进入系统4、测试如下:二、MySQL弱密码登录:1、在kali上执行mysql –h 192.168.26.129 –u root2、登录成功,进入MySQL系统3、测试效果:三、PostgreSQL弱密码登录1、在Kali上执行psql -h 192.168.26.129 –U post..._metasploitable2怎么进入
Python学习之路:从入门到精通的指南_python人工智能开发从入门到精通pdf-程序员宅基地
文章浏览阅读257次。本文将为初学者提供Python学习的详细指南,从Python的历史、基础语法和数据类型到面向对象编程、模块和库的使用。通过本文,您将能够掌握Python编程的核心概念,为今后的编程学习和实践打下坚实基础。_python人工智能开发从入门到精通pdf