”Scrapy爬虫框架“ 的搜索结果
Scratch,是抓取的意思,这个Python的爬虫框架叫Scrapy,大概也是这个意思吧,就叫它:小刮刮吧。 小刮刮是一个为遍历爬行网站、分解获取数据而设计的应用程序框架,它可以应用在广泛领域:数据挖掘、信息处理和或者...
本文我们通过抓取Quotes网站完成了整个Scrapy的简单入门,到此为止我们应该能对Scrapy的基本用法有一个初步的概念了。不过本文内容仅仅是Scrapy所有功能的冰山一角,还有很多内容等待我们去探索,我们后续文章继续...
Scrapy 爬虫框架 1. 概述 Scrapy是一个可以爬取网站数据,为了提取结构性数据而编写的开源框架。Scrapy的用途非常广泛,不仅可以应用到网络爬虫中,还可以用于数据挖掘、数据监测以及自动化测试等。Scrapy是基于...
Scrapy是一个功能强大并且非常快速的网络爬虫框架,是非常优秀的python第三方库,也是基于python实现网络爬虫的重要的技术路线。 Scrapy的安装: 直接在命令提示符窗口执行pip install scrapy貌似不行。 我们需要先...
本系统采用Scrapy爬虫框架来开发,使用Xpath网页提取技术对下载网页进行内容解析,使用Redis做分布式,使用MongoDB对提取的数据进行存储,使用Django开发可视化界面对爬取的结果进行友好展示,设计并实现了针对链家...
本系统采用Scrapy爬虫框架来开发,使用Xpath网页提取技术对下载网页进行内容解析,使用Redis做分布式,使用MongoDB对提取的数据进行存储,使用Django开发可视化界面对爬取的结果进行友好展示,设计并实现了针对链家...
大家好我是小菜鸡,让我们一起学习Python的网络爬虫框架-Scrapy爬虫框架的使用(一起努力,咱们顶峰相见!!!)
scrapy爬虫框架
标签: python


Scrapy是一个基于Python的开源网络爬虫框架,用于从网页中提取数据。它提供了一套高效、灵活和可扩展的工具,可以帮助开发者快速构建和部署爬虫程序Scrapy是一个由Python语言开发的适用爬取网站数据、提取结构性数据...
本资源提供了一套基于Python的Scrapy爬虫框架与Scrapy-Redis分布式爬虫的设计源码,包含61个文件,其中包括51个Python源代码文件,7个配置文件,以及1个Git忽略文件。此外,还包括1个文本文件和1个Markdown文档。...
【课程简介】 本课程适合所有需要弥补python网络爬虫的同学,课件内容制作精细,由浅入深...10-Scrapy爬虫框架(共34页).pptx 11-Scrapy爬虫基本使用(共32页).pptx 12-实例4-股票数据定向Scrapy爬虫(共23页).pptx
本源码提供了一个基于Python的Scrapy爬虫框架设计。项目包含20个文件,其中包括6个Python字节码文件、6个Python源文件、3个XML文件、1个Gitignore文件、1个IML文件、1个CSV文件、1个TXT文件和1个CFG文件。这个项目是...
Python Scrapy爬虫框架安装和创建
scrapy 是 python 写的爬虫框架,代码架构借鉴于django,灵活多样,功能强大。
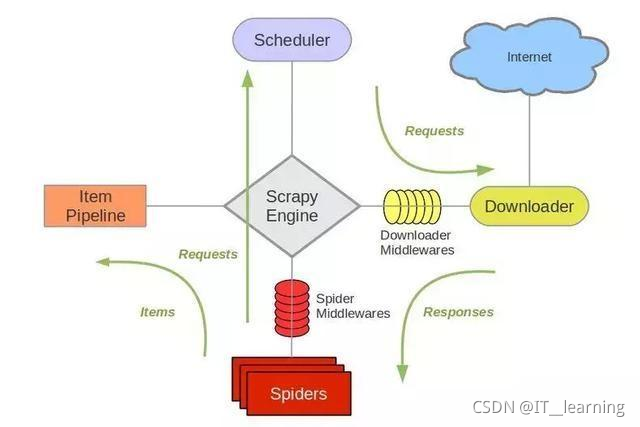
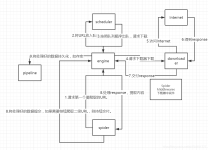
通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。1.引擎(Engine)– 引擎负责控制数据流在系统所有组件中的流向,并在不同的条件时触发相对应的事件。这个组件相当于爬虫的“大脑”...
Python实现的基于Scrapy爬虫框架和Django框架的新闻采集和订阅系统 摘要 随着互联网的迅速发展,互联网大大提升了信息的产生和传播速度,网络上每天都会产生大量的内容,如何高效地从这些杂乱无章的内容中发现并采集...
Scrapy爬虫框架 笔趣阁小说抓取 知识点:Scrapy爬虫框架使用 Scrapy爬虫框架使用 scrapy爬虫开发的基本步骤 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目 明确目标 (编写items.py):明确你想要抓取...
crapy是一个强大、灵活且开源的Python网络爬虫框架,用于抓取网站数据并提取结构化信息。它是专门为高效、快速、可扩展的数据爬取而设计的,广泛应用于网络数据挖掘、信息收集、搜索引擎索引和数据分析等领域。...
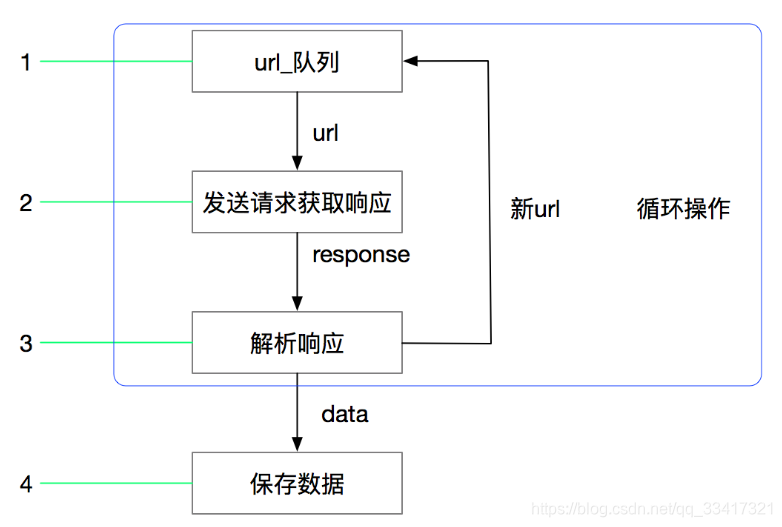


文章目录scrapy 简介scrapy 构架图scrapy 运作过程 scrapy 简介 scrapy 构架图 scrapy 运作过程
scrapy爬虫框架课程,包含全部课件与代码课程纲要:1.scrapy的概念作用和工作流程2.scrapy的入门使用3.scrapy构造并发送请求4.scrapy模拟登陆5.scrapy管道的使用6.scrapy中间件的使用7.scrapy_redis概念作用和流程8....
上篇我们记录了Scrapy的各个组件功能,这篇我们来动手scrapy爬虫框架的依赖库搭建和项目创建,开始进入进阶实战。
基于vue前端框架/scrapy爬虫框架/结巴分词实现的小型搜索引擎 整体实现 大体流程如下: 1.爬虫爬取网页数据,保存在文件中, 2.python读取文件内容,存到数据库表中,使用结巴分词对网页内容进行分词,并获得...
Python实现爬虫是很容易的,一般来说就是获取目标网站的页面,对目标页面的分析、解析、识别,提取有用的信息,然后该入库的入库,该下载的下载。...这次介绍通过Scrapy爬虫框架来实现同样的功能。
推荐文章
- Android 编译so文件 MP4V2_android下编译mp4v2-程序员宅基地
- 通讯录Contact_02_contact文件内容-程序员宅基地
- Qt笔记(四十二)之QZXing的编译 配置 使用_qzxingfilterrunnable error:-程序员宅基地
- 关于画图软件Dia打开程序始终为英文界面的问题-程序员宅基地
- OpenCV从入门到精通实战(二)——文档OCR识别(tesseract)-程序员宅基地
- 详解avcodec_receive_packet 11_avcodec_receive_packet eagain-程序员宅基地
- OpenGL SuperBible 7th源码编译记录_superbible7-media github-程序员宅基地
- Wireshark简单使用-程序员宅基地
- MXNet 粗糙的使用指南_iou loss mxnet-程序员宅基地
- iOS对ipa包进行代码混淆《二》 ---代码混淆_ipa包混淆-程序员宅基地