python爬虫urllib模块详解_python urllib-程序员宅基地
技术标签: 爬虫 python urllib python网络爬虫 urllib.request urlopen
1.urllib模块简介
python2有urllib和urllib2两种模块,都用来实现网络请求的发送。python3将urllib和urllib2模块整合并命名为urllib模块。urllib模块有多个子模块,各有不同的功能:
- ①urllib.request模块:用于实现基本的http请求。
- ②urllib.error模块:用于异常处理。如在发送网络请求时出现错误,用该模块捕捉并处理。
- ③urllib.parse模块:用于解析。
- ④urllib.robotparser:用于解析robots.txt文件,判断是否可以爬取网站信息。
2.发送请求:urlopen()方法
urloprn() 方法由urllib.request模块提供,以实现基本的http请求,并接受服务器端返回的响应数据。
urlopen()语法:
urllib.request.urlopen(url,data=None,[timeout,]*,cafile=None,capath=None,cadefault=False,context=None)
- url:访问网站的完整url地址
- data:默认为None,表示请求方式为get请求;如果需要实现post请求,需要字典形式的数据作为参数。
- timeout:设置超时,单位为秒。
- cafile,capath:指定一组HTTPS请求信任的CA证书,cafile指包含单个证书的CA文件,capath指定证书文件的目录。
- cadefault:CA证书的默认值。
- context:描述SSL选项的 的实例。
3. 发送GET请求
代码示例
import urllib.request # 导入request子模块
url = 'https://www.python.org/'
response = urllib.request.urlopen(url=url) # 发送网络请求
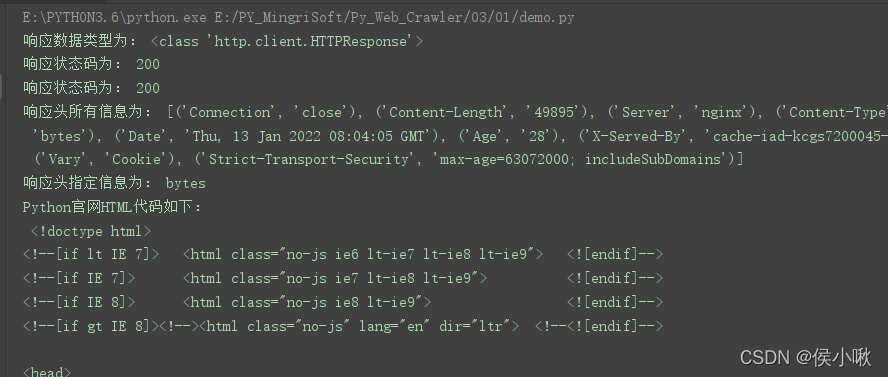
print('响应数据类型为:', type(response))
print('响应状态码为:', response.status)
print('响应状态码为:', response.getcode())
print('响应头所有信息为:', response.getheaders())
print('响应头指定信息为:', response.getheader('Accept-Ranges'))
# 读取HTML代码并进行utf-8解码
print('Python官网HTML代码如下:\n', response.read().decode('utf-8'))
输出结果如下(部分):
- response是一个<class ‘http.client.HTTPResponse’>对象;
- 响应状态码也称响应码,也称状态码,可以通过status属性查看,也可以通过getcode()方法查看。
- getheaders()用于查看响应头所有信息
- getheader()中传入参数,用于查看响应头的指定信息。
- 关于请求头&响应头
当你使用http(https)协议请求一个网站的时候,你的浏览器会向对方的服务器发送一个http请求,这个请求同样包含三个部分
- 请求方法 请求路径(URL) 请求协议版本
例:GET https://www.google.com.hk/ HTTP/1.1 - 报文主体
- (POST/GET)参数
当你向对方发送请求后,对方会回应你浏览器的请求,返回两个部分:响应头,Body
Body就是返回给你的主体,比如说请求网站返回的html
响应头讯息里包含了服务器的响应讯息,如http版本,压缩方式,响应文件类型,文件编码等
4.发送post请求
即在上边基础上,在urlopen()函数中写入data参数。详情参考链接:python爬虫post访问案例-有道翻译。
- post请求会携带一些form表单数据,这个需要复制过来以字典形式写入。
表单数据在网页上点击F12后,在Fetch/XHR一栏中的Payload中获取。
以爬取有道翻译,翻译“你好”为例,此时的表单数据如下:
i: 你好
from: AUTO
to: AUTO
smartresult: dict
client: fanyideskweb
salt: 16417380413821
sign: 6545acd2d928b39eb5bead9349a2d4ff
lts: 1641738041382
bv: fdac15c78f51b91dabd0a15d9a1b10f5
doctype: json
version: 2.1
keyfrom: fanyi.web
action: FY_BY_REALTlME
代码示例如下:
import urllib.request
import urllib.parse
import json
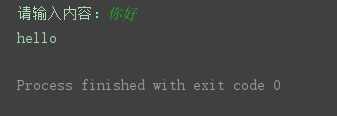
# 要进行输入内容
key = input("请输入内容:")
data = {
"i": key,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": "16374132986488",
"sign": "dfd139af546a8cd63de0676f446ca2ee",
"lts": "1637413298648",
"bv": "03a6a27012b22bc3c7ecc76381772182",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME",
}
# 字节流,如果输入中文,需要处理的
data = urllib.parse.urlencode(data) # 转为十六进制形式
data = bytes(data, encoding='utf8') # 转为字节流
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
# 目标url发请求
# {"errorCode":50} ,把_o
url = 'https://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
# 构建请求对象
req = urllib.request.Request(url, data=data, headers=headers)
# 发请求,获取响应对象
res = urllib.request.urlopen(req)
# print(res.getcode()) # 得到响应码,200表示请求成功
html = res.read().decode('utf-8')
# print(type(html)) # <class 'str'>,得到的是json数据
# json数据转字典
dic = json.loads(html)
result = dic["translateResult"] # [[{'src': '你好', 'tgt': 'hello'}]]
print(result[0][0]['tgt'])
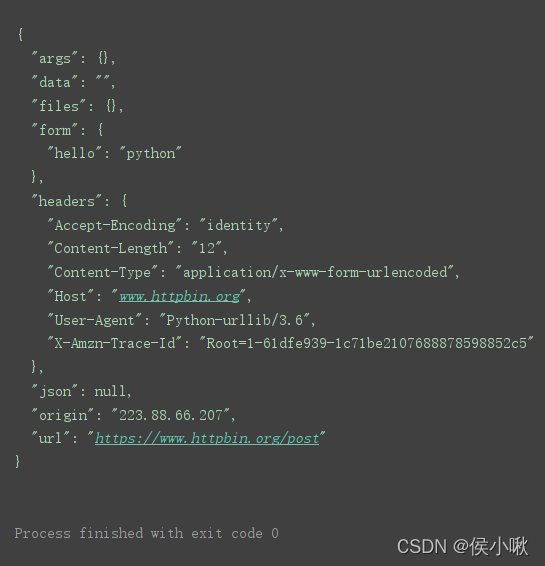
另一个简单的示例:
import urllib.request # 导入urllib.request模块
import urllib.parse # 导入urllib.parse模块
url = 'https://www.httpbin.org/post' # post请求测试地址
# 将表单数据转换为bytes类型,并设置编码方式为utf-8
print()
data = bytes(urllib.parse.urlencode({
'hello': 'python'}), encoding='utf-8')
response = urllib.request.urlopen(url=url, data=data) # 发送网络请求
print(response.read().decode('utf-8')) # 读取HTML代码并进行
5. 设置网络超时
urlopen()的timeout参数用于设置请求超时,该参数以秒为单位,表示如果在请求时超出了设置的时间还没有得到响应时就会抛出异常。
import urllib.request
url = 'https://www.python.org/'
response = urllib.request.urlopen(url=url, timeout=0.1) # 设置超时时间为0.1秒
print(response.read().decode('utf-8'))
因为0.1秒设置的过快,结果因超时而产生异常,报错。
通常根据网络环境不同,设置一个合理的时间,如2秒,3秒。
对该网络超时异常进行捕捉并处理:
import urllib.request # 导入urllib.request模块
import urllib.error # 导入urllib.error模块
import socket # 导入socket模块
url = 'https://www.python.org/' # 请求地址
try:
# 发送网络请求,设置超时时间为0.1秒
response = urllib.request.urlopen(url=url, timeout=0.1)
print(response.read().decode('utf-8')) # 读取HTML代码并进行utf-8解码
except urllib.error.URLError as error: # 处理异常
if isinstance(error.reason, socket.timeout): # 判断异常是否为超时异常
print('当前任务已超时,即将执行下一任务!')

6. 复杂网络请求_urllib.request.Request()
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
参数说明:
- url:访问网站的完整url地址
- data:默认为None,表示请求方式为get请求;如果需要实现post请求,需要字典形式的数据作为参数。
- headers:设置请求头部信息,字典类型。
- origin_req_host:用于设置请求方的host名称或者IP。
- unverifiable:用于设置网页是否需要验证,默认值为False。
- method:用于设置请求方式,如GET,POST。
7.设置请求头
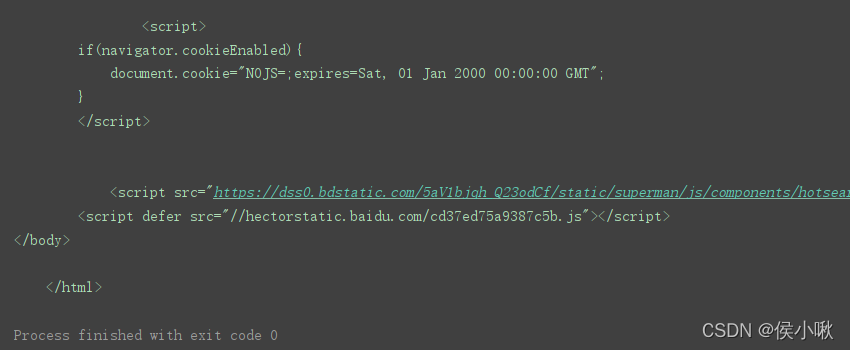
7.1get请求示例
url = 'https://www.baidu.com'
# 定义请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'}
# 创建Request对象
r = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(r) # 发送网络请求
print(response.read().decode('utf-8')) # 读取HTML代码并进行utf-8解码
7.2post请求示例
import urllib.request # 导入urllib.request模块
import urllib.parse # 导入urllib.parse模块
url = 'https://www.httpbin.org/post' # 请求地址
# 定义请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'}
# 将表单数据转换为bytes类型,并设置编码方式为utf-8
data = bytes(urllib.parse.urlencode({
'hello': 'python'}),encoding='utf-8')
# 创建Request对象
r = urllib.request.Request(url=url,data=data,headers=headers,method='POST')
response = urllib.request.urlopen(r) # 发送网络请求
print(response.read().decode('utf-8')) # 读取HTML代码并进行utf-8解码
创建出一个Request对象,然后直接调用urlopen()函数。
创建Request也被称为创建请求对象。

8. Cookies的获取与设置
Cookies是服务器向客户端返回响应数据时所留下的标记。当客户再次访问服务器时会携带这个标记。一般登录一个页面成功后,会在浏览器的cookie中保留一些信息,再次访问时服务器核对后即可确认当前用户登录过,此时可直接将登录后的数据返回。
import urllib.request
url = "https://www.csdn.net/"
opener = urllib.request.build_opener() # 获取opener对象
resp = opener.open(url)
print(resp.read().decode())
因为urlopen()方法不支持代理、cookie等其他的HTTP/GTTPS高级功能,所以这里不用urlopen()发送请求,而需要创建一个opener对象(这本来是urllib2中的方法)。示例如下。学习过程中这里作为了解即可,建议重点研究/使用requests库。
import urllib.request # 导入urllib.request模块
import http.cookiejar # 导入http.cookiejar子模块
# 登录后页面的请求地址
url = 'xxx'
cookie_file = 'cookie.txt' # cookie文件
cookie = http.cookiejar.LWPCookieJar() # 创建LWPCookieJar对象
# 读取cookie文件内容
cookie.load(cookie_file,ignore_expires=True,ignore_discard=True)
# 生成cookie处理器
handler = urllib.request.HTTPCookieProcessor(cookie)
# 创建opener对象
opener = urllib.request.build_opener(handler)
response = opener.open(url) # 发送网络请求
print(response.read().decode('utf-8')) # 打印登录后页面的html代码
9.设置代理IP
import urllib.request # 导入urllib.request模块
url= 'xxxxxxxxxxxxxxx'
# 创建代理IP
proxy_handler = urllib.request.ProxyHandler({
'https': 'xxxxxxxxxxxxxxxxx' # 写入代理IP
})
# 创建opener对象
opener = urllib.request.build_opener(proxy_handler)
response = opener.open(url,timeout=2)
print(response.read().decode('utf-8'))
10.异常处理
urllib模块中的urllib.error子模块包含了URLError与HTTPError两个比较重要的异常类。
10.1 URLError
URLError类提供了一个reason属性,可以通过这个属性了解错误的原因。示例如下:
import urllib.request # 导入urllib.request模块
import urllib.error # 导入urllib.error模块
try:
# 向不存在的网络地址发送请求
response = urllib.request.urlopen('https://www.python.org/1111111111.html')
except urllib.error.URLError as error: # 捕获异常信息
print(error.reason) # 打印异常原因
程序运行结果:
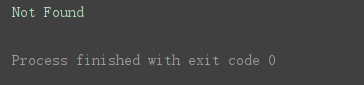
10.2HTTPError
HTTPError类是URLError的子类,主要用于处理HTTP请求所出现的一次。此类有以下三个属性。
- code :返回HTTP状态码
- reason 返回错误原因
- headers 返回请求头
import urllib.request # 导入urllib.request模块
import urllib.error # 导入urllib.error模块
try:
# 向不存在的网络地址发送请求
response = urllib.request.urlopen('https://www.python.org/1111111111.html')
print(response.status)
except urllib.error.HTTPError as error: # 捕获异常信息
print('状态码为:',error.code) # 打印状态码
print('异常信息为:',error.reason) # 打印异常原因
print('请求头信息如下:\n',error.headers) # 打印请求头
结果如下(部分):
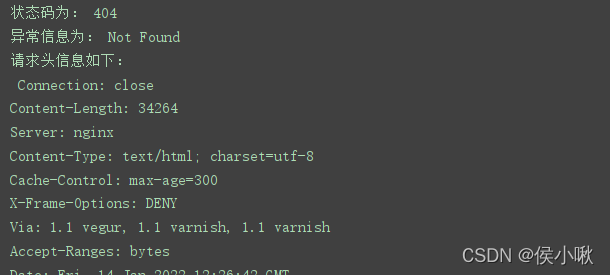
10.3URLError&HTTPError双重异常捕捉
因为URLError是HTTPError的父类,所以在捕获异常的时候可以先找子类是否异常,父类的异常应当写到子类异常的后面,如果子类捕获不到,那么可以捕获父类的异常。
URLError产生的原因主要是
-
- 网络没有连接,
-
- 服务器连接失
-
- 找不到指定的服务器。
当使用urlopen或 opener.open 不能处理的,服务器上都对应一个响应对象,其中包含一个数字(状态码),如果urlopen不能处理,urlopen会产生一个相应的HTTPError对应相应的状态码,HTTP状态码表示HTTP协议所返回的响应的状态码。
import urllib.request # 导入urllib.request模块
import urllib.error # 导入urllib.error模块
try:
response = urllib.request.urlopen('https://www.python.org/',timeout=0.1)
except urllib.error.HTTPError as error: # HTTPError捕获异常信息
print('状态码为:',error.code) # 打印状态码
print('HTTPError异常信息为:',error.reason) # 打印异常原因
print('请求头信息如下:\n',error.headers) # 打印请求头
except urllib.error.URLError as error: # URLError捕获异常信息
print('URLError异常信息为:',error.reason)
这里访问了一个真实存在的URL,输出结果为:

11.解析URL
urllin模块提供了parse子模块用来解析URL。
11.1 拆分URL
urlparse()方法
parse子模块提供了urlparse()方法,实现将URL分解成不同部分,语法格式如下:
urllib.parse.urlparse(urlstring,scheme=’’,allow_fragment=True)
- urlstring:需要拆分的URL,必选参数。
- scheme:可选参数,需要设置的默认协议,默认为空字符串,如果要拆分的URL中没有协议,可通过该参数设置一个默认协议。
- allow_fragment:可选参数,如果该参数设置为False,则表示忽略fragment这部分内容,默认为True。
示例:
import urllib.parse #导入urllib.parse模块
parse_result = urllib.parse.urlparse('https://docs.python.org/3/library/urllib.parse.html')
print(type(parse_result)) # 打印类型
print(parse_result) # 打印拆分后的结果
程序运行结果:

用此方法,除了返回ParseResult对象以外,还可以直接获取ParseResult对象中的每个属性值:
print('scheme值为:', parse_result.scheme)
print('netloc值为:', parse_result.netloc)
print('path值为:', parse_result.path)
print('params值为:', parse_result.params)
print('query值为:', parse_result.query)
print('fragment值为:', parse_result.fragment)
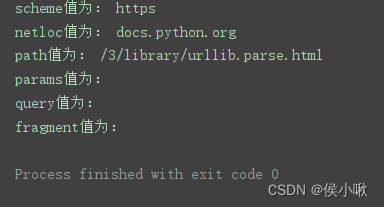
urlsplit()方法
urlsplit()方法与urlparse()方法类似,都可以实现URL的拆分。只是urlsplit()方法不再单独拆分params这部分内容,而是将params合并到path中,所以返回结果只有5部分内容。且返回的数据类型为SplitResult。
import urllib.parse #导入urllib.parse模块
# 需要拆分的URL
url = 'https://docs.python.org/3/library/urllib.parse.html'
print(urllib.parse.urlsplit(url)) # 使用urlsplit()方法拆分URL
print(urllib.parse.urlparse(url)) # 使用urlparse()方法拆分URL
程序运行结果:

11.2 组合URL
urlunparse()方法
urlunparse()方法实现URL的组合
语法:urlunparse(parts)
parts表示用于组合url的可迭代对象
import urllib.parse #导入urllib.parse模块
list_url = ['https', 'docs.python.org', '/3/library/urllib.parse.html', '', '', '']
tuple_url = ('https', 'docs.python.org', '/3/library/urllib.parse.html', '', '', '')
dict_url = {
'scheme': 'https', 'netloc': 'docs.python.org', 'path': '/3/library/urllib.parse.html', 'params': '', 'query':'', 'fragment': ''}
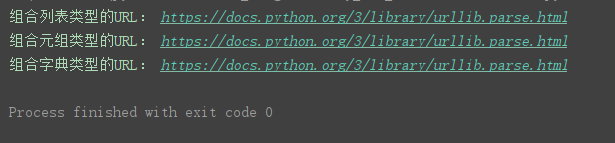
print('组合列表类型的URL:', urllib.parse.urlunparse(list_url))
print('组合元组类型的URL:', urllib.parse.urlunparse(tuple_url))
print('组合字典类型的URL:', urllib.parse.urlunparse(dict_url.values()))
程序运行结果:
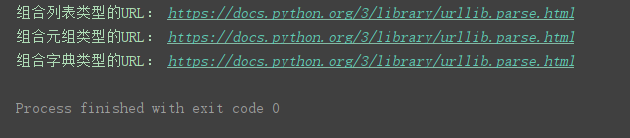
urlunsplit()方法
同样用于URL组合,只是参数中的元素必须是5个。
import urllib.parse #导入urllib.parse模块
list_url = ['https', 'docs.python.org', '/3/library/urllib.parse.html', '', '']
tuple_url = ('https', 'docs.python.org', '/3/library/urllib.parse.html', '', '')
dict_url = {
'scheme': 'https', 'netloc': 'docs.python.org', 'path': '/3/library/urllib.parse.html', 'query': '', 'fragment': ''}
print('组合列表类型的URL:', urllib.parse.urlunsplit(list_url))
print('组合元组类型的URL:', urllib.parse.urlunsplit(tuple_url))
print('组合字典类型的URL:', urllib.parse.urlunsplit(dict_url.values()))
程序运行结果
11.3 连接URL
用**urljoin()**方法来实现URL的连接。
urllib.parse.urljoin(base,url,allow_fragments=True)
- base 表示基础链接
- url 表示新的链接
- allow_fragments 为可选参数,默认为Ture,设为False则忽略fragment这部分内容。
import urllib.parse #导入urllib.parse模块
base_url = 'https://docs.python.org' # 定义基础链接
# 第二参数不完整时
print(urllib.parse.urljoin(base_url,'3/library/urllib.parse.html'))
# 第二参数完整时,直接返回第二参数的链接
print(urllib.parse.urljoin(base_url,'https://docs.python.org/3/library/urllib.parse.html#url-parsing'))
程序运行结果:

11.4 URL的编码与解码
使用urlencode()方法编码请求参数,该方法接收的参数值为字典。
示例
import urllib.parse # 导入urllib.parse模块
base_url = 'http://httpbin.org/get?' # 定义基础链接
params = {
'name': 'Jack', 'country': 'China', 'age': 18} # 定义字典类型的请求参数
url = base_url+urllib.parse.urlencode(params) # 连接请求地址
print('编码后的请求地址为:', url)
程序运行结果:

使用quote方法编码请求参数,该方法接收的参数值类型为字符串。
示例:
import urllib.parse #导入urllib.parse模块
base_url = 'http://httpbin.org/get?country=' # 定义基础链接
url = base_url + urllib.parse.quote('中国') # 字符串编码
print('编码后的请求地址为:', url)
程序运行结果:

使用unquote()方法解码请求参数,即逆向解码。
示例:
import urllib.parse #导入urllib.parse模块
u = urllib.parse.urlencode({
'country': '中国'}) # 使用urlencode编码
q = urllib.parse.quote('country=中国') # 使用quote编码
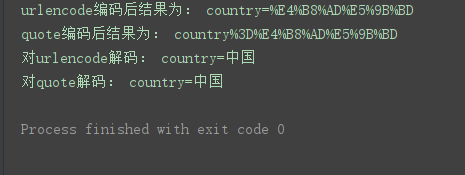
print('urlencode编码后结果为:', u)
print('quote编码后结果为:', q)
print('对urlencode解码:', urllib.parse.unquote(u))
print('对quote解码:', urllib.parse.unquote(q))
程序运行结果:
11.5URL参数的转换
使用parse_qs()方法将参数转换为字典类型。
import urllib.parse #导入urllib.parse模块
# 定义一个请求地址
url = 'http://httpbin.org/get?name=Jack&country=%E4%B8%AD%E5%9B%BD&age=30'
q = urllib.parse.urlsplit(url).query # 获取需要的参数
q_dict = urllib.parse.parse_qs(q) # 将参数转换为字典类型的数据
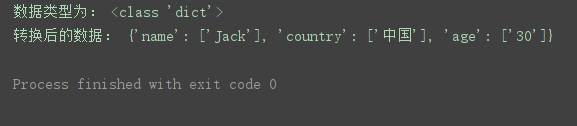
print('数据类型为:', type(q_dict))
print('转换后的数据:', q_dict)
(其中query是前边拆分部分提到的拆分结果对象的一个属性)
程序运行结果:
使用parse_qsl()方法将参数转换为元组组成的列表
import urllib.parse # 导入urllib.parse模块
str_params = 'name=Jack&country=%E4%B8%AD%E5%9B%BD&age=30' # 字符串参数
list_params = urllib.parse.parse_qsl(str_params) # 将字符串参数转为元组所组成的列表
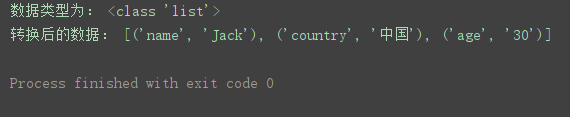
print('数据类型为:', type(list_params))
print('转换后的数据:', list_params)
程序运行结果:
智能推荐
5个超厉害的资源搜索网站,每一款都可以让你的资源满满!_最全资源搜索引擎-程序员宅基地
文章浏览阅读1.6w次,点赞8次,收藏41次。生活中我们无时不刻不都要在网站搜索资源,但就是缺少一个趁手的资源搜索网站,如果有一个比较好的资源搜索网站可以帮助我们节省一大半时间!今天小编在这里为大家分享5款超厉害的资源搜索网站,每一款都可以让你的资源丰富精彩!网盘传奇一款最有效的网盘资源搜索网站你还在为找网站里面的资源而烦恼找不到什么合适的工具而烦恼吗?这款网站传奇网站汇聚了4853w个资源,并且它每一天都会持续更新资源;..._最全资源搜索引擎
Book类的设计(Java)_6-1 book类的设计java-程序员宅基地
文章浏览阅读4.5k次,点赞5次,收藏18次。阅读测试程序,设计一个Book类。函数接口定义:class Book{}该类有 四个私有属性 分别是 书籍名称、 价格、 作者、 出版年份,以及相应的set 与get方法;该类有一个含有四个参数的构造方法,这四个参数依次是 书籍名称、 价格、 作者、 出版年份 。裁判测试程序样例:import java.util.*;public class Main { public static void main(String[] args) { List <Book>_6-1 book类的设计java
基于微信小程序的校园导航小程序设计与实现_校园导航微信小程序系统的设计与实现-程序员宅基地
文章浏览阅读613次,点赞28次,收藏27次。相比于以前的传统手工管理方式,智能化的管理方式可以大幅降低学校的运营人员成本,实现了校园导航的标准化、制度化、程序化的管理,有效地防止了校园导航的随意管理,提高了信息的处理速度和精确度,能够及时、准确地查询和修正建筑速看等信息。课题主要采用微信小程序、SpringBoot架构技术,前端以小程序页面呈现给学生,结合后台java语言使页面更加完善,后台使用MySQL数据库进行数据存储。微信小程序主要包括学生信息、校园简介、建筑速看、系统信息等功能,从而实现智能化的管理方式,提高工作效率。
有状态和无状态登录
传统上用户登陆状态会以 Session 的形式保存在服务器上,而 Session ID 则保存在前端的 Cookie 中;而使用 JWT 以后,用户的认证信息将会以 Token 的形式保存在前端,服务器不需要保存任何的用户状态,这也就是为什么 JWT 被称为无状态登陆的原因,无状态登陆最大的优势就是完美支持分布式部署,可以使用一个 Token 发送给不同的服务器,而所有的服务器都会返回同样的结果。有状态和无状态最大的区别就是服务端会不会保存客户端的信息。
九大角度全方位对比Android、iOS开发_ios 开发角度-程序员宅基地
文章浏览阅读784次。发表于10小时前| 2674次阅读| 来源TechCrunch| 19 条评论| 作者Jon EvansiOSAndroid应用开发产品编程语言JavaObjective-C摘要:即便Android市场份额已经超过80%,对于开发者来说,使用哪一个平台做开发仍然很难选择。本文从开发环境、配置、UX设计、语言、API、网络、分享、碎片化、发布等九个方面把Android和iOS_ios 开发角度
搜索引擎的发展历史
搜索引擎的发展历史可以追溯到20世纪90年代初,随着互联网的快速发展和信息量的急剧增加,人们开始感受到了获取和管理信息的挑战。这些阶段展示了搜索引擎在技术和商业模式上的不断演进,以满足用户对信息获取的不断增长的需求。
随便推点
控制对象的特性_控制对象特性-程序员宅基地
文章浏览阅读990次。对象特性是指控制对象的输出参数和输入参数之间的相互作用规律。放大系数K描述控制对象特性的静态特性参数。它的意义是:输出量的变化量和输入量的变化量之比。时间常数T当输入量发生变化后,所引起输出量变化的快慢。(动态参数) ..._控制对象特性
FRP搭建内网穿透(亲测有效)_locyanfrp-程序员宅基地
文章浏览阅读5.7w次,点赞50次,收藏276次。FRP搭建内网穿透1.概述:frp可以通过有公网IP的的服务器将内网的主机暴露给互联网,从而实现通过外网能直接访问到内网主机;frp有服务端和客户端,服务端需要装在有公网ip的服务器上,客户端装在内网主机上。2.简单的图解:3.准备工作:1.一个域名(www.test.xyz)2.一台有公网IP的服务器(阿里云、腾讯云等都行)3.一台内网主机4.下载frp,选择适合的版本下载解压如下:我这里服务器端和客户端都放在了/usr/local/frp/目录下4.执行命令# 服务器端给执_locyanfrp
UVA 12534 - Binary Matrix 2 (网络流‘最小费用最大流’ZKW)_uva12534-程序员宅基地
文章浏览阅读687次。题目:http://acm.hust.edu.cn/vjudge/contest/view.action?cid=93745#problem/A题意:给出r*c的01矩阵,可以翻转格子使得0表成1,1变成0,求出最小的步数使得每一行中1的个数相等,每一列中1的个数相等。思路:网络流。容量可以保证每一行和每一列的1的个数相等,费用可以算出最小步数。行向列建边,如果该格子是_uva12534
免费SSL证书_csdn alphassl免费申请-程序员宅基地
文章浏览阅读504次。1、Let's Encrypt 90天,支持泛域名2、Buypass:https://www.buypass.com/ssl/resources/go-ssl-technical-specification6个月,单域名3、AlwaysOnSLL:https://alwaysonssl.com/ 1年,单域名 可参考蜗牛(wn789)4、TrustAsia5、Alpha..._csdn alphassl免费申请
测试算法的性能(以选择排序为例)_算法性能测试-程序员宅基地
文章浏览阅读1.6k次。测试算法的性能 很多时候我们需要对算法的性能进行测试,最简单的方式是看算法在特定的数据集上的执行时间,简单的测试算法性能的函数实现见testSort()。【思想】:用clock_t计算某排序算法所需的时间,(endTime - startTime)/ CLOCKS_PER_SEC来表示执行了多少秒。【关于宏CLOCKS_PER_SEC】:以下摘自百度百科,“CLOCKS_PE_算法性能测试
Lane Detection_lanedetectionlite-程序员宅基地
文章浏览阅读1.2k次。fromhttps://towardsdatascience.com/finding-lane-lines-simple-pipeline-for-lane-detection-d02b62e7572bIdentifying lanes of the road is very common task that human driver performs. This is important ..._lanedetectionlite