1)、Scrapy: Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化...Scrap,是碎片的意思,这个Python的爬虫框架叫Scrapy。 优点: 1.极其灵活的定制化爬取。 2.社区人
”爬虫框架“ 的搜索结果
在分享今天的内容之前,可能有同学会问了:什么是Python爬虫框架? 就像超市里有卖半成品的菜一样,Python爬虫工具也有半成品,就是Python爬虫框架。就是把一些常见的爬虫功能的代码先写好,然后留下一些借口。当...
go爬虫框架,快速的,强大的,可扩展的爬虫框架。持robots.txt * 支持自定义模块 * 支持Item管道处理 * 支持多种代理协议(socks5,http,https) * 支持XPath查询HTML/XML数据 * 做为框架,易于上手。

Scrapy框架是一个基于Twisted、Selector和Requests库的高效稳定的Python爬虫框架。它采用了事件驱动和异步模式,在爬取网页时能够高效地提取出需要的内容。Scrapy框架通过规则匹配和提取网页内容,让爬虫的编写变得...
简单易用,内置三种爬虫,可应对各种需求场景 AirSpider 轻量爬虫:学习成本低,可快速上手 Spider 分布式爬虫:支持断点续爬、爬虫报警、数据自动入库等功能 BatchSpider 批次爬虫:可周期性的采集数据,自动将...
在大数据时代,掌握数据就掌握了企业发展的方向。爬虫作为抓取互联网数据的一个途径,成为企业需求量非常大的岗位之一。...而如果遇到大型的爬虫需求,则需要考虑使用框架了。下面我们来一起学习以及各框架。
Scrapy是一个功能强大的Python网络爬虫框架,专为数据采集而设计。它提供了一套高度可定制的工具和流程,使得你可以轻松地构建和管理网络爬虫,从而快速地获取所需的数据。Requests-HTML是一个基于Requests库的...
精通Python爬虫框架Scrapy.pdf
Scratch,是抓取的意思,这个Python的爬虫框架叫Scrapy,大概也是这个意思吧,就叫它:小刮刮吧。 小刮刮是一个为遍历爬行网站、分解获取数据而设计的应用程序框架,它可以应用在广泛领域:数据挖掘、信息处理和或者...
Scrapy是一个功能强大并且非常快速的网络爬虫框架,是非常优秀的python第三方库,也是基于python实现网络爬虫的重要的技术路线。 Scrapy的安装: 直接在命令提示符窗口执行pip install scrapy貌似不行。 我们需要先...
本文实例讲述了python爬虫框架scrapy实现模拟登录操作。分享给大家供大家参考,具体如下: 一、背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML、json数据,但是忽略了很多的一个问题,有很...
一个敏捷,强大,独立的分布式爬虫框架。支持spring boot和redisson。 SeimiCrawler的目标是成为Java里最实用的爬虫框架,大家一起加油。 简介 SeimiCrawler是一个敏捷的,独立部署的,支持分布式的Java爬虫框架,...
《我用爬虫一天时间“偷了”知乎一百万用户,只为证明PHP是世界上最好的语言 》所使用的程序
本文实例讲述了Python爬虫框架Scrapy常用命令。分享给大家供大家参考,具体如下: 在Scrapy中,工具命令分为两种,一种为全局命令,一种为项目命令。 全局命令不需要依靠Scrapy项目就可以在全局中直接运行,而项目...
python爬虫框架python爬虫框架
py也有很多爬虫框架,比如scrapy,Portia,Crawley等。 之前我个人更喜欢用C#做爬虫。 随着对nodejs的熟悉。发现做这种事情还是用脚本语言适合多了,至少不用写那么多的实体类。而且脚本一般使用比较简单。 在...
经常游弋在互联网爬虫行业的程序员来说,如何快速的实现程序自动化,高效化都是自身技术的一种沉淀的结果。
开源python网络爬虫框架Scrapy.pdf开源python网络爬虫框架Scrapy.pdf开源python网络爬虫框架Scrapy.pdf开源python网络爬虫框架Scrapy.pdf开源python网络爬虫框架Scrapy.pdf开源python网络爬虫框架Scrapy.pdf开源...
大家好我是小菜鸡,让我们一起学习Python的网络爬虫框架-Scrapy爬虫框架的使用(一起努力,咱们顶峰相见!!!)
为您提供ScrapyWeb爬虫框架下载,Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
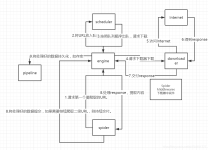
使用nodejs开发爬虫半年左右了,爬虫可以很简单,也可以很复杂。简单的爬虫定向爬取一个网站,可能有个几万或者几十万的页面请求,今天给大家介绍这款非常好用的爬虫框架crawl-pet
本测试Demo共包含两个网站,涉及到三个数据页面的操作,三个Controller层由浅及深,可以更快入手,数据才存储数据库的时候,做了重复性的判断,避免重复添加。
在本篇文章里小编给大家整理的是关于2020年8个效率最高的爬虫框架知识点,需要的朋友们可以学习下。
网络收藏家WebCollector是一个基于Java的开源网络爬虫框架,提供了一些简单的网页爬取接口。
WebMagic是一个基于Java的开源爬虫框架,它提供了一个灵活且易于使用的API,可以帮助开发人员快速开发爬虫程序。你可以从Apache HttpClient的官方网站上下载最新的jar包,并将其添加到你的项目中。Jsoup是一个用于...
win10环境 搭建 python环境 pycharm工具搭建scrapy爬虫框架 附带教程 附带插件 根据环境自行下载 适用于各个版本, 参照教程下载安装即可
Java爬虫框架(20210809123939).pdf

推荐文章
- confluence搭建部署_ata confluence-程序员宅基地
- SpringCloud与SpringBoot版本对应关系_springboot 2.1.1 对于的cloud-程序员宅基地
- 如何恢复硬盘数据?简单解决问题_磁盘恢复 csdn-程序员宅基地
- 苹果手机测试网络速度的软件,App Store 上的“网速测试大师-测网速首选”-程序员宅基地
- 教了一年少儿编程,说说感想和体验-程序员宅基地
- 22东华大学计算机专硕854考研上岸实录-程序员宅基地
- 如何用《玉树芝兰》入门数据科学?-程序员宅基地
- macOS使用brew包管理器_brew清理缓存-程序员宅基地
- 【echarts没有刷新】用按钮切换echarts图表的时候,该消失的图表还在,加个key属性就解决了_echarts 怎么加key值-程序员宅基地
- 常用机器学习的模型和算法_常见机器学习模型算法整理和对应超参数表格整理-程序员宅基地