AI算法工程师 | 01人工智能基础-快速入门_人工智能算法-程序员宅基地
文章目录
一、我们身处人工智能的时代
人工智能的时代
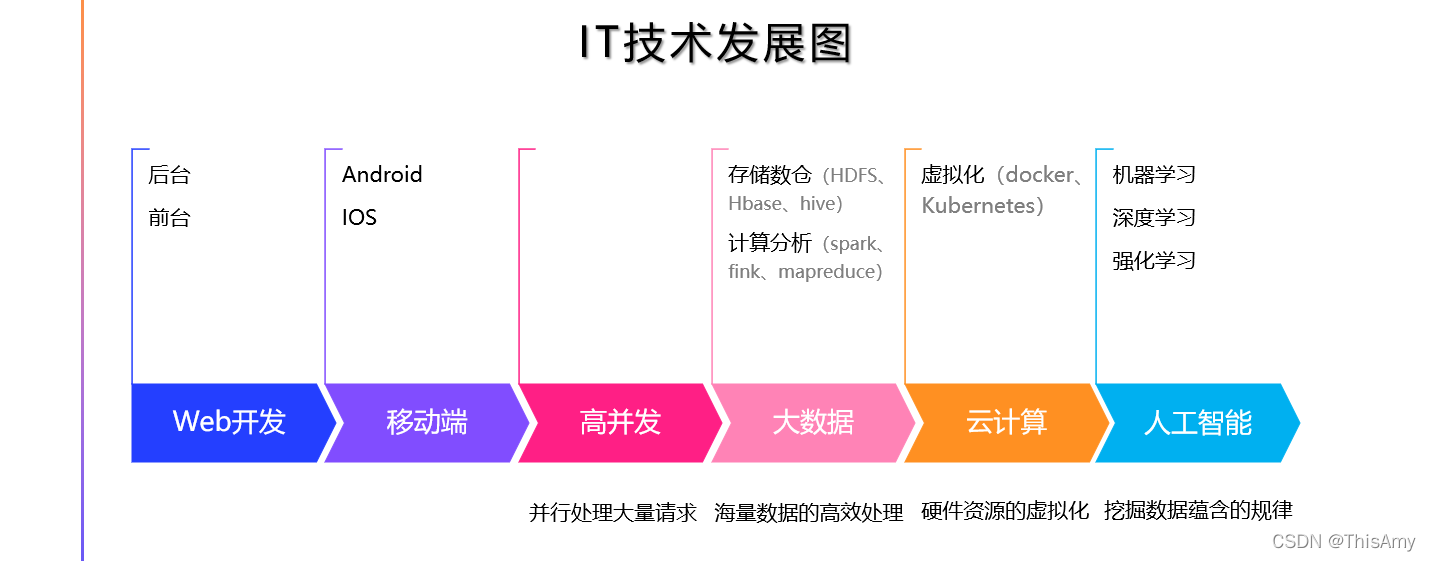
互联网时代的发展
站在互联网的角度理解人工智能:人工智能AI(artificial intelligence)是互联网时代发展的必然趋势。
人们从早期做web开发,到移动端的开发;之后随着数据量的增大,人们开始研究高并发的问题;当数据量不断的增大,而人们希望数据不被浪费时,产生了大数据的技术,包括:大数据的如何存储以及大量数据的如何计算分析;由于计算分析和存储需要资源,互联网便发展到通过云计算进行存储与计算,包括虚拟化的计算,如:docker,k8s;再到后来,人们不是仅仅局限于将数据进行存储和简单分析,更多的是想从数据中挖掘出价值,人们便想到了人工智能,因为人工智能中有很多的算法,可以帮助人们从数据中挖掘出价值。
注意,区分大数据和人工智能的概念:
① 大数据:专注于已有的数据的存储和计算,生成分析报表;
② 人工智能:专注于利用已有数据挖掘规律,对未来进行预测。
人工智能领域的技术
在人工智能领域中,其技术的发展具体有如下内容:
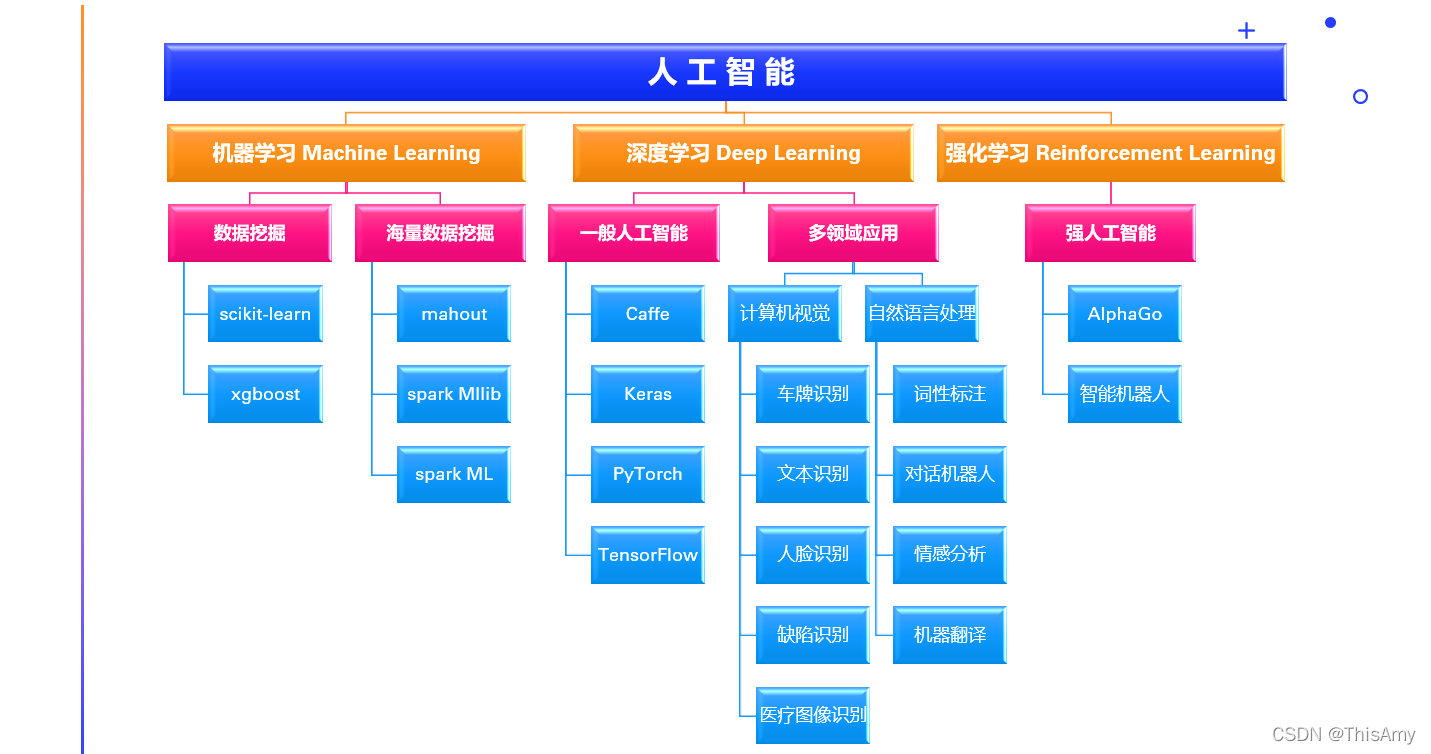
人工智能从早期的使用机器学习的算法来做数据挖掘,到分布式的进行数据挖掘;再到进一步的把算法研究得更加深入,走向了深度学习的领域,于是人们开始发现深度学习可以使更加复杂的问题(如:计算机视觉、自然语言处理)变得更加的准确,于是有了各种各样的应用;在人工智能发展过程中还存在强化学习,比如:利用强化学习的技术,在前几年有AlphaGo这样下围棋的机器人,近几年有各种各样的智能制造中使用到的机器人。这些都是应用人工智能产生的一些产业。
所以,人工智能是现在互联网中发展的一个大的趋势:如何更好的利用数据去挖掘数据中的价值,把挖掘到的数据的价值(规律)进行更好的应用,并对各行各业加以帮助。
人工智能的应用
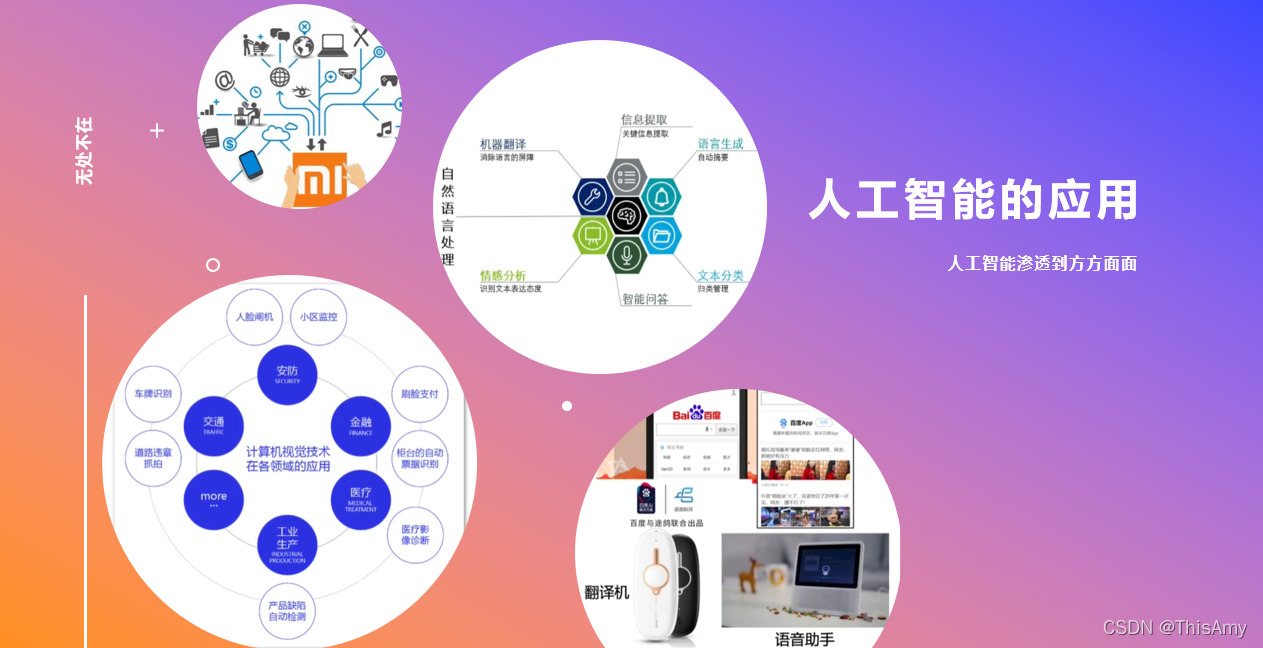
人工智能已经逐步渗透到生产生活中的方方面面,无论是医疗、教育、交通、物流,还是传统生产制造、金融、农业设置是军事、游戏,人工智能的身影无处不在,并发挥着越来越重要的作用。


二、人工智能的流程和基本概念
人工智能常见流程
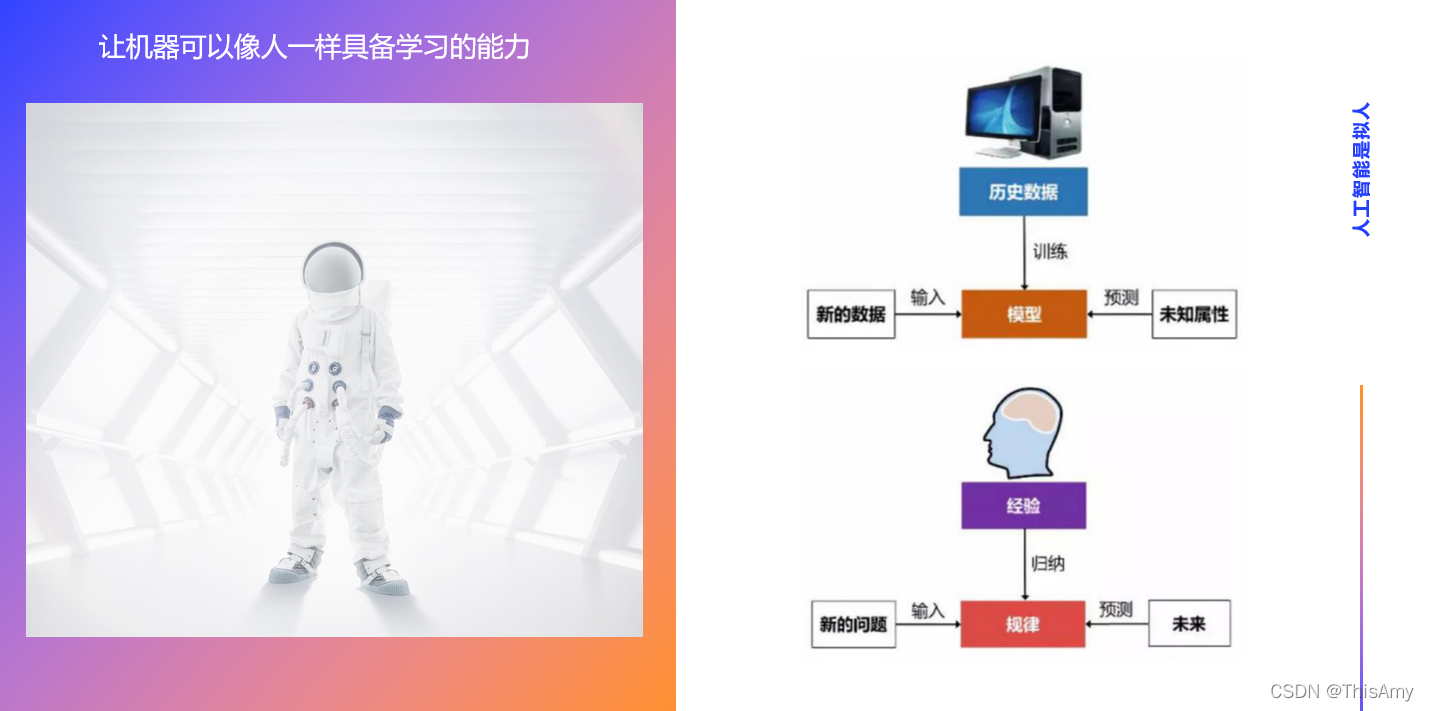
人工智能是拟人
灵魂三连问:
- 为什么说 “人工智能是拟人” ?因为人工智能的流程与思考的过程非常相像。
- 如何看现在的人工智能做得有多好?其越像人的思考过程,越和人的准确率接近,则该人工智能做得越好。
- 怎么理解人工智能是 “拟人” 这两个字?且看下文讲解 ↓↓↓
首先,需要理解的是何为人工智能?通俗来讲,人工智能就是让机器像人一样具备学习的能力。
其次,人工智能 AI 包含三大块内容,分别是:机器学习 ML(Machine Learning)、深度学习 DL(Deep Learning)、强化学习 RL(Reinforcement Learning)。
在早期的人工智能,人们会称为机器学习,是一些经典机器学习算法的统称。关于 “机器学习” ,可以用 “让机器像人一样具备学习的能力” 这句话来解释。但如何让机器像人一样具备学习的能力,做到人工智能呢?这需要先了解人类的思考过程。
- 人类的思考过程:人的大脑根据生活中的经验,归纳和总结出相对应的规律。这些规律可以使人们未来碰到新的问题时,能够将新的问题代入到脑海中,根据已有的规律来思考——当未来碰到该新问题时,应该给出什么样的预测结果,需进行怎样的决策。
- 人工智能流程对比人类思考的过程:
- 对于机器,它的大脑是计算能力(如CPU和内存,这些帮助机器来计算的,实际上就是它的大脑),而历史数据相当于人类的经验;
- 将数据交给计算机进行训练,训练的过程相当于像人一样归纳和总结相对应的规律;
- 在人工智能中,这些规律就是模型;
- 未来出现新的问题,即碰到新的数据,将新的数据代入到模型中去预测未知的属性,得到的结果便是预测值。
从中可以发现:这种对已有的数据进行训练得出某种模型,利用此模型预测结果的这一过程,与人类的思考过程非常类似。
人工智能的流程与本质
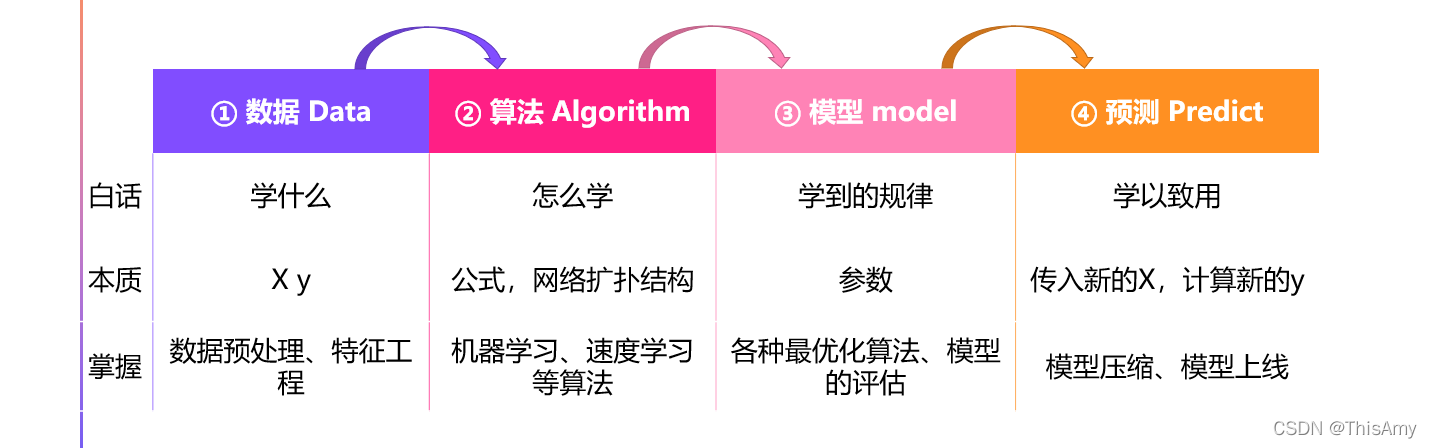
人工智能的流程:把数据代入到算法中,生成对应的模型,最终把模型上线,来进行预测。(即:数据预处理 → 算法求解 → 模型评估 → 模型上线)
人工智能的本质:把X、y代入公式中计算出参数(解方程组算出参数),当未来有新的X时,将其代入公式中得到预测的y(ŷ,叫做y hat)。
怎么才能猜的更准?“数据为王” 的思想。若拿到的历史数据,其数据质量越高,数据量越大,得到的参数就越可靠,于是通过该参数算出的值会越准确。
做工人智能的目的是——做预测;目标为——生成模型,而想要生成模型,需要数据和算法。
因此,对于人工智能来说,为了得到更好的模型结果,要不就是改算法(公式),要不就是找到更多等好的数据。
算法工程师:
① 核心任务是生成可以预测准确的模型
② 具备相关的代码能力
人工智能基本概念与区别
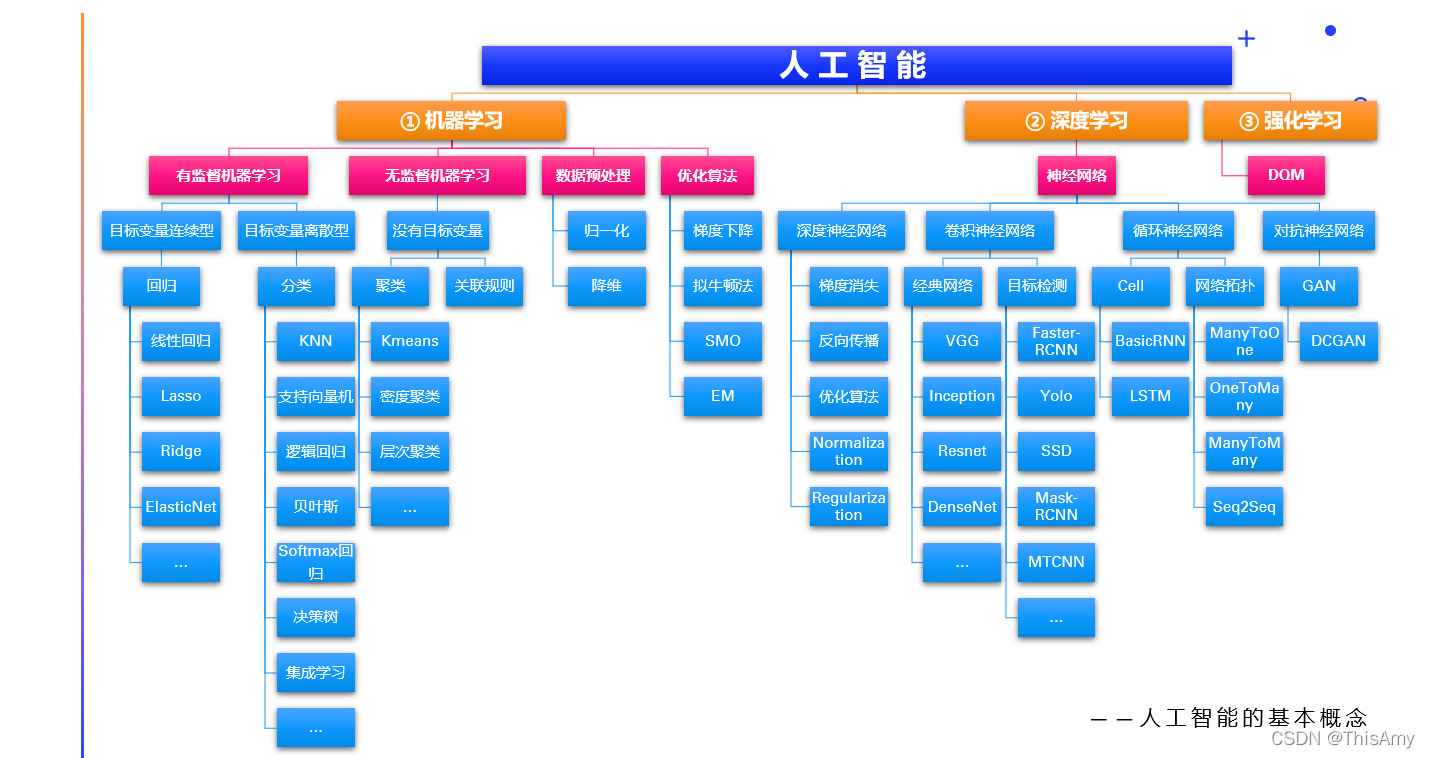
深度学习以前是机器学习的分支,因为深度学习是基于神经网络算法衍生出来的,由于近些年发展的很快,所有往往单独拎出来成为一门学科。
强化学习以前也只是机器学习的分支,随着现在深度强化学习(深度学习结合强化学习)的流行,也成为了一门学科,强化学习将来有望成为人工智能未来的明星。
机器学习不同的学习方式
人工智能中的核心是机器学习(Machine Learning,ML)。其原因是:机器学习研究的是各种各样的算法,算法是核心。
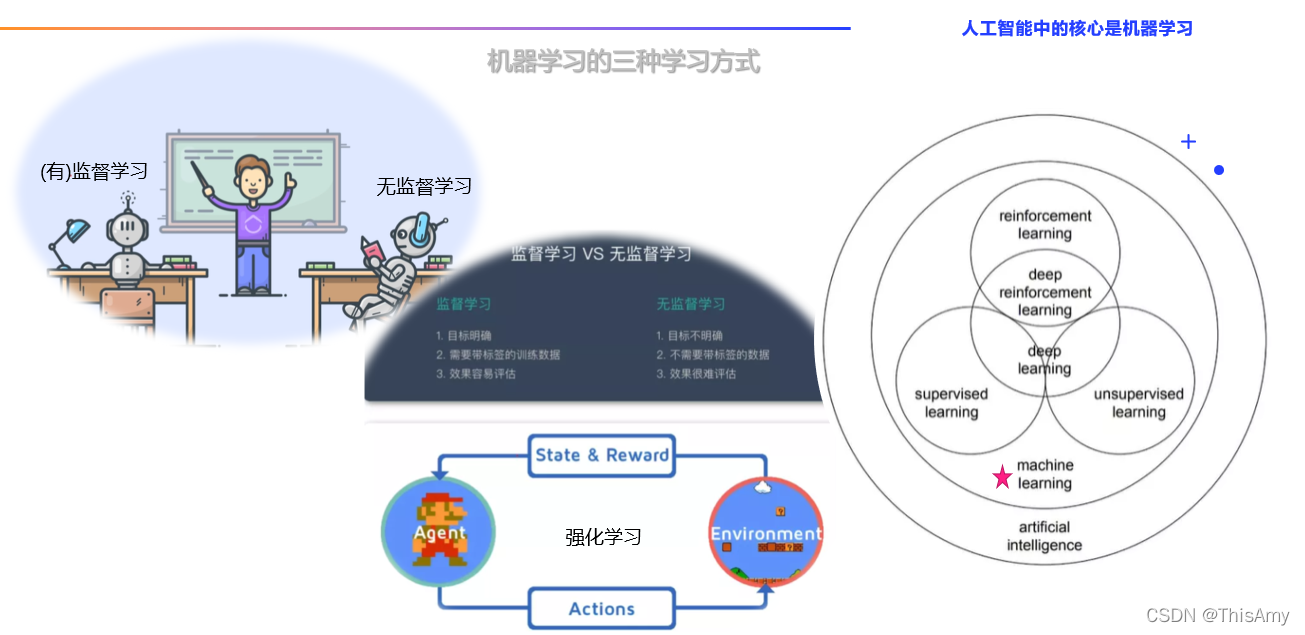
从学习方式上看,机器学习分为:有监督学习、无监督学习、强化学习
- 有监督学习(Supervised Learning, SL)
- 指原始数据中既有特征值也有标签值的机器学习
- 特点:① 目标明确 ② 需要带标签的训练数据 ③ 效果容易评估
- 无监督学习(Unsupervised Learning, UL)
- 其中没有需要预测或估计的目标变量(或标签值)
- 特点:① 目标不明确 ② 不需要带标签的训练数据 ③ 效果很难评估
- 强化学习(Reinforcement Learning, RL)
- 含义:让智能体与环境进行互动,不断学习以便调整策略的过程,这使智能体变得越来越聪明。
人工智能按照学习方式可分为:a. 有监督学习(数据集中有x和y)、b. 无监督学习(有x)、c. 半监督学习(有x和一部分y)、d. 强化学习(智能体与环境互动过程中产生数据,再代入算法中生成模型)。
深度学习比传统机器学习有优势
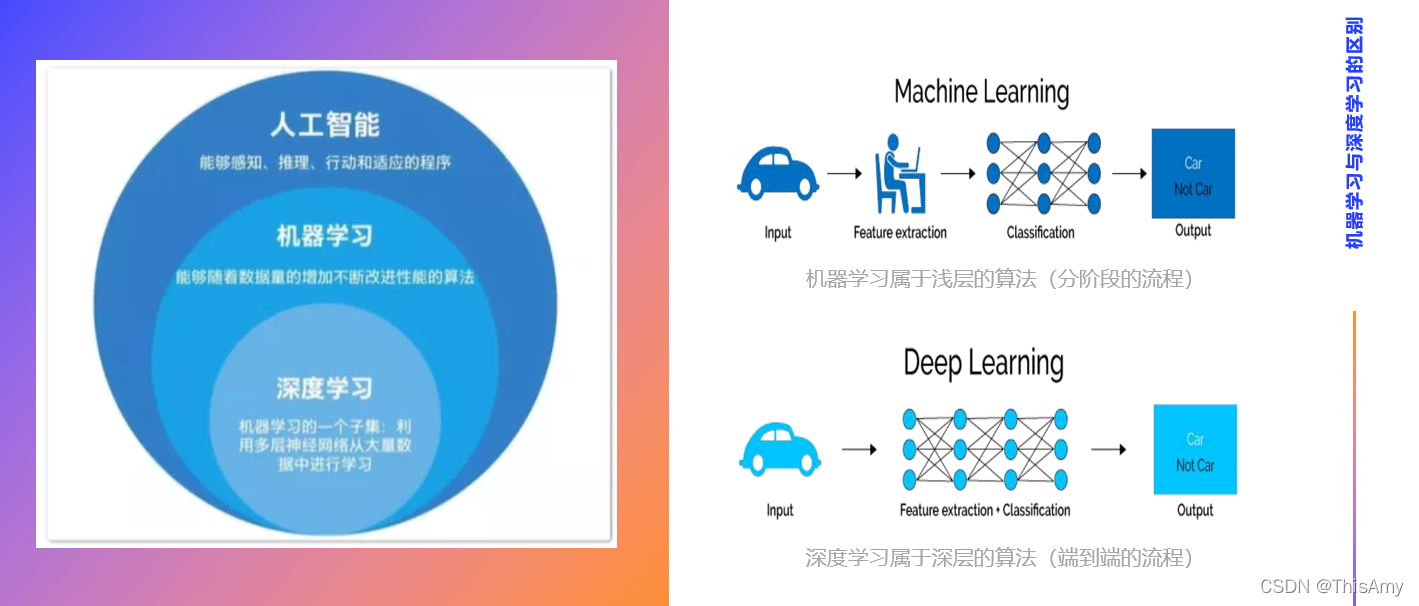
机器学习:人们更多的是把数据拿过来做特征的抽取(特征处理),这个过程更多的会有人为的参与,如:人为的选择用哪些算法,使用哪些数据做特征抽取。人为更多的参与预处理,将预处理后的数据交给后续的算法去生成算法中的参数。
机器学习和深度学习的区别:
① 机器学习属于浅层的算法(算法的公式不是特别复杂,更像分阶段的流程);
② 深度学习属于深层的算法(将提取特征的阶段放到整个神经网络中,更像端到端的流程)。
深度学习相比机器学习的优势:
① 是更端到端的学习方式;
② 由于网络层次更深,其可训练的参数更多(可以学习如何更好提取特征);
③ 可以解决更复杂的问题。
理解 —— 有多少人工就有多少智能(人工智能的本质)
- 机器学习:在特征工程中做的多好,最后的算法就能预测的有多准;
- 深度学习:设计的网络有多好,模型预测的就有多准确。
三、人工智能的常见任务和本质
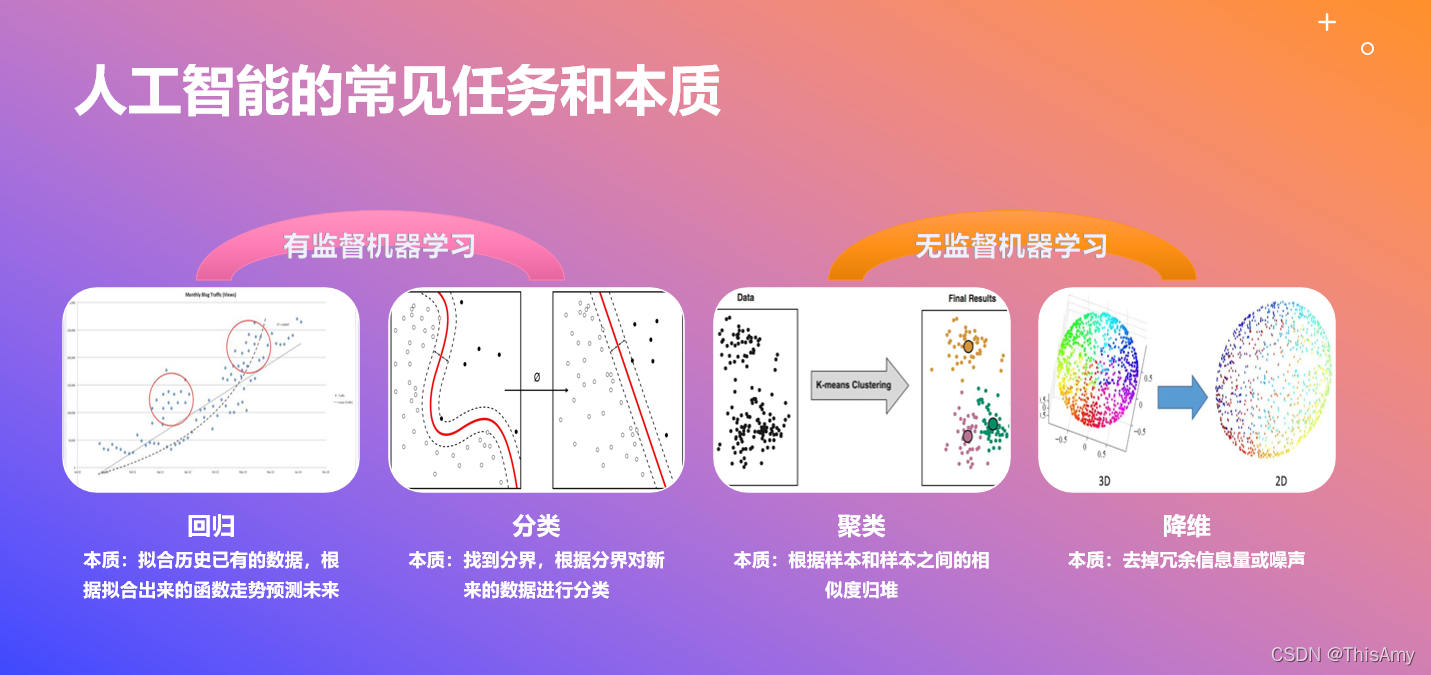
有监督机器学习任务与本质
做人工智能时,首先要明确需求是什么?预测的东西是什么?即:先明确有哪些任务,再选择相对应的算法。
回归、分类、聚类、降维都是机器学习中具体的任务。其中,① 回归和分类属于有监督机器学习;② 聚类和降维属于无监督机器学习。
回归 Regression
- 本质:拟合历史已有的数据,根据拟合出来的函数走势预测未来
- 目标:预测-inf 到+inf 之间具体的值,连续值
- 应用:股票预测(如:股票值的预测)、房价预测
分类 Classification
- 本质:找到分界,根据分界对新来的数据进行分类
- 目标:对新的数据预测出是各个类别的概率,正确的类别概率越大越好,最后通过选择概率最大的类别为最终类别,类别号 label 是离散值
- 应用:图像识别(如:识别该人是否戴安全帽)、情感分析(如:分析是正面情感还是负面情感)、银行风控(如:预测该人可承受怎样的风险,推荐不同的理财产品)
总结:
① 回归是做拟合,分类是找分界对应的超平面(通常超平面指:点、线、面)。
② 回归(连续型)和分类(离散型):有监督机器学习。具体看预测的值是离散型的还是连续型的,对应不同的分类。
③ 注意:股票预测中,若要预测未来某股票是会涨还是跌—— 分类任务,则需找分类所对应的算法去求相对应的分界线/面。
无监督机器学习任务与本质
无监督机器学习问题主要有两种:聚类、降维
聚类 Clustering
- 本质:根据样本和样本之间的相似度归堆
- 目标:将一批数据划分到多个组
- 应用:用户分组、异常检测、前景背景分离
降维 Dimensionality Reduction
- 本质:去掉冗余信息量或噪声
- 目标:将数据的维度减少
- 应用:数据的预处理、可视化、提高模型计算速度
总结:
① 聚类就是分组(归堆);降维类似于换个角度去审视原来的数据。
② 由于维度越多,速度越慢。所以,为提高模型运行速度,通常会做降维的任务。
智能推荐
初始化时checkbox选中问题-程序员宅基地
文章浏览阅读746次。首先我们大家在写页面的时候可能回经常遇到checkbox、radio等一些使选中或者是不选中的问题。这是我在项目当中做的时候发现的一个小知识点,把它赶紧记录下来。以便以后复习与巩固。 现把代码写出来再解释: function operateCheckOrRadio() { var sForm = document.getElementById("sform"); var sStatus = d..._flutter checkbox用变量初始化无法设置为选中状态
UE5——问题——MediaPlayer的使用播放视频注意点_ue mediaplayer-程序员宅基地
文章浏览阅读1.1k次。UE5——问题——MediaPlayer的使用播放视频注意点_ue mediaplayer
毕设仿真分享 单片机非接触式红外感应体温计-程序员宅基地
文章浏览阅读311次,点赞9次,收藏7次。非接触式电子体温计主要利用红外测温原理,一切温度高于绝对零度(-273.35℃)的物体,由于分子热运动,物体会不停地向外辐射能量。物体辐射能量的大小与它的表面温度有十分密切的关系。因此,通过测量物体辐射的能量,就能够测量出物体的温度。本用户手册中的非接触式电子体温计就是利用这种测量方法,实现测量人体体温的功能。
Vista/Win7下普通权限进程动态提升权限_findwindow 没有权限-程序员宅基地
文章浏览阅读2k次。本文出自 “碧海笙箫” 博客,请务必保留此出处http://pyhcx.blog.51cto.com/713166/197073一、前提在Vista/Win7下,加强了对安全的管理,对注册表修改,系统目录的文件操作,都需要管理员权限才能完成(当然虚拟存储机制,表面上也相当于能操作)。所以,对于程序中有相关操作的,这时候,就要求我们的程序必须拥有管理员权限。通过mainfest文件,我们可以让程序总是需要管理员权限执行,但是,这将导致程序每次运行时,都需要弹出UAC框老骚扰用户,另外,有时候我们的程序只是在某_findwindow 没有权限
PCS7 入门指南 v9.0 SP3 v9.1 中文版 学习资料 (官方公开可用资料)_pcs7v9.1-程序员宅基地
文章浏览阅读1.8w次,点赞13次,收藏82次。链接:https://pan.baidu.com/s/1-p4h_QDL8BN04tnn3vSkOA提取码:nou3PCS7入门指南v9.0含APL(包含PDF和项目文件)官方地址:SIMATIC 过程控制系统 PCS 7 入门指南第1部分 (V9.0,含APL)https://support.industry.siemens.com/cs/document/109756196/simatic-%E8%BF%87%E7%A8%8B%E6%8E%A7%E5%88%B6%E7%B3%BB..._pcs7v9.1
c# 调用非托管代码_c# 声明kernel32 函数-程序员宅基地
文章浏览阅读956次,点赞3次,收藏5次。编程过程中,一般c#调用非托管的代码有两种方式:1.直接调用从DLL中导出的函数。2.调用COM对象上的接口方法。首先说明第1种方式,基本步骤如下:1.使用关键字static,extern声明需要导出的函数。2.把DllImport 属性附加到函数上。3.掌握常用的数据类型传递的对应关系。4.如果需要,为函数的参数和返回值指定自定义数据封送处理信息,这将重写.net framework默认的封送处理。简单举例如下:托管函数原型:DWORD GetShortPathName(LPCTST_c# 声明kernel32 函数
随便推点
ES6——Map和Set-程序员宅基地
文章浏览阅读608次。ES6新增的数据类型,Map、Set之间的关系,如何使用?Map和Set的属性和方法。
FP-Growth算法全解析:理论基础与实战指导_pyfpgrowth库-程序员宅基地
文章浏览阅读574次。FP-Growth(Frequent Pattern Growth,频繁模式增长)算法是一种用于数据挖掘中频繁项集发现的有效方法。它是由Jian Pei,Jiawei Han和Runying Mao在2000年的论文中首次提出的。该算法主要应用于事务数据分析、关联规则挖掘以及数据挖掘领域的其他相关应用。_pyfpgrowth库
MySQL安装与环境变量配置_mysql-installer-web-community-5.7.35.0.msi .net-程序员宅基地
文章浏览阅读299次。一、下载MySQL:mysql-installer-web-community-5.7.35.0.msi二、安装双击下载的msi安装文件,弹出安装界面根据指示进行下一步的安装。选择安装的产品,分别为:MySQL Server、MySQL Workbench,然后Next一路执行execute和next。直到设置root用户的密码一路next三、配置环境变量为了能在cmd中使用mysql,需要将安装路径的bin配置到环境变量path中。在 ._mysql-installer-web-community-5.7.35.0.msi .net
JSON(一):JSON的定义及常用的Java-JSON库_java和.net怎么去定义json的格式-程序员宅基地
文章浏览阅读254次。目录 一、JSON是什么?二、序列化和反序列化三、JSON两种数据结构和表示形式四、Java语言的常见JSON库五、JSON的应用场景资料一、JSON是什么?1、JSON:JavaScript Object Notation(JavaScript对象表示法)。2、JSON 是轻量级的文本数据交换格式。和 XML类似,比 XML更小、更快,更易解析。3、J..._java和.net怎么去定义json的格式
优化算法——拟牛顿法之BFGS算法-程序员宅基地
文章浏览阅读6.2w次,点赞25次,收藏188次。一、BFGS算法简介 BFGS算法是使用较多的一种拟牛顿方法,是由Broyden,Fletcher,Goldfarb,Shanno四个人分别提出的,故称为BFGS校正。 同DFP校正的推导公式一样,DFP校正见博文“优化算法——拟牛顿法之DFP算法”。对于拟牛顿方程:可以化简为:令,则可得:在B_bfgs算法
联想RD430服务器的Raid 5阵列+Esxi6.7部署_esxi6 raid m5015-程序员宅基地
文章浏览阅读3.9k次。一、主要解决的问题:(一)硬盘存储总容量提高+读写速率快1、原RD430服务器主板自带阵列卡仅支持Raid 0、Raid 1、Raid 10,主要特点:Raid 0速率快但是某一块硬盘物理故障后,所有数据都将丢失;Raid 1需要一半的硬盘做冗余,容量牺牲较多,速率比Raid 0降一倍。Raid 10容量牺牲一半,速率比Raid1稍快。2、独立阵列卡的Raid 5特点:Raid 5改进的特点:比如8个硬盘做成的阵列,总容量少1块硬盘的空间,某数据分布于不同的7个硬盘上,另1块硬盘进行数据校验,校验_esxi6 raid m5015