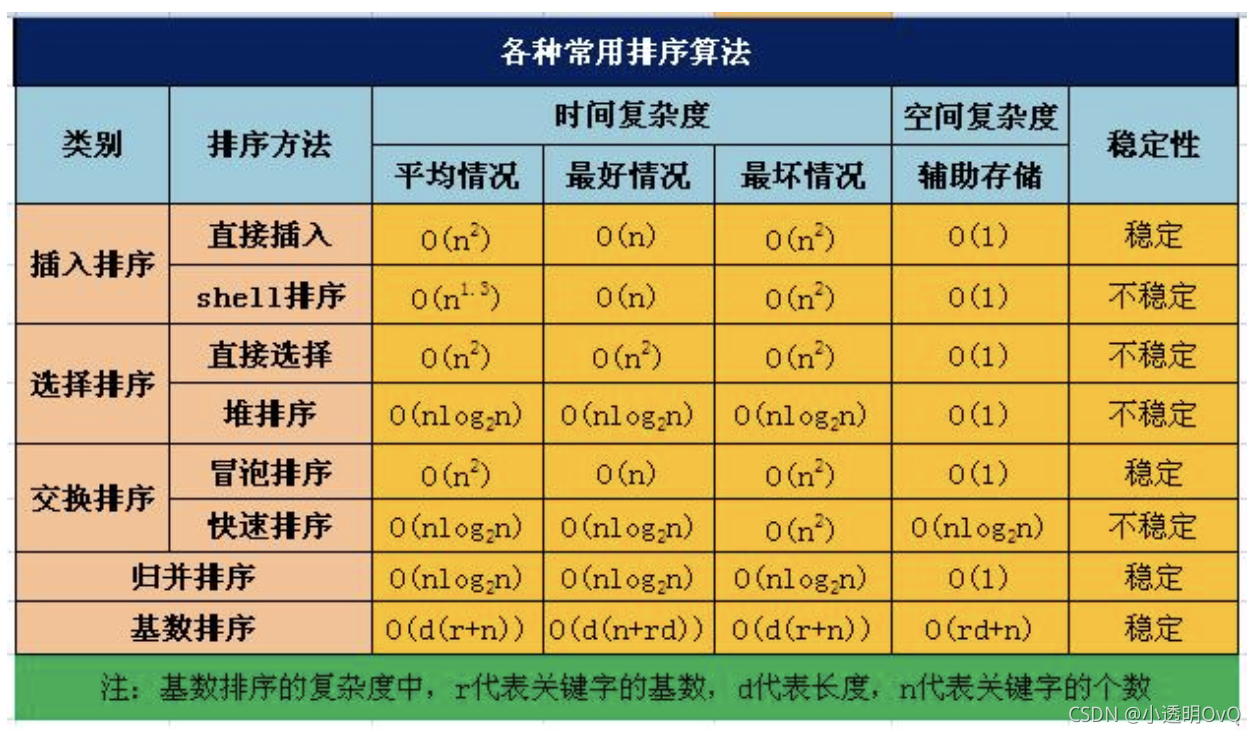
八大排序算法的Java实现-程序员宅基地
内容参考此链接,感谢。
一、插入排序
1. 直接插入排序
/**
* 插入排序
*
* 1. 从第一个元素开始,该元素可以认为已经被排序
* 2. 取出下一个元素,在已经排序的元素序列中从后向前扫描
* 3. 如果该元素(已排序)大于新元素,将该元素移到下一位置
* 4. 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
* 5. 将新元素插入到该位置后
* 6. 重复步骤2~5
* @param arr 待排序数组
*/
public static void insertionSort(int[] arr){
for(int i=1;i<arr.length;i++){
int temp = arr[i]; // 记录一下这个要排序的值
for(int j=i;j>=0;j--){
if(j>0&&arr[j-1]>temp){
arr[j]=arr[j-1];
}else{
// 要么到头了,就是j=0,要么就是arr[j-1]<temp
arr[j]=temp;
break; // 当前这个temp已经放进去了,那就退出最里层的for循环
}
}
}
}
2. 希尔排序
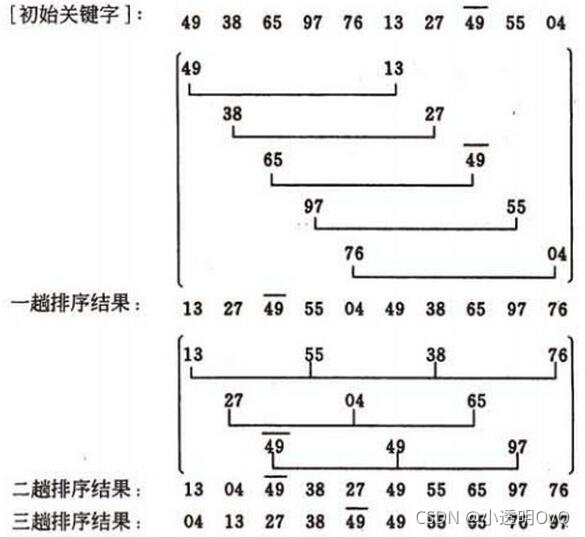
/**
* 希尔排序
*
* 1. 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;(一般初次取数组半长,之后每次再减半,直到增量为1)
* 2. 按增量序列个数k,对序列进行k趟排序;
* 3. 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。
* 仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
* @param arr 待排序数组
*/
public class ShellSort {
public static void main(String[] args)
{
int[] ins = {
2,3,5,1,23,6,78,34,23,4,5,78,34,65,32,65,76,32,76,1,9};
int[] ins2 = shellSort(ins);
for(int in: ins2){
System.out.print(in+" ");
}
}
public static int[] shellSort(int[] arr){
int gap = arr.length/2;
for(;gap>0;gap/=2){
// gap不断缩小,直到gap=1
for(int i=0;i<gap;i++){
for(int j=i+gap;j<arr.length;j+=gap){
int temp = arr[j];
int k = j - gap;
while(k>=0&&arr[k]>temp){
arr[k+gap] = arr[k];
k-=gap;
}
arr[k + gap] = temp;
}
}
}
return arr;
}
}
二、选择排序
1. 简单选择排序/直接选择排序
/**
* 选择排序
*
* 1. 从待排序序列中,找到关键字最小的元素;
* 2. 如果最小元素不是待排序序列的第一个元素,将其和第一个元素互换;
* 3. 从余下的 N - 1 个元素中,找出关键字最小的元素,重复①、②步,直到排序结束。
* 仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
* @param arr 待排序数组
*/
public static void selectionSort(int[] arr){
for(int i=0;i<arr.length;i++){
int min = i;
for(int j=i+1;j<arr.length;j++){
if(arr[j]<arr[min]){
min=j;
}
}
if(min!=i){
int temp = arr[min];
arr[min] = arr[i];
arr[i] = temp;
}
}
}
2. 堆排序(不想看了 想吐了)
/**
* 堆排序
*
* 1. 先将初始序列K[1..n]建成一个大顶堆, 那么此时第一个元素K1最大, 此堆为初始的无序区.
* 2. 再将关键字最大的记录K1 (即堆顶, 第一个元素)和无序区的最后一个记录 Kn 交换, 由此得到新的无序区K[1..n−1]和有序区K[n], 且满足K[1..n−1].keys⩽K[n].key
* 3. 交换K1 和 Kn 后, 堆顶可能违反堆性质, 因此需将K[1..n−1]调整为堆. 然后重复步骤②, 直到无序区只有一个元素时停止.
* @param arr 待排序数组
*/
public static void heapSort(int[] arr){
for(int i = arr.length; i > 0; i--){
max_heapify(arr, i);
int temp = arr[0]; //堆顶元素(第一个元素)与Kn交换
arr[0] = arr[i-1];
arr[i-1] = temp;
}
}
private static void max_heapify(int[] arr, int limit){
if(arr.length <= 0 || arr.length < limit) return;
int parentIdx = limit / 2;
for(; parentIdx >= 0; parentIdx--){
if(parentIdx * 2 >= limit){
continue;
}
int left = parentIdx * 2; //左子节点位置
int right = (left + 1) >= limit ? left : (left + 1); //右子节点位置,如果没有右节点,默认为左节点位置
int maxChildId = arr[left] >= arr[right] ? left : right;
if(arr[maxChildId] > arr[parentIdx]){
//交换父节点与左右子节点中的最大值
int temp = arr[parentIdx];
arr[parentIdx] = arr[maxChildId];
arr[maxChildId] = temp;
}
}
System.out.println("Max_Heapify: " + Arrays.toString(arr));
}
三、交换排序
1. 冒泡排序
/**
* 冒泡排序
*
* 冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。
* 如果不满足就让它俩互换。一次冒泡会让至少一个元素移动到它应该在的位置,重复n次,就完成了 n 个数据的排序工作。
**/
public class BubbleSort {
public void bubbleSort(Integer[] arr, int n) {
if (n <= 1) return; //如果只有一个元素就不用排序了
for (int i = 0; i < n; ++i) {
// 提前退出冒泡循环的标志位,即一次比较中没有交换任何元素,这个数组就已经是有序的了
boolean flag = false;
for (int j = 0; j < n - i - 1; ++j) {
//此处你可能会疑问的j<n-i-1,因为冒泡是把每轮循环中较大的数飘到后面,
// 数组下标又是从0开始的,i下标后面已经排序的个数就得多减1,总结就是i增多少,j的循环位置减多少
if (arr[j] > arr[j + 1]) {
//即这两个相邻的数是逆序的,交换
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
flag = true;
}
}
if (!flag) break;//没有数据交换,数组已经有序,退出排序
}
}
public static void main(String[] args) {
Integer arr[] = {
2, 4, 7, 6, 8, 5, 9};
SortUtil.show(arr);
BubbleSort bubbleSort = new BubbleSort();
bubbleSort.bubbleSort(arr, arr.length);
SortUtil.show(arr);
}
}
2. 快速排序
/**
* 快速排序(递归)
*
* ①. 从数列中挑出一个元素,称为"基准"(pivot)。
* ②. 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
* ③. 递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。
* @param arr 待排序数组
* @param low 左边界
* @param high 右边界
*/
public static void quickSort(int[] arr, int low, int high){
if(arr.length <= 0) return;
if(low >= high) return;
int left = low;
int right = high;
int temp = arr[left]; //挖坑1:保存基准的值
while (left < right){
while(left < right && arr[right] >= temp){
//坑2:从后向前找到比基准小的元素,插入到基准位置坑1中
right--;
}
arr[left] = arr[right];
while(left < right && arr[left] <= temp){
//坑3:从前往后找到比基准大的元素,放到刚才挖的坑2中
left++;
}
arr[right] = arr[left];
}
arr[left] = temp; //基准值填补到坑3中,准备分治递归快排
System.out.println("Sorting: " + Arrays.toString(arr));
quickSort(arr, low, left-1);
quickSort(arr, left+1, high);
}
四、归并排序
/**
* 归并排序(递归)
*
* ①. 将序列每相邻两个数字进行归并操作,形成 floor(n/2)个序列,排序后每个序列包含两个元素;
* ②. 将上述序列再次归并,形成 floor(n/4)个序列,每个序列包含四个元素;
* ③. 重复步骤②,直到所有元素排序完毕。
* @param arr 待排序数组
*/
public static int[] mergingSort(int[] arr){
if(arr.length <= 1) return arr;
int num = arr.length >> 1;
int[] leftArr = Arrays.copyOfRange(arr, 0, num);
int[] rightArr = Arrays.copyOfRange(arr, num, arr.length);
System.out.println("split two array: " + Arrays.toString(leftArr) + " And " + Arrays.toString(rightArr));
return mergeTwoArray(mergingSort(leftArr), mergingSort(rightArr)); //不断拆分为最小单元,再排序合并
}
private static int[] mergeTwoArray(int[] arr1, int[] arr2){
int i = 0, j = 0, k = 0;
int[] result = new int[arr1.length + arr2.length]; //申请额外的空间存储合并之后的数组
while(i < arr1.length && j < arr2.length){
//选取两个序列中的较小值放入新数组
if(arr1[i] <= arr2[j]){
result[k++] = arr1[i++];
}else{
result[k++] = arr2[j++];
}
}
while(i < arr1.length){
//序列1中多余的元素移入新数组
result[k++] = arr1[i++];
}
while(j < arr2.length){
//序列2中多余的元素移入新数组
result[k++] = arr2[j++];
}
System.out.println("Merging: " + Arrays.toString(result));
return result;
}
五、归并排序
/**
* 基数排序(LSD 从低位开始)
*
* 基数排序适用于:
* (1)数据范围较小,建议在小于1000
* (2)每个数值都要大于等于0
*
* ①. 取得数组中的最大数,并取得位数;
* ②. arr为原始数组,从最低位开始取每个位组成radix数组;
* ③. 对radix进行计数排序(利用计数排序适用于小范围数的特点);
* @param arr 待排序数组
*/
public static void radixSort(int[] arr){
if(arr.length <= 1) return;
//取得数组中的最大数,并取得位数
int max = 0;
for(int i = 0; i < arr.length; i++){
if(max < arr[i]){
max = arr[i];
}
}
int maxDigit = 1;
while(max / 10 > 0){
maxDigit++;
max = max / 10;
}
System.out.println("maxDigit: " + maxDigit);
//申请一个桶空间
int[][] buckets = new int[10][arr.length-1];
int base = 10;
//从低位到高位,对每一位遍历,将所有元素分配到桶中
for(int i = 0; i < maxDigit; i++){
int[] bktLen = new int[10]; //存储各个桶中存储元素的数量
//分配:将所有元素分配到桶中
for(int j = 0; j < arr.length; j++){
int whichBucket = (arr[j] % base) / (base / 10);
buckets[whichBucket][bktLen[whichBucket]] = arr[j];
bktLen[whichBucket]++;
}
//收集:将不同桶里数据挨个捞出来,为下一轮高位排序做准备,由于靠近桶底的元素排名靠前,因此从桶底先捞
int k = 0;
for(int b = 0; b < buckets.length; b++){
for(int p = 0; p < bktLen[b]; p++){
arr[k++] = buckets[b][p];
}
}
System.out.println("Sorting: " + Arrays.toString(arr));
base *= 10;
}
}
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象